Downloaded 12 times




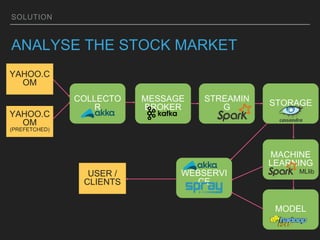

Distributed machine learning allows companies to collect and process large amounts of data continuously to build models that generate value. The solution involves collecting high-volume data from various sources and applying a multi-step pipeline to process, analyze, and model the data using machine learning algorithms. The models are then deployed via web services so users can integrate the insights into applications to solve problems like analyzing stock market trends.







![Building Serverless Machine Learning Models in the Cloud [PyData DC]](https://cdn.slidesharecdn.com/ss_thumbnails/building-serverless-machine-learning-models-pydata-dc-161003061550-thumbnail.jpg?width=640&height=640&fit=bounds)












































