Downloaded 14 times












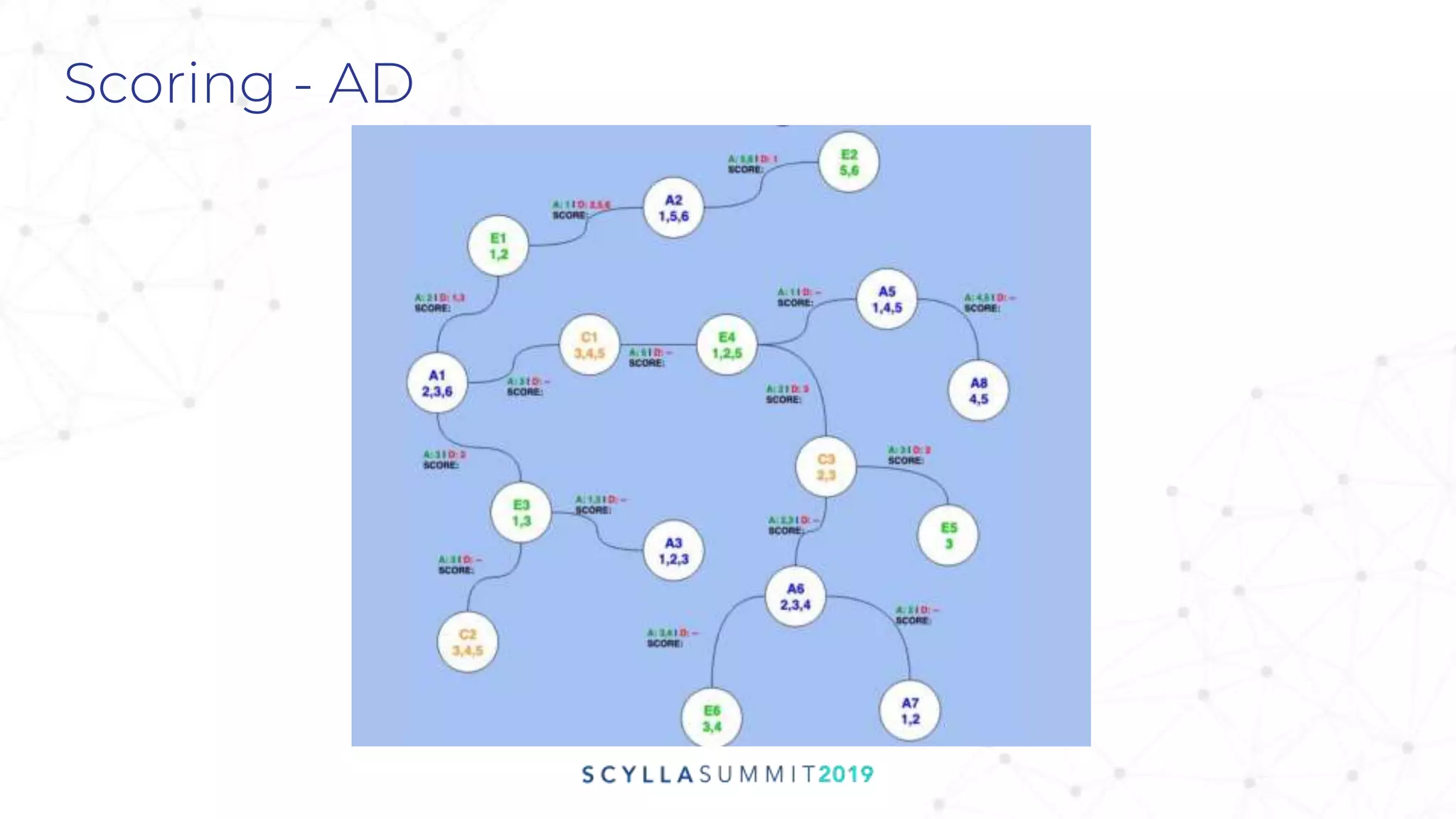
![ID Graph Data Model
label: id
type: online
idtype: adid_sha1
id: c3b2a1ed
os: ‘android’
country: ‘ESP’
dpid: {1}
ip: [1.2.3.4]
linkedTo: {dp1: t1, dp2: t2,
quality: 0.30, linkType: 1}
linkedTo: {dp1: t1, dp2: t2, dp3: t3,
dp4: t4, quality: 0.55, linkType: 3}
label: id
type: online
idtype: adid
id: a711a4de
os: ‘android’
country: ‘ITA’
dpid: {2,3,4}
label: id
type: online
Idtype: googlecookie
id: 01e0ffa7
os: ‘android’
country: ‘ESP’
dpid: {1,2}
label: id
type: online
idtype: adid
id: 412ce1f0
os: ‘android’
country: ‘ITA’
dpid: {2,4}
ip: [1.2.3.4]
label: id
type: offline
idtype: email
id: abc@gmail.com
os: ‘ios’
country: ‘ESP’
dpid: {2,4}
linkedTo: {dp1: t1, quality: 0.25,
linkType: 3, linkSource: ip}
linkedTo: {dp2: t2, dp3: t3,
dp4: t4, quality: 0.71,
linkType: 9}](https://image.slidesharecdn.com/cm12wed930zeotapsathishsaurabhmovingtoscylla-191113204155/75/Zeotap-Moving-to-ScyllaDB-A-Graph-of-Billions-Scale-18-2048.jpg)
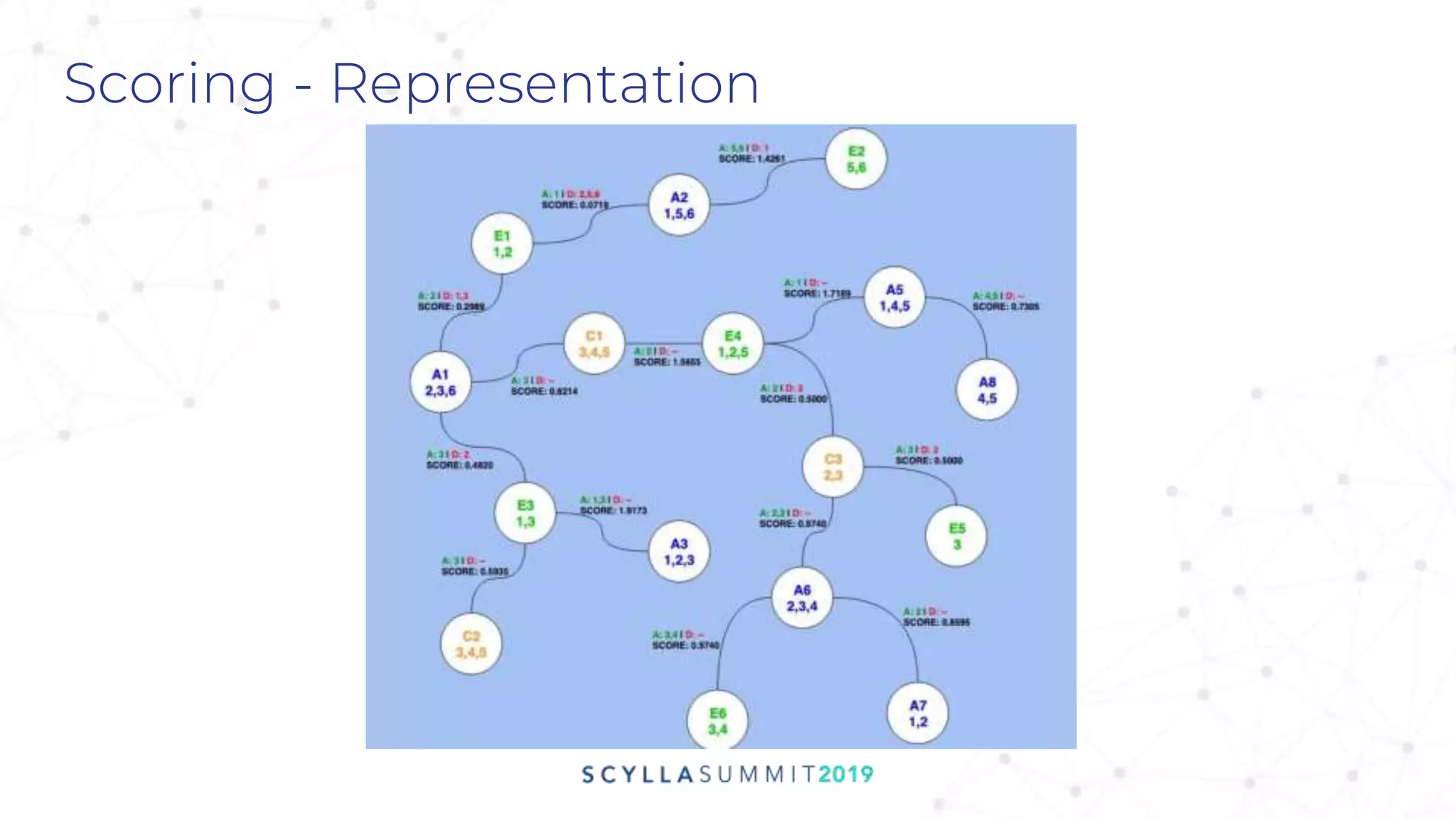
![Expressiveness of Model
label: id
type: online
idtype: adid_sha1
id: c3b2a1ed
os: ‘android’
country: ‘ESP’
dpid: {1}
ip: [1.2.3.4]
linkedTo: {dp1: t1, dp2: t2,
quality: 0.30, linkType: 1}
linkedTo: {dp1: t1, dp2: t2, dp3: t3,
dp4: t4, quality: 0.55, linkType: 3}
label: id
type: online
idtype: adid
id: a711a4de
os: ‘android’
country: ‘ITA’
dpid: {2,3,4}
label: id
type: online
Idtype: googlecookie
id: 01e0ffa7
os: ‘android’
country: ‘ESP’
dpid: {1,2}
label: id
type: online
idtype: adid
id: 412ce1f0
os: ‘android’
country: ‘ITA’
dpid: {2,4}
ip: [1.2.3.4]
label: id
type: offline
idtype: email
id: abc@gmail.com
os: ‘ios’
country: ‘ESP’
dpid: {2,4}
linkedTo: {dp1: t1, quality: 0.25,
linkType: 3, linkSource: ip}
linkedTo: {dp2: t2, dp3: t3,
dp4: t4, quality: 0.71,
linkType: 9}
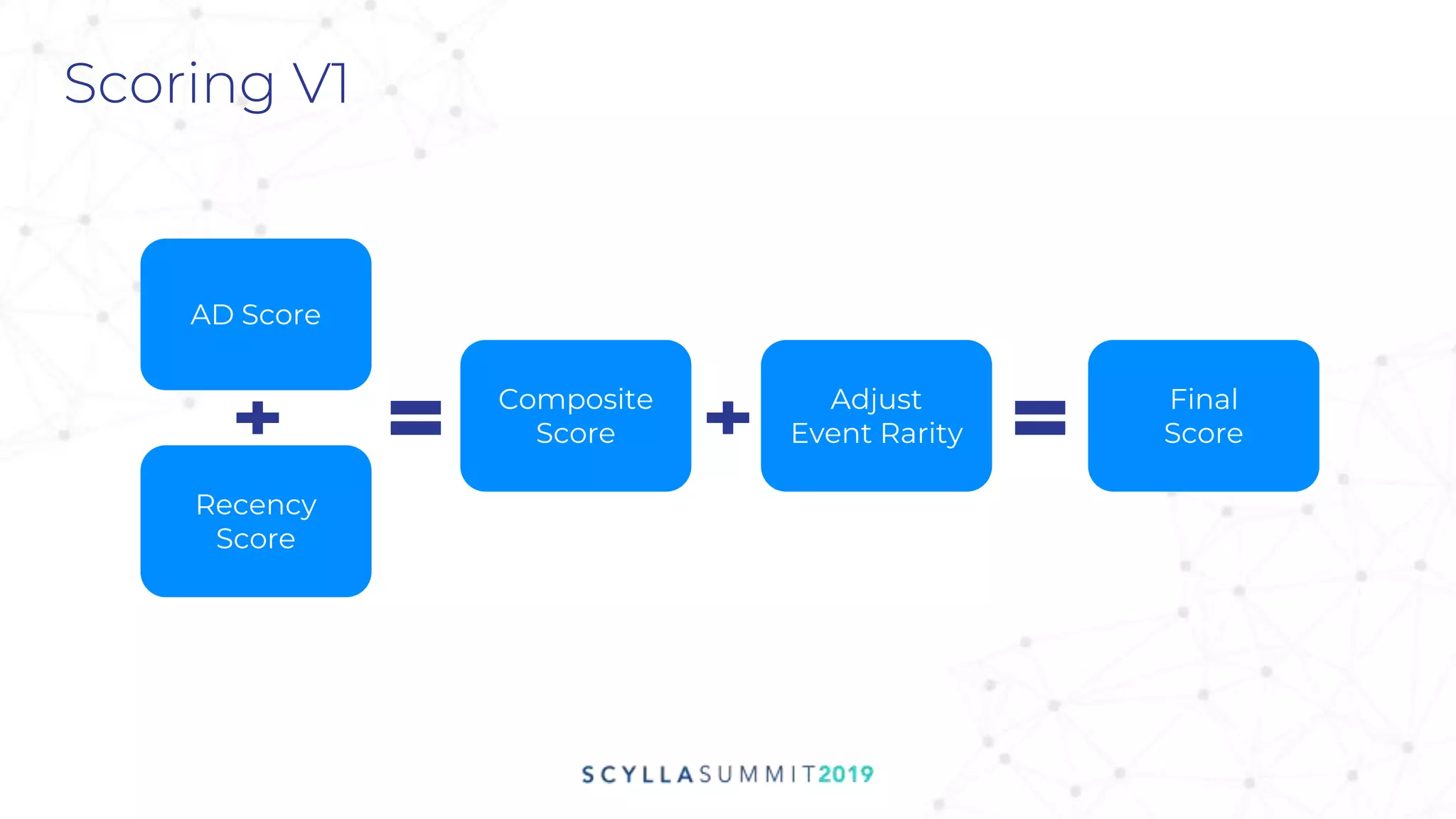
Quality
Filtered Links
ID Attribute
Filtering
Recency
Filtered Links
Extensible
Data Model
Transitive
Links](https://image.slidesharecdn.com/cm12wed930zeotapsathishsaurabhmovingtoscylla-191113204155/75/Zeotap-Moving-to-ScyllaDB-A-Graph-of-Billions-Scale-19-2048.jpg)







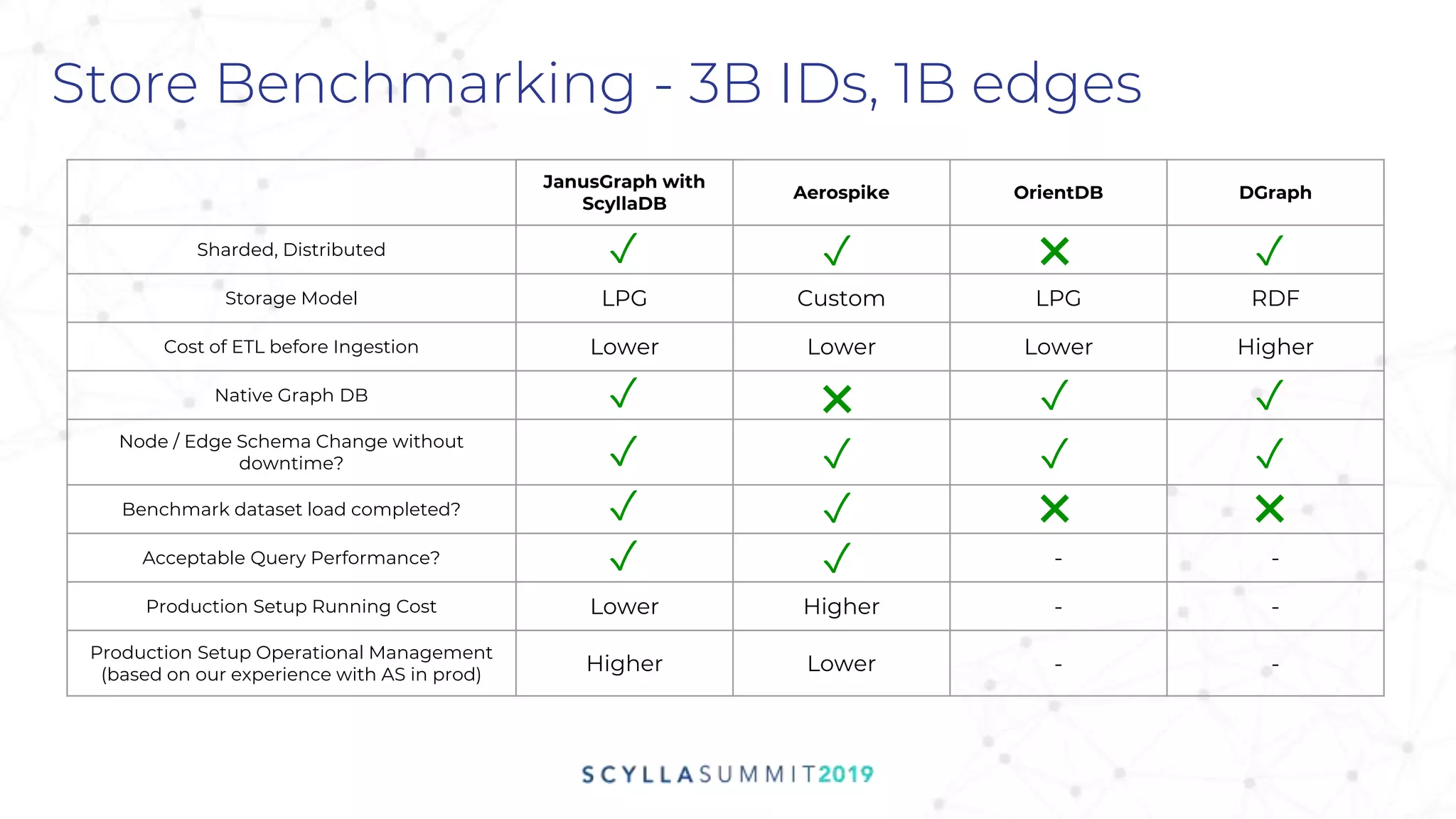
![Know Your Query And Data
■ Segments are country based - filter based on Countries
■ Vertex Metadata not huge
Fetching individual properties from the Vertex
gremlin>g.V().has('id','1').has('type','email')
.values('id', 'type', 'USA').profile()
Fetching entire property map during traversal
gremlin>g.V().has('id','1').has('type','email')
.valueMap().profile()
Step Traversers Time
JanusGraphStep
_condition=(id=1
AND type = email)
1 0.987
JanusGraphPrope
rtiesStep
_condition=((type[
id] OR type[type]
OR type[USA]))
4 1.337
2.325 s
Step Traversers Time
JanusGraphStep
_condition=(id=1
AND type = email)
1 0.902
PropertyMapStep
(value)
1 0.175
1.077 s
~200%](https://image.slidesharecdn.com/cm12wed930zeotapsathishsaurabhmovingtoscylla-191113204155/75/Zeotap-Moving-to-ScyllaDB-A-Graph-of-Billions-Scale-27-2048.jpg)












The document discusses the transition to ScyllaDB for managing a large-scale identity and data platform at Zeotap, focusing on graph databases to enhance identity resolution and data processing capabilities. It details the requirements for the identity technology, including high read and write performance, streaming ingestion, and real-time lookups, as well as challenges encountered during implementation. Additionally, it outlines findings related to system performance, query optimization, and operational management, culminating in a successful production setup using ScyllaDB on AWS.






















































































