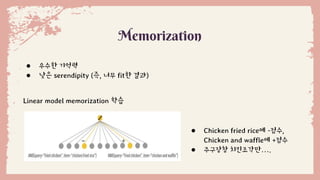
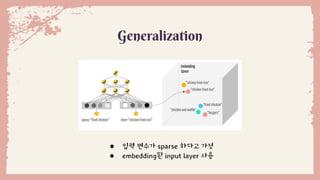
● 입력 변수가sparse 하다고 가정
● embedding된 input layer 사용
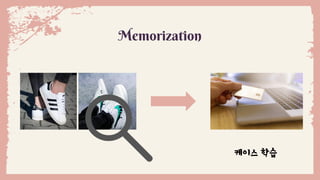
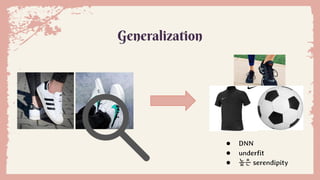
Generalization
8.
● polynomial하게 cross-product로재구성
● 어떤 조합을 사용할 지 분석가가 결정
(차원 수 기하급수적 증가 시 불가능)
Feature 연관성 반영
● MF기반의 CF 혹은 FM, Deep Learning
● cross-product의 기능을 하는 무언가를 학습
9.
‘날개 달린 동물은난다’
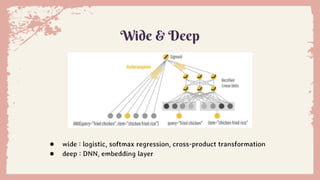
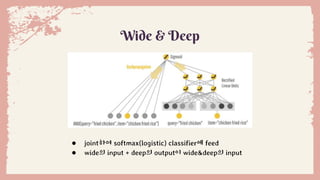
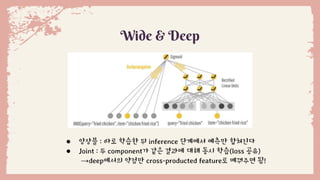
Wide & Deep
‘펭귄은 날지 못한다’ ‘날개 달린 동물은 날지만
펭귄은 날지 못한다’
10.
● wide :logistic, softmax regression, cross-product transformation
● deep : DNN, embedding layer
Wide & Deep
Recommender Policy?
추천시스템은 일반적으로유저가 높은 평가를 준 아이템과 비슷한 아이템들을 추천해준다.
● 높은 평가를 받는 아이템은 그 아이템만의 고유 특성이 유저의 고유 취향과 잘 부합하기
때문
● 따라서 유저 취향에 잘 부합하는 아이템 위주로 추천해주는 정책이 회사의 수익성을 보장할
것이다.
18.
Recommender Policy?
얼핏 보면당연히 옳은 추천 정책이지만 - 역설적으로 유저의 취향에 따라서만 추천해주는데에
문제가 있을 수 있다.
● 유저 자신이 좋아하는 분야는 굳이 추천을 안받아도 자신이 알아서 잘 찾아볼 것이다. 그러면
추천의 효율성이 떨어진다.
마케터 입장에서는 - 수익성을 높이기 위해서는 유저의 취향을 ‘넓혀야’ 한다.
● 즉, 선택의 폭을 넓히려면 유저의 취향과 좀 다른 아이템들도 추천해줘야함.
○ 평소에 잘 모르는 분야이기에 유저 입장에서 직접 찾아보기 힘든 아이템을 회사가
추천해주는것.
19.
‘만약 평소에 잘안찾거나 잘 모르던 아이템을
억지로 추천해준다면
유저의 평가는 어떨까?’
마케터의 관심사는
20.
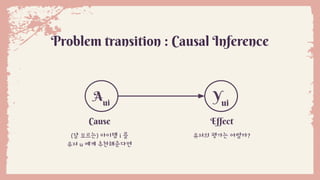
Problem transition :Causal Inference
Cause
(잘 모르는) 아이템 i 를
유저 u 에게 추천해준다면
Effect
유저의 평가는 어떨까?
Yui
Aui
21.
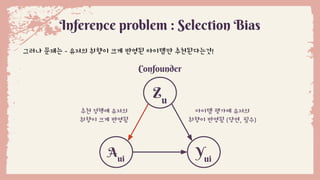
Inference problem :Selection Bias
그러나 문제는 - 유저의 취향이 크게 반영된 아이템만 추천된다는것!
Yui
Aui
Zu
Confounder
아이템 평가에 유저의
취향이 반영됨 (당연, 필수)
추천 정책에 유저의
취향이 크게 반영됨
22.
Wait, why it’sthe Problem??
● 이전의 유저 평가들이 순수한 인과관계라고 보기 어렵다.
○ 추천여부 자체가 유저의 편향에 영향받기에 - 특정 아이템의 평가 역시 편향적
유저들에 의해서만 이루어질 수 있다.
Yui
Aui
Zu
23.
How do wesolve it?
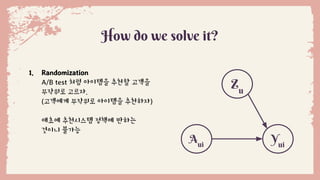
1. Randomization
A/B test 처럼 아이템을 추천할 고객을
무작위로 고르자.
(고객에게 무작위로 아이템을 추천하자)
애초에 추천시스템 정책에 반하는
것이니 불가능
Yui
Aui
Zu
24.
How do wesolve it?
2. Inverse Propensity Scoring
모델링 자체에서 - 마치 아이템이 무작위로 추천된 것처럼 만들자.
(모델링 과정에서 아이템 i가 유저 u에게 추천될 확률을 나누어주자)
25.
How do wesolve it?
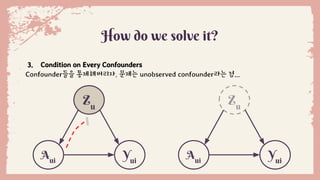
3. Condition on Every Confounders
Confounder들을 통제해버리자. 문제는 unobserved confounder라는 점...
Yui
Aui
Zu
Yui
Aui
Zu
26.
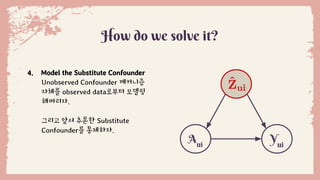
How do wesolve it?
4. Model the Substitute Confounder
Unobserved Confounder 메커니즘
자체를 observed data로부터 모델링
해버리자.
그리고 앞서 추론한 Substitute
Confounder를 통제하자.
Yui
Aui
눈여겨볼 것은 SubstituteConfounder의 계수
● 유저마다 자신의 preference를 아이템 평가에 얼마나 반영할지 다를것이라는 가정
Substitute Confounder의 효과 :
● 단일 Outcome Model만으로 유저평가를 예측한다면 Overestimated 결과를 내놓는다.
● 그러나 1-stage에서 추론한 유저 성향을 실제 rating에서 미리 제거하여 Outcome
Model의 Overestimate를 방지한다.
○ Outcome Model 예측 값이 순수한 인과관계를 반영하는데 도움준다.
32.
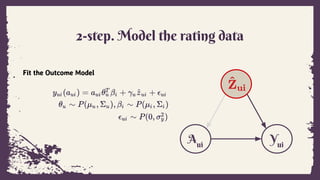
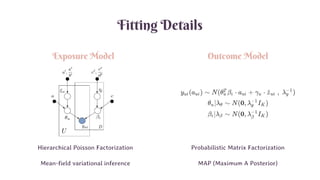
Fitting Details
Exposure ModelOutcome Model
Hierarchical Poisson Factorization
Mean-field variational inference
Probabilistic Matrix Factorization
MAP (Maximum A Posterior)
33.
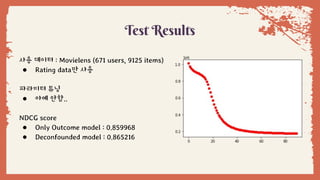
Test Results
사용 데이터: Movielens (671 users, 9125 items)
● Rating data만 사용
파라미터 튜닝
● 아예 안함..
NDCG score
● Only Outcome model : 0.859968
● Deconfounded model : 0.865216
34.
Discussions
● Deconfounded recommender은특정 모형이 아닌 - 프레임워크다.
○ Exposure model에 다른 Generative model과 Outcome model에 다른
Embedding model을 적용하여 개선 가능
● 주의할 점은 1-stage model부터 성능이 안좋다면 Outcome model만 쓴 것보다도
못한 결과가 초래할수도…!
○ 조정할 파라미터 수가 너무 많다..
● 꼭 이러한 프레임워크를 따를 필요 없이 - 모델러 자신이 옳다고 생각한 인과구조를
바탕으로 프레임워크를 임의로 설계할 수 있다.
○ 대신 타당한 이론과 test score로 자신의 가설을 입증해야할 것이다.
35.
References
1. Yixin, W.,Liang, D., Charlin, L., and Blei, D.M. (2020). Causal Inference for
Recommender Systems.
2. Yixin, W. and Blei, D.M. (2019). The Blessings of Multiple Causes.
3. Bonner, S. and Vasile, F. (2018). Causal Embeddings for Recommendation.
4. Schnabel, T., Swaminathan, A., Singh, A., Chandak, N., and Joachims, T.
(2016). Recommendations as Treatments: Debiasing Learning and Evaluation.
5. Liang, D., Charlin, L., and Blei, D.M. (2016). Causal Inference for
Recommendation.
6. Gopalan, P., Hofman J.M., and Blei, D.M. (2015). Scalable Recommendation
with Hierarchical Poisson Factorization





















![[시스템종합설계].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/3doit-220608124356-ea37a6e3-thumbnail.jpg?width=640&height=640&fit=bounds)





![[팝콘 시즌1] 최보경 : 실무자를 위한 인과추론 활용 - Best Practices](https://cdn.slidesharecdn.com/ss_thumbnails/papconcausalinferencebestpractices-220221141200-thumbnail.jpg?width=640&height=640&fit=bounds)
![[PAP] 실무자를 위한 인과추론 활용 : Best Practices](https://cdn.slidesharecdn.com/ss_thumbnails/papcon1-220218051343-thumbnail.jpg?width=640&height=640&fit=bounds)









![제 19회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [COLLABO-AZ] : 고객 세그멘테이션 기반 개인 맞춤형 추천시스템 for 루빗](https://cdn.slidesharecdn.com/ss_thumbnails/random-240214103130-13fea14b-thumbnail.jpg?width=640&height=640&fit=bounds)



























