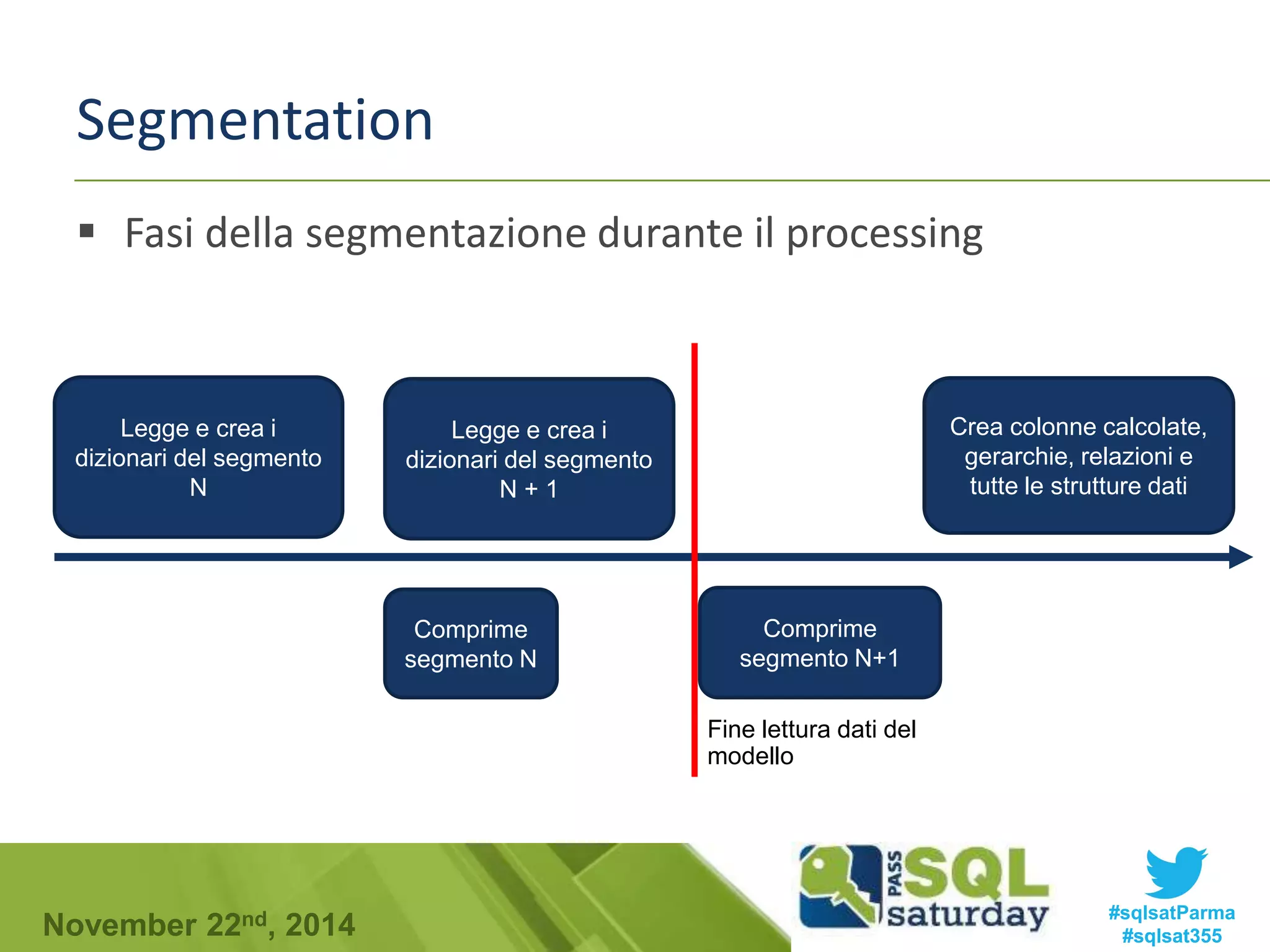
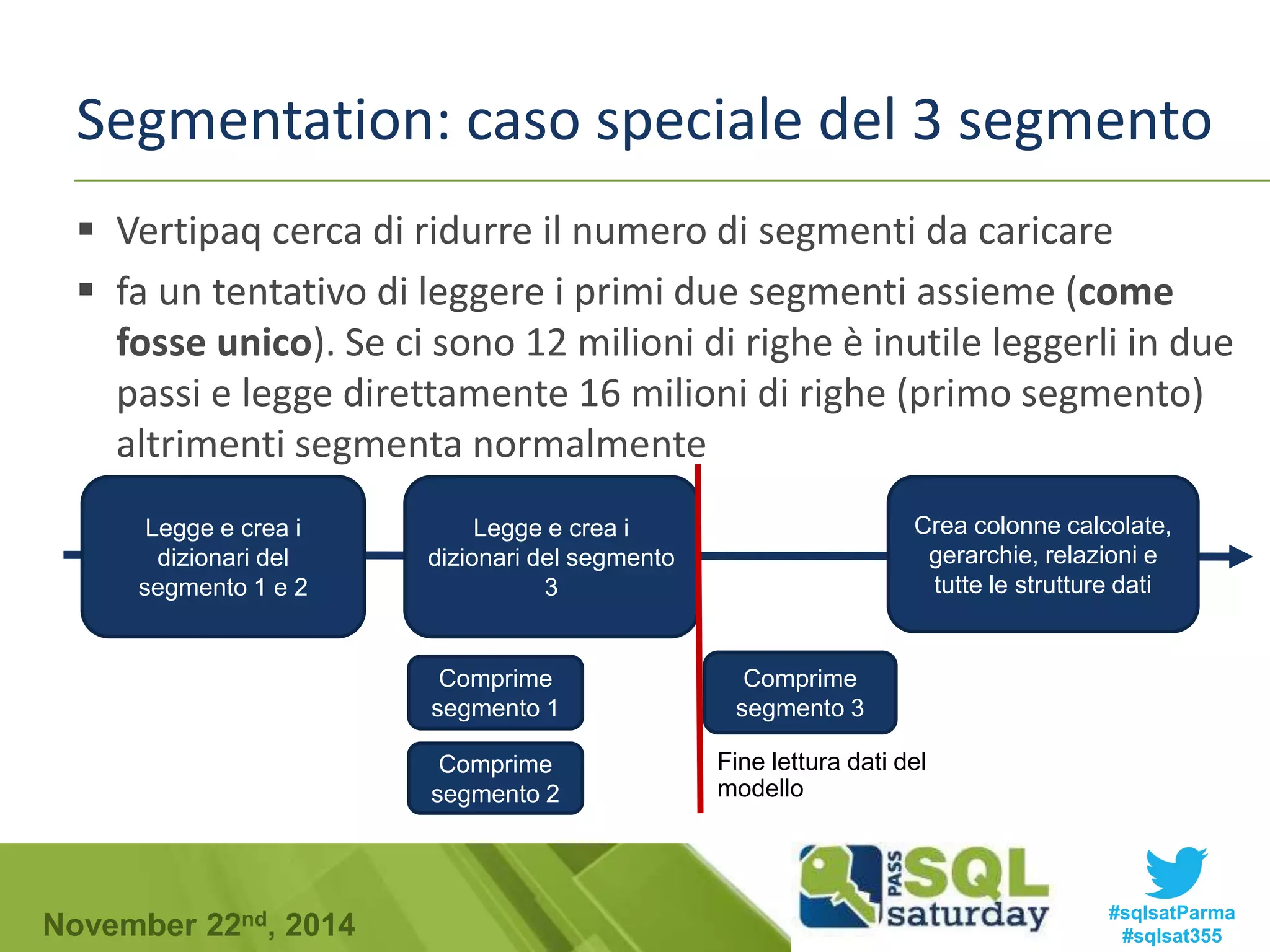
Download to read offline





























![Materialization
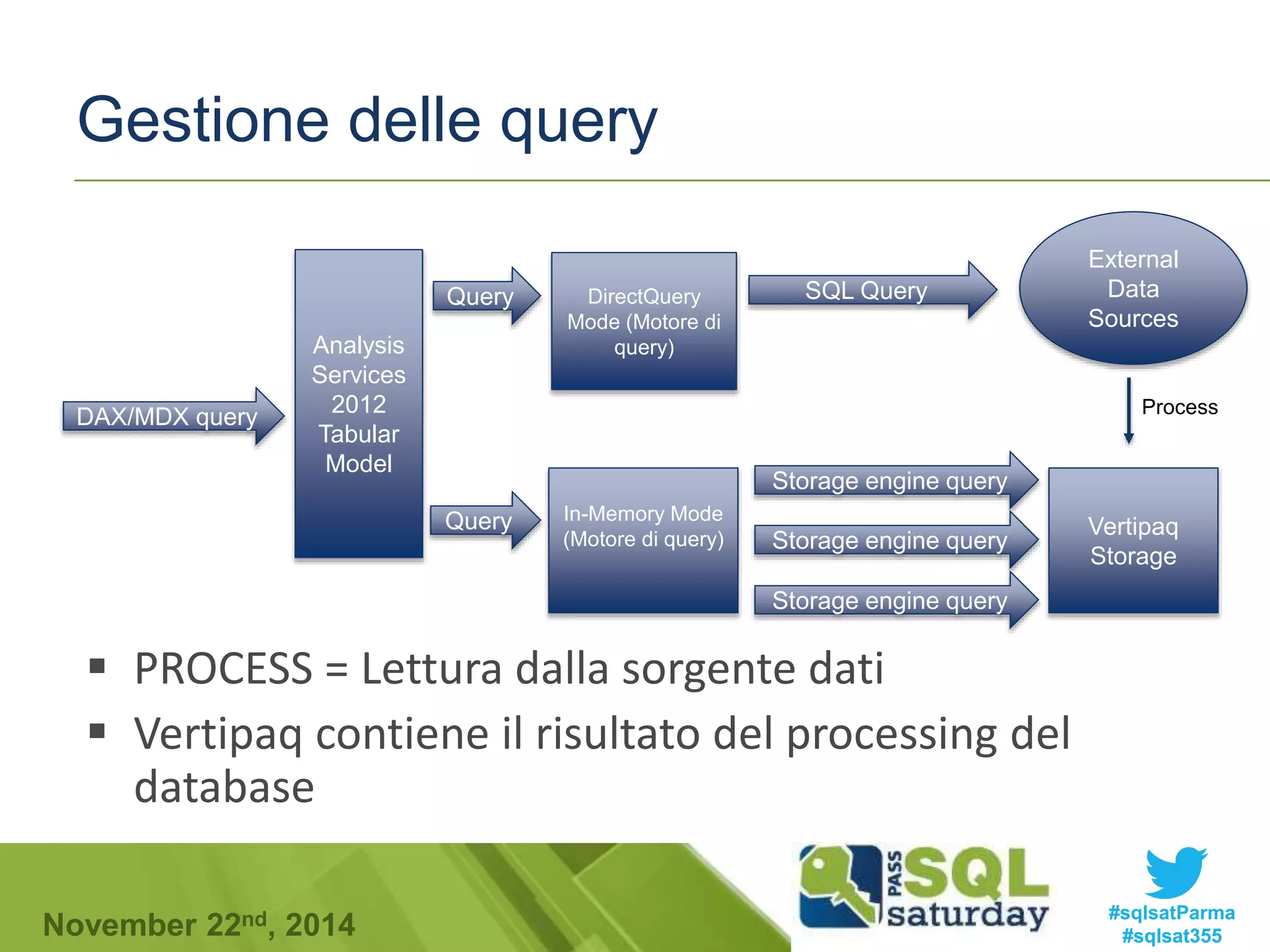
Se vogliamo eseguire su un database colonnare la
seguente query:
SELECT SUM(num730) AS N730,[COD_Ufficio]
FROM [dbo].[Dichiarazioni730]
WHERE [COD_Utente] = 345 AND [Tipo730] = 1
GROUP BY [COD_Ufficio]
Tipo730
1
2
1
1
Cod_Ufficio
4555
2345
6545
444
COD_Utente
345
1678
345
100
Ci sono diverse tecniche ma agli estremi ci sono:
Early Materialization
Late Materializzation
num730
234
100
400
3
#sqlsatParma
#sqlsat355 November 22nd, 2014](https://image.slidesharecdn.com/sqlsaturday-141122092631-conversion-gate02/75/xVelocity-in-Deep-36-2048.jpg)
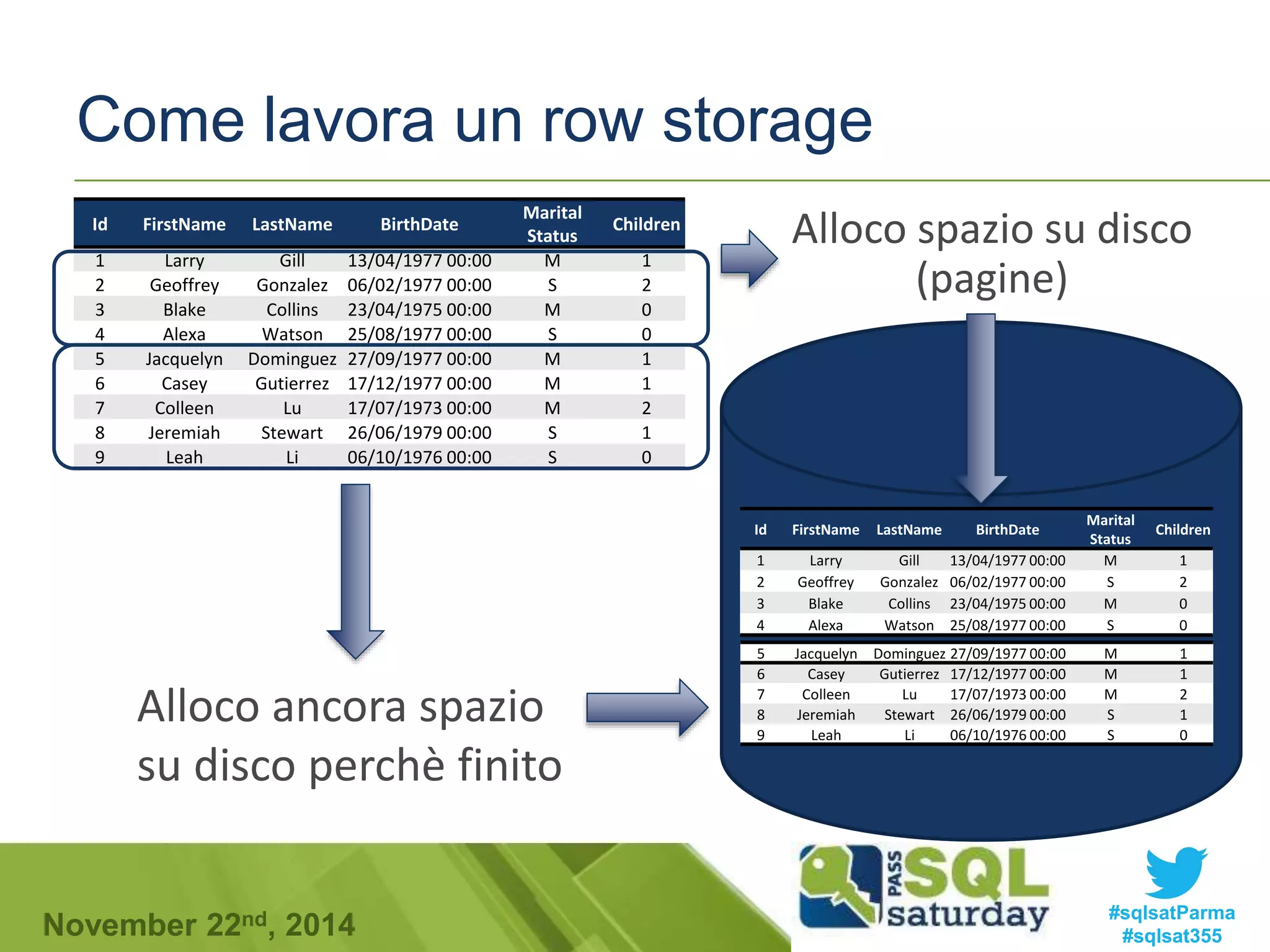
![Early materialization
Tipo730
1
2
1
1
Cod_Ufficio
4555
2345
4555
444
num730
234
100
400
3
COD_Utente
345
1678
345
100
Ricomponiamo il row store
(Materializzo)
345 1 4555 234
1678 2 2345 100
345 1 4555 400
100 1 444 3
SELECT SUM(num730) AS N730,[COD_Ufficio]
FROM [dbo].[Dichiarazioni730]
WHERE [COD_Utente] = 345 AND [Tipo730] = 1
GROUP BY [COD_Ufficio]
La fregatura è che faccio tanto
lavoro per comprimere in
colonne separate e poi devo
riunire tutto. Uso tanta
memoria se faccio select *
Applico la where
345 1 4555 234
345 1 4555 400
Proiezione per num730 e cod_ufficio
4555 234
4555 400
Sommo
4555 634
#sqlsatParma
#sqlsat355 November 22nd, 2014](https://image.slidesharecdn.com/sqlsaturday-141122092631-conversion-gate02/75/xVelocity-in-Deep-37-2048.jpg)
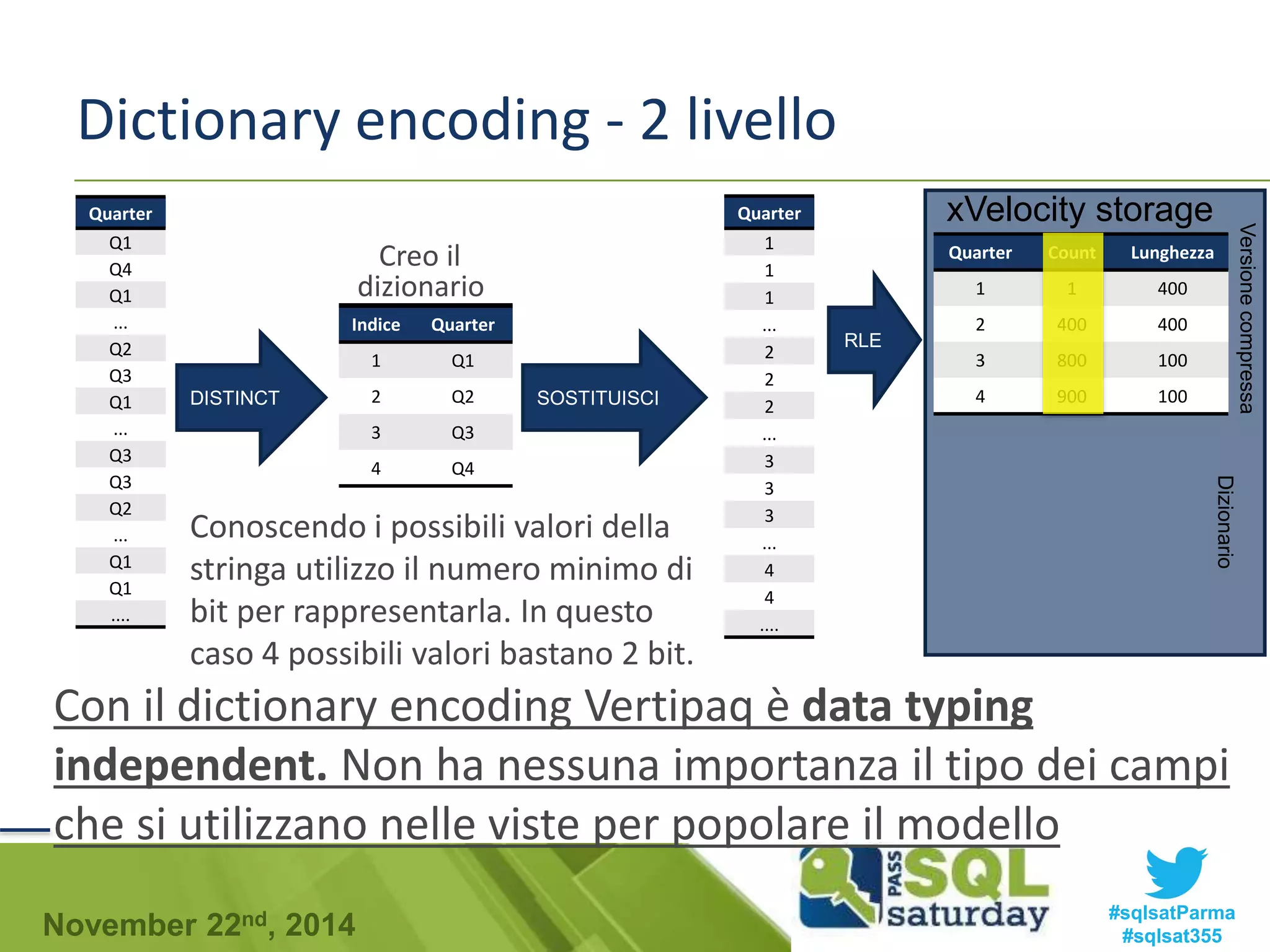
![Late materializzation
Tipo730
Tipo730
1
2
1
1
Cod_Ufficio
4555
2345
4555
444
num730
234
100
400
3
COD_COD_Utente
345
1678
345
100
SELECT SUM(num730) AS N730,[COD_Ufficio]
FROM [dbo].[Dichiarazioni730]
WHERE [COD_Utente] = 345 AND [Tipo730] = 1
GROUP BY [COD_Ufficio]
Bitmap
1
0
1
0
Applico la clausola
where sulle due
colonne separate
Materializzo
4555 234
4555 400
Sommo
4555 634
Bitmap
1
0
1
1
And
Bitmap
1
0
1
0
Cod_Ufficio
4555
2345
6545
444
num730
234
100
400
3
Applico la bitmap
Cod_Ufficio
4555
4555
num730
234
400
#sqlsatParma
#sqlsat355 November 22nd, 2014](https://image.slidesharecdn.com/sqlsaturday-141122092631-conversion-gate02/75/xVelocity-in-Deep-38-2048.jpg)













Il documento discute XVelocity in-memory, un database colonnare che ottimizza la gestione delle query e il processamento dei dati in memoria. Viene confrontato l'accesso ai dati in storage a righe rispetto a quello a colonne, evidenziando le superiorità del column storage in termini di velocità e compressione. Si approfondiscono anche tecniche di compressione come Run Length Encoding (RLE) e Dictionary Encoding, che aumentano l'efficienza del database.



























![noSQL La nuova frontiera dei Database [DB05-S]](https://cdn.slidesharecdn.com/ss_thumbnails/db05-ssiracusa05-03-2016-160304154822-thumbnail.jpg?width=640&height=640&fit=bounds)



















