Downloaded 13 times
















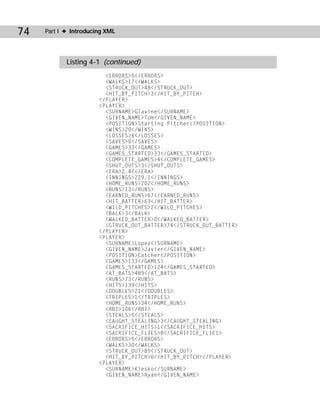

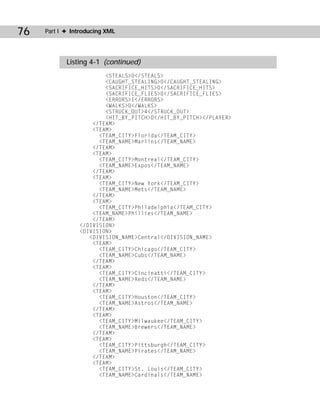



















This document discusses structuring baseball statistics data in XML format. It examines sample data for the 1998 New York Yankees team, including batting statistics for position players and pitching statistics. It considers different ways the data could be organized in an XML structure, with elements for things like player, team, season, games, at-bats, hits, runs etc. The chapter aims to demonstrate marking up the data in XML and preparing a style sheet for displaying the document.




































































