🔹 Hands-on guidance to design, orchestrate, and deploy autonomous AI agents
🔹 Deep dives into modern LLM frameworks
🔹 Practical understanding of:
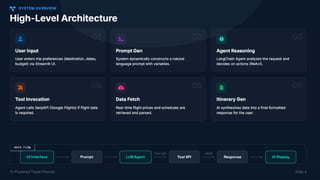
🛠️ Tool usage
🧩 Agent workflows
🧠 Memory management
🧭 Planning & decision-making techniques
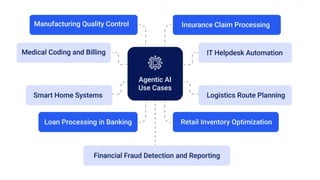
🔹 Exploration of real-world use cases and applications
👥 Who Should Attend?





























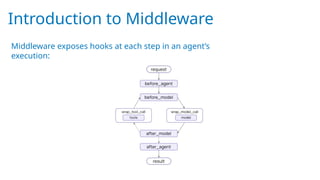


![Examples of inbuilt middleware
PIIMiddleware("email", strategy="redact", apply_to_input=True),
PIIMiddleware(
"phone_number",
detector=(
r"(?:+?d{1,3}[s.-]?)?"
r"(?:(?d{2,4})?[s.-]?)?"
r"d{3,4}[s.-]?d{4}"
),
strategy="block"
),
SummarizationMiddleware(
model="claude-sonnet-4-5-20250929",
trigger={"tokens": 500}
),
HumanInTheLoopMiddleware(
interrupt_on={
"send_email": {
"allowed_decisions": ["approve", "edit", "reject"]
}
}
)](https://image.slidesharecdn.com/whatisagenticai-260201180336-20e17a77/85/WOWVerse-Workshop-Agentic-AI-LLM-Workshop-39-320.jpg)
![Example of Custom middleware
from langchain.agents.middleware import dynamic_prompt
@dynamic_prompt
def prompt_with_context(request):
query = request.state["messages"][-1].content
retrieved_docs = retriever.invoke(query)
context = "nn".join([doc.page_content for doc in retrieved_docs])
system_prompt = (
"Use the given context to answer the question. "
"If you don't know the answer, say you don't know. "
f"Context: {context}"
)
return system_prompt](https://image.slidesharecdn.com/whatisagenticai-260201180336-20e17a77/85/WOWVerse-Workshop-Agentic-AI-LLM-Workshop-40-320.jpg)






























































![[DSC Europe 24] Lana Malic - AI Agents: The Future of Autonomous Decision-Mak...](https://cdn.slidesharecdn.com/ss_thumbnails/lanamalic-aiagents-250212223710-84219c4c-thumbnail.jpg?width=640&height=640&fit=bounds)




















