

![@BIANCHI
Wagner Bianchi has been working with the MySQL ecosystem for more than 12 years now. He is an Oracle ACE
Director since 2014 and has worked on the most complex environments running Open Source solutions. Bianchi
joint MariaDB RDBA Team in 2017 where he works as Remote DBA Team Lead @ MariaDB Remote DBA
Team.
He is specialized in multi-tier/HA/FT setups when multi-integrations are needed to keep systems highly available
and fault-tolerant. MySQL Expert (DEV, DBA, NDB CLUSTER), AWS Certified Solutions Architect, and Splunk
Architect, Bianchi has worked with the biggest environments running MariaDB products like MaxScale, MariaDB
Server, AWS, Azure, providing architecture [re]design, products upgrades, and migrations.
bianchi@mariadb.com
@wagnerbianchijr
wagnerbianchi.com
mariadb.com/blog](https://image.slidesharecdn.com/usingallofthehighavailabilityoptionsinmariadb-190307011159/75/Using-all-of-the-high-availability-options-in-MariaDB-3-2048.jpg)



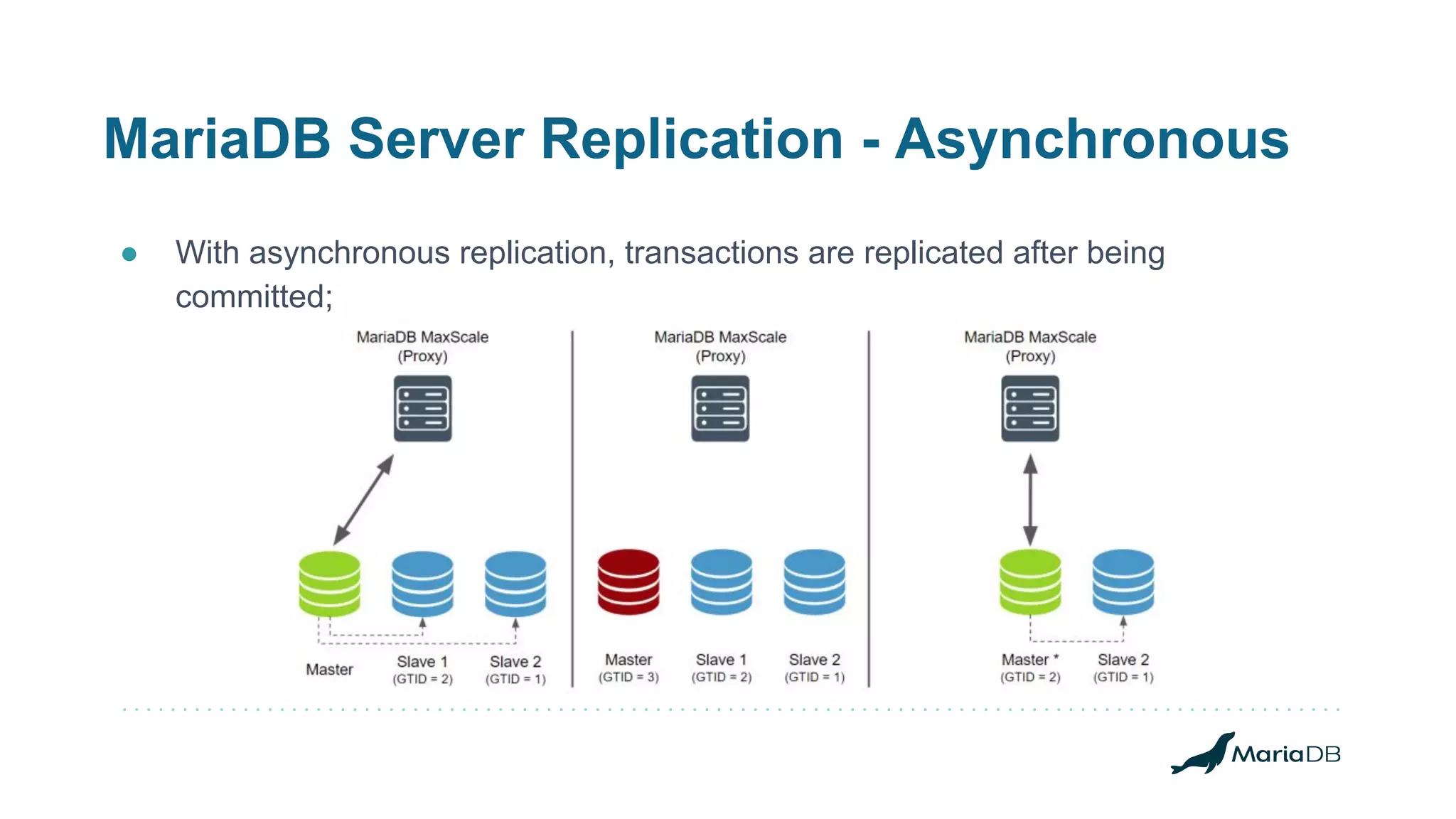
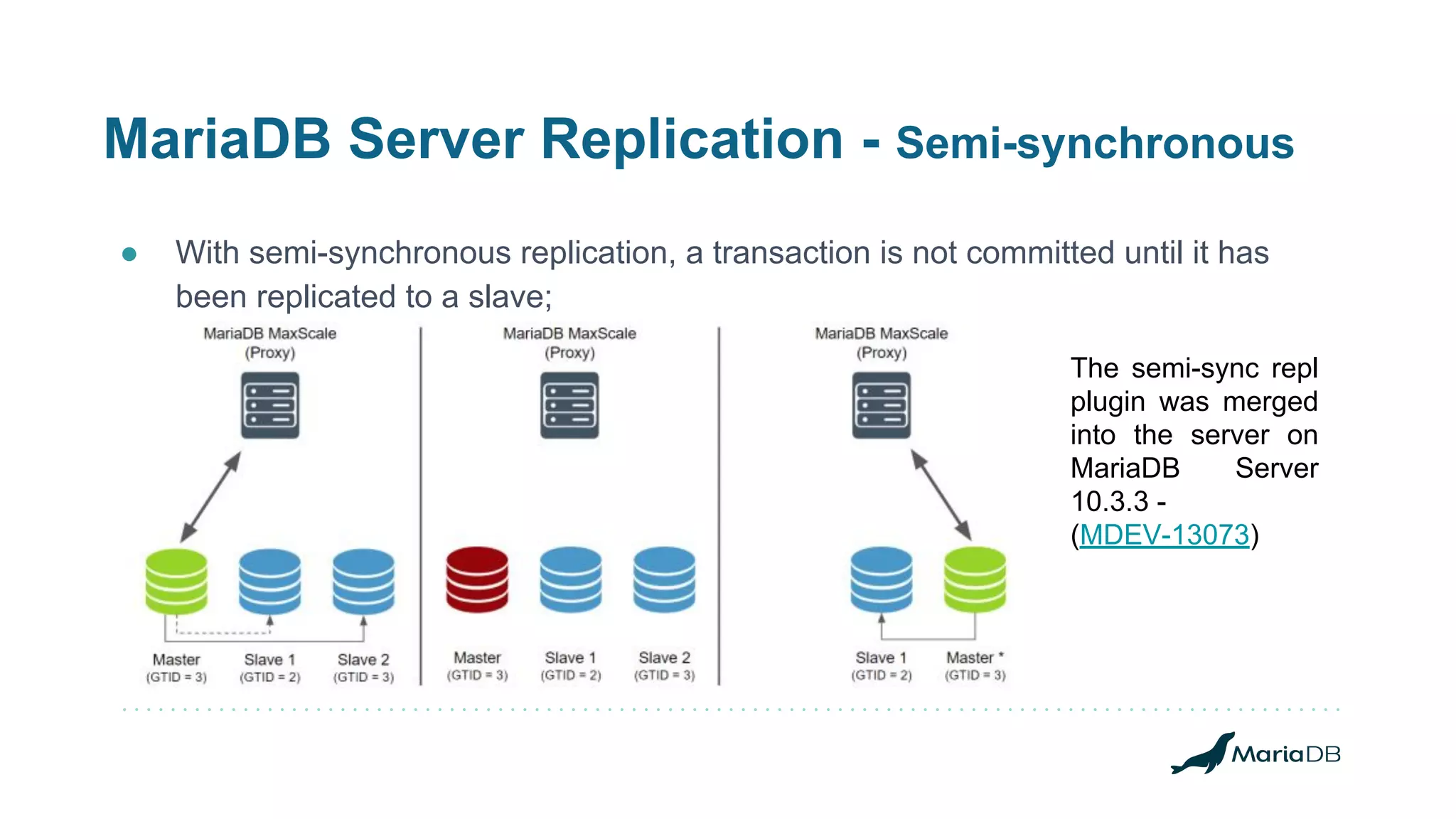
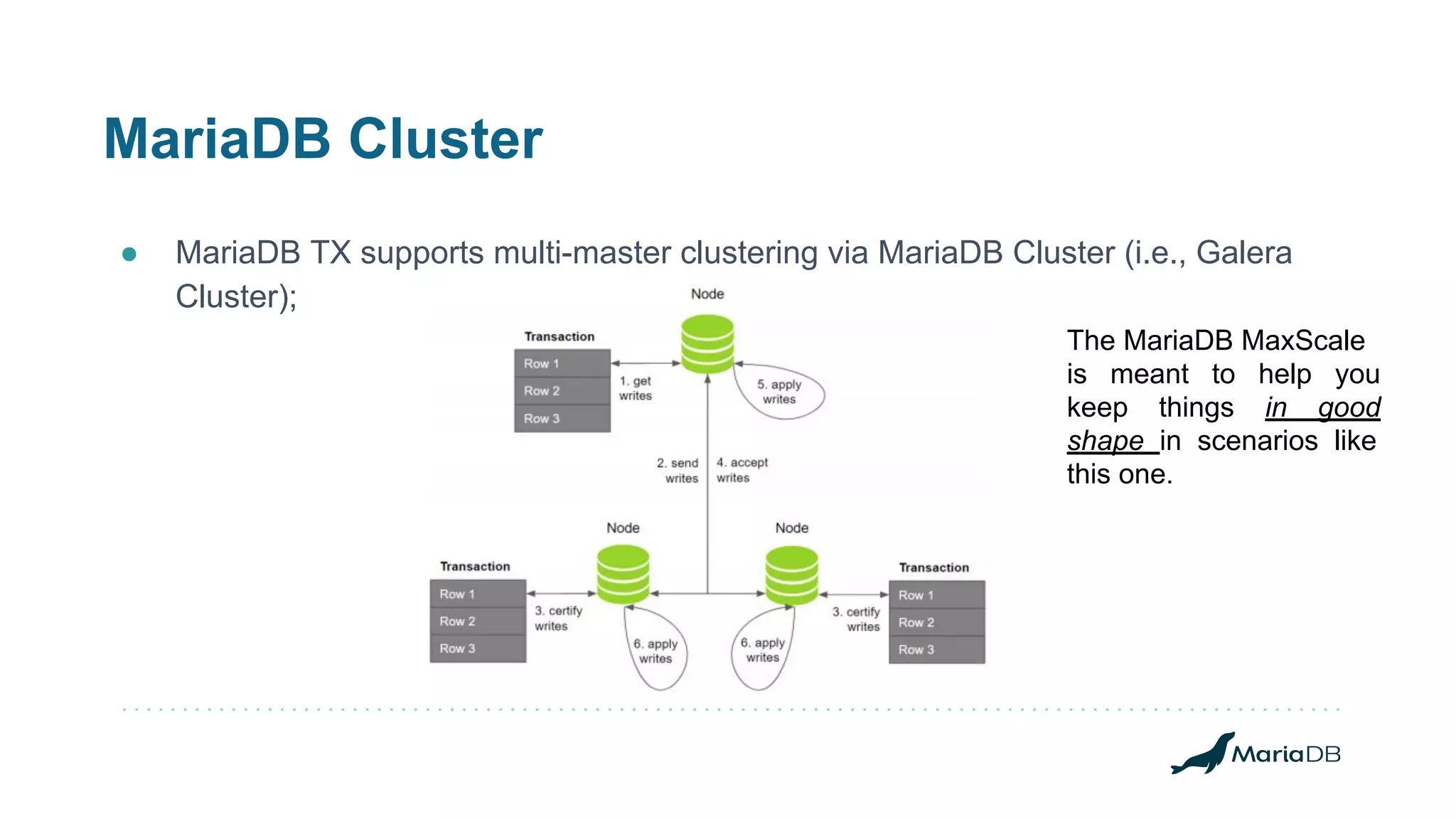

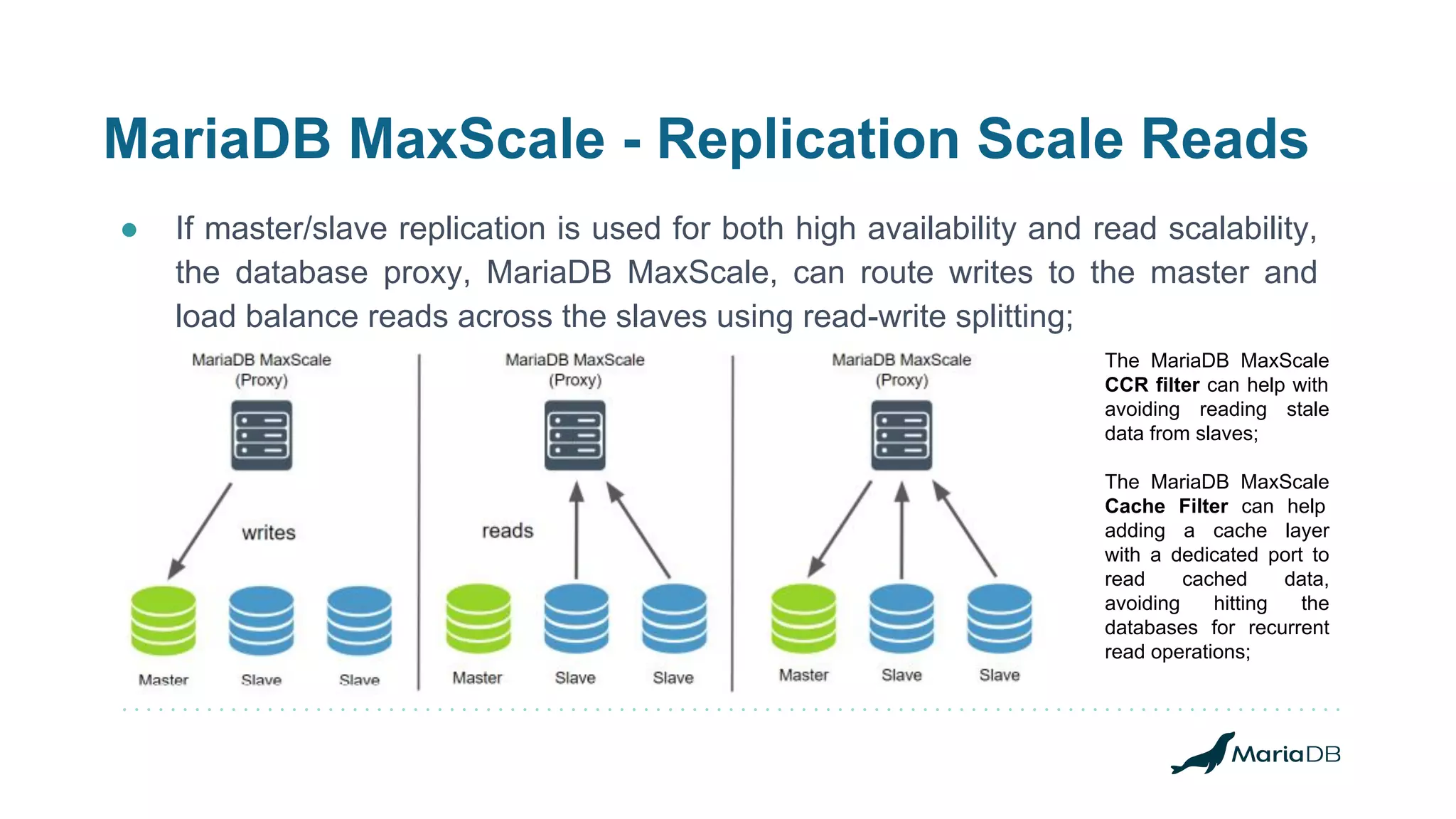
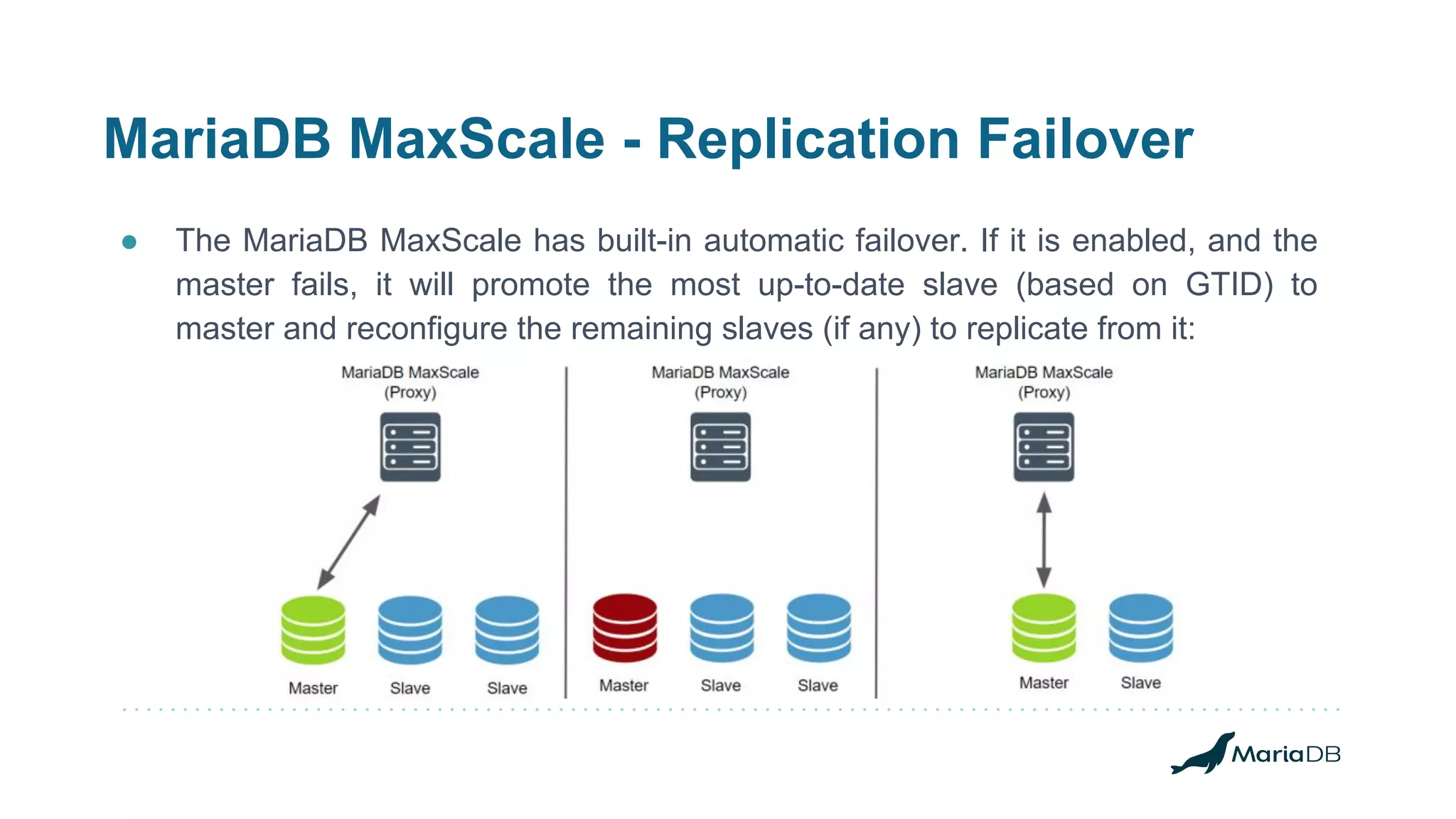
![MariaDB MaxScale - Replication Switchover
● When having operational issues with the current master or even having the
need to move the current master away, promoting one of the existing slaves as
the new master, the switchover is welcome;
○ replication_user=mariadb #: replication user
○ replication_password=ACEEF153D52F8391E3218F9F2B259EAD #: replication password
○ switchover_timeout=90 #: time to complete
● There is a command to call out a monitor module so the switchover happens:
$ maxctrl call command mariadbmon switchover replication-monitor opmdb02
OK
#: what does the maxscale log says?
2019-01-06 20:29:14.596 notice : (redirect_slaves_ex): All redirects successful.
2019-01-06 20:29:14.607 notice : (manual_switchover): Switchover 'opmdb01' -> 'opmdb02' performed.
2019-01-06 20:29:14.765 notice : (mon_log_state_change): Server changed state: opmdb01[10.0.0.11:3306]: new_slave.
[Master, Running] -> [Slave, Running]
2019-01-06 20:29:14.765 notice : (mon_log_state_change): Server changed state: opmdb02[10.0.0.12:3306]:
new_master. [Slave, Running] -> [Master, Running]](https://image.slidesharecdn.com/usingallofthehighavailabilityoptionsinmariadb-190307011159/75/Using-all-of-the-high-availability-options-in-MariaDB-17-2048.jpg)
![MariaDB MaxScale - Replication Failover
● The MariaDBMon monitor is configured with:
○ failcount=5 #: number of passes/checks if a server failed
○ monitor_interval=1000 #: time in ms for each of the passes
○ auto_failover=true #: if the automatic failover is enabled
○ failover_timeout=10 #: time in secs the failover ops has to complete
● The formula for the failover to happen, though, is:
#: automatric_failover = monitor_interval * failcount
2018-01-12 20:19:39 error : Monitor was unable to connect to server [192.168.50.13]:3306
: "Can't connect to MySQL server on '192.168.50.13' (115)"
2018-01-12 20:19:44 warning: [mariadbmon] Master has failed. If master status does not
change in 5 monitor passes, failover begins.](https://image.slidesharecdn.com/usingallofthehighavailabilityoptionsinmariadb-190307011159/75/Using-all-of-the-high-availability-options-in-MariaDB-18-2048.jpg)
![MariaDB MaxScale - Replication Rejoin
● When auto_rejoin is enabled, the monitor will rejoin any standalone database
servers or any slaves replicating from a relay master to the main cluster:
2019-01-04 19:54:25.266 notice : (mon_log_state_change): Server changed state: opmdb01[10.0.0.11:3306]:
server_up. [Down] -> [Running]
2019-01-04 19:54:25.277 notice : (do_rejoin): Directing standalone server 'opmdb01' to replicate from
'opmdb02'.
2019-01-04 19:54:25.295 notice : (create_start_slave): Slave connection from opmdb01 to [10.0.0.12]:3306
created and started.
2019-01-04 19:54:25.295 notice : (handle_auto_rejoin): 1 server(s) redirected or rejoined the cluster.
2019-01-04 19:54:25.764 notice : (mon_log_state_change): Server changed state: opmdb01[10.0.0.11:3306]:
new_slave. [Running] -> [Slave, Running]](https://image.slidesharecdn.com/usingallofthehighavailabilityoptionsinmariadb-190307011159/75/Using-all-of-the-high-availability-options-in-MariaDB-19-2048.jpg)
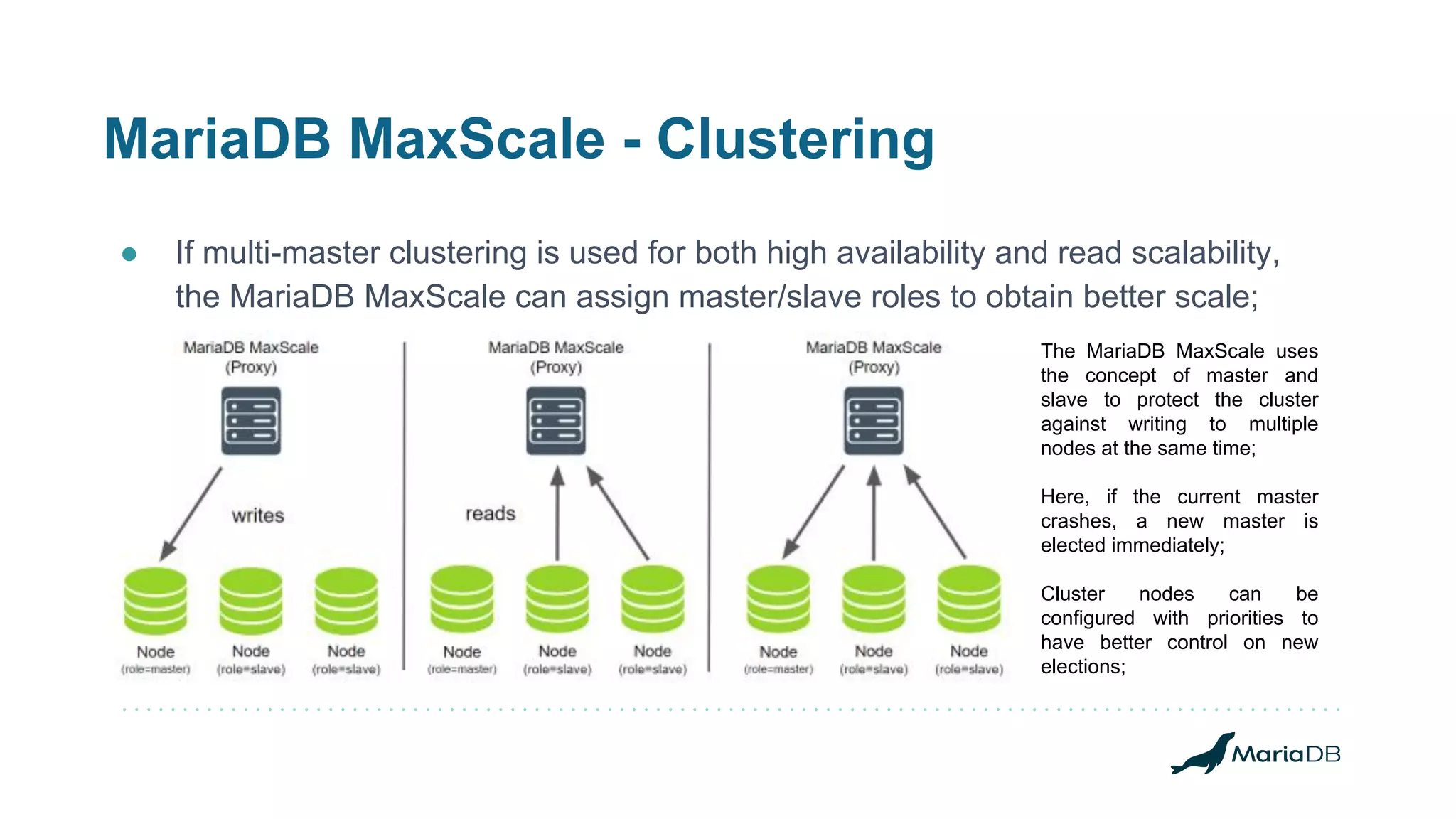



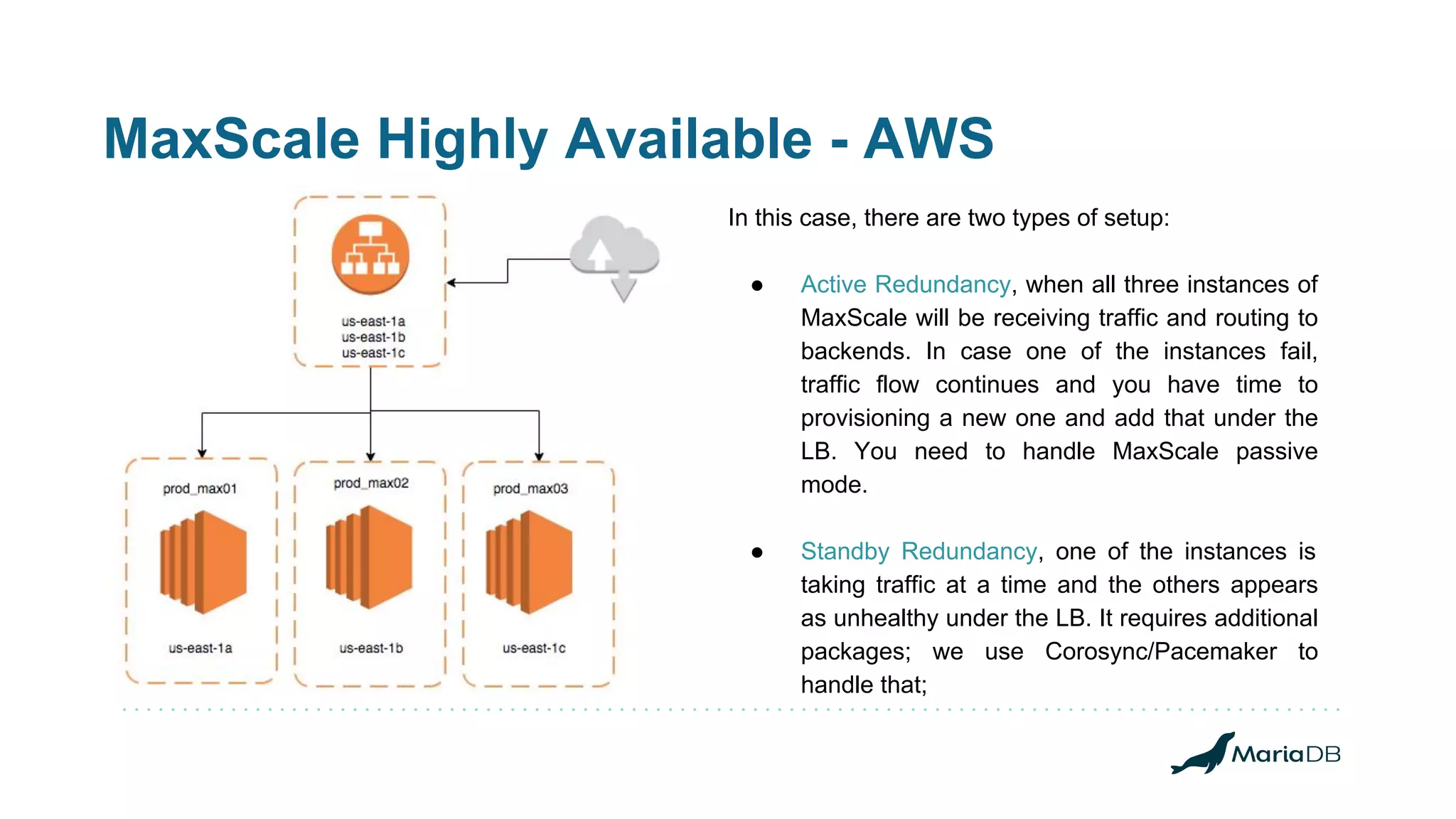




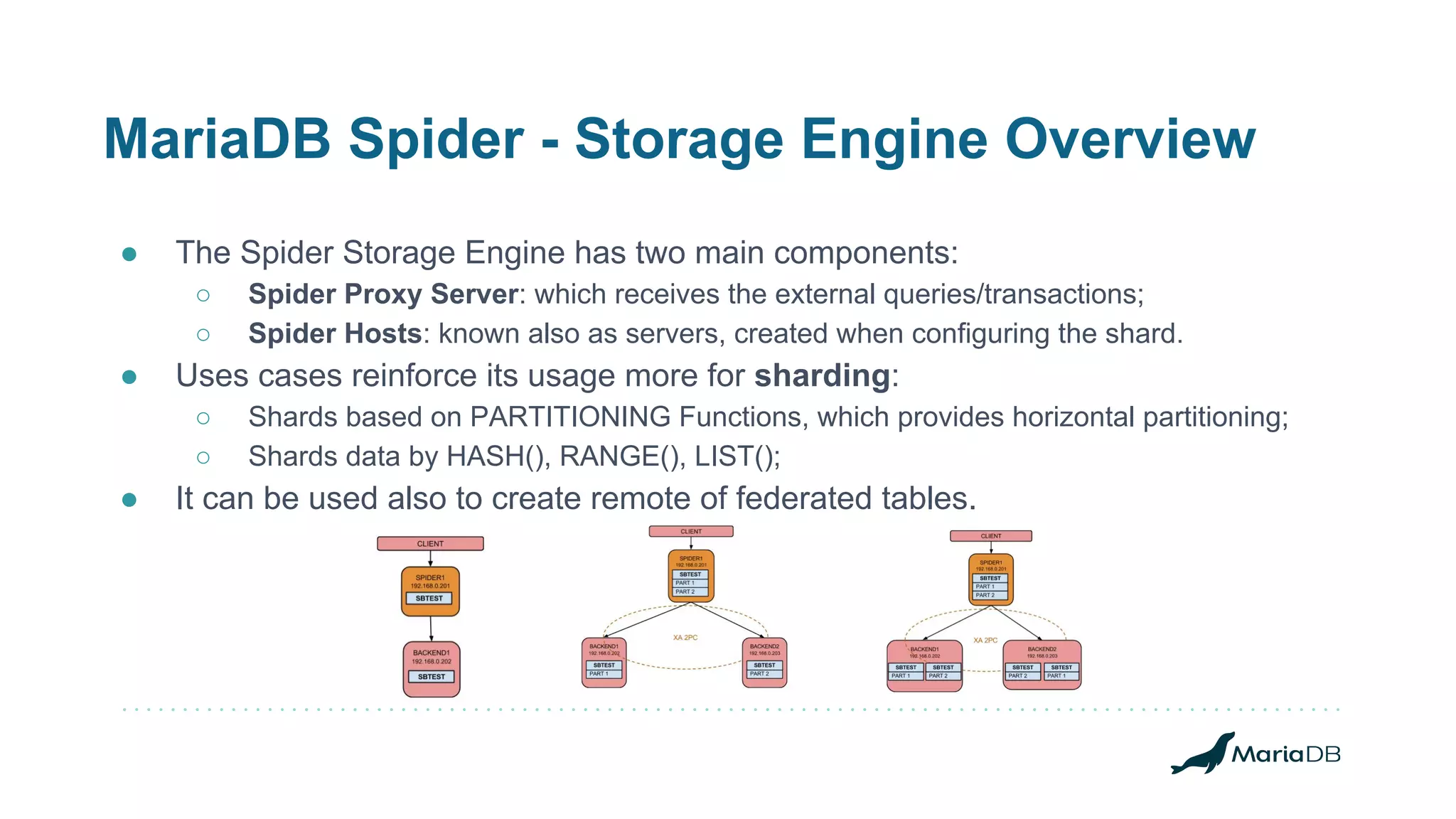
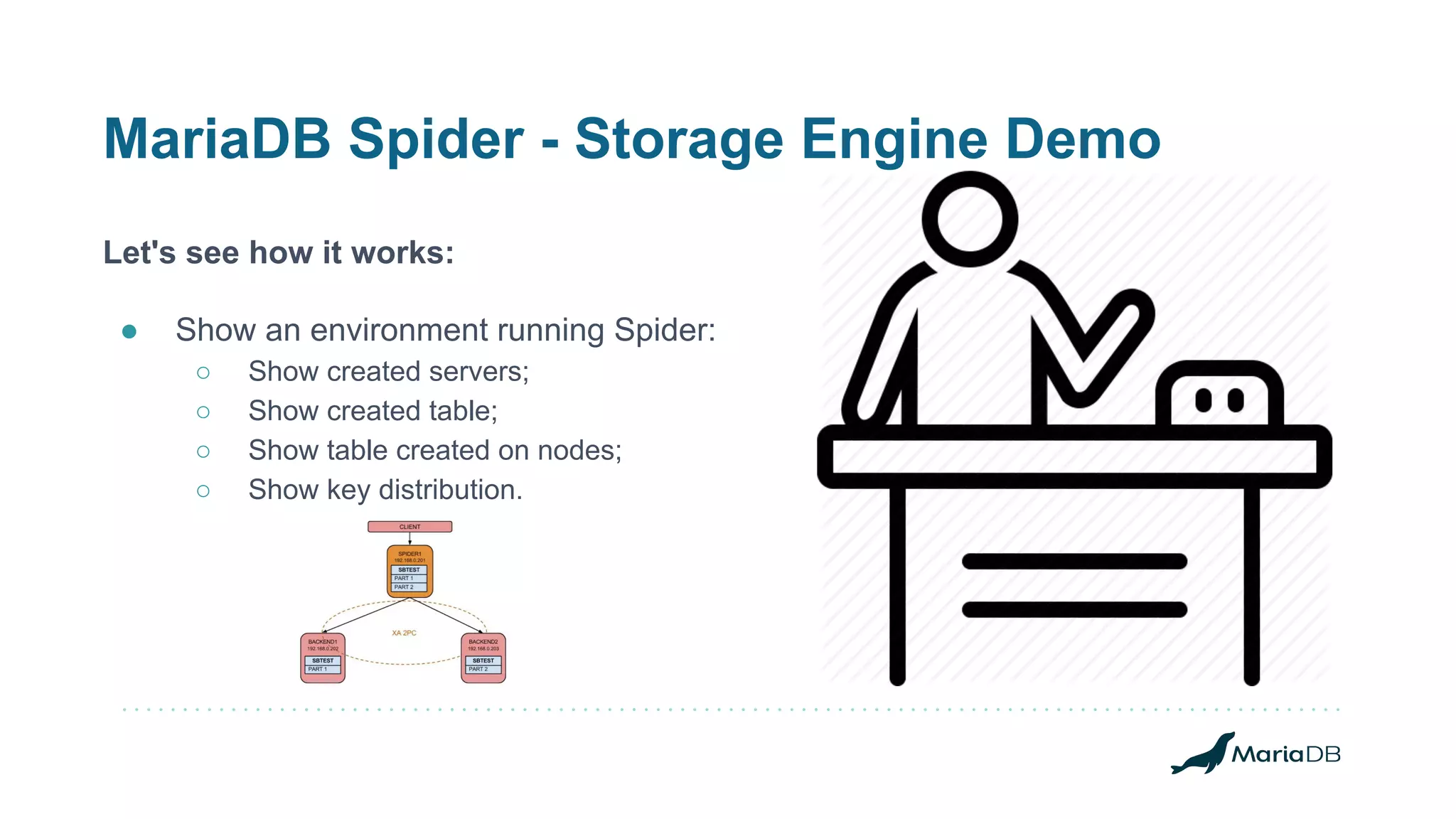


MariaDB Corporation offers high availability options including replication, clustering, and fault tolerance through various products like MaxScale and Spider. The document details the features, configurations, and strategies for achieving operational continuity and performance with MariaDB's database solutions, catering to both transactional and analytical workloads. It highlights the technical expertise of team lead Wagner Bianchi in maintaining and optimizing complex environments utilizing these high availability options.

















![[2018] MySQL 이중화 진화기](https://cdn.slidesharecdn.com/ss_thumbnails/cloudinfra03-190131073325-thumbnail.jpg?width=640&height=640&fit=bounds)





































































