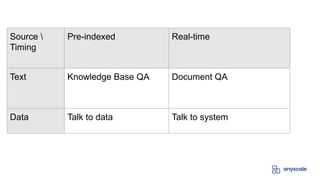
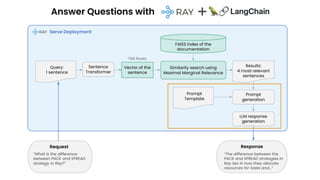
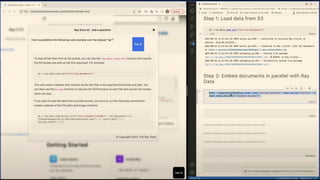
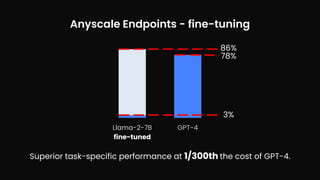
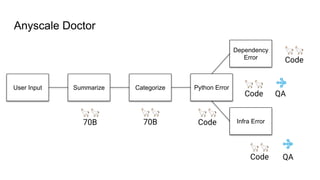
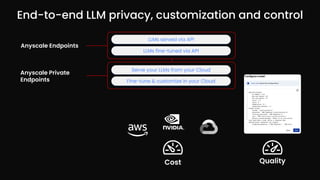
The document outlines various use case patterns for deploying large language models (LLMs) in organizations, with a focus on tasks like summarization, knowledge base questioning, and document questioning. It describes the capabilities of AnyScale's services, including cost efficiency and customization options for LLM deployment on their scalable platform. The document also highlights the importance of effective indexing and retrieval approaches to enhance LLM performance and prevent issues like misinformation.










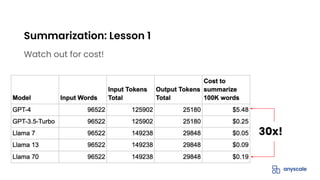
![LLMs are very good at summarizing
When GPT-3 came out, it outperformed existing engineered
solutions
Easy: prompt is
- Please summarize this into x bullet points
- Stick to the facts in the document
- Leave out irrelevant parts
- [Optional] Particularly focus on topics A, B and C
Summarization](https://image.slidesharecdn.com/usecasepatternsforllmapplications1-231114195946-8083c901/85/Use-Case-Patterns-for-LLM-Applications-1-pdf-11-320.jpg)