Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
hoxo_m
21,889 views
非制約最小二乗密度比推定法 uLSIF を用いた外れ値検出
「異常検知と変化検知」 輪読会 第11章 密度比推定による異常検知 http://connpass.com/event/35625/ LT 資料
Data & Analytics
◦
Read more
20
Save
Share
Embed
Embed presentation
1
/ 52
2
/ 52
3
/ 52
4
/ 52
5
/ 52
6
/ 52
7
/ 52
8
/ 52
9
/ 52
10
/ 52
11
/ 52
Most read
12
/ 52
13
/ 52
14
/ 52
15
/ 52
16
/ 52
Most read
17
/ 52
18
/ 52
19
/ 52
20
/ 52
21
/ 52
22
/ 52
23
/ 52
24
/ 52
25
/ 52
26
/ 52
27
/ 52
28
/ 52
Most read
29
/ 52
30
/ 52
31
/ 52
32
/ 52
33
/ 52
34
/ 52
35
/ 52
36
/ 52
37
/ 52
38
/ 52
39
/ 52
40
/ 52
41
/ 52
42
/ 52
43
/ 52
44
/ 52
45
/ 52
46
/ 52
47
/ 52
48
/ 52
49
/ 52
50
/ 52
51
/ 52
52
/ 52
More Related Content
PPTX
Transformerを雰囲気で理解する
by
AtsukiYamaguchi1
PDF
研究効率化Tips Ver.2
by
cvpaper. challenge
PDF
深層生成モデルと世界モデル
by
Masahiro Suzuki
PDF
ゼロから始める転移学習
by
Yahoo!デベロッパーネットワーク
PPTX
【DL輪読会】Scaling Laws for Neural Language Models
by
Deep Learning JP
PPTX
ようやく分かった!最尤推定とベイズ推定
by
Akira Masuda
PDF
モデルではなく、データセットを蒸留する
by
Takahiro Kubo
PDF
【DL輪読会】Implicit Behavioral Cloning
by
Deep Learning JP
Transformerを雰囲気で理解する
by
AtsukiYamaguchi1
研究効率化Tips Ver.2
by
cvpaper. challenge
深層生成モデルと世界モデル
by
Masahiro Suzuki
ゼロから始める転移学習
by
Yahoo!デベロッパーネットワーク
【DL輪読会】Scaling Laws for Neural Language Models
by
Deep Learning JP
ようやく分かった!最尤推定とベイズ推定
by
Akira Masuda
モデルではなく、データセットを蒸留する
by
Takahiro Kubo
【DL輪読会】Implicit Behavioral Cloning
by
Deep Learning JP
What's hot
PDF
Bayesian Neural Networks : Survey
by
tmtm otm
PDF
機械学習モデルの判断根拠の説明
by
Satoshi Hara
PPTX
【DL輪読会】High-Resolution Image Synthesis with Latent Diffusion Models
by
Deep Learning JP
PDF
最適化超入門
by
Takami Sato
PPTX
【DL輪読会】マルチモーダル 基盤モデル
by
Deep Learning JP
PDF
Layer Normalization@NIPS+読み会・関西
by
Keigo Nishida
PPTX
CatBoost on GPU のひみつ
by
Takuji Tahara
PPTX
変分ベイズ法の説明
by
Haruka Ozaki
PDF
Jubatus Casual Talks #2 異常検知入門
by
Shohei Hido
PDF
4 データ間の距離と類似度
by
Seiichi Uchida
PDF
SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜
by
SSII
PDF
[DL輪読会]ICLR2020の分布外検知速報
by
Deep Learning JP
PDF
深層学習による自然言語処理入門: word2vecからBERT, GPT-3まで
by
Yahoo!デベロッパーネットワーク
PPTX
[DL輪読会]Objects as Points
by
Deep Learning JP
PDF
【メタサーベイ】数式ドリブン教師あり学習
by
cvpaper. challenge
PPTX
Swin Transformer (ICCV'21 Best Paper) を完璧に理解する資料
by
Yusuke Uchida
PDF
三次元点群を取り扱うニューラルネットワークのサーベイ
by
Naoya Chiba
PDF
SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法
by
SSII
PPTX
[DL輪読会]Focal Loss for Dense Object Detection
by
Deep Learning JP
PPTX
Active Learning と Bayesian Neural Network
by
Naoki Matsunaga
Bayesian Neural Networks : Survey
by
tmtm otm
機械学習モデルの判断根拠の説明
by
Satoshi Hara
【DL輪読会】High-Resolution Image Synthesis with Latent Diffusion Models
by
Deep Learning JP
最適化超入門
by
Takami Sato
【DL輪読会】マルチモーダル 基盤モデル
by
Deep Learning JP
Layer Normalization@NIPS+読み会・関西
by
Keigo Nishida
CatBoost on GPU のひみつ
by
Takuji Tahara
変分ベイズ法の説明
by
Haruka Ozaki
Jubatus Casual Talks #2 異常検知入門
by
Shohei Hido
4 データ間の距離と類似度
by
Seiichi Uchida
SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜
by
SSII
[DL輪読会]ICLR2020の分布外検知速報
by
Deep Learning JP
深層学習による自然言語処理入門: word2vecからBERT, GPT-3まで
by
Yahoo!デベロッパーネットワーク
[DL輪読会]Objects as Points
by
Deep Learning JP
【メタサーベイ】数式ドリブン教師あり学習
by
cvpaper. challenge
Swin Transformer (ICCV'21 Best Paper) を完璧に理解する資料
by
Yusuke Uchida
三次元点群を取り扱うニューラルネットワークのサーベイ
by
Naoya Chiba
SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法
by
SSII
[DL輪読会]Focal Loss for Dense Object Detection
by
Deep Learning JP
Active Learning と Bayesian Neural Network
by
Naoki Matsunaga
Viewers also liked
PDF
20140329 tokyo r lt 「カーネルとsvm」
by
tetsuro ito
PDF
差分プライベート最小二乗密度比推定
by
Hiroshi Nakagawa
PDF
グラフィカル Lasso を用いた異常検知
by
Yuya Takashina
PDF
SMO徹底入門 - SVMをちゃんと実装する
by
sleepy_yoshi
PDF
協調フィルタリング入門
by
hoxo_m
PDF
ディープラーニングの産業応用とそれを支える技術
by
Shohei Hido
PDF
機械学習モデルフォーマットの話:さようならPMML、こんにちはPFA
by
Shohei Hido
PDF
シンギュラリティを知らずに機械学習を語るな
by
hoxo_m
PDF
FIT2012招待講演「異常検知技術のビジネス応用最前線」
by
Shohei Hido
20140329 tokyo r lt 「カーネルとsvm」
by
tetsuro ito
差分プライベート最小二乗密度比推定
by
Hiroshi Nakagawa
グラフィカル Lasso を用いた異常検知
by
Yuya Takashina
SMO徹底入門 - SVMをちゃんと実装する
by
sleepy_yoshi
協調フィルタリング入門
by
hoxo_m
ディープラーニングの産業応用とそれを支える技術
by
Shohei Hido
機械学習モデルフォーマットの話:さようならPMML、こんにちはPFA
by
Shohei Hido
シンギュラリティを知らずに機械学習を語るな
by
hoxo_m
FIT2012招待講演「異常検知技術のビジネス応用最前線」
by
Shohei Hido
Similar to 非制約最小二乗密度比推定法 uLSIF を用いた外れ値検出
PPTX
DLLab 異常検知ナイト 資料 20180214
by
Kosuke Nakago
PDF
数理情報学特別講義ⅰ輪講
by
Shengbo Xu
PDF
異常検知と変化検知で復習するPRML
by
Katsuya Ito
PDF
正則化による尤度比推定法を応用した多値分類器の改良
by
MasatoKikuchi4
PPTX
異常検知と変化検知の1~3章をまとめてみた
by
Takahiro Yoshizawa
PPTX
密度比推定による時系列データの異常検知
by
- Core Concept Technologies
PDF
異常検知と変化検知 第4章 近傍法による異常検知
by
Ken'ichi Matsui
PPT
ma92007id395
by
matsushimalab
PDF
構造方程式モデルによる因果探索と非ガウス性
by
Shiga University, RIKEN
PDF
修士論文発表:「非負値行列分解における漸近的Bayes汎化誤差」
by
Naoki Hayashi
PDF
【論文レベルで理解しよう!】 欠測値処理編
by
ARISE analytics
PPTX
Angle-Based Outlier Detection周辺の論文紹介
by
Naotaka Yamada
PDF
Anomaly detection survey
by
ぱんいち すみもと
PPTX
PRML4.3
by
hiroki yamaoka
PPTX
DSB2019振り返り会:あのにっくき QWK を閾値調整なしで攻略した(かった)
by
Takuji Tahara
PDF
One Class SVMを用いた異常値検知
by
Yuto Mori
PDF
R実践 機械学習による異常検知 02
by
akira_11
PDF
異常検知と変化検知 9章 部分空間法による変化点検知
by
hagino 3000
PDF
外れ値
by
Shintaro Fukushima
PDF
Deep Learning Lab 異常検知入門
by
Shohei Hido
DLLab 異常検知ナイト 資料 20180214
by
Kosuke Nakago
数理情報学特別講義ⅰ輪講
by
Shengbo Xu
異常検知と変化検知で復習するPRML
by
Katsuya Ito
正則化による尤度比推定法を応用した多値分類器の改良
by
MasatoKikuchi4
異常検知と変化検知の1~3章をまとめてみた
by
Takahiro Yoshizawa
密度比推定による時系列データの異常検知
by
- Core Concept Technologies
異常検知と変化検知 第4章 近傍法による異常検知
by
Ken'ichi Matsui
ma92007id395
by
matsushimalab
構造方程式モデルによる因果探索と非ガウス性
by
Shiga University, RIKEN
修士論文発表:「非負値行列分解における漸近的Bayes汎化誤差」
by
Naoki Hayashi
【論文レベルで理解しよう!】 欠測値処理編
by
ARISE analytics
Angle-Based Outlier Detection周辺の論文紹介
by
Naotaka Yamada
Anomaly detection survey
by
ぱんいち すみもと
PRML4.3
by
hiroki yamaoka
DSB2019振り返り会:あのにっくき QWK を閾値調整なしで攻略した(かった)
by
Takuji Tahara
One Class SVMを用いた異常値検知
by
Yuto Mori
R実践 機械学習による異常検知 02
by
akira_11
異常検知と変化検知 9章 部分空間法による変化点検知
by
hagino 3000
外れ値
by
Shintaro Fukushima
Deep Learning Lab 異常検知入門
by
Shohei Hido
More from hoxo_m
PDF
Shinyユーザのための非同期プログラミング入門
by
hoxo_m
PDF
Prophet入門【理論編】Facebookの時系列予測ツール
by
hoxo_m
PDF
Prophet入門【R編】Facebookの時系列予測ツール
by
hoxo_m
PDF
機械学習のためのベイズ最適化入門
by
hoxo_m
PDF
学習係数
by
hoxo_m
PDF
Prophet入門【Python編】Facebookの時系列予測ツール
by
hoxo_m
PDF
AJAXサイトの情報をWebスクレイピング
by
hoxo_m
PPTX
高速なガンマ分布の最尤推定法について
by
hoxo_m
PDF
経験過程
by
hoxo_m
PDF
確率論基礎
by
hoxo_m
PDF
トピックモデルの評価指標 Perplexity とは何なのか?
by
hoxo_m
PDF
階層モデルの分散パラメータの事前分布について
by
hoxo_m
PDF
トピックモデルの評価指標 Coherence 研究まとめ #トピ本
by
hoxo_m
PDF
トピックモデルによる統計的潜在意味解析読書会 3.7 評価方法 - 3.9 モデル選択 #トピ本
by
hoxo_m
PDF
データの不備を統計的に見抜く (Gelman’s secret weapon)
by
hoxo_m
PDF
カップルが一緒にお風呂に入る割合をベイズ推定してみた
by
hoxo_m
PDF
Stan で欠測データの相関係数を推定してみた
by
hoxo_m
PDF
チェビシェフの不等式
by
hoxo_m
PDF
swirl パッケージでインタラクティブ学習
by
hoxo_m
PPTX
RPubs とその Bot たち
by
hoxo_m
Shinyユーザのための非同期プログラミング入門
by
hoxo_m
Prophet入門【理論編】Facebookの時系列予測ツール
by
hoxo_m
Prophet入門【R編】Facebookの時系列予測ツール
by
hoxo_m
機械学習のためのベイズ最適化入門
by
hoxo_m
学習係数
by
hoxo_m
Prophet入門【Python編】Facebookの時系列予測ツール
by
hoxo_m
AJAXサイトの情報をWebスクレイピング
by
hoxo_m
高速なガンマ分布の最尤推定法について
by
hoxo_m
経験過程
by
hoxo_m
確率論基礎
by
hoxo_m
トピックモデルの評価指標 Perplexity とは何なのか?
by
hoxo_m
階層モデルの分散パラメータの事前分布について
by
hoxo_m
トピックモデルの評価指標 Coherence 研究まとめ #トピ本
by
hoxo_m
トピックモデルによる統計的潜在意味解析読書会 3.7 評価方法 - 3.9 モデル選択 #トピ本
by
hoxo_m
データの不備を統計的に見抜く (Gelman’s secret weapon)
by
hoxo_m
カップルが一緒にお風呂に入る割合をベイズ推定してみた
by
hoxo_m
Stan で欠測データの相関係数を推定してみた
by
hoxo_m
チェビシェフの不等式
by
hoxo_m
swirl パッケージでインタラクティブ学習
by
hoxo_m
RPubs とその Bot たち
by
hoxo_m
非制約最小二乗密度比推定法 uLSIF を用いた外れ値検出
1.
【論論⽂文紹介】 ⾮非制約最⼩小⼆二乗密度度⽐比推定法 uLSIF を⽤用いた外れ値検出 @hoxo_m 2016/07/21 1
2.
本⽇日紹介する論論⽂文 • “Statistical Outlier
Detection Using Direct Density Ratio Estimation” 直接密度度⽐比推定を⽤用いた統計的外れ値検出 • Shohei Hido (⽐比⼾戸 将平) et al. 元 IBM Researcher 現 PFN Chief Research Officer • Knowledge and Information Systems 2011 2
3.
この論論⽂文を選んだ理理由 • 井⼿手剛 杉⼭山将『異異常検知と変化検知』 •
Chapter 11 密度度⽐比推定による異異常検知 – カルバック・ライブラー密度度⽐比推定法 • KLIEP (Sugiyama+ 2008) – 最⼩小2乗密度度⽐比推定法 • LSIF (Kanamori+ 2009) • ⾮非制約最⼩小⼆二乗密度度⽐比推定法 – uLSIF (Kanamori+ 2009) ➡︎ 本に載ってない最新⼿手法が! 3
4.
論論⽂文概要 • 【内容】 統計的外れ値検出法として、既存⼿手法お よび確率率率密度度⽐比を⽤用いた⼿手法を網羅羅的に ⽐比較した • 【結論論】 確率率率密度度⽐比を
uLSIF で求める⼿手法が、 精度度が良良く、速度度も速い 4
5.
発表の流流れ 1. 研究背景 2. 確率率率密度度⽐比による外れ値検出 3.
直接密度度⽐比推定法の⽐比較 4. やってみた 5. 既存⼿手法 6. 実験 5
6.
研究背景 • 外れ値検出の問題として、inlier-based outlier detection
という問題がある • この問題に対して、One-Class SVM や Local Outlier Factor が使われる • これに対して次を提案する 1. 密度度⽐比を外れ値のスコアに使う 2. 密度度⽐比の推定法に uLSIF を使う 6
7.
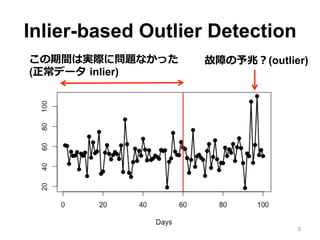
Inlier-based Outlier Detection •
外れ値を検出したい場合、外れ値を含ま ない (inlier) データを持っている場合が 多い • 例例:機器の正常データ • 外れ値を含まないデータ (inlier) と外れ値 を含むデータ (contains outlier) を持って いる場合に、外れ値を検出する問題を扱 う 7
8.
Inlier-based Outlier Detection 8 この期間は実際に問題なかった (正常データ
inlier) 故障の予兆?(outlier)
9.
発表の流流れ 1. 研究背景 2. 確率率率密度度⽐比による外れ値検出 3.
直接密度度⽐比推定法の⽐比較 4. やってみた 5. 既存⼿手法 6. 実験 9
10.
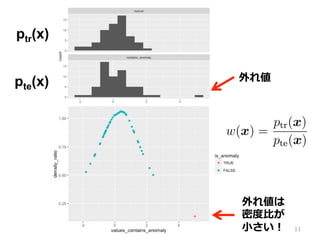
問題設定 • 外れ値を含まないデータ xtr •
外れ値を含むデータ xte • このとき xte の中で外れ値を検出したい • 提案①: 外れ値のスコアとして確率率率密度度⽐比を使う 10
11.
11 ptr(x) pte(x) 外れ値は 密度度⽐比が ⼩小さい! 外れ値
12.
密度度⽐比を⽤用いた外れ値検出 • 外れ値は密度度⽐比が⼩小さくなる • 密度度⽐比を外れ値のスコアとしたい •
密度度⽐比を求める⼿手法は⾊色々ある • 提案②: 密度度⽐比を求める⽅方法として uLSIF を使う 12
13.
発表の流流れ 1. 研究背景 2. 確率率率密度度⽐比による外れ値検出 3.
直接密度度⽐比推定法の⽐比較 4. やってみた 5. 既存⼿手法 6. 実験 13
14.
密度度⽐比を割り算で求めてはいけない • xtr と
xte それぞれの確率率率密度度を求め、 それを割り算する ⇨ 誤差が⼤大きい! • バプニックの原理理(Vapnik's principle) 「ある問題を解くときにそれよりも⼀一般的な問 題を途中段階で得べきでない」 • 密度度⽐比 w(x) を直接推定する 14
15.
直接密度度⽐比推定法 • 直接密度度⽐比を推定する⼿手法を紹介する ① KMM ②
LogReg ③ KLIEP ④ LSIF ⑤ uLSIF 15
16.
基本的な考え⽅方 • 密度度⽐比 • 下式両辺が同じになるように
w(x) を推定 16 ➡ 同じとは何か?の違いが⼿手法の違いとなる
17.
① KMM (Kernel
Mean Matching) • Huang et al. 2007 • 再⽣生核ヒルベルト空間上で ptr(x) と w(x)pte(x) の期待値の差を最⼩小にする • w(x) の関数形でなく xte における w を推定 • クロスバリデーションが使えないのが⽋欠点 17
18.
② Logistic Regression
(LogReg) • 左項 p(η=-1) / p(η=1) = nte / ntr で推定 • 右項の p(η | x) はそれぞれロジスティック 回帰で求める 18
19.
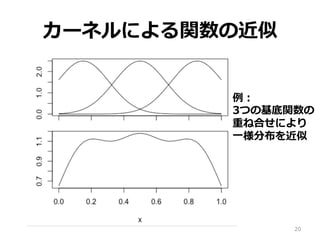
③ KLIEP • カルバックライブラー密度度⽐比推定法 •
密度度⽐比を次の式で近似 • ptr(x) と w(x)pte(x) の KL ダイバージェン スを最⼩小にする 19 カーネル
20.
20 カーネルによる関数の近似 例例: 3つの基底関数の 重ね合せにより ⼀一様分布を近似
21.
④ LSIF • Least-Square
Importance Fitting • w(x) と w-hat(x) の2乗誤差を最⼩小にする 21 凸⼆二次計画問題
22.
⑤ uLSIF (unconstrained
LSIF) • LSIF の α ≧ 0 の制約を除去 • 解析的に解が求まる 22 ︎ α < 0 となった場合は強制的に 0 にする
23.
⑤ uLSIF (unconstrained
LSIF) • LOOCV も解析的に求まる • カーネルパラメータの選択が⾼高速化! 23
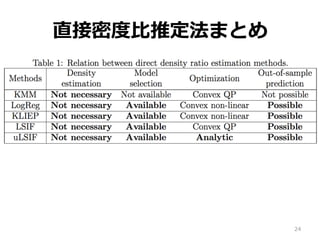
24.
直接密度度⽐比推定法まとめ 24
25.
直接密度度⽐比推定法の⽐比較 • KMM ⇨
CV ができない • LogReg & KLIEP ⇨ CV できるけど遅い • LSIF ⇨ CV 可 & 速い、けど解が不不安定 • uLSIF ⇨ CV 可 & 速い & 安定 • 結論論: uLSIF 最強 25
26.
発表の流流れ 1. 研究背景 2. 確率率率密度度⽐比による外れ値検出 3.
直接密度度⽐比推定法の⽐比較 4. やってみた 5. 既存⼿手法 6. 実験 26
27.
やってみた • 確率率率密度度⽐比による外れ値検出法を提案し たが、本当に検出できるのかやってみた 27
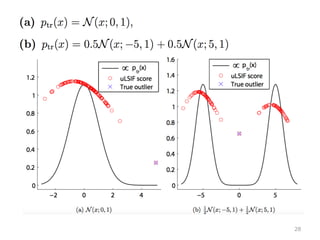
28.
28
29.
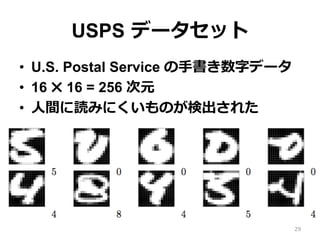
USPS データセット • U.S.
Postal Service の⼿手書き数字データ • 16 ✖ 16 = 256 次元 • ⼈人間に読みにくいものが検出された 29
30.
発表の流流れ 1. 研究背景 2. 確率率率密度度⽐比による外れ値検出 3.
直接密度度⽐比推定法の⽐比較 4. やってみた 5. 既存⼿手法 6. 実験 30
31.
既存⼿手法 • 提案⼿手法が良良いのか⽐比較実験を⾏行行いたい • 密度度⽐比を使った外れ値検出⼿手法だけでな く、他の⼿手法も⽐比較したい ① Kernel
Density Estimator (KDE) ② One-class SVM (OSVM) ③ Local Outlier Factor (LOF) 31
32.
① Kernel Density
Estimator (KDE) • pnu(x) と pde(x) の密度度をそれぞれ推定 • 割り算した値を密度度⽐比として、外れ値スコ アにする • 次元の呪いにより⾼高次元でうまくいかない 32
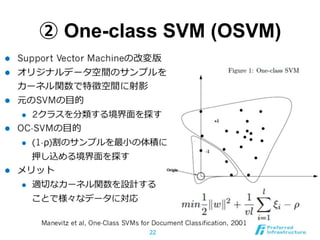
33.
② One-class SVM
(OSVM) 33
34.
③ Local Outlier
Factor (LOF) 34
35.
既存⼿手法との⽐比較 • 提案した uLSIF
を使った⽅方法は、 • ①KDE には勝つだろう • ②OSVM, ③LOF はパラメータ選択が必要 – OSVM ⇨ ガウスカーネルの σ – LOF ⇨ k-近傍の k • uLSIF は、LOOCV で最適なパラメータ選 択ができるのが強み。あと速い。 35
36.
発表の流流れ 1. 研究背景 2. 確率率率密度度⽐比による外れ値検出 3.
直接密度度⽐比推定法の⽐比較 4. やってみた 5. 既存⼿手法 6. 実験 36
37.
実験 • 3 つのデータセットに対して実験 ①
R ̈atsch’s ベンチマーク(⼆二値分類) ② ハードディスク異異常 (SMART) ③ ローンリスク (Real Finance) 37
38.
実験① • R ̈atsch’s
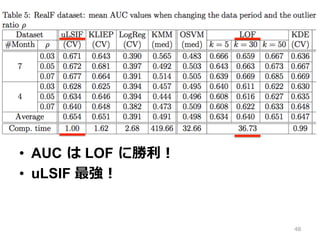
Benchmark Repository • ⼆二値分類データセット (12個) • 訓練データから負例例を全部消去 • テストデータには⽐比率率率 ρ で負例例を⼊入れる • 検出率率率(true positive) と 検出精度度(false positive) で ROC 曲線が描かれるので、 その AUC で評価する 38
39.
39 ⾒見見えない; ➡︎ ⼀一部抜粋 (次ページ)
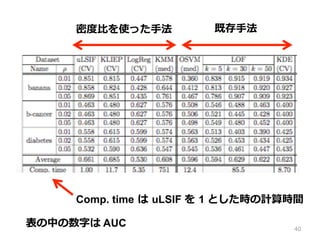
40.
40 既存⼿手法密度度⽐比を使った⼿手法 Comp. time は
uLSIF を 1 とした時の計算時間 表の中の数字は AUC
41.
• uLSIF はおおむね良良い •
KLIEP も良良いが遅い • LogReg は良良いときと悪いときがある 41
42.
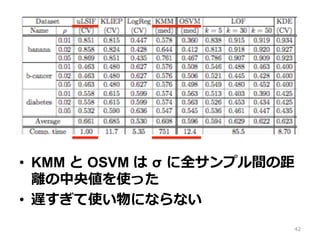
• KMM と
OSVM は σ に全サンプル間の距 離離の中央値を使った • 遅すぎて使い物にならない 42
43.
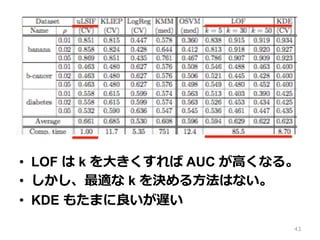
• LOF は
k を⼤大きくすれば AUC が⾼高くなる。 • しかし、最適な k を決める⽅方法はない。 • KDE もたまに良良いが遅い 43
44.
実験①まとめ • uLSIF は他の⼿手法と同じくらい良良い精度度 を出すし、なにより速い。 •
ooO( 精度度の⽐比較をしていたはずが、既存 ⼿手法遅すぎプギャー m9(^Д^) としか⾔言っ てないような・・ ) 44
45.
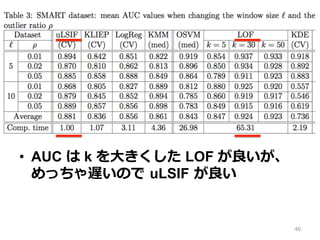
実験② • SMART データ •
ハードディスクのセルフモニタリング • 369 サンプル中 178 “good”, 191 “failed” • 59 変数中 25 個を使う (Murray+2005) • “good” だけの訓練データ • ρ だけ “failed” を混ぜたテストデータ 45
46.
• AUC は
k を⼤大きくした LOF が良良いが、 めっちゃ遅いので uLSIF が良良い 46
47.
実験③ • Real Finance
データ • ローン顧客の7ヶ⽉月間⾏行行動データ(11変数) • 6ヶ⽉月後にリスク “high”, “low” か判定 • これが正解データになる • 訓練 “low” のみ、テスト ρ だけ “high” • 7ヶ⽉月間のデータでリスク “high” を検出 • 4ヶ⽉月間のデータでリスク “high” を検出 47
48.
• AUC は
LOF に勝利利! • uLSIF 最強! 48
49.
まとめ • 密度度⽐比を⽤用いた外れ値検出⼿手法を提案 • 密度度⽐比推定には
uLSIF を使う • 解が解析的に求まるのでめっちゃ速い • ハイパーパラメータの選定も LOOCV で できるしめっちゃ速い • 既存⼿手法遅すぎ m9(^Д^) 49
50.
おまけ 50 • R で実装してみた
(densratioパッケージ) > install.packages("densratio") > vignette("densratio")
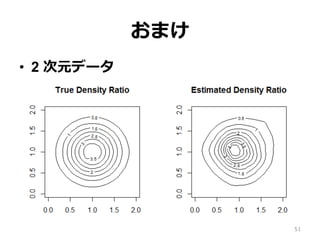
51.
おまけ • 2 次元データ 51
52.
参考⽂文献 • KLIEP Sugiyama, M.,
Suzuki, T., Nakajima, S., Kashima, H., von Bünau, P. & Kawanabe, M. Direct importance estimation for covariate shift adaptation. AISM 2008. • OSVM, LOF 「異異常検知技術のビジネス応⽤用最前線」 http://www.slideshare.net/shoheihido/fit2012 52

























































![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]ICLR2020の分布外検知速報](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2020ood-190927011524-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Objects as Points](https://cdn.slidesharecdn.com/ss_thumbnails/20190614centernetkuboshizuma-190614004246-thumbnail.jpg?width=640&height=640&fit=bounds)



![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Focal Loss for Dense Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/focalloss-180208092846-thumbnail.jpg?width=640&height=640&fit=bounds)

















































