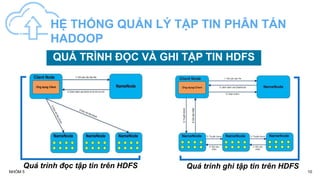
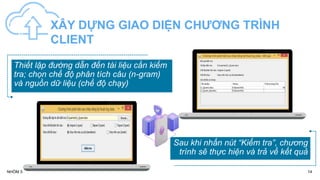
Tài liệu nghiên cứu tổng quan về dữ liệu lớn và ứng dụng của nó trong việc xử lý văn bản tiếng Việt, bao gồm các thuật toán tách từ, câu và so khớp mẫu. Nó giới thiệu về hệ thống quản lý tập tin phân tán Hadoop và giải thuật xử lý song song MapReduce, đồng thời đánh giá kết quả thực nghiệm với các ứng dụng trong việc phát hiện sao chép. Cuối cùng, tài liệu cũng đề xuất một số phương pháp và công cụ hỗ trợ trong phân tích dữ liệu lớn.

































![[123doc] - slide-phan-tich-thiet-ke-he-thong-bai-7.ppt](https://cdn.slidesharecdn.com/ss_thumbnails/123doc-slide-phan-tich-thiet-ke-he-thong-bai-7-251216161550-0d4588e4-thumbnail.jpg?width=640&height=640&fit=bounds)








