Download as PDF, PPTX
























































.
Apache Software Foundation. (2017). INTRODUCTION Everything you need to know about Kafka in 10 minutes. Apache Kafka.
[https://kafka.apache.org/intro](https://kafka.apache.org/intro).
Brewer, E. (2001). Lessons from giant-scale services IEEE Internet Computing 5(4), 46-55.
[https://dx.doi.org/10.1109/4236.939450](https://dx.doi.org/10.1109/4236.939450)
Brewer, E. (2012). CAP Twelve Years Later: How the “Rules” Have Changed Computer 45(2), 23-29.
[https://dx.doi.org/10.1109/mc.2012.37](https://dx.doi.org/10.1109/mc.2012.37)
Chen, M., Mao, S., & Liu, Y. (2014). Big data: A survey. Mobile networks and applications, 19(2), 171-209.
Dean, J., Ghemawat, S., Mehta, B. (2008). MapReduce: simplified data processing on large clusters Communications of the ACM 51(1), 107-113.
https://dx.doi.org/10.1145/1327452.1327492
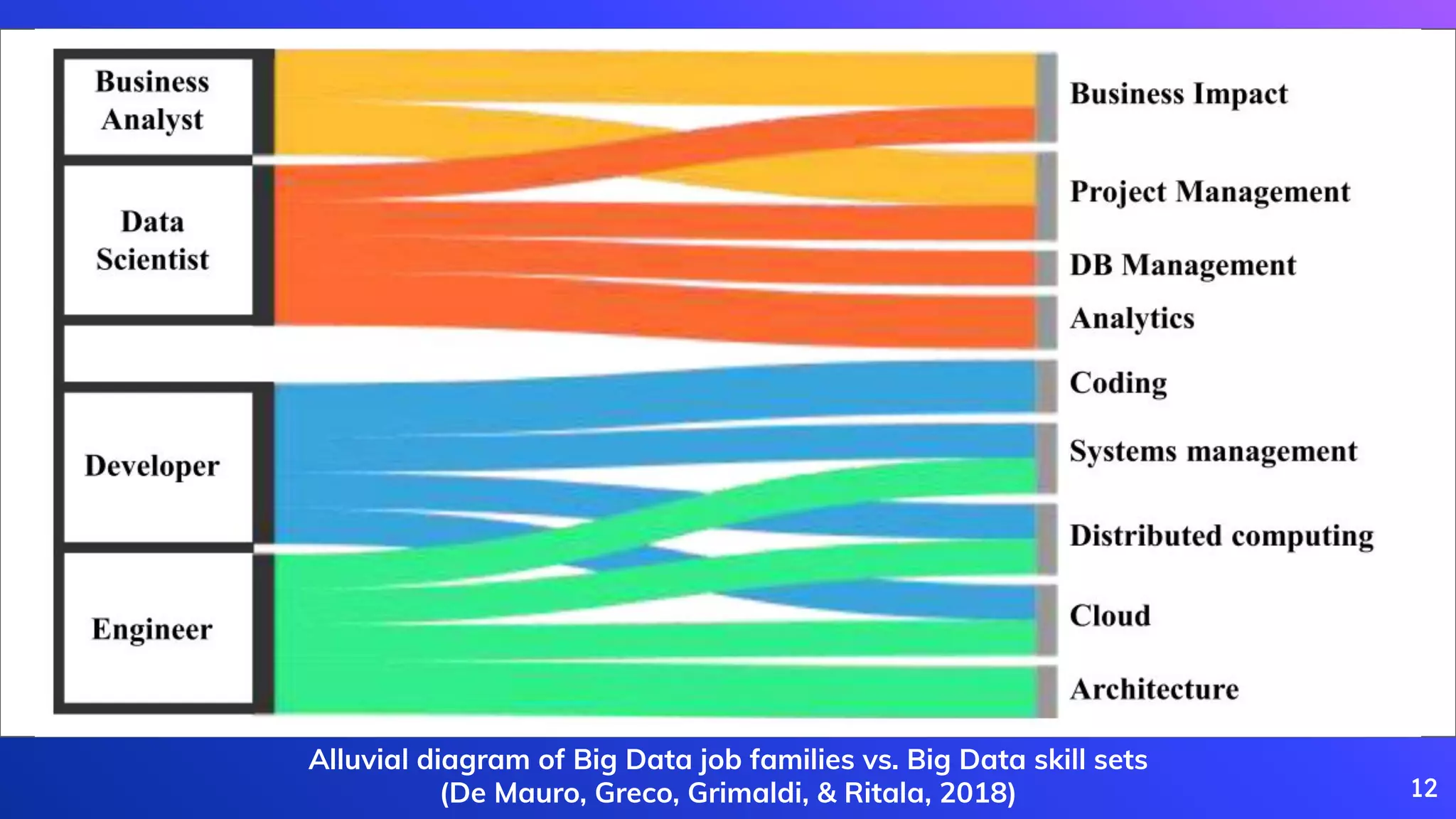
De Mauro, A., Greco, M., Grimaldi, M., & Ritala, P. (2018). Human resources for Big Data professions: A systematic classification of job roles and required skill sets.
Information Processing & Management, 54(5), 807-817.
Devopedia. 2020. "CAP Theorem." Version 4, April 30. Accessed 2020-09-14. https://devopedia.org/cap-theorem
Dixon, J. (2010, October 14). Pentaho, Hadoop, and Data Lakes. James Dixon’s Blog.
[https://jamesdixon.wordpress.com/2010/10/14/pentaho-hadoop-and-data-lakes/](https://jamesdixon.wordpress.com/2010/10/14/pentaho-hadoop-and-data-lakes/).
Feng, Z., Hui-Feng, X., Dong-Sheng, X., Yong-Heng, Z., & Fei, Y. (2013). Big data cleaning algorithms in cloud computing. International Journal of Online Engineering, 9(3),
77–81. [https://doi.org/10.3991/ijoe.v9i3.2765](https://doi.org/10.3991/ijoe.v9i3.2765)
Gray, J., & Shenoy, P. (2000). Rules of thumb in data engineering. Proceedings - International Conference on Data Engineering, 3–10.
[https://doi.org/10.1109/icde.2000.839382](https://doi.org/10.1109/icde.2000.839382)
97](https://image.slidesharecdn.com/theroleofdataengineeringindatascienceandanalyticspractice-200915114740/75/The-role-of-data-engineering-in-data-science-and-analytics-practice-96-2048.jpg)

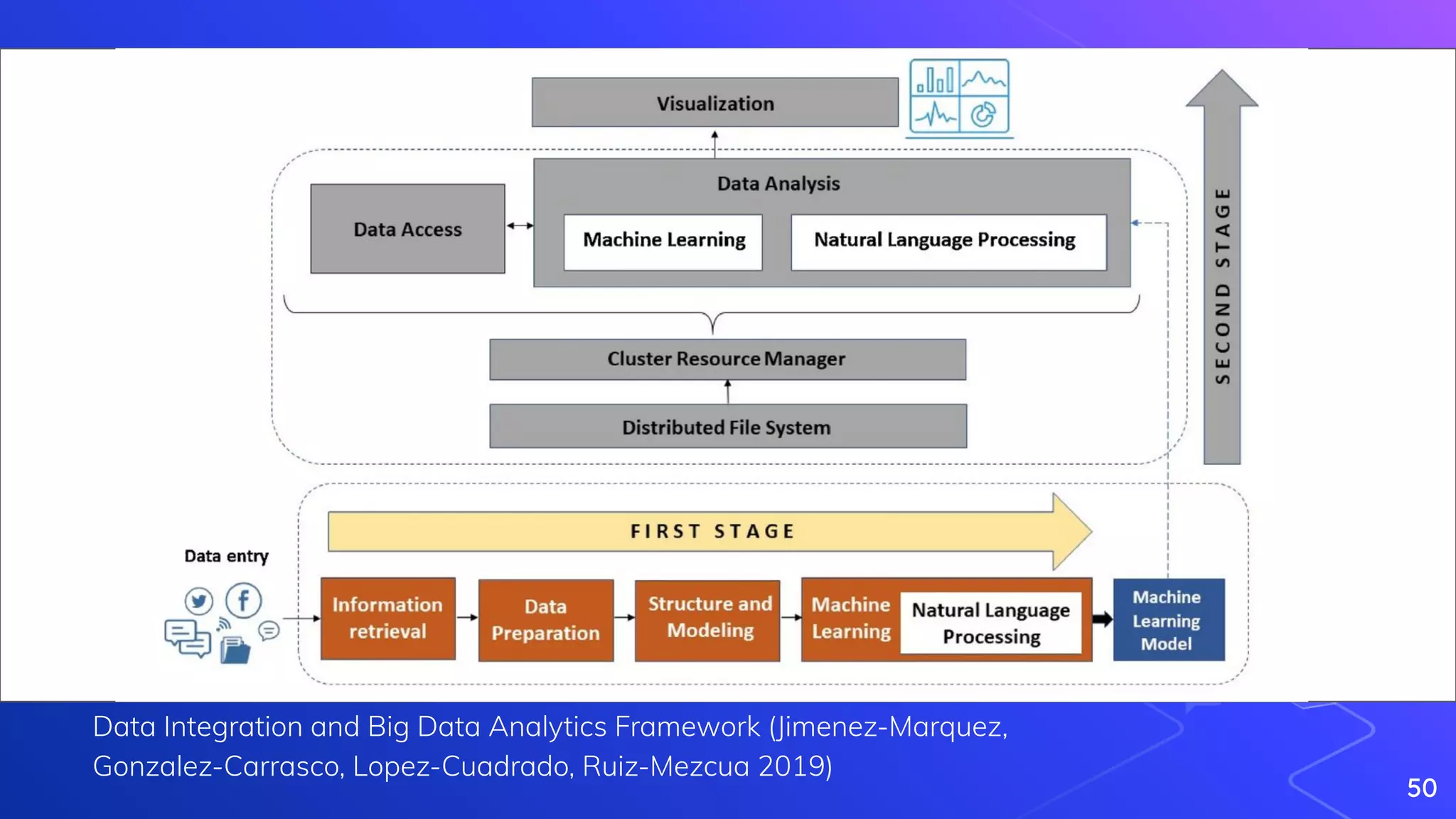
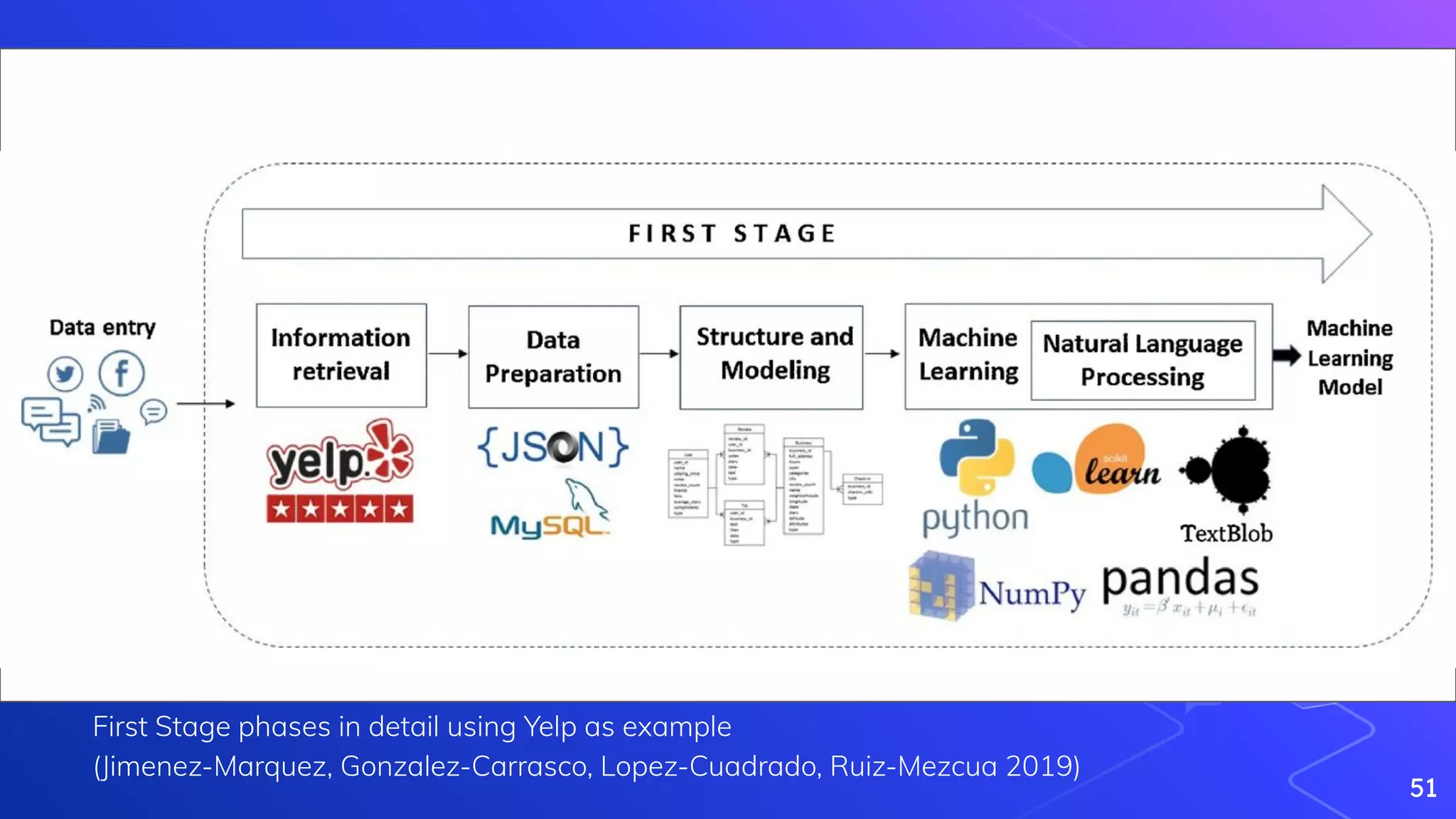
Jimenez-Marquez, J., Gonzalez-Carrasco, I., Lopez-Cuadrado, J., Ruiz-Mezcua, B. (2019). Towards a big data framework for analyzing social media content International
Journal of Information Management 44(), 1-12. [https://dx.doi.org/10.1016/j.ijinfomgt.2018.09.003](https://dx.doi.org/10.1016/j.ijinfomgt.2018.09.003)
Khazaei, H. (2016). How do I choose the right NoSQL solution? Big Data, X(0), 1–33.
Laskowski, N. (2016). Data lake governance: A big data do or die. URL:
[http://searchcio](http://searchcio/).techtarget.com/feature/Data-lake-governance-A-big-data-do-or-die (access date 28/05/2016)
Marz, N., & Warren, J. (2015). Big Data: Principles and best practices of scalable real-time data systems. New York; Manning Publications Co.
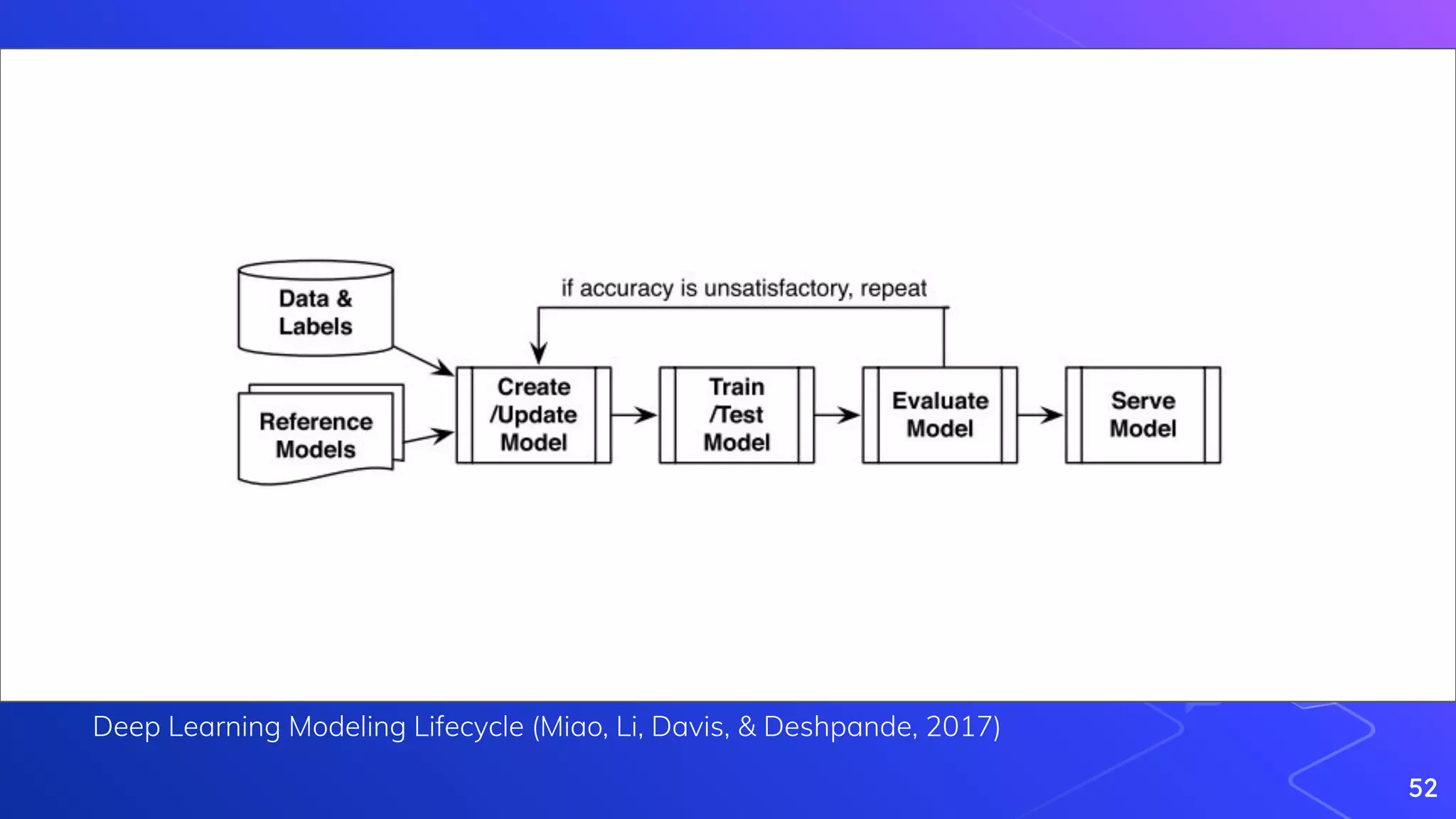
Miao, H., Li, A., Davis, L. S., & Deshpande, A. (2017, April). Towards unified data and lifecycle management for deep learning. In 2017 IEEE 33rd International Conference on
Data Engineering (ICDE) (pp. 571-582). IEEE.
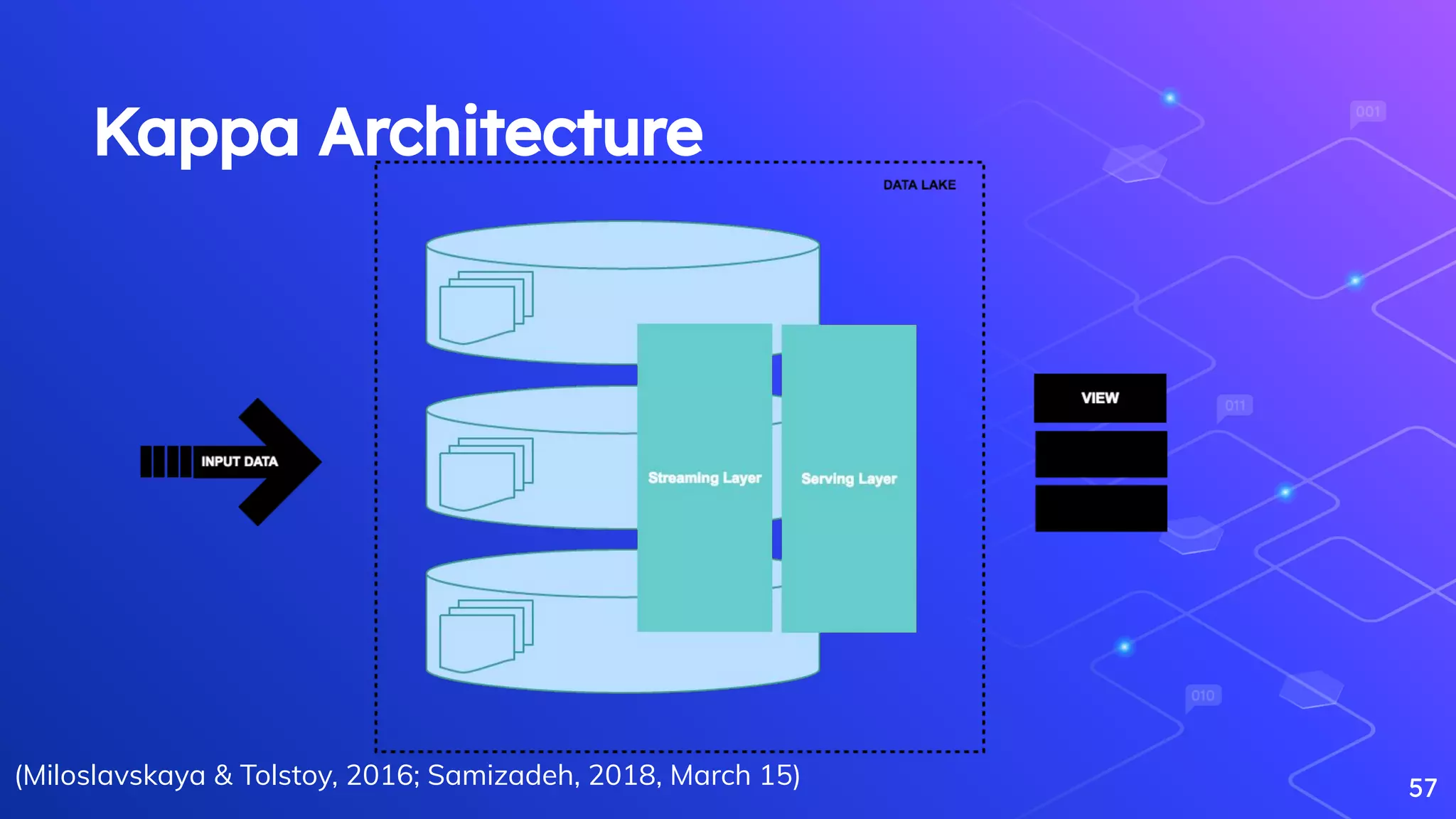
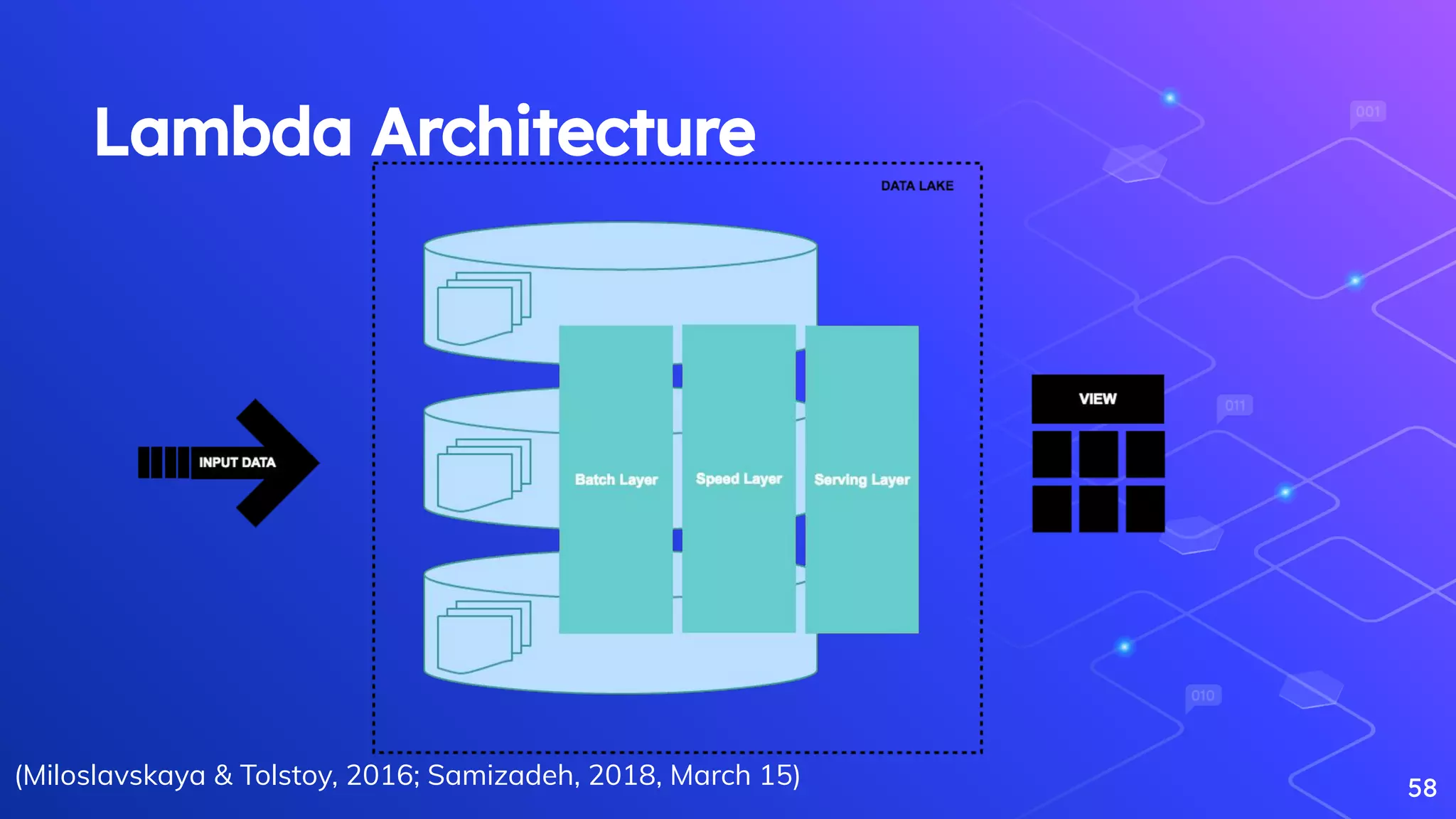
Miloslavskaya, N., & Tolstoy, A. (2016). Big Data, Fast Data and Data Lake Concepts. Procedia Computer Science, 88, 300–305.
[https://doi.org/10.1016/j.procs.2016.07.439](https://doi.org/10.1016/j.procs.2016.07.439)
Najafabadi, M. M., Villanustre, F., Khoshgoftaar, T. M., Seliya, N., Wald, R., & Muharemagic, E. (2015). Deep learning applications and challenges in big data analytics. Journal
of Big Data, 2(1), 1.
Rahm, E., & Do, H. H. (2000). Data cleaning: Problems and current approaches. IEEE Data Eng. Bull., 23(4), 3-13.
Samizadeh, I. (2018, March 15). A brief introduction to two data processing architectures - Lambda and Kappa for Big Data.
[https://towardsdatascience.com/a-brief-introduction-to-two-data-processing-architectures-lambda-and-kappa-for-big-data-4f35c28005bb](https://towardsdatasci
ence.com/a-brief-introduction-to-two-data-processing-architectures-lambda-and-kappa-for-big-data-4f35c28005bb).
98](https://image.slidesharecdn.com/theroleofdataengineeringindatascienceandanalyticspractice-200915114740/75/The-role-of-data-engineering-in-data-science-and-analytics-practice-97-2048.jpg)

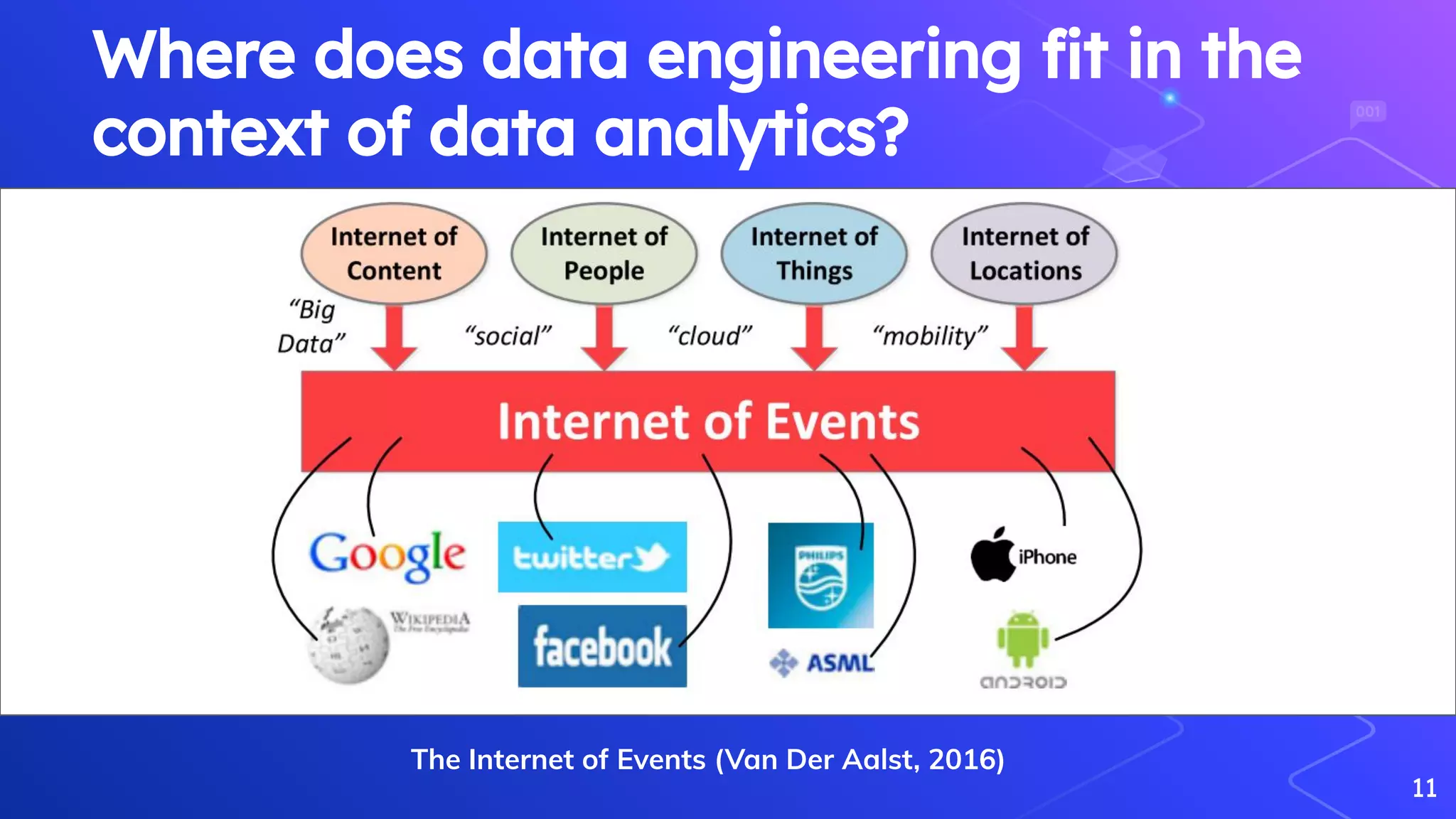
Van Der Aalst, W. (2016). Data science in action. In Process mining (pp. 3-23). Springer, Berlin, Heidelberg.
Vogels, W. (2009). Eventually consistent Communications of the ACM 52(1), 40-44.
[https://dx.doi.org/10.1145/1435417.1435432](https://dx.doi.org/10.1145/1435417.1435432)
Wang, R. Y., Kon, H. B., & Madnick, S. E. (1993). Data quality requirements analysis and modeling. Proceedings - International Conference on Data Engineering, 670–677.
[https://doi.org/10.1109/icde.1993.344012](https://doi.org/10.1109/icde.1993.344012)
Yin, S., & Kaynak, O. (2015). Big data for modern industry: challenges and trends [point of view]. Proceedings of the IEEE, 103(2), 143-146.
99](https://image.slidesharecdn.com/theroleofdataengineeringindatascienceandanalyticspractice-200915114740/75/The-role-of-data-engineering-in-data-science-and-analytics-practice-98-2048.jpg)

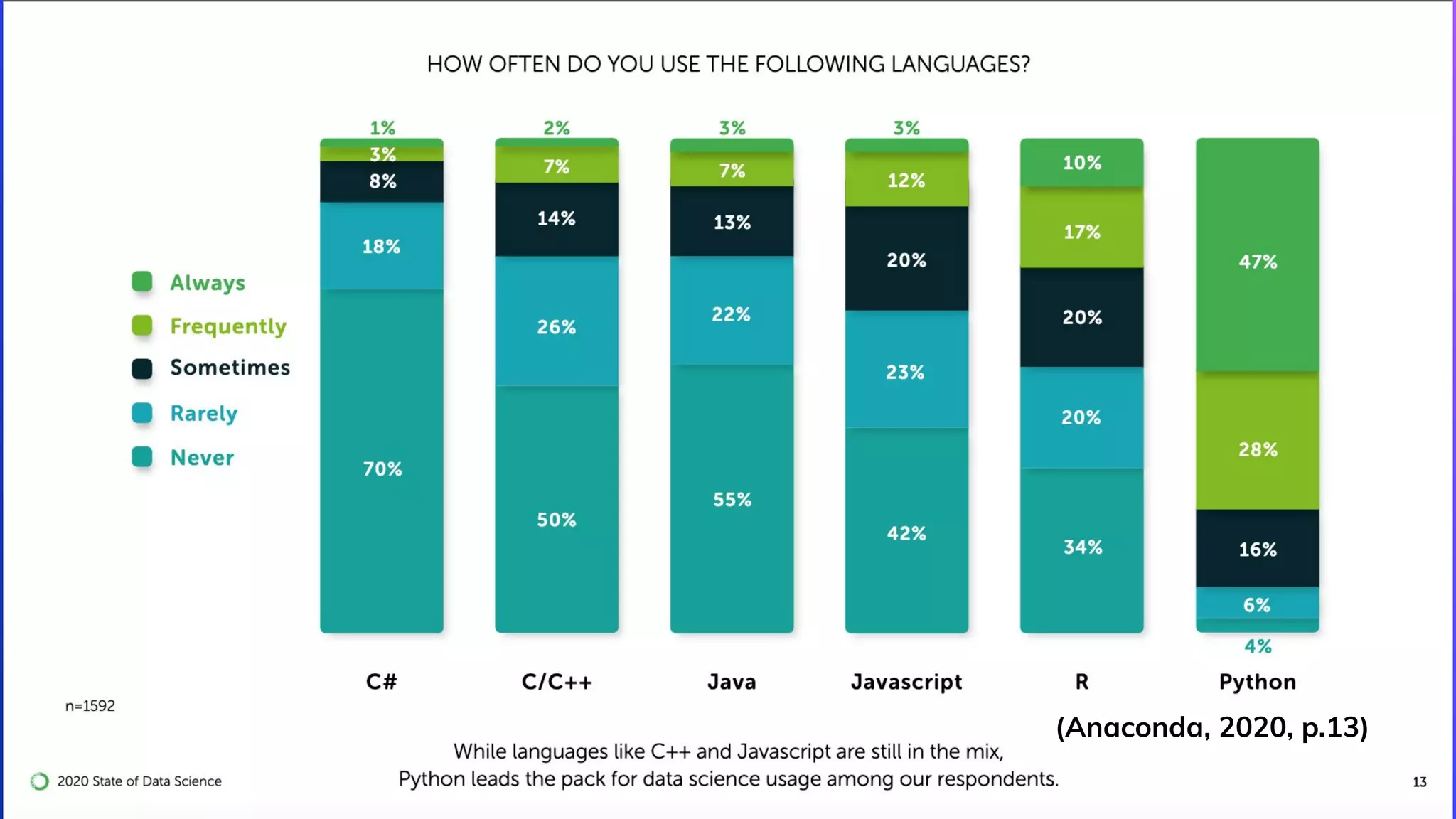
The document discusses the role of data engineering in the context of data science and analytics, highlighting the multidisciplinary nature of data engineering teams and the significance of creating data pipelines. It outlines essential skills, processes, and big data concepts, including the importance of data cleaning, event streaming, and the distinctions between big data and fast data. The document emphasizes continuous learning and collaboration within the field of data engineering.
The presentation introduces Data Engineering's role in Data Science and provides speaker details.
Discussion on the multidisciplinary nature of data engineering teams and their role in data analytics.
Overview of job families and skills related to Big Data, showing prevalent roles through visuals.
Insight into becoming a Data Engineer, including skills required and personal experiences.
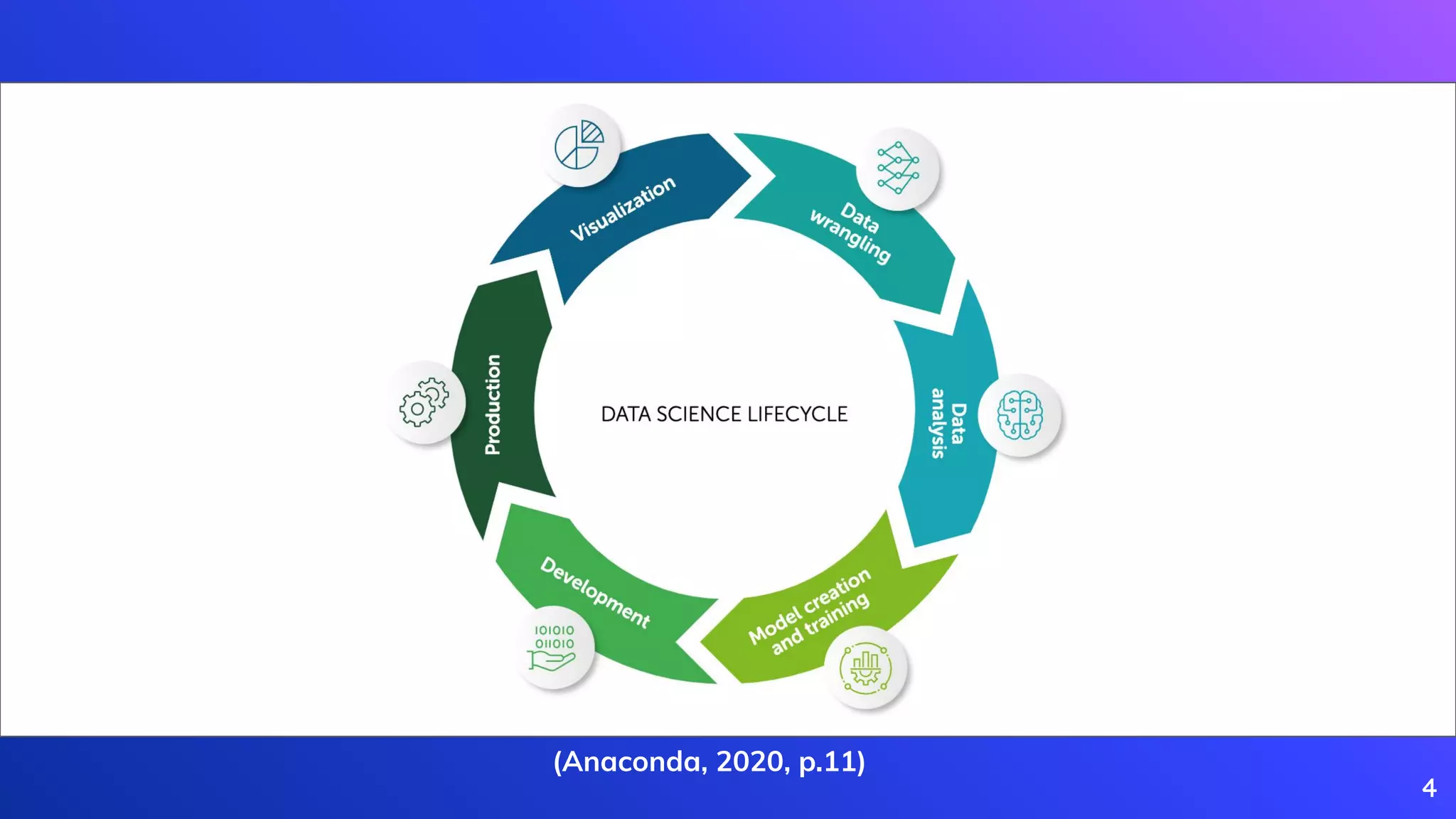
Detailed iterative steps in the data engineering process, from project initiation to evaluation.
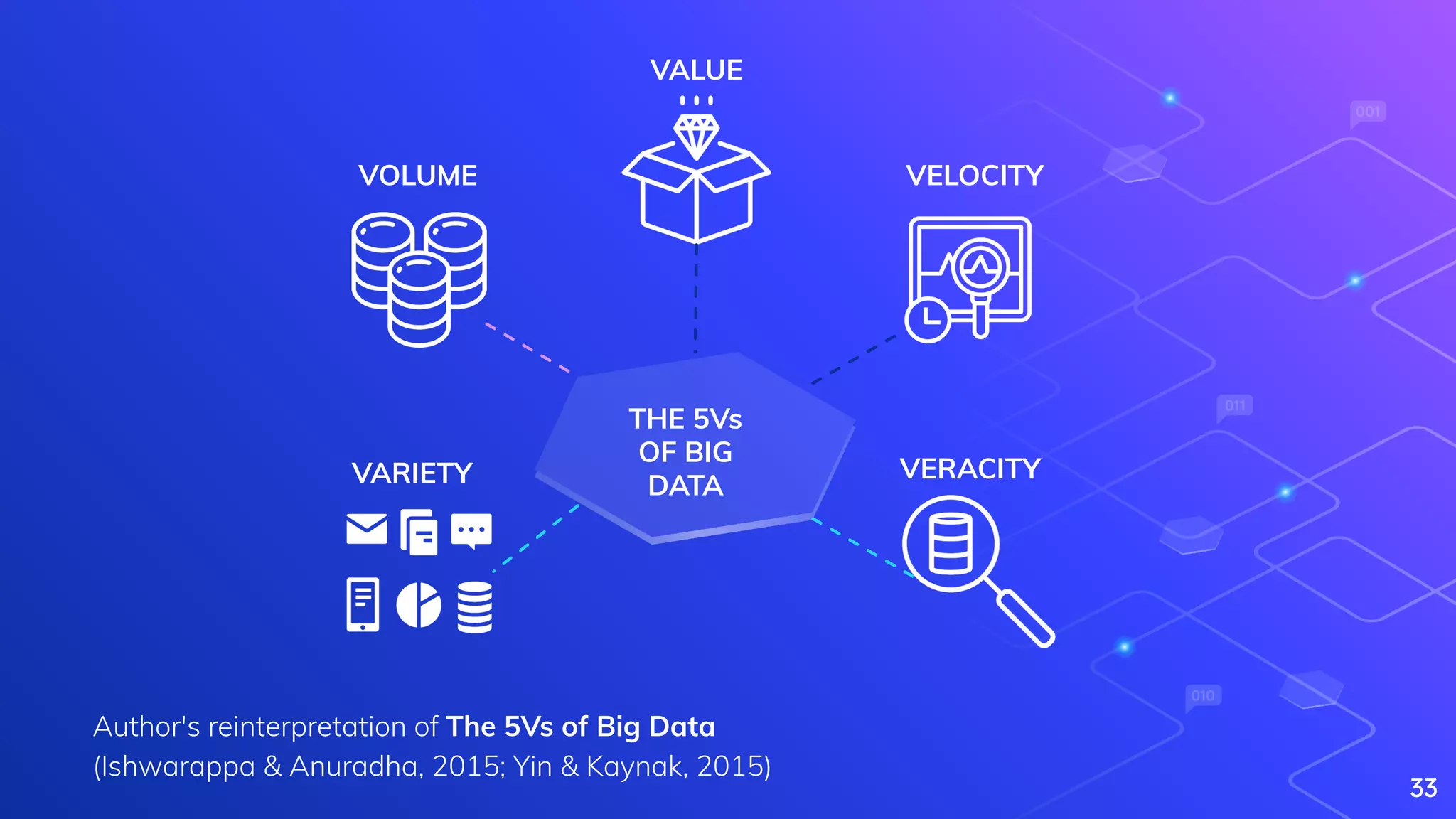
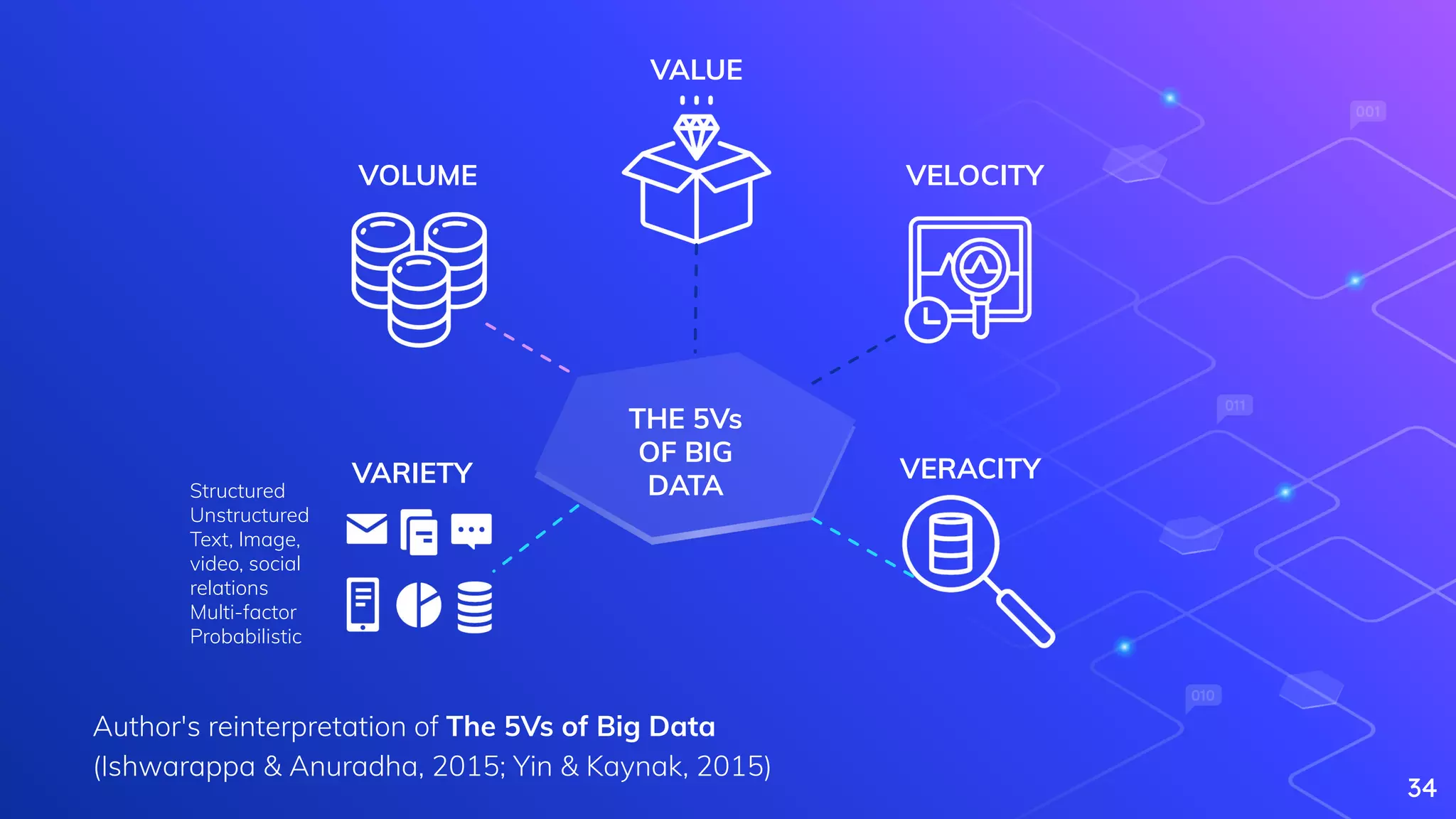
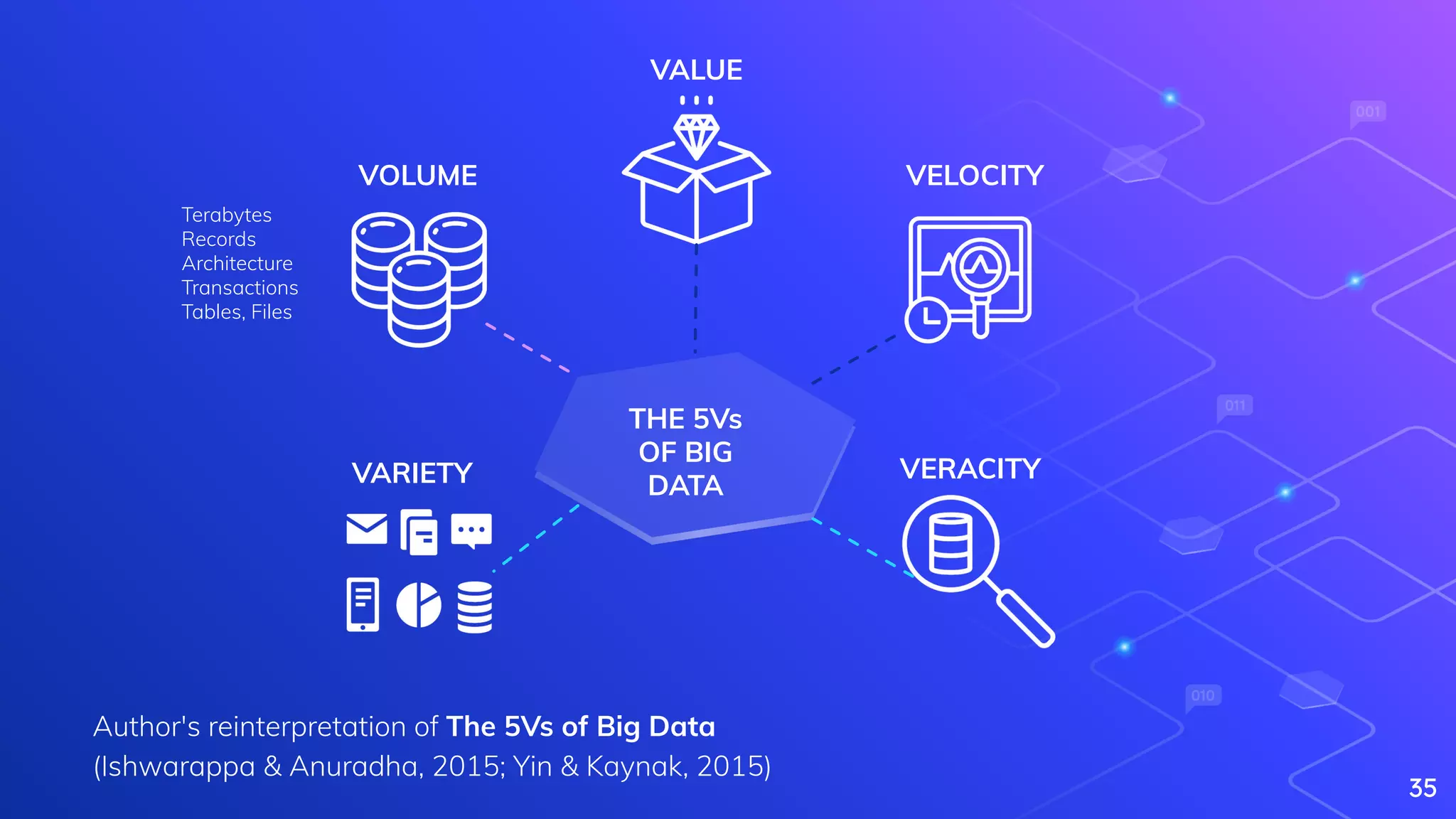
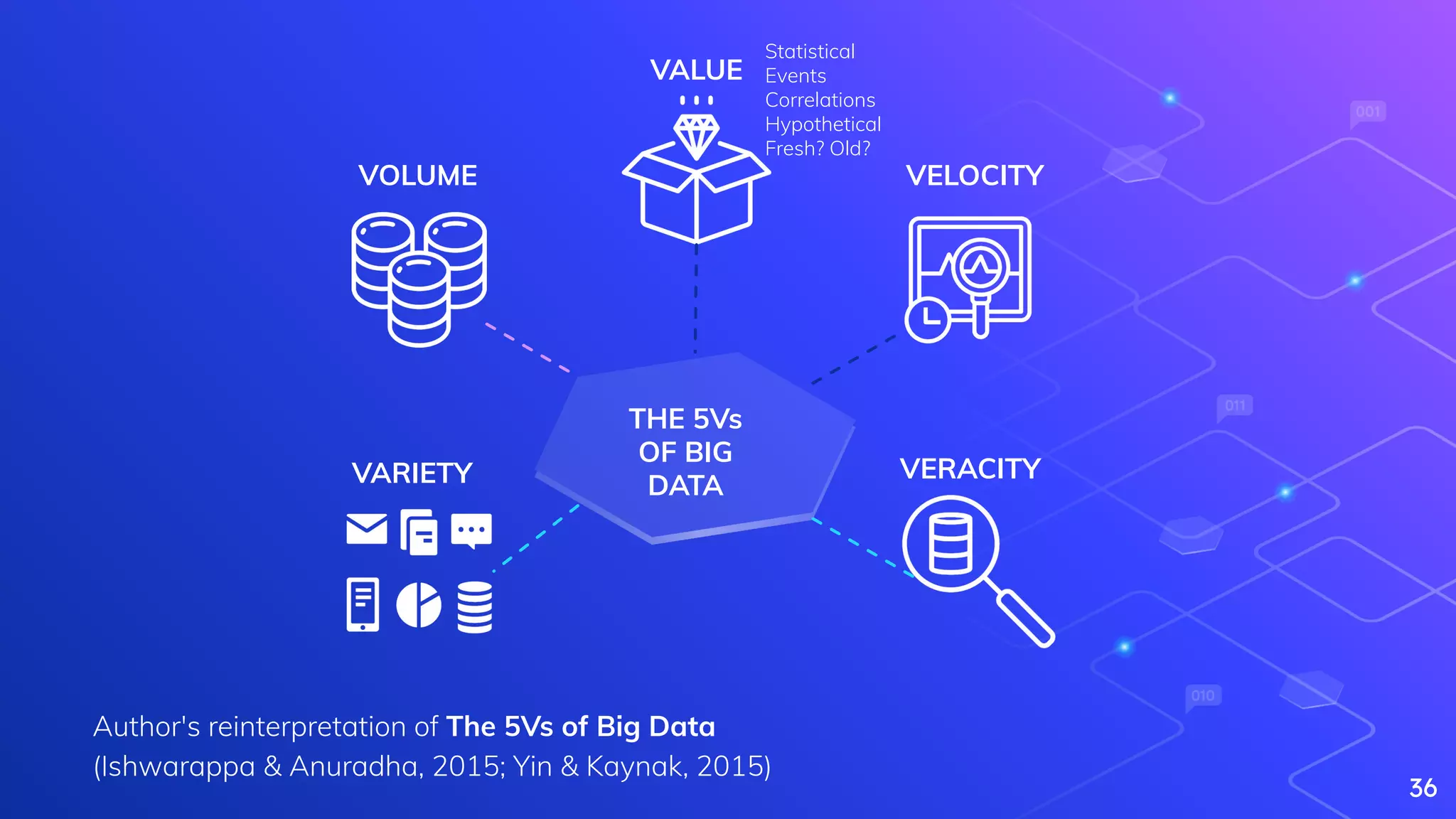
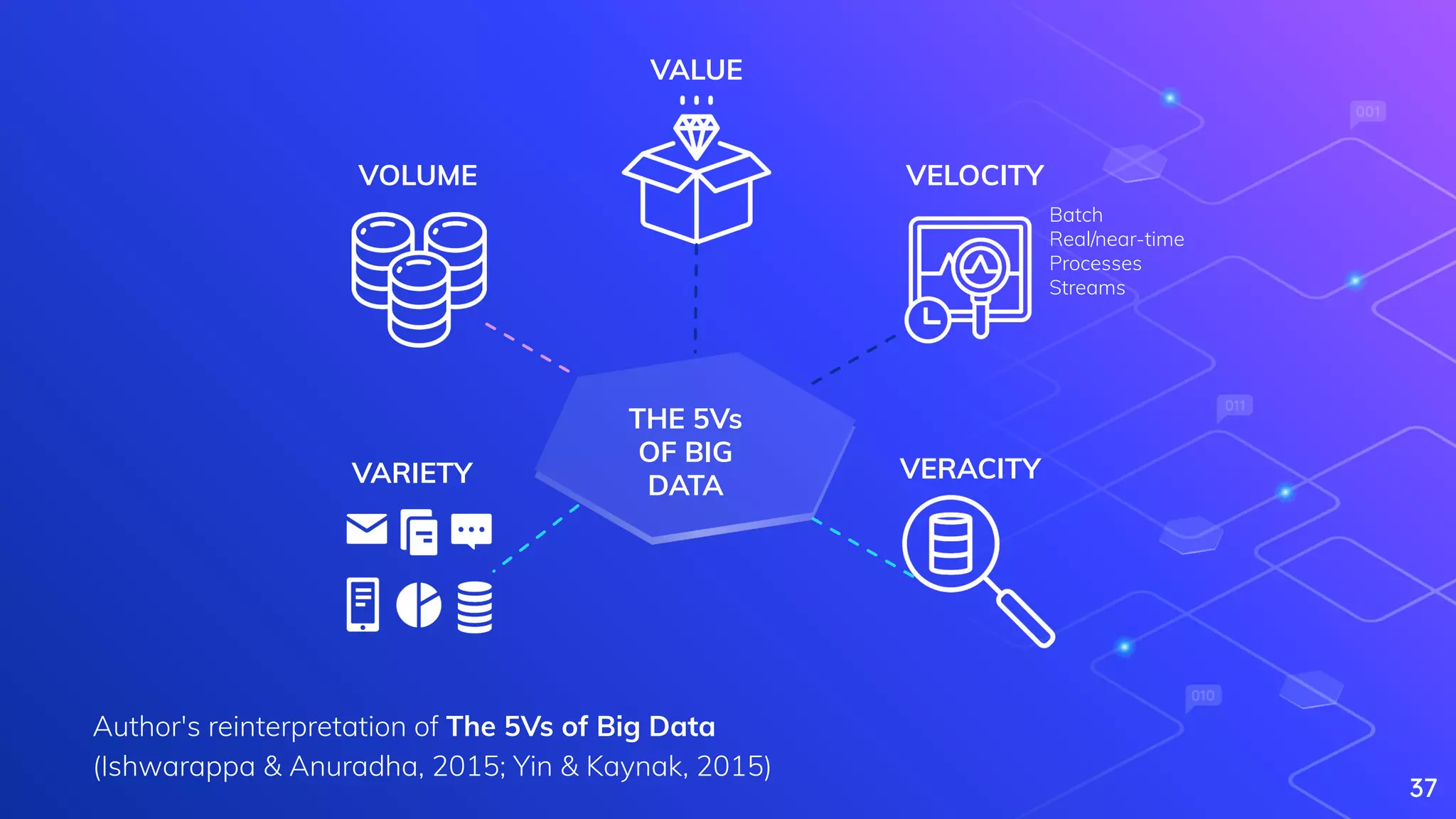
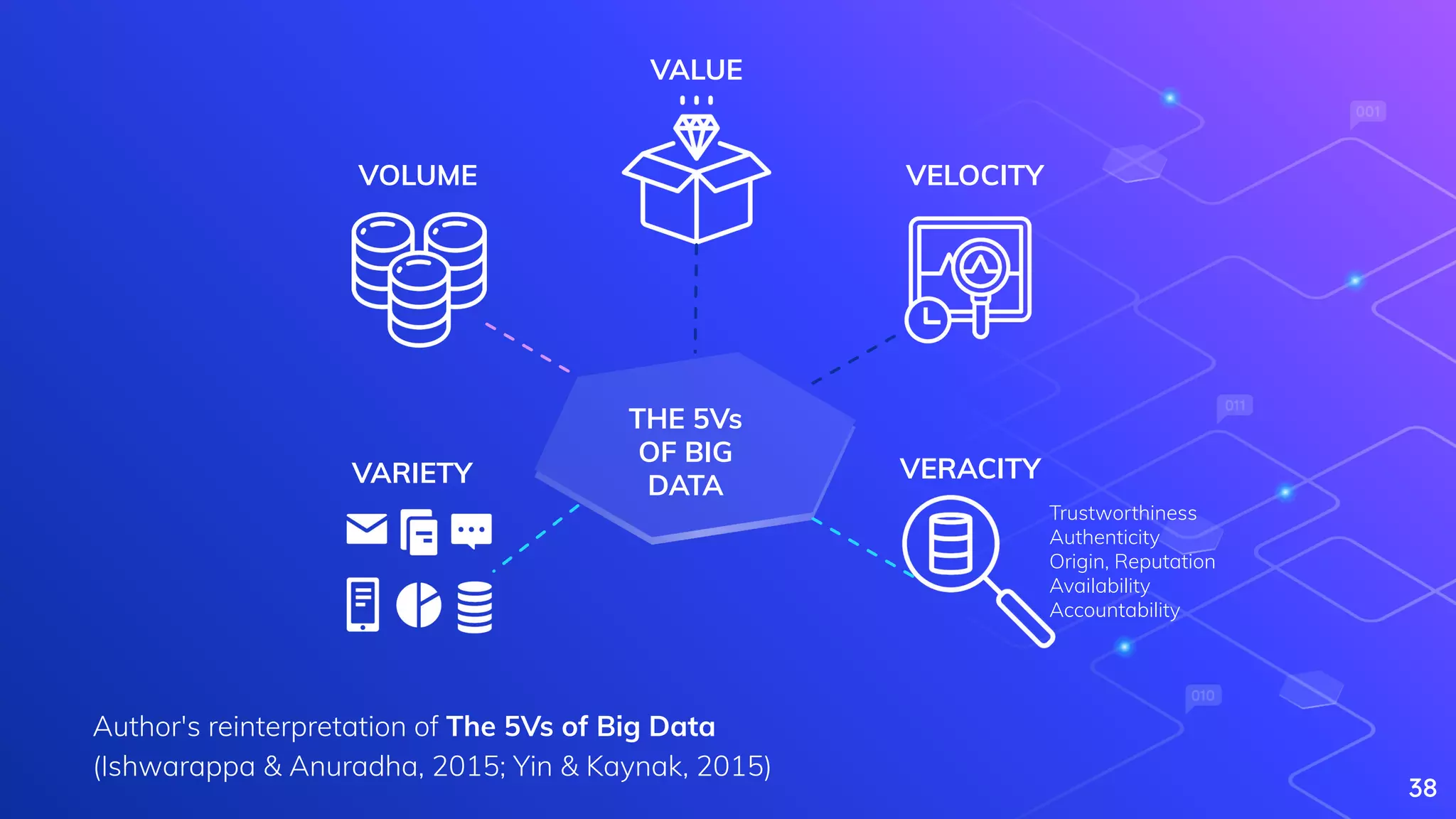
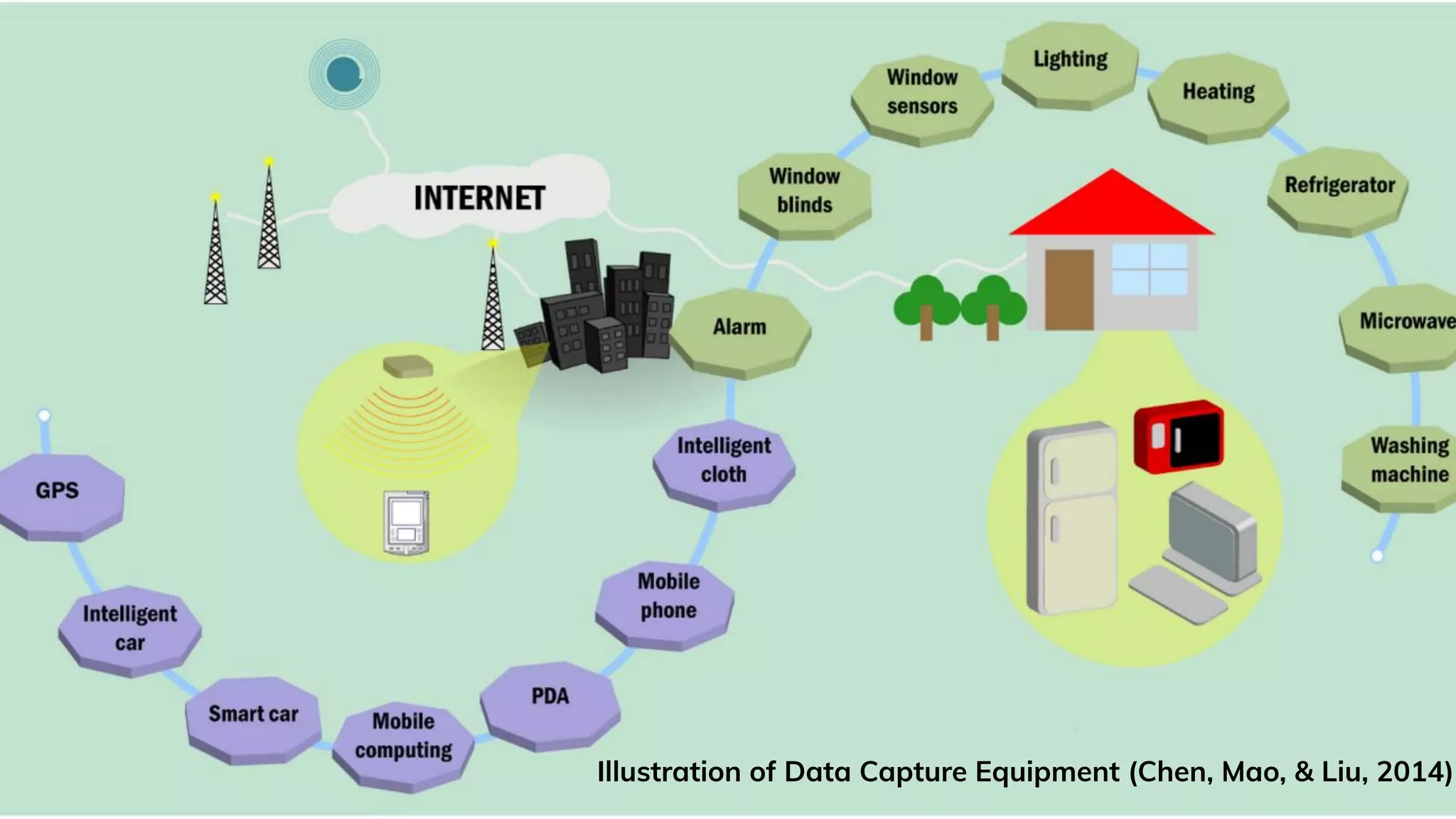
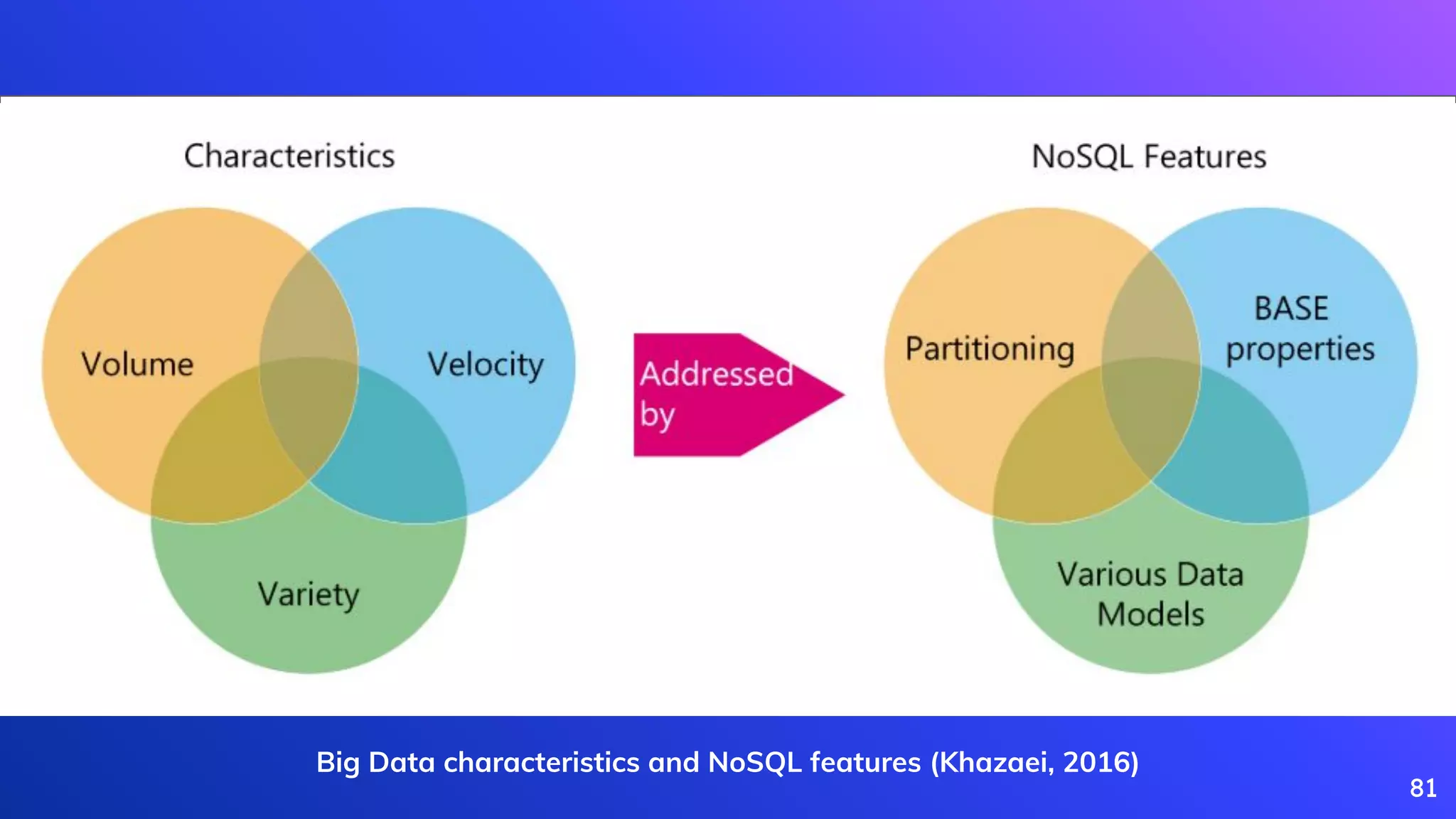
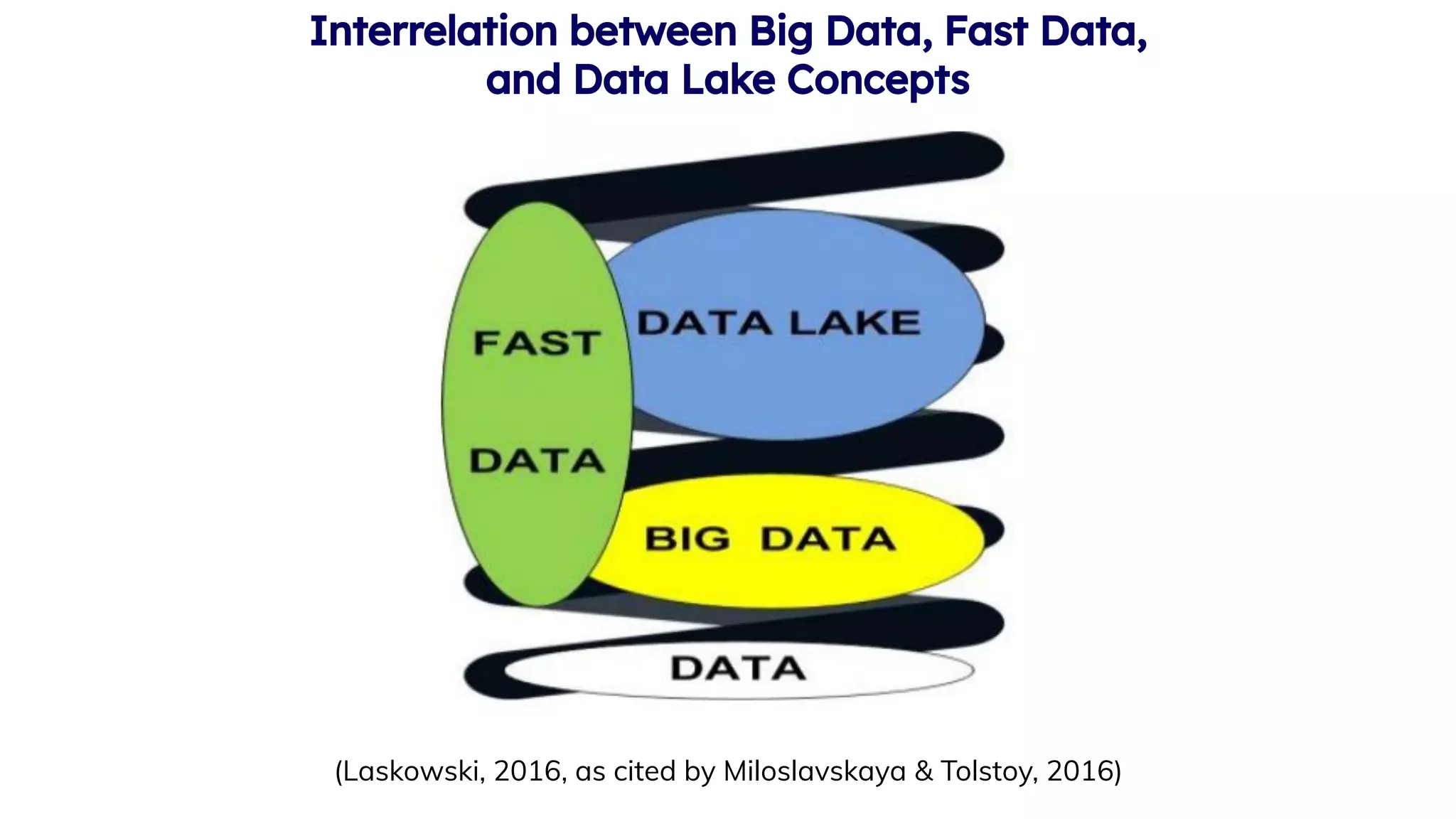
Explains Big Data, its characteristics (5Vs), and complexities in processing large datasets.
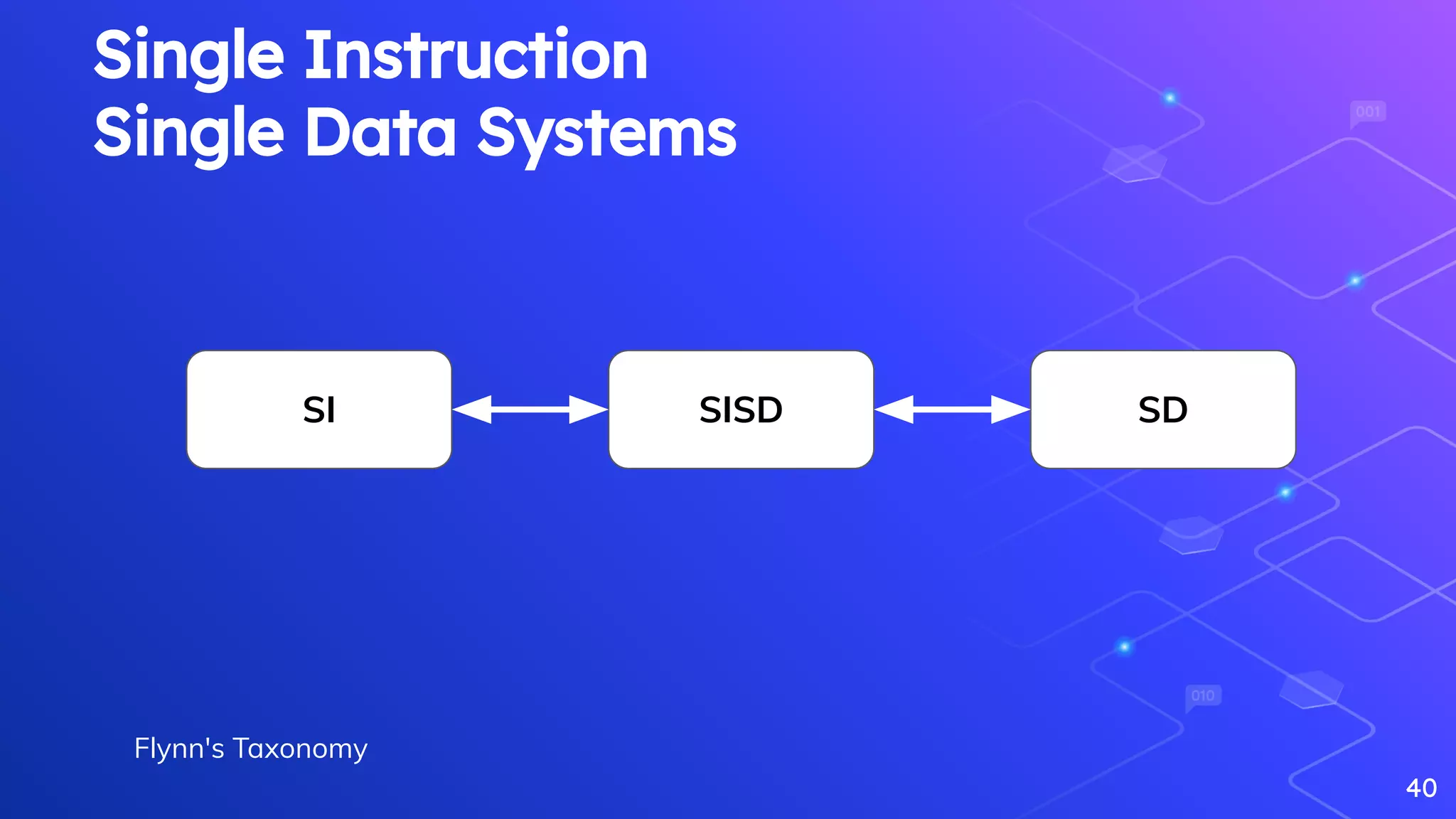
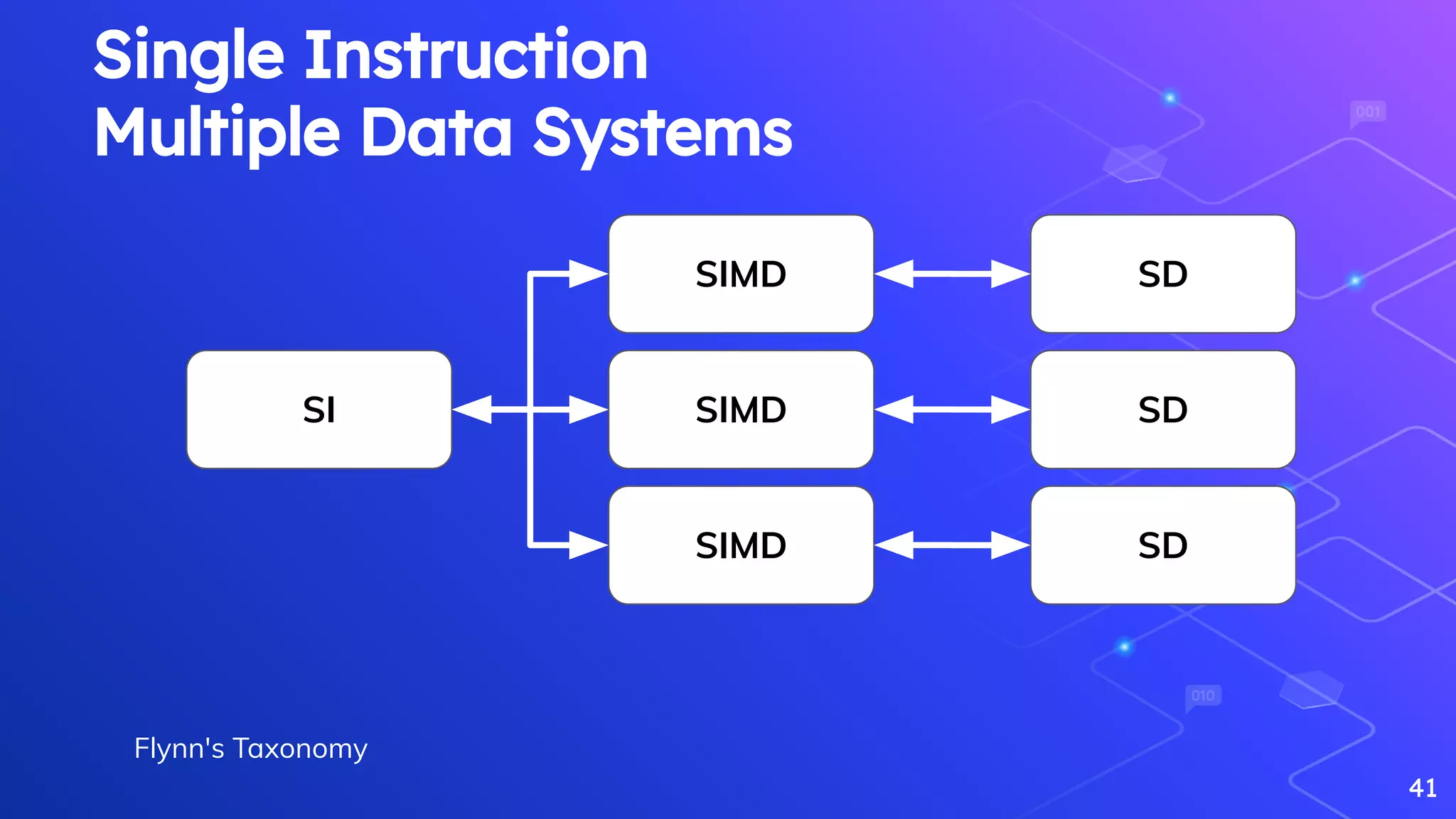
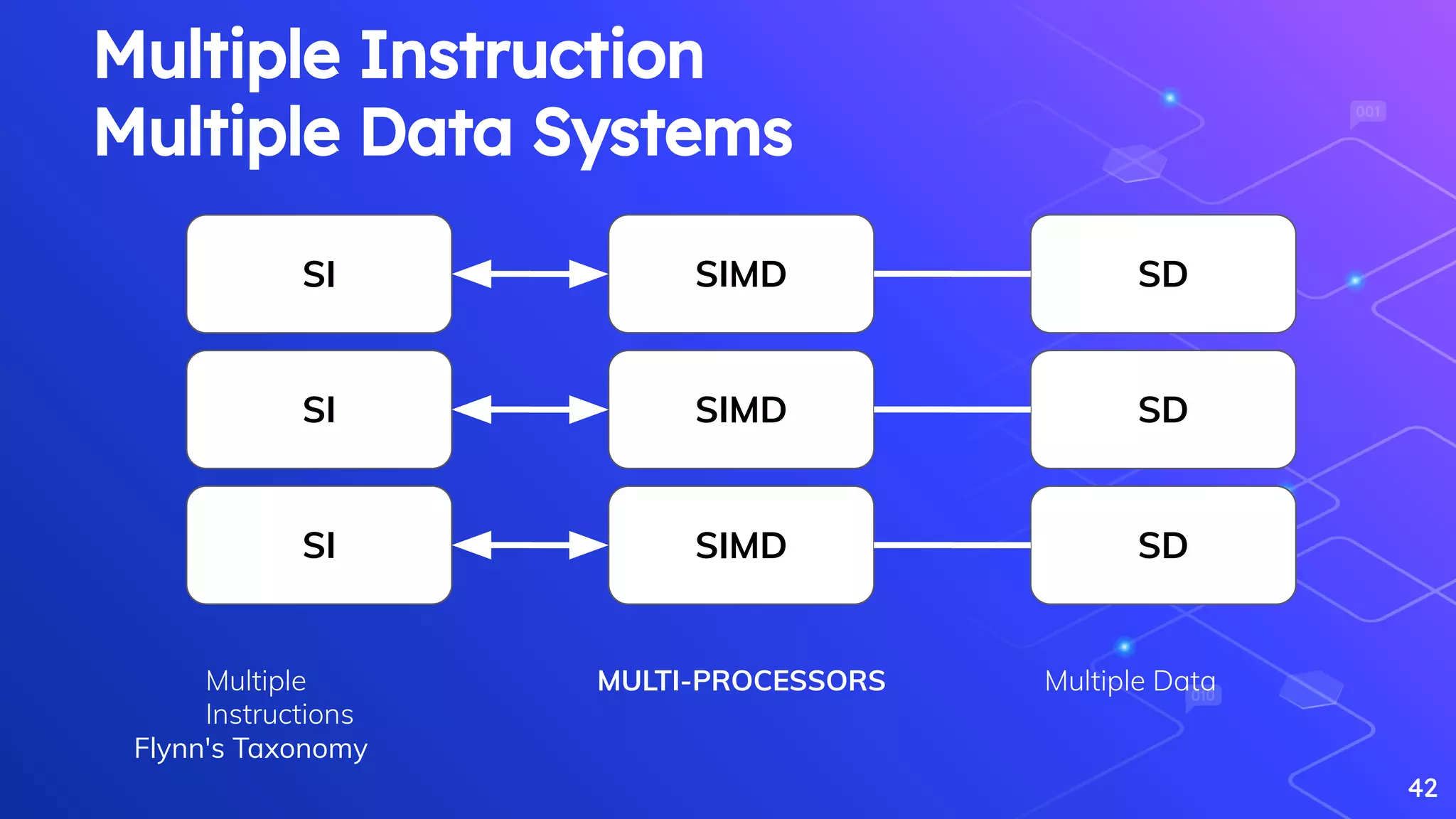
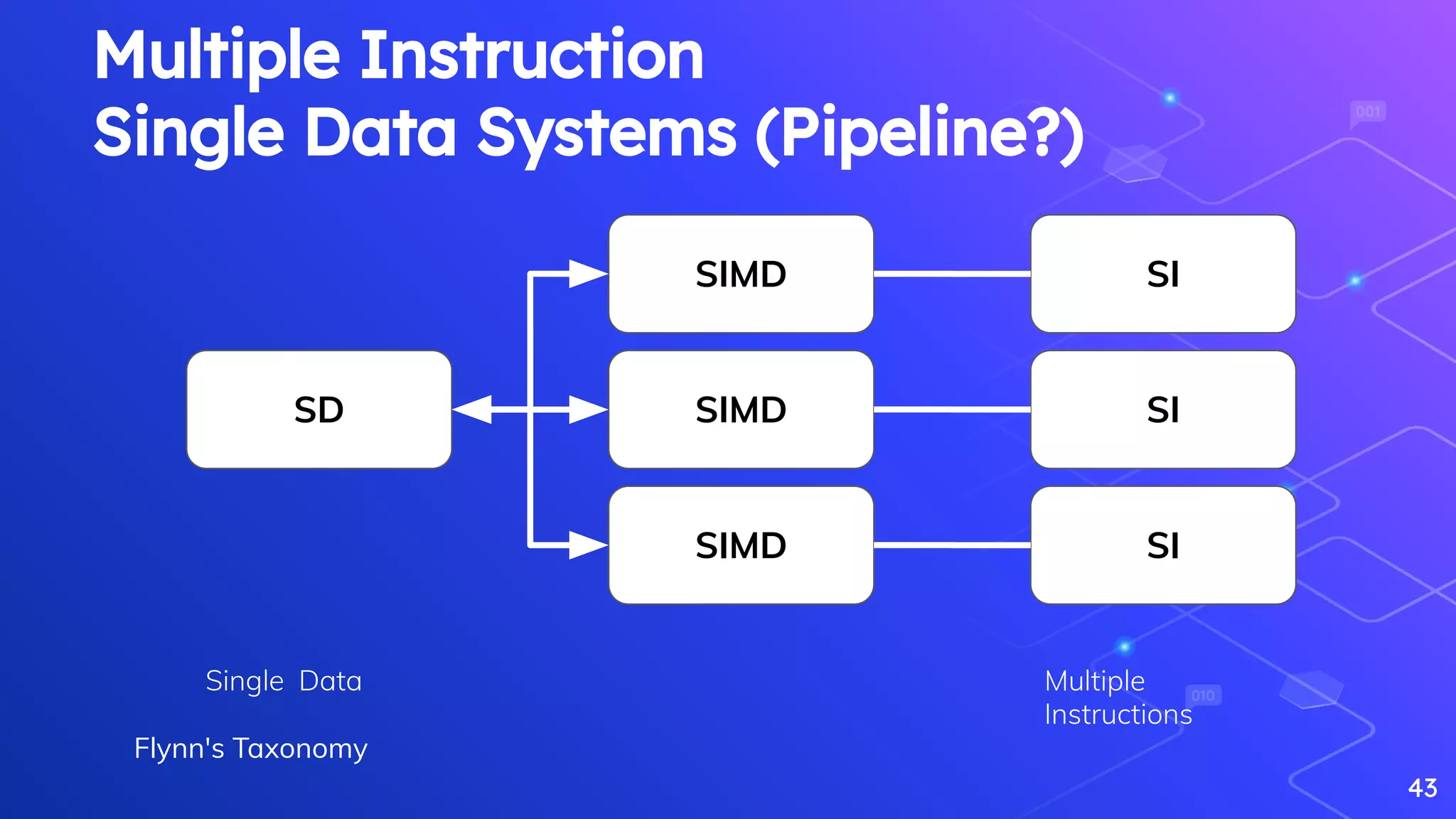
Discussion on workload management and Flynn's Taxonomy related to data processing systems.
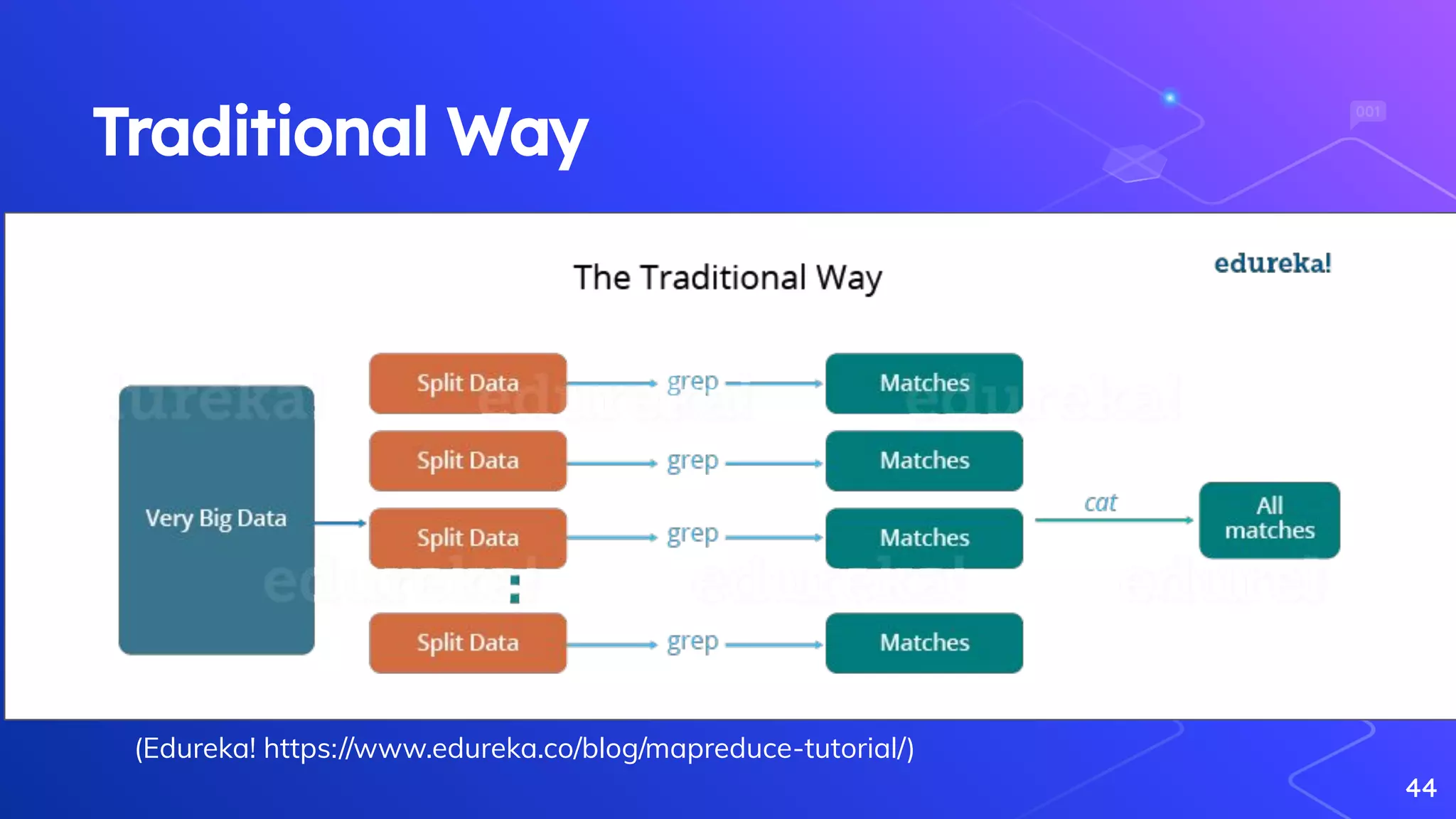
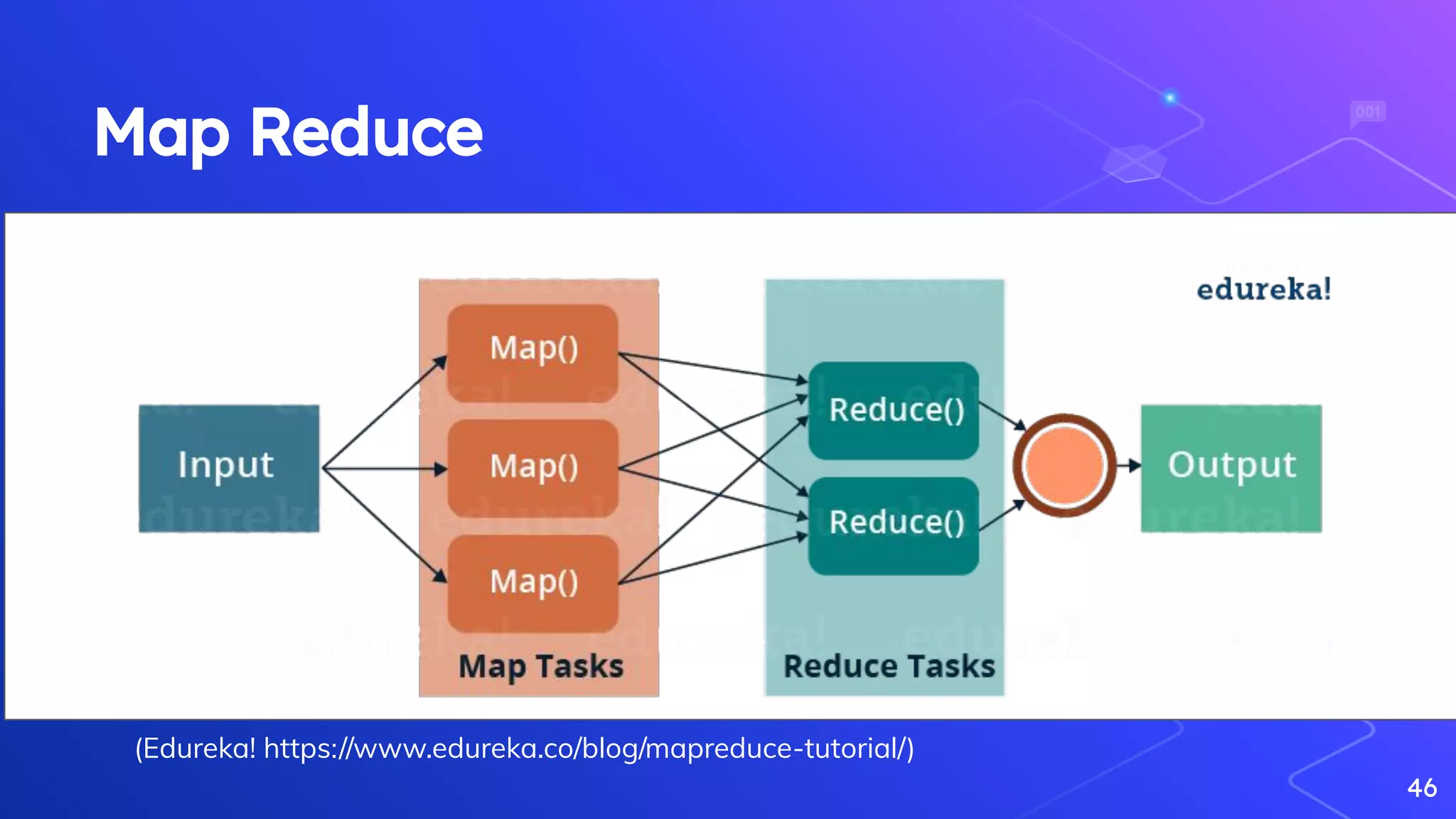
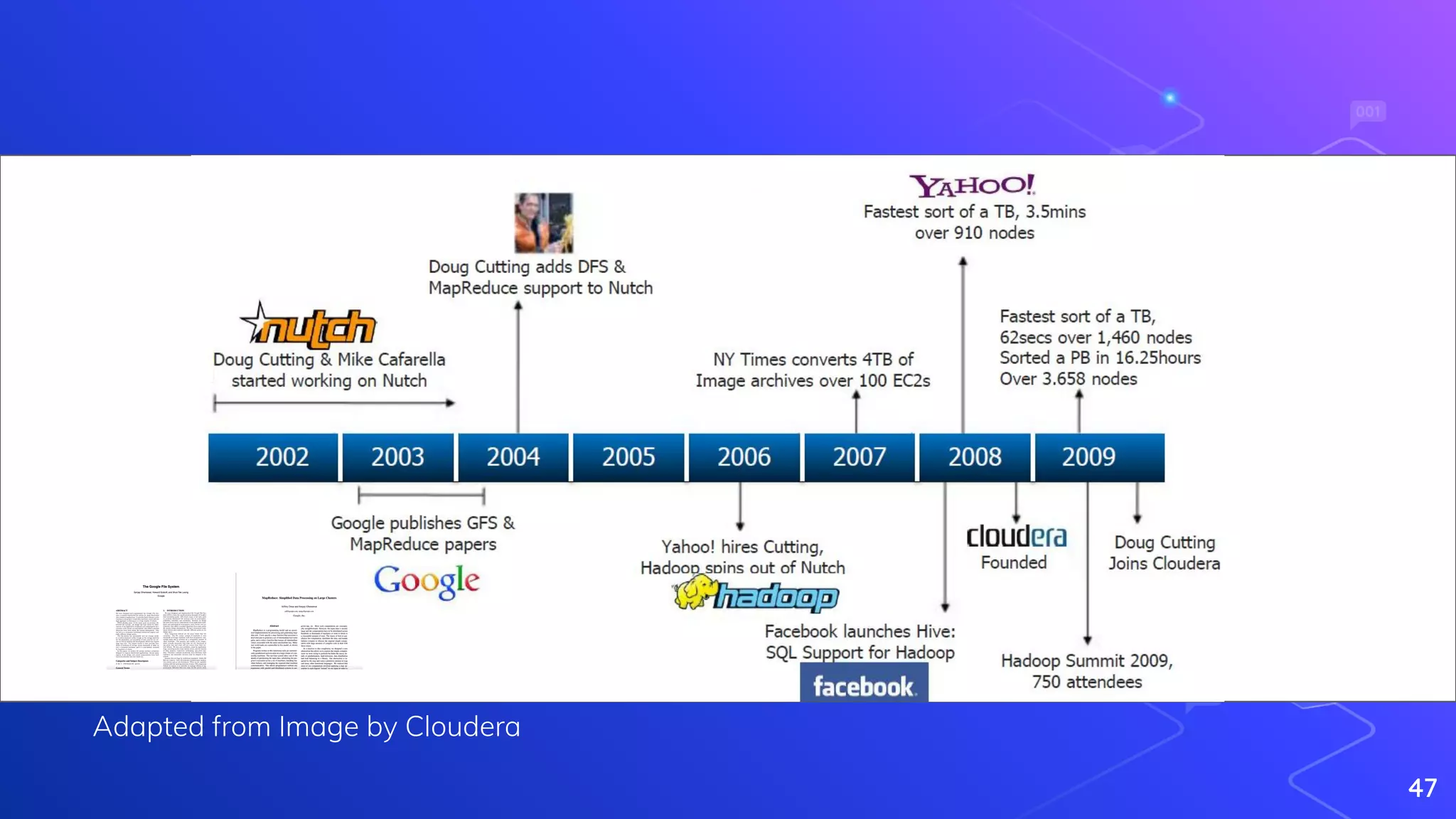
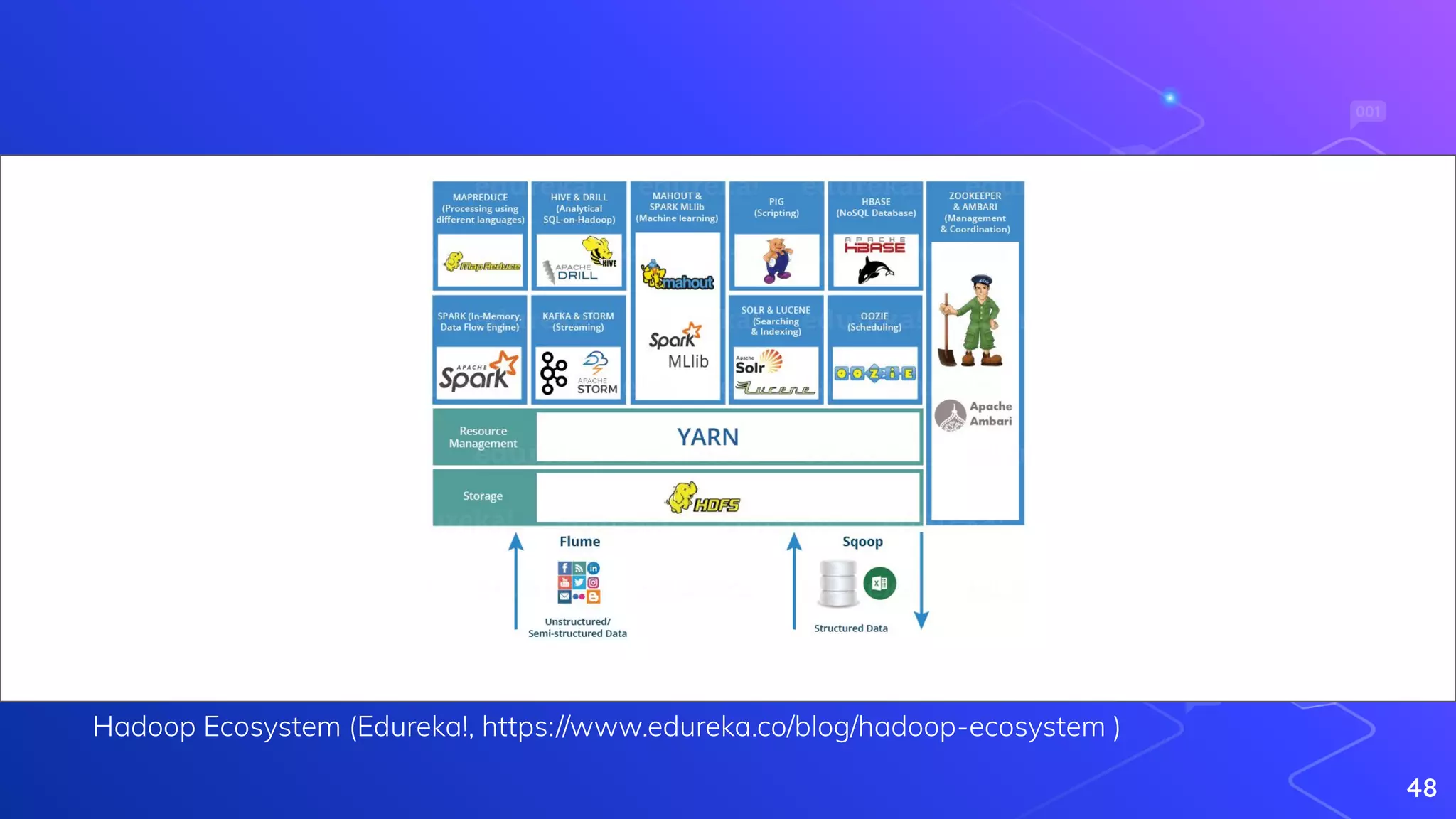
Explanation of the MapReduce paradigm and introduction to Hadoop's ecosystem.
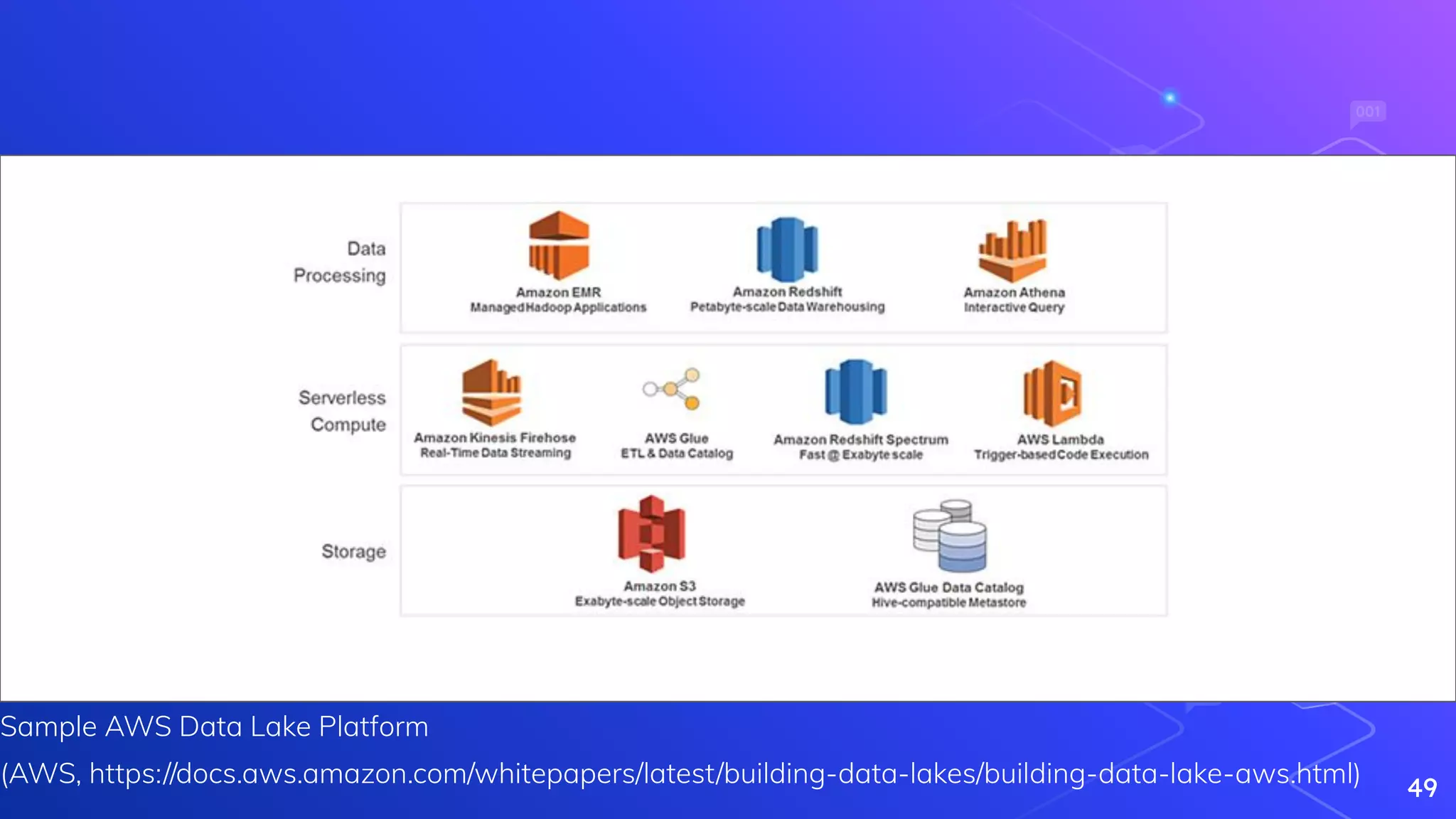
Introduction to the concept of Data Lakes as flexible storage for raw data and its governance.
Overview of batch, stream, and hybrid processing architectures in Big Data.
Definition and requirements of Fast Data processing for near-real-time analytics.
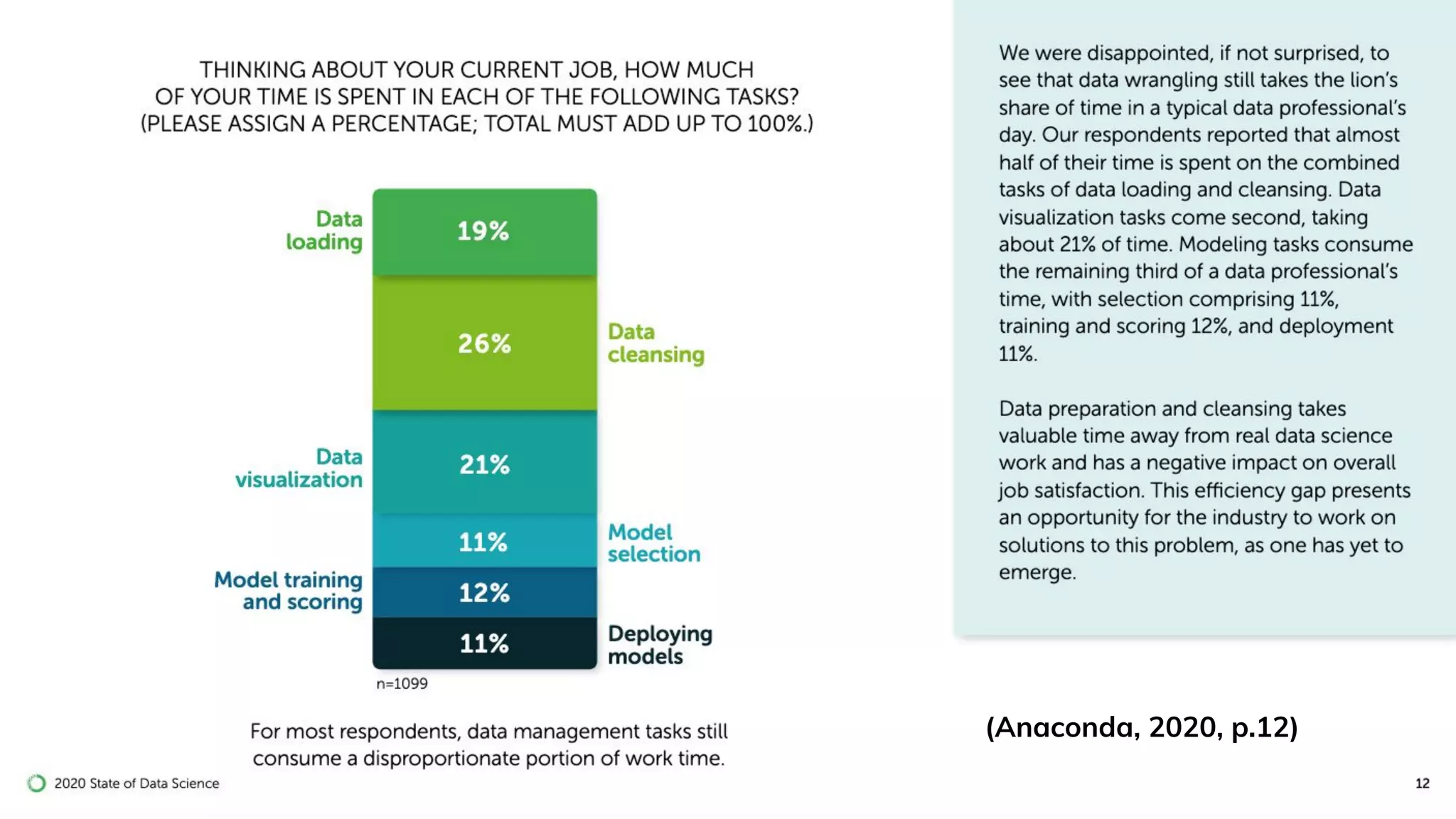
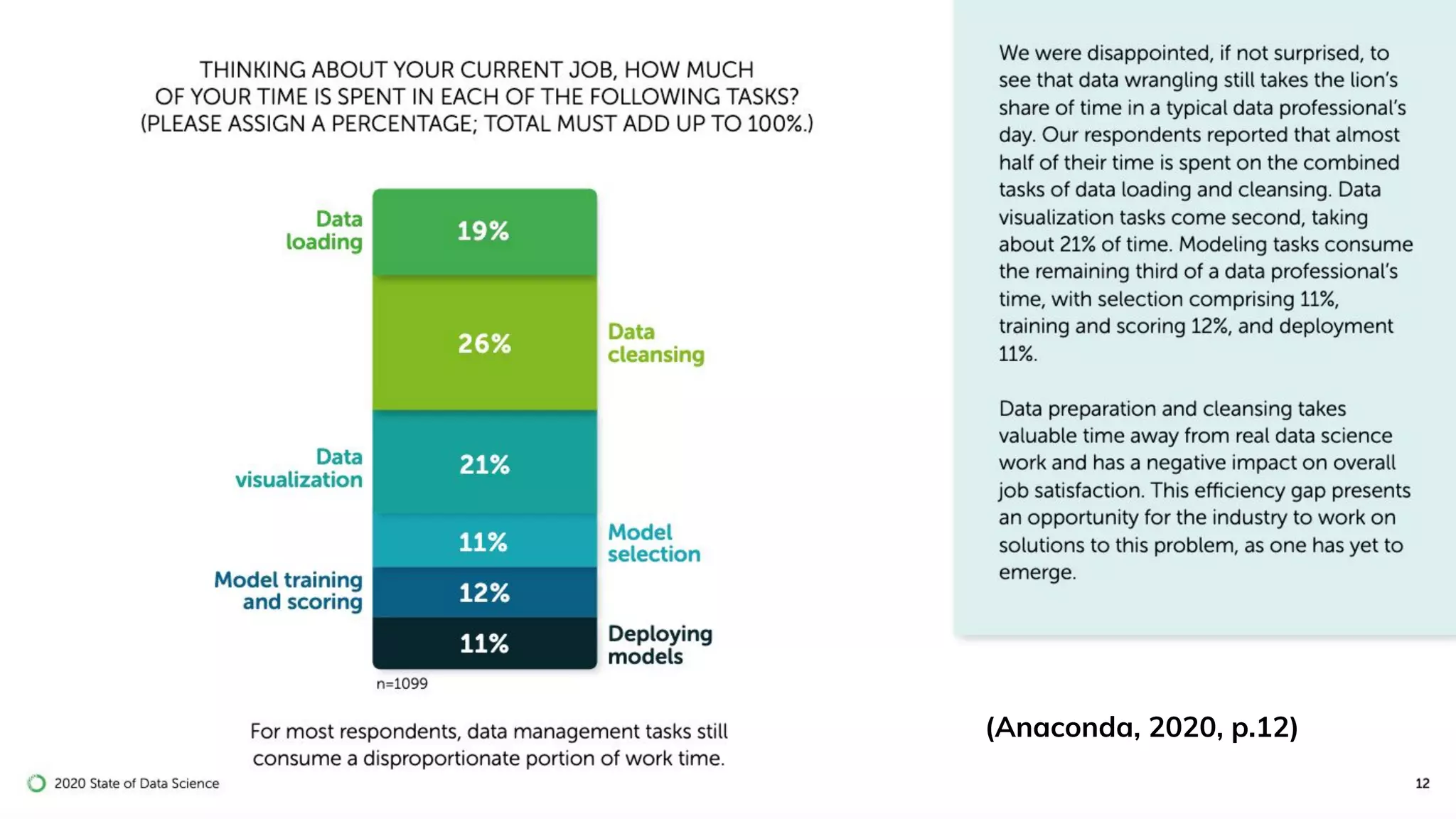
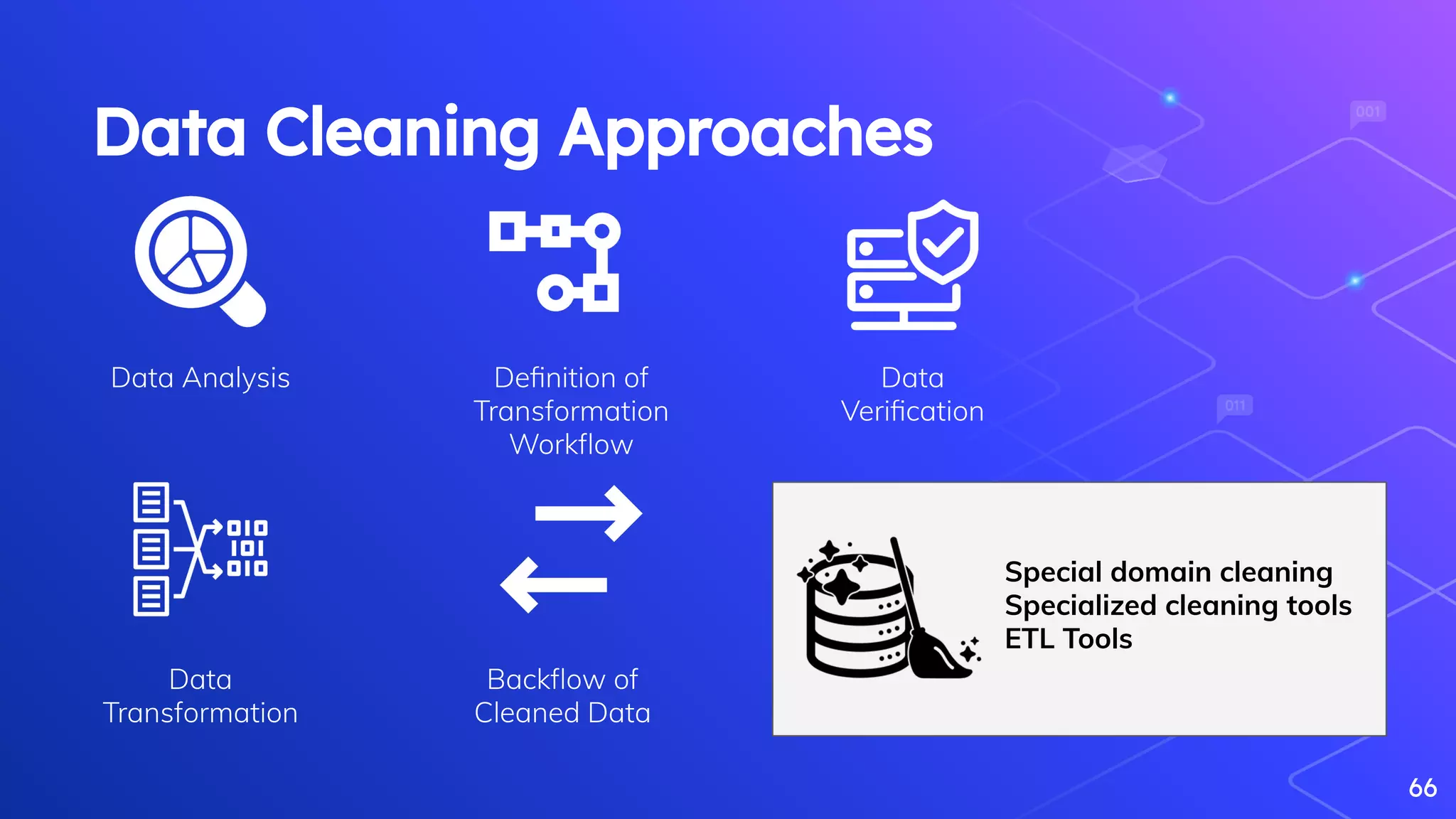
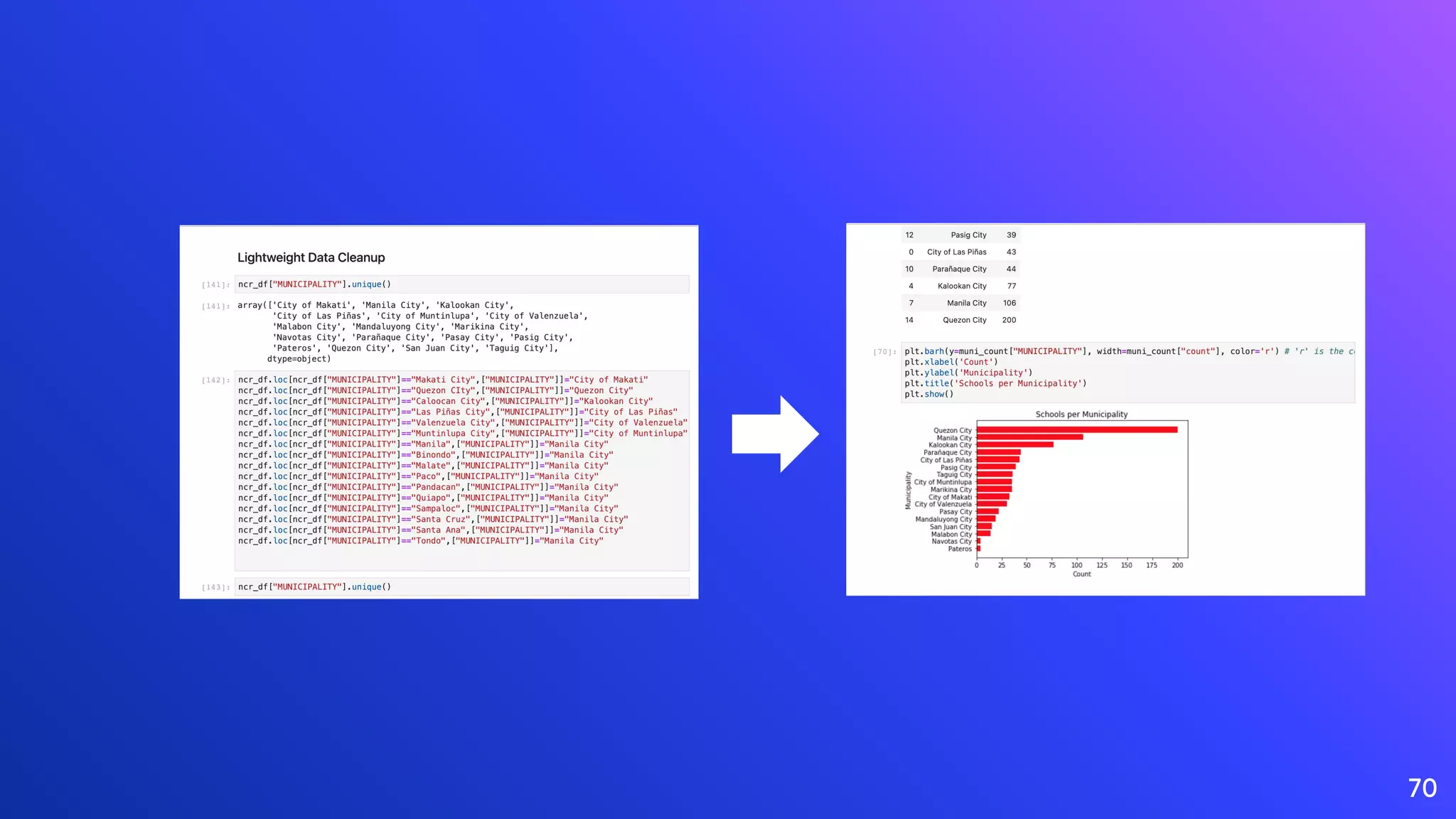
Importance of data cleaning, its methods, and common data quality issues.
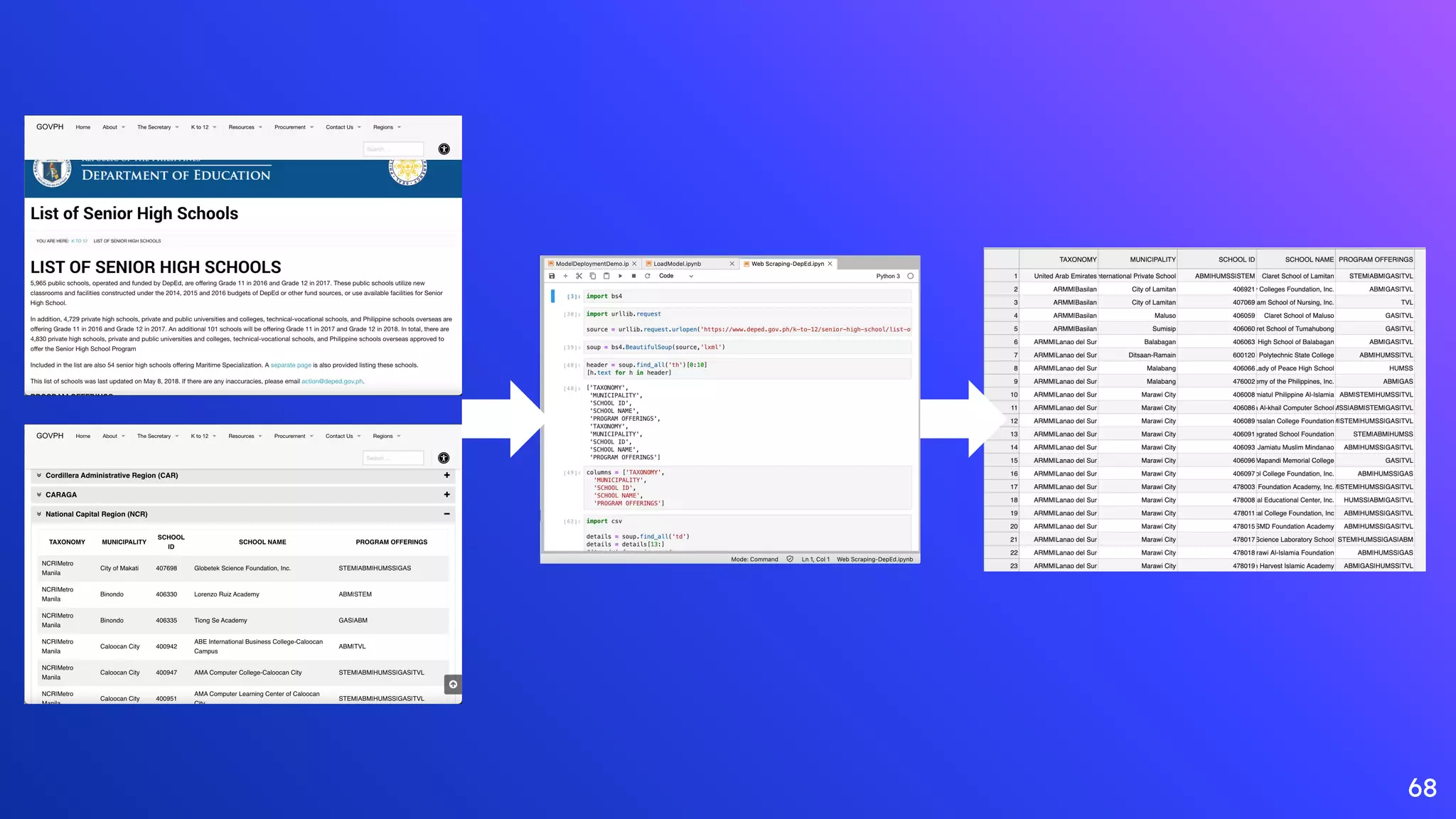
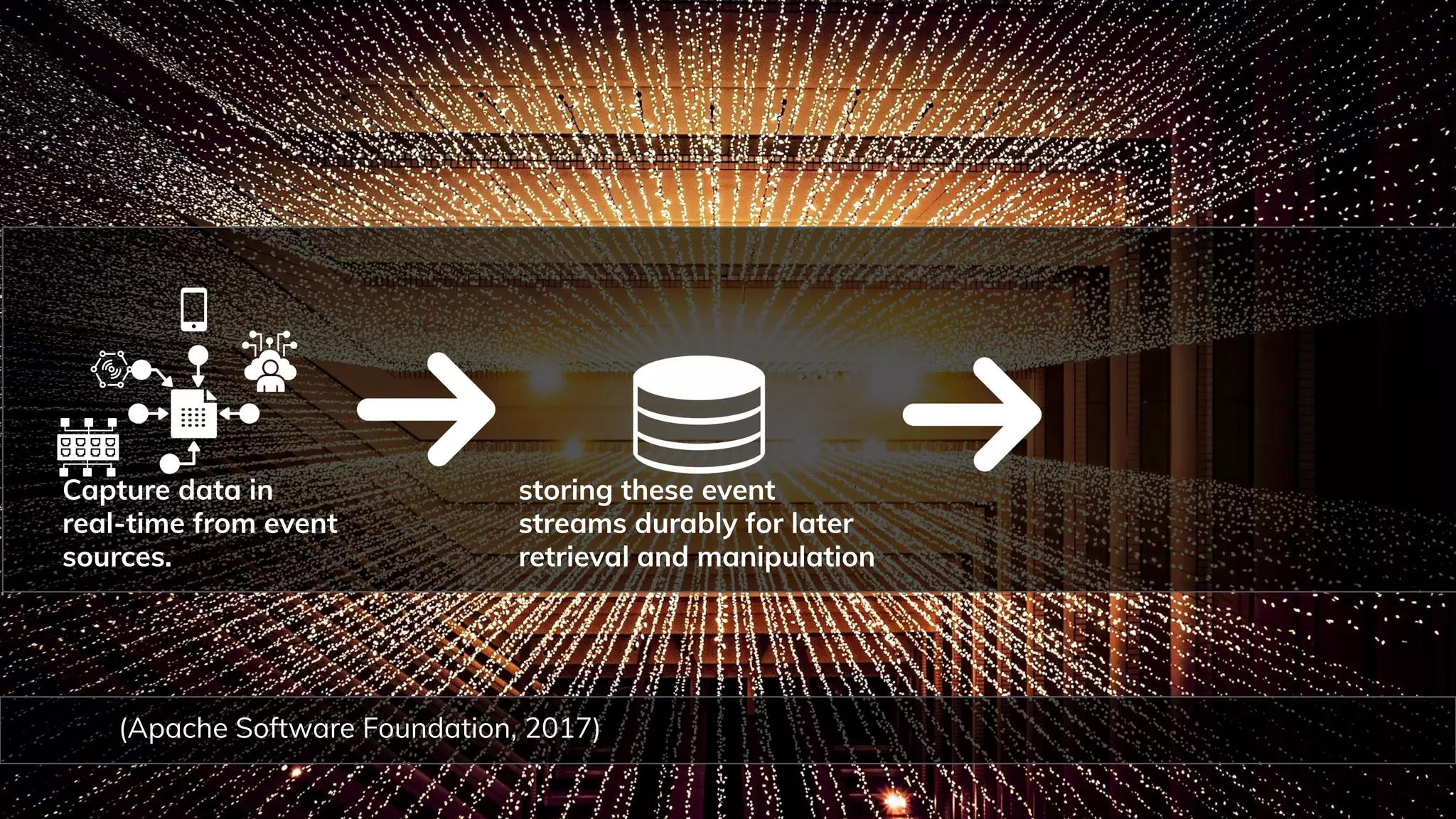
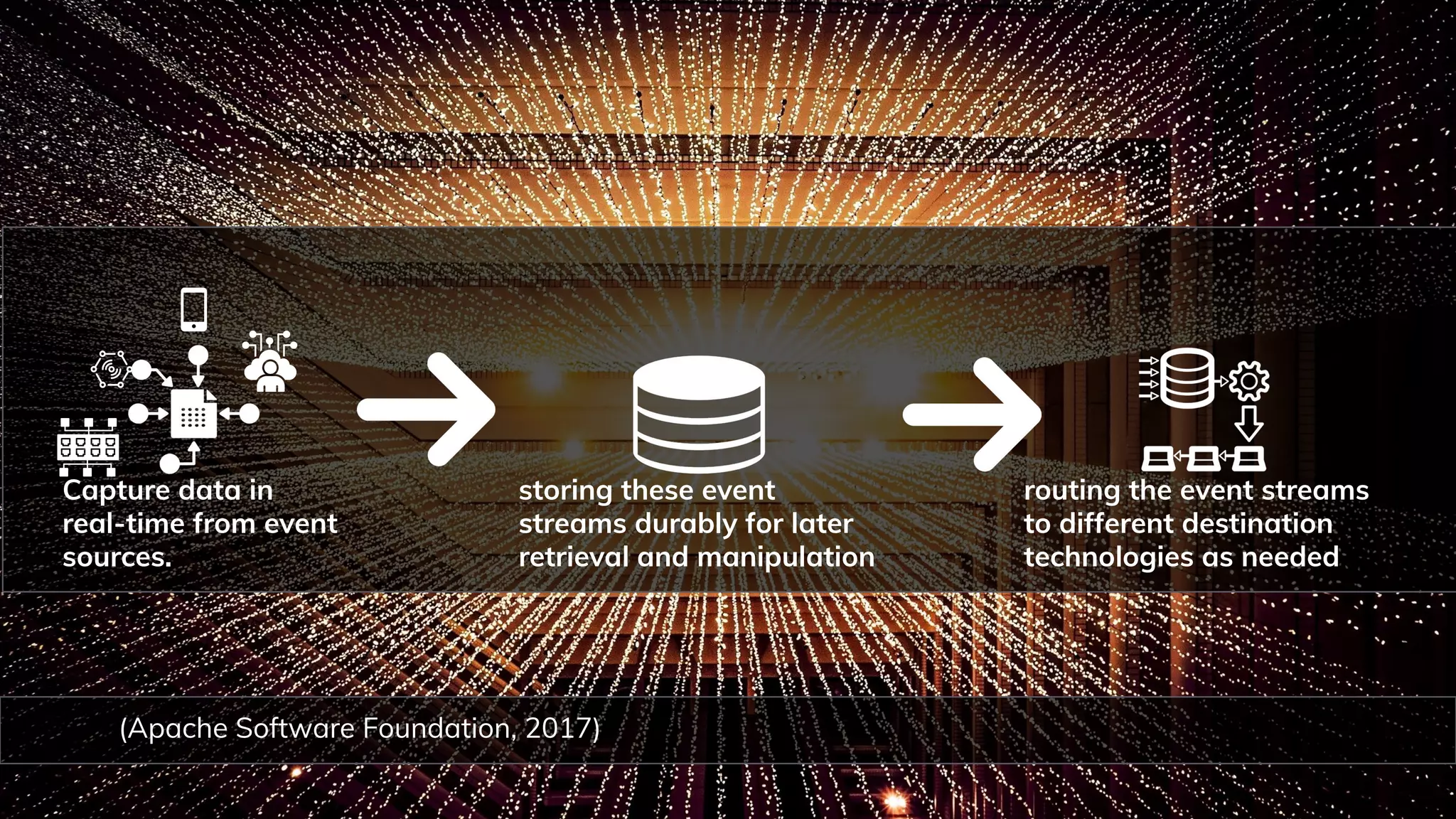
Explanation of web scraping, data wrangling, and event streaming as techniques in data operations.
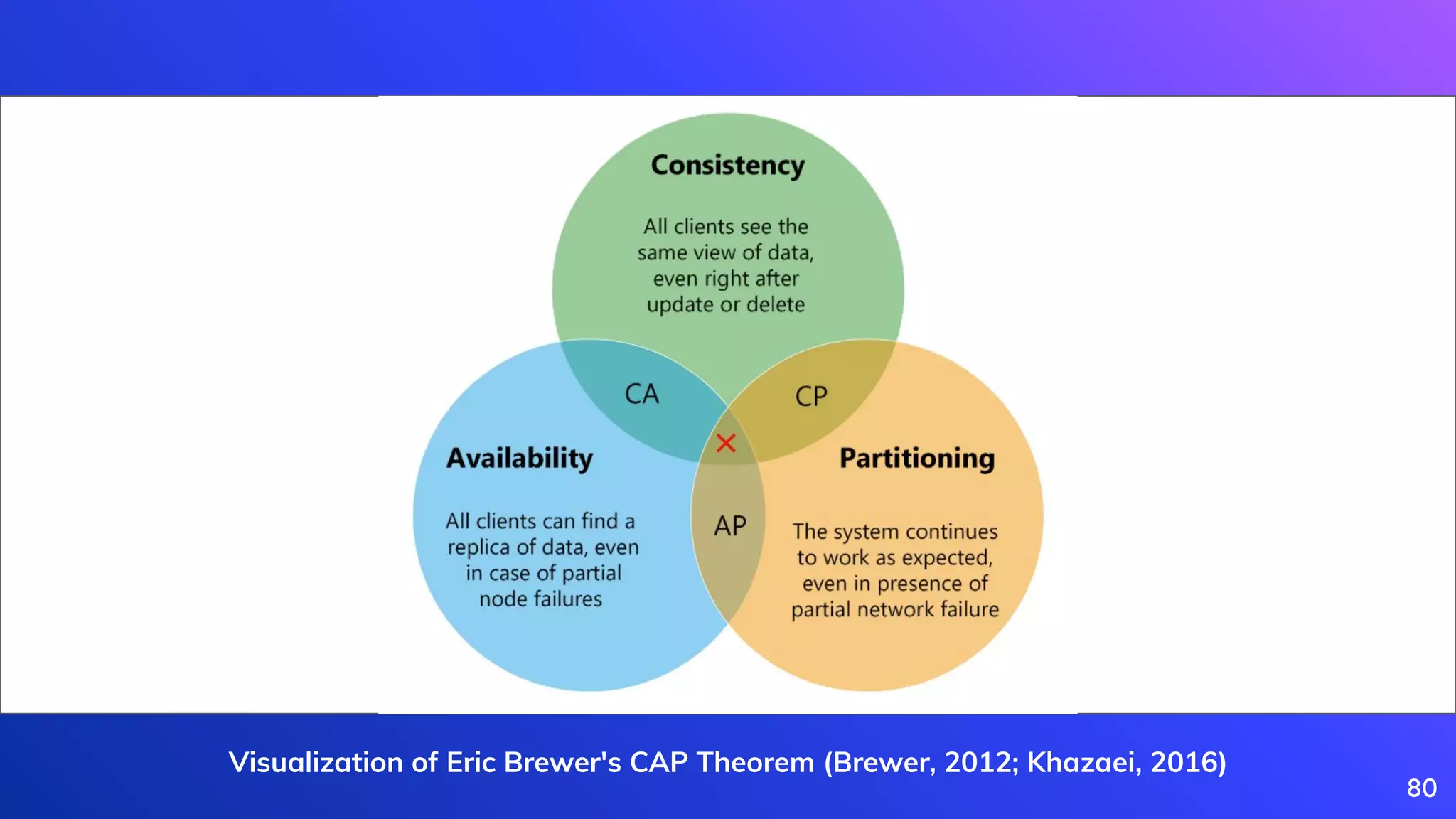
Introduction of CAP theorem illustrating consistency, availability, and partition tolerance in system design.
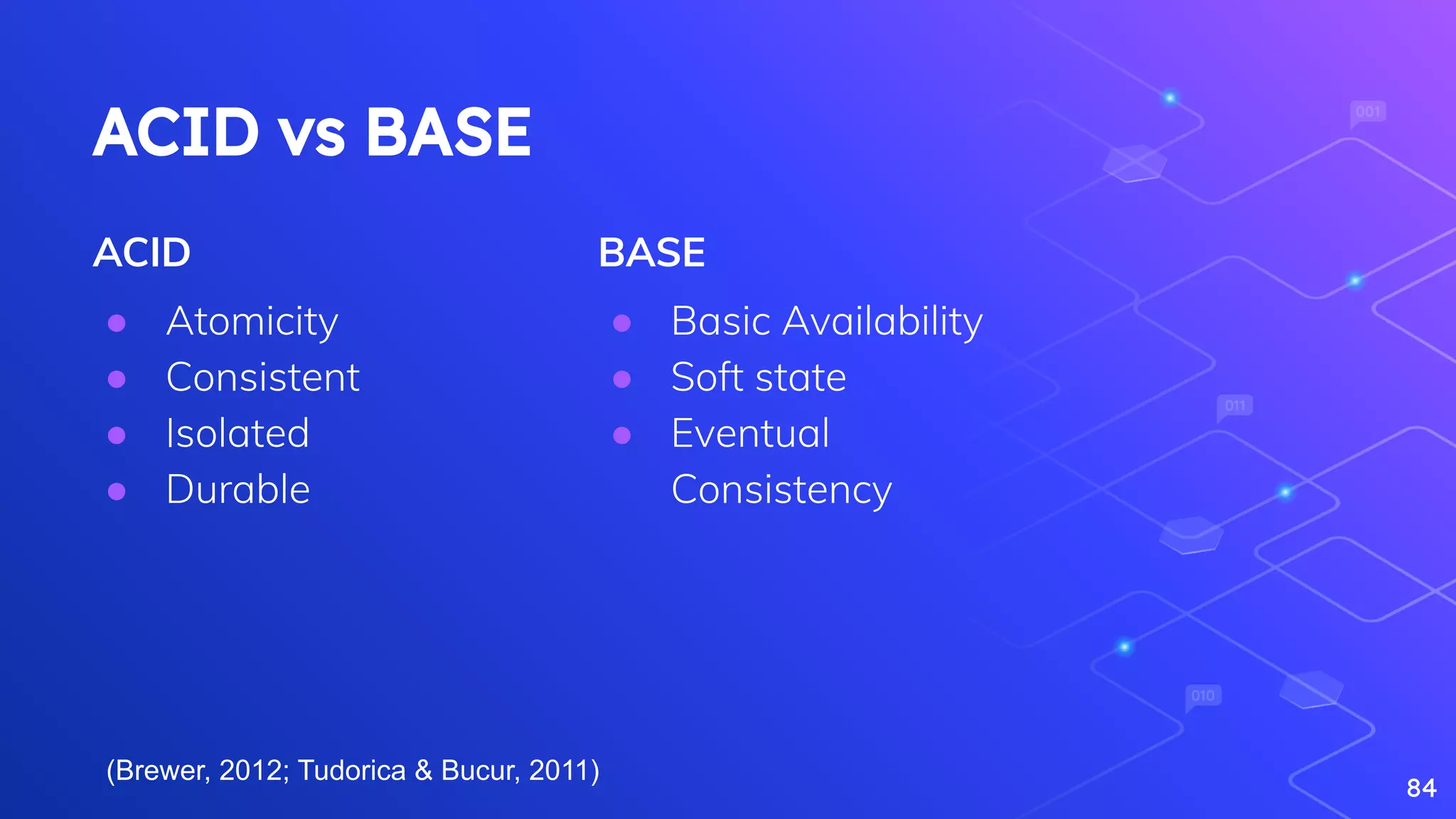
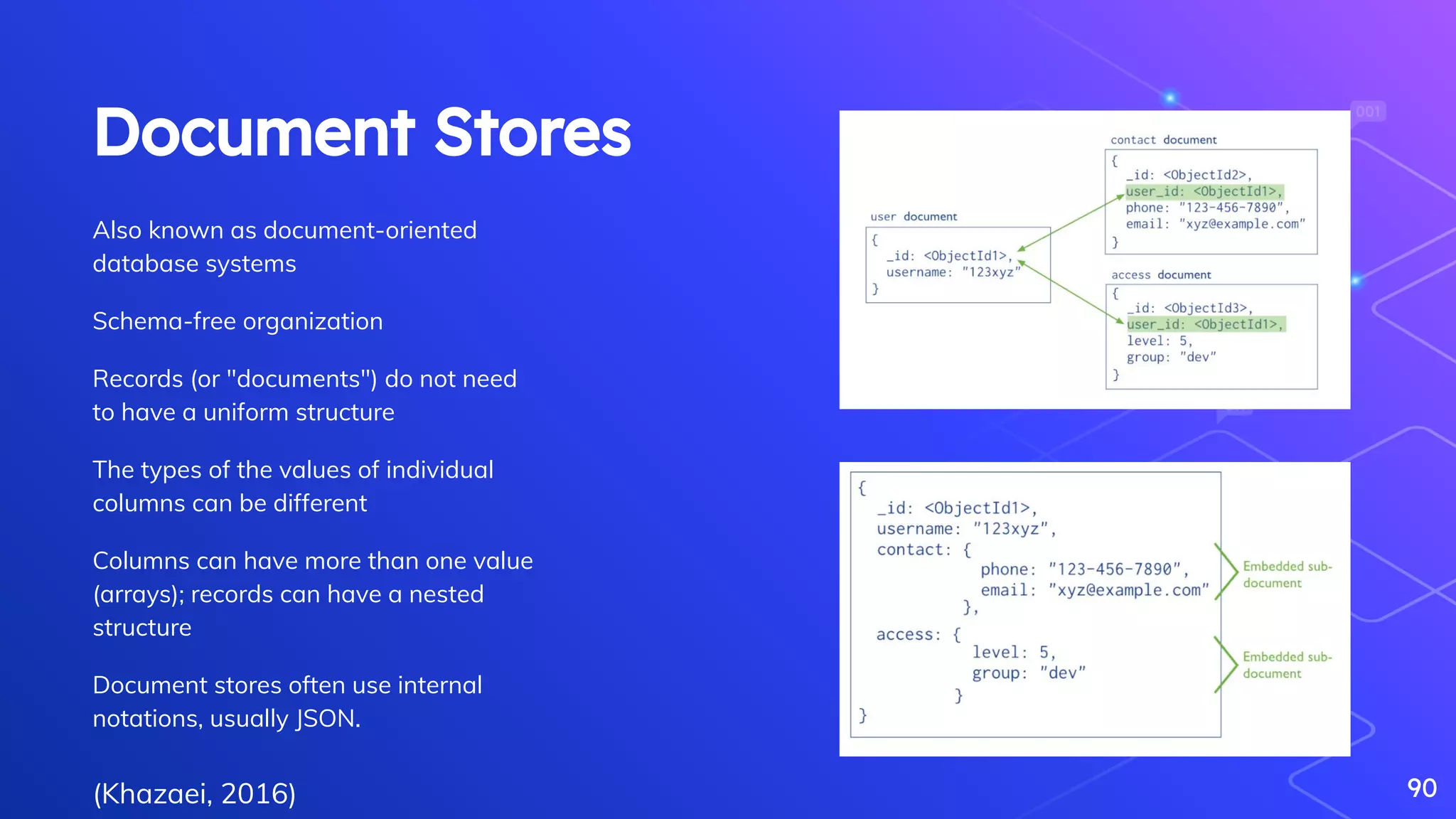
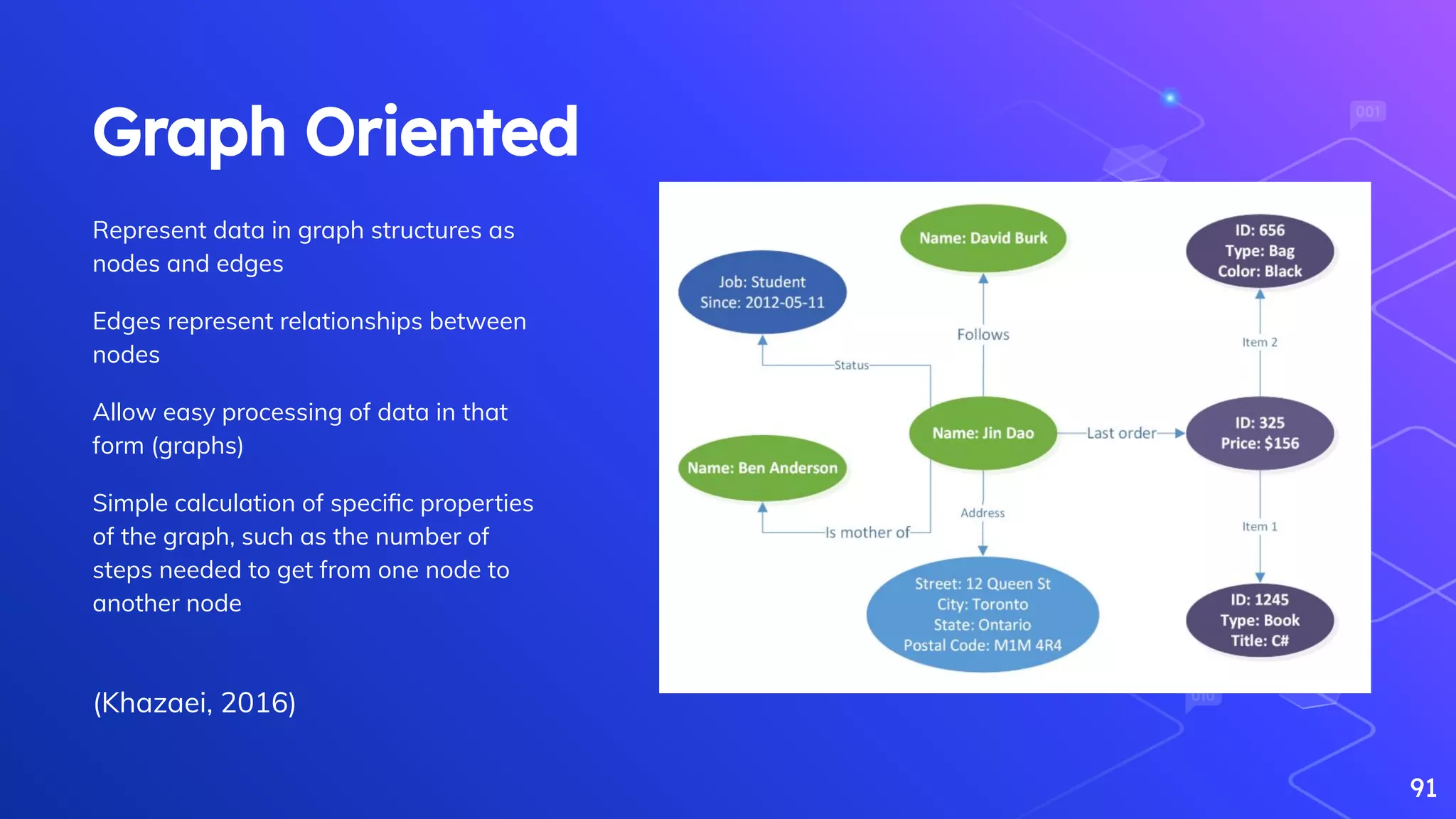
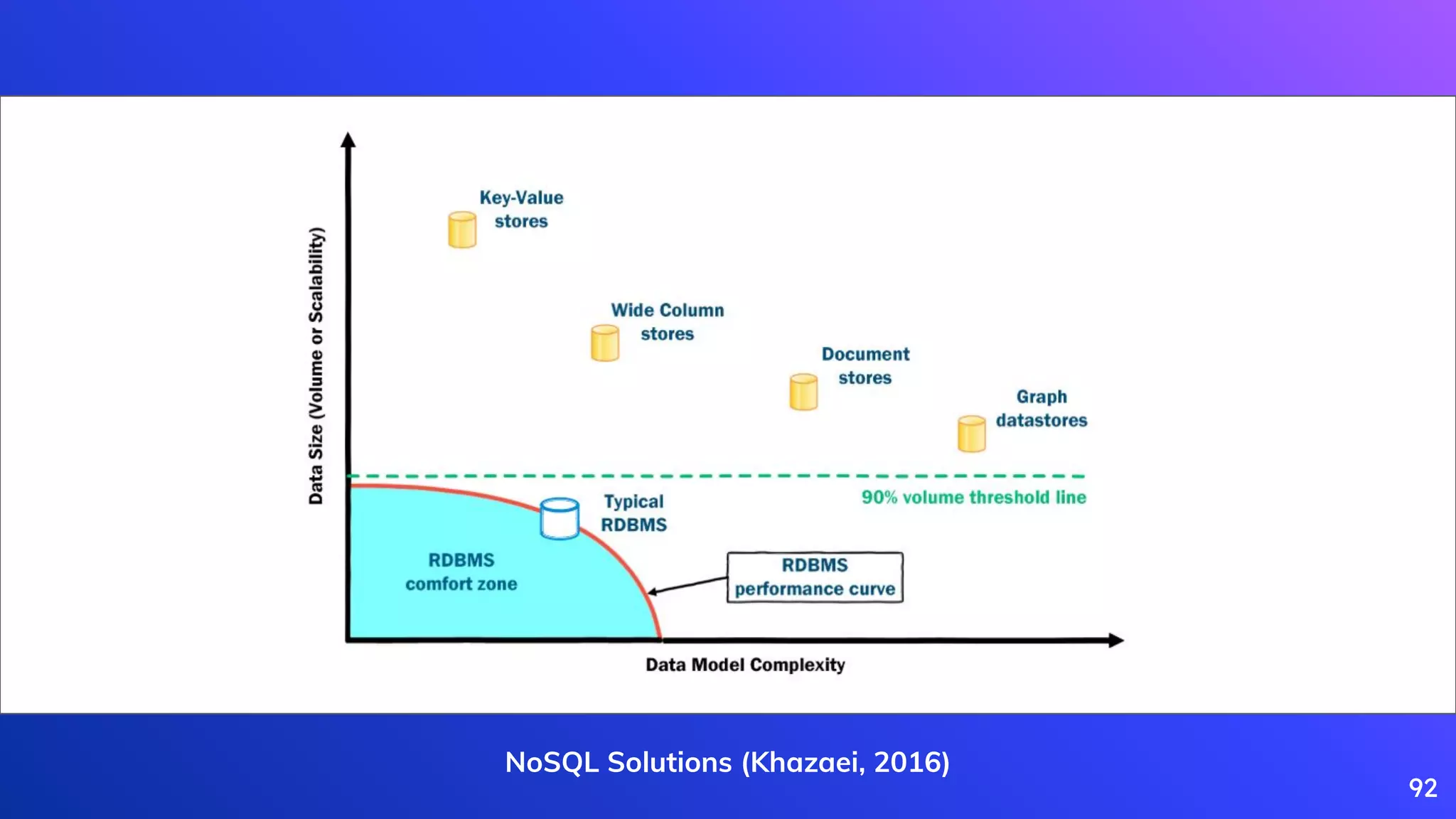
Overview of NoSQL databases, their types, advantages, and typical use cases.
Key takeaways emphasizing upskilling in data engineering and collaborative learning.


















































![[DSC Europe 25] Dusan Jovicic - AI Story: From on-prem to cloud and back agai...](https://cdn.slidesharecdn.com/ss_thumbnails/8kp49m6uq22ifnbwhfnk-2-251205085715-964d11a6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Nikola Rajovic - Hardware Technologies Under the Hood: RISC-V...](https://cdn.slidesharecdn.com/ss_thumbnails/o2gptrmtoyqndgoshwgq-dsc2025-tenstorrent-rajovic-251205090438-814685f5-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dragan Vucic - Building the Learning Organization - How AI Tr...](https://cdn.slidesharecdn.com/ss_thumbnails/8brigo2sbu6qur6gxrra-7-251205085715-6ae07d24-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Goran Obradovic - The Rise of Sovereign AI: Building the Regi...](https://cdn.slidesharecdn.com/ss_thumbnails/7nw2xxixrxqdxvrb5wca-6-251205085714-ab09a2ac-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Bogdan Daniel Maruneac - AI - It starts with you.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/odov3snhrcqs9hx5ny2n-4-251205085715-f1daacfe-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Dragana Ilic - AI for Big Data in Astronomy.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/8palya86qaatvjhva1ms-2-dragana-ilic-ai-ilic-251208151906-652b819c-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Max Talanov - Non digital NNs.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/wif8tr3gtua74qvtopke-non-digital-nns-251205090438-26b0eea6-thumbnail.jpg?width=640&height=640&fit=bounds)







