Downloaded 119 times


![Emerging Variety of Queries
Natural Language Queries instead of Keyword Represented Queries
“who is the best classical singer in India” instead of “best classical singer India”
Use of NL Queries increasing (Makoto et.al in [1])
Local Search Queries
“Where can I eat cheesecake right now?”
Context Dependent Queries (Interactive Question Answering
(Source: Bing – location set as US)](https://image.slidesharecdn.com/seminarpptupdated-141029001143-conversion-gate01/75/Techniques-For-Deep-Query-Understanding-3-2048.jpg)
![Background: How results are generated
Query Understanding
(which index parameters to
be used)
Review: Hotel ABC, Civil Lines:
I ate cheesecake, which was really
awesome. (4/5 star)
High Level Architecture of Search Mechanism (Source: Self Made)
INDEX
(Knowledge Base)
Document Understanding
(What and how to Index)
User Query
Results Ranking
Entities: Hotel ABC, cheesecake
Location: Civil Lines
Quality: 0.8
Time: 8:15 PM
“where can I eat cheesecake
right now?”
Data
(Text documents, User
Reviews, Blogs, Tweets,
Linkedin …)
[Time: 8:15 PM]
Intent: Hotel Search
Search for: cheesecake
Location: Civil lines
Time: 8:20 PM](https://image.slidesharecdn.com/seminarpptupdated-141029001143-conversion-gate01/75/Techniques-For-Deep-Query-Understanding-4-2048.jpg)
![Background: QU & Adv. In Search (Weotta in [3])
1. Basic Search
Direct text match based retrieval of documents
Restrict search space using facet values provided by user
Current day example: Online shopping sites
Mechanism in Basic Search (Source: Self Made)
Example of Facets (Source: Flipkart.com)](https://image.slidesharecdn.com/seminarpptupdated-141029001143-conversion-gate01/75/Techniques-For-Deep-Query-Understanding-5-2048.jpg)
![Background: QU & Adv. In Search (Weotta in [3])
2. Advanced Search
Ranking of result documents based on:
TF-IDF to identify more relevant documents
Website authority and popularity
Keyword weighting
Not Considered:
Context, NLP for semantic understanding
Location of query, time of query
Example: Google as was in its early stage](https://image.slidesharecdn.com/seminarpptupdated-141029001143-conversion-gate01/75/Techniques-For-Deep-Query-Understanding-6-2048.jpg)
![Background: QU & Adv. In Search (Weotta in [3])
3. Deep Search
What difference does it bring?
Requirements:
Semantic Understanding of Query
Knowledge of Context, previous tasks
User Understanding and Personalization](https://image.slidesharecdn.com/seminarpptupdated-141029001143-conversion-gate01/75/Techniques-For-Deep-Query-Understanding-7-2048.jpg)
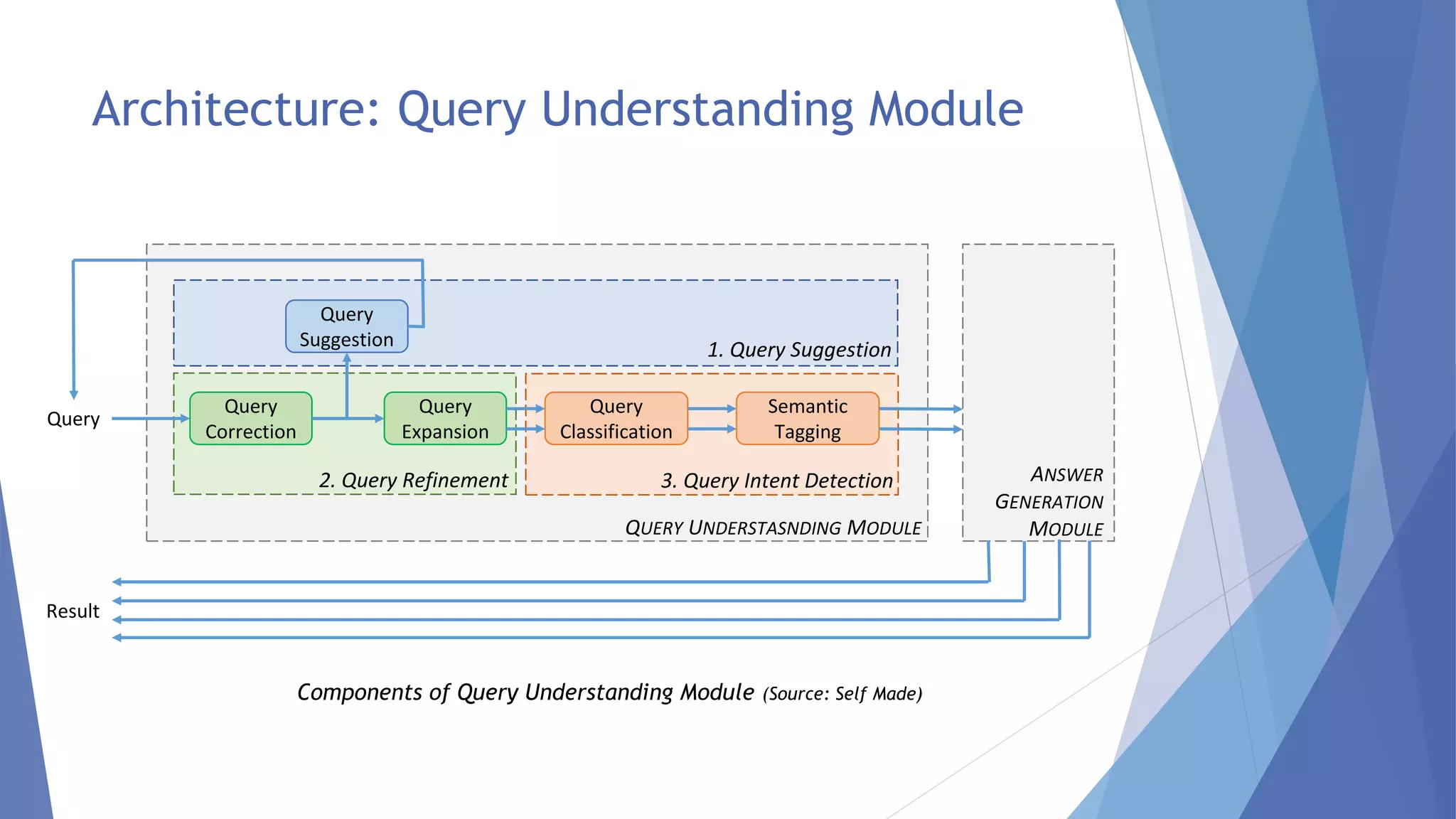
![Architecture: Query Understanding Module
Query
i) michael jordan berkley
ii) michael jordan NBA
Query
Suggestion
Query
Correction
Query
Expansion
i) michael jordan berkley: academic
ii) michael l. Jordan Berkley: academic
Query
Classification
Semantic
Tagging
Example of purpose of each Component (Source: Self Made)
michal jrdan
michael jordan
i) michael jordan berkley
ii) michael l. jordan berkley
i) [michael jordan: PersonName]
[berkley: Location]: academic
ii) [michael l. jordan: PersonName]
[berkley: Location]: academic](https://image.slidesharecdn.com/seminarpptupdated-141029001143-conversion-gate01/75/Techniques-For-Deep-Query-Understanding-9-2048.jpg)

![ Problem Modeled by Jiafeng et.al in [10] as
Original Query (푥 = 푥1 푥2 . . . 푥푛) Corrected Query (푦 = 푦1 푦2 . . . 푦푛)
Get y(complete sequence) which has maximum probability of occurrence, given the
sequence x.
Simple Technique
Assume terms independent take 푦푖 with max Pr 푦푖 푥푖
Prime Disadvantage:
Reality deviates a lot from assumption
Ex. “Lectures on machine learning”
Independent Corrections
Query Correction](https://image.slidesharecdn.com/seminarpptupdated-141029001143-conversion-gate01/75/Techniques-For-Deep-Query-Understanding-11-2048.jpg)
![ Restricting space of y for the given x
conditioned 푦푖 on operation also
표 = 표1 표2 … 표푛, such that 표푖 required to get 푦푖 from 푥푖
표푖 is operation like deletion, insertion of characters, etc.
Learning and Prediction
Dataset of (푥(1), 푦(1), 표(1)), . . . , (푥(푁), 푦(푁), 표(푁))
Features
log Pr(푦푖−1|푦푖 ), where the prob. calculated using corpus
Whether 푦푖 푖푠 표푏푡푎푖푛푒푑 푓푟표푚 푥푖 푎푓푡푒푟 표푝푒푟푎푡푖표푛 표푖 --{0|1}
Basic CRF-QR Model
Query Correction
Basic CRF-QR Model (Jiafeng et. al in [10])](https://image.slidesharecdn.com/seminarpptupdated-141029001143-conversion-gate01/75/Techniques-For-Deep-Query-Understanding-13-2048.jpg)
![ What is new?
Handles scenario with more than one refinements
Machine learm learn learning
Sequence of (sequence of operation)
표 = 표푖,1, 표푖,2, . . . 표푖,푛 i.e. multiple operations on each word
Intermediate results: 푧푖 = 푧푖,1푧푖,2 . . . 푧푖,푚−1
Extended CRF-QR
Query Correction
Extended CRF-QR Model (Jiafeng et. al in [10])](https://image.slidesharecdn.com/seminarpptupdated-141029001143-conversion-gate01/75/Techniques-For-Deep-Query-Understanding-14-2048.jpg)
![Query Suggestion
Purpose:
Suggest similar queries
Query auto-completion
Requirements
Context consideration [7]
Identifying Interleaved Tasks [9]
Personalized suggestion [2]
Suggestions on “iit r..”](https://image.slidesharecdn.com/seminarpptupdated-141029001143-conversion-gate01/75/Techniques-For-Deep-Query-Understanding-15-2048.jpg)
![Context aware Query Suggestion (Huanhuan et.al in [7])
Query Suggestion Mechanism (Source: [7])
Query Suggestion
Query – mapped Concept
Concept Suffix tree from log
Suggestion time: Transition on tree with each query’s concept
Suggest top queries of that state](https://image.slidesharecdn.com/seminarpptupdated-141029001143-conversion-gate01/75/Techniques-For-Deep-Query-Understanding-16-2048.jpg)
![Concept Suffix Tree
Concept Discovery
Queries clustered using set of clicked URLs
Feature vector 푞푖 =
푛표푟푚 푤푖푗 푖푓 푒푑푔푒 푒푖푗 푒푥푖푠푡푠
0 표푡ℎ푒푟푤푖푠푒
Each identified cluster is taken as a Concept
Concept Suffix Tree
Vertex: state after transition through a sequence of
concepts (of queries)
Transition in a session
C2C3C1: transition Beginning C1 C3 C2
Click-Through Bipartite
Query Suggestion
Context aware Query Suggestion (Huanhuan et.al in [7])](https://image.slidesharecdn.com/seminarpptupdated-141029001143-conversion-gate01/75/Techniques-For-Deep-Query-Understanding-17-2048.jpg)
![Query Suggestion
Task aware Query Suggestion (Allan et.al in [9])
Why task identification Important?
Considering Off-Task query in context adversely affect quality of recommendation
30% sessions contained multiple tasks (Zhen et.al in [8])
5% sessions have Interleaved tasks (Zhen et.al in [8])
Identify similar previous queries as On-Task
consider only On-Task queries as context
Effect of On-Task and Off-Task
queries](https://image.slidesharecdn.com/seminarpptupdated-141029001143-conversion-gate01/75/Techniques-For-Deep-Query-Understanding-18-2048.jpg)
![Query Suggestion
Task aware Query Suggestion (Allan et.al in [9])
Measures to evaluate similarity between two queries
Lexical Score: captures similarity at word level directly. Average of:
Jaccard Coefficient between trigrams from the two queries: how many common trigrams?
(1 - Levenshtein Edit Distance), which shows closeness at word level
Semantic Score: maximum of the following two
푠푤푖푘푖푝푒푑푖푒푎(푞푖 , 푞푗 ): cosine similarity of vector of tf-idf score of Wikipedia documents w.r.t the
two queries.
푠푤푖푘푡푖표푛푎푟푦 (푞푖 , 푞푗 ): similar to above on Wiktionary entries
Final Similarity(풒풊, 풒풋) = 휶 . Lexical Score + (1-휶) . Semantic Score
If Similarity(푞푖, Reference_q) greater than threshold 푞푖 is On-Task Query](https://image.slidesharecdn.com/seminarpptupdated-141029001143-conversion-gate01/75/Techniques-For-Deep-Query-Understanding-19-2048.jpg)
![Query Suggestion
Personalization in Query Suggestion (Milad et.al in [2])
On character hit of ‘i’
“Instagram” more popular for female below 25
“Imdb” more popular for male in 25-44.
Candidate queries generated by prior general method
Personalization by re-ranking candidate queries
Features for feedback earlier global rank
Original position
Original score
Short History Features
3-Gram similarity with just previous query
Avg. 3-gram similarity with all previous queries in the session](https://image.slidesharecdn.com/seminarpptupdated-141029001143-conversion-gate01/75/Techniques-For-Deep-Query-Understanding-20-2048.jpg)
![Query Suggestion
Personalization in Query Suggestion (Source: [2])
Long History Features
No. of times candidate query issued in past
Avg. 3-gram similarity with all previous queries in the past
Demographic Features
Candidate query frequency over queries by same age group
Candidate query likelihood -- same age group
Candidate query frequency -- same gender group
Candidate query likelihood -- same gender group
Candidate query frequency -- same region group
Candidate query likelihood -- same region group](https://image.slidesharecdn.com/seminarpptupdated-141029001143-conversion-gate01/75/Techniques-For-Deep-Query-Understanding-21-2048.jpg)

![Query Expansion
Path Constrained Random Walk (Jianfeng et.al in [11])
Exploiting search logs for identifying terms having similar end result
Search log data of <Query, Document> clicks
Graph Representation
Node Q: seed query
Nodes Q’: queries in search log
Nodes D: documents
Nodes W: words that occur in queries and documents
Word nodes are the candidate expansion terms
Edges have scoring function
Represents probability of transition from start node
to end node
Search Log as Graph](https://image.slidesharecdn.com/seminarpptupdated-141029001143-conversion-gate01/75/Techniques-For-Deep-Query-Understanding-23-2048.jpg)
![Query Expansion
Path Constrained Random Walk (Jiafeng et.al in [11])
Probability of using w as an expansion word?
Product of probabilities in Paths starting at
node Q and ending at w
Top probable words picked, obtained from
random walk
Search Log as Graph](https://image.slidesharecdn.com/seminarpptupdated-141029001143-conversion-gate01/75/Techniques-For-Deep-Query-Understanding-24-2048.jpg)
![Query Classification
Classifying given query in a predefined Intent Class
Ex. michael Jordan berkley: academic
Precise intent by sequence of nodes from root to leaf
More challenging than document classification
Short length
Keyword representation, makes more ambiguous
Ex. query “brazil germany”
Older basic techniques
Example Taxonomy (Source: [6])
Considering single query statistical techniques like 2-gram/3-gram inference](https://image.slidesharecdn.com/seminarpptupdated-141029001143-conversion-gate01/75/Techniques-For-Deep-Query-Understanding-25-2048.jpg)
![Query Classification
Context aware Query Classification (Huanhuan et.al in [6])
Resolving ambiguity using context
Previous Queries ∈ sports, then “Michael Jordan” sports (Basketball Player)
Previous Queries ∈ academic, then “Michael Jordan” academic (ML professor)
Use of CRF (because training and prediction on sequence)
Local Features
Query Terms: Each 푞푡 supports a target category
Pseudo Feedback:
푞푡 with concept 푐푡, submitted to an external web directory
How many of top M results have 푐푡 concept?
Implicit Feedback:
Instead of Top M results – only the clicked documents taken](https://image.slidesharecdn.com/seminarpptupdated-141029001143-conversion-gate01/75/Techniques-For-Deep-Query-Understanding-26-2048.jpg)
![Query Classification
Context aware Query Classification (Huanhuan et.al in [6])
Contextual Features
Direct association between adjacent labels
Number of occurrences of adjacent labels < 푐푡−1, 푐푡 >
Higher weight higher probability of transit from 푐푡−1to 푐푡
Taxonomy-based association between adjacent labels
Given pair of adjacent labels < 푐푡−1, 푐푡 > at level n
n-1 features of taxonomy-based association between 푐푡−1, 푐푡 considered
e.g. Computer/Software related to Computer/Hardware, matching at (n-1)th level
Computer](https://image.slidesharecdn.com/seminarpptupdated-141029001143-conversion-gate01/75/Techniques-For-Deep-Query-Understanding-27-2048.jpg)
![Semantic Tagging
Identifies the semantic concepts of a word or phrase
[michael jordan: PersonName] [berkley: Location]: academic
Useful only if phrases in documents also tagged
Shallow Parsing Methods
Part of Speech Tags: e.g. Clubbing consecutive nouns for Named Entity Recognition
Disadvantage: Sentence Level Long Segments can’t be identified](https://image.slidesharecdn.com/seminarpptupdated-141029001143-conversion-gate01/75/Techniques-For-Deep-Query-Understanding-28-2048.jpg)


![References
[1] Makoto P. Kato, Takehiro Yamamoto, Hiroaki Ohshima and Katsumi Tanaka, "Cognitive
Search Intents Hidden Behind Queries: A User Study on Query Formulations," in WWW
Companion, Seoul, Korea, 2014.
[2] Milad Shokouhi, "Learning to Personalize Query Auto-Completion," in SIGIR, Dublin,
Ireland, 2013.
[3] Weotta, "Deep Search," 10 6 2014. [Online]. Available:
http://streamhacker.com/2014/06/10/deepsearch/. [Accessed 6 8 2014].
[4] W. Bruce Croft, Michael Bendersky, Hang Li and Gu Xu, "Query Understanding and
Representation," SIGIR Forum, vol. 44, no. 2, pp. 48-53, 2010.
[5] Jingjing Liu, Panupong Pasupat, Yining Wang, Scott Cyphers and Jim Glass, "Query
Understanding Enhanced by Hierarchical Parsing Structures," in ASRU, 2013.
[6] Huanhuan Cao, Derek Hao Hu, Dou Shen and Daxin Jiang, "Context-Aware Query
Classification," in SIGIR, Boston, Massachusetts, USA, 2009.](https://image.slidesharecdn.com/seminarpptupdated-141029001143-conversion-gate01/75/Techniques-For-Deep-Query-Understanding-32-2048.jpg)
![References (Continued…)
[7] Huanhuan Cao, Daxin Jiang, Jian Pei, Qi He, Zhen Liao, Enhong Chen, Hang Li,
"Context-Aware Query Suggestion by Mining Click-Through and Session Data," in
KDD, Las Vegas, Nevada, USA, 2008.
[8] Zhen Liao, Yang Song, Li-wei He and Yalou Huang, "Evaluating the Effectiveness of
Search Task Trails," in WWW, Lyon, France, 2012.
[9] Allan, Henry Feild and James, "Task-Aware Query Recommendation," in SIGIR,
Dublin, Ireland, 2013.
[10] Jiafeng Guo, Gu Xu, Hang Li and Xueqi Cheng, "A Unified and Discriminative
Model for Query Refinement,“ in SIGIR, Singapore, 2008.
[11] Jianfeng Gao, Gu Xu and Jinxi Xu, "Query Expansion Using Path-Constrained
Random Walks," in SIGIR, Dublin, Ireland, 2013.](https://image.slidesharecdn.com/seminarpptupdated-141029001143-conversion-gate01/75/Techniques-For-Deep-Query-Understanding-33-2048.jpg)


The document summarizes techniques for deep query understanding in search systems. It discusses query understanding, which involves understanding a user's information need from their query. This allows for query correction, suggestion, expansion, classification and semantic tagging. Query correction reformulates ill-formed queries. Query suggestion provides similar queries. Query expansion adds synonyms to broaden results. Query classification determines the intent or topic of the query. Semantic tagging identifies entities in the query. The document outlines various models for these techniques, including using contextual information and graph representations of search logs.
![Query Understanding at LinkedIn [Talk at Facebook]](https://cdn.slidesharecdn.com/ss_thumbnails/8c193eb7-3e7f-4ce4-8517-ee9ae67ab9de-160410073847-thumbnail.jpg?width=640&height=640&fit=bounds)





















































































