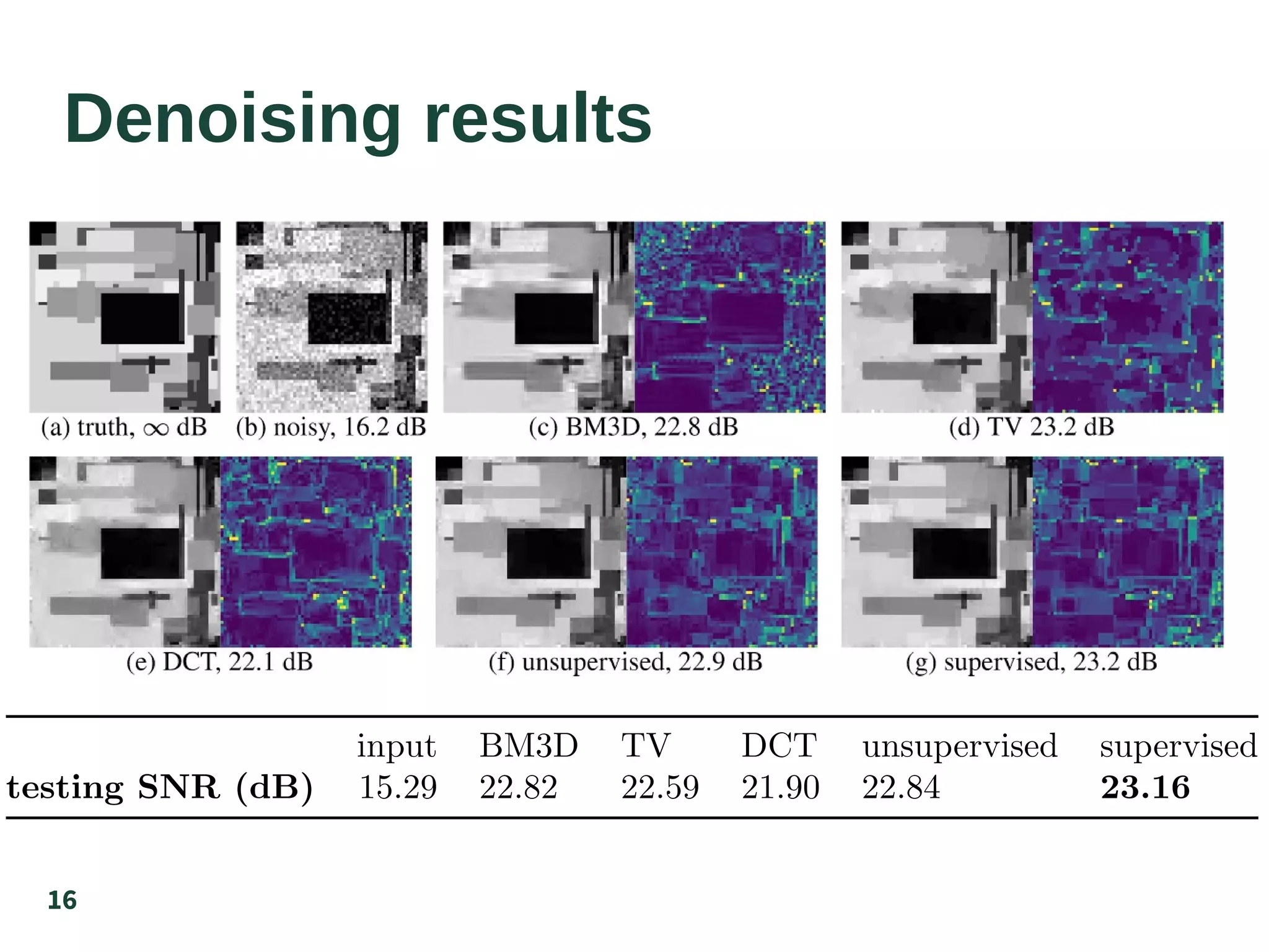
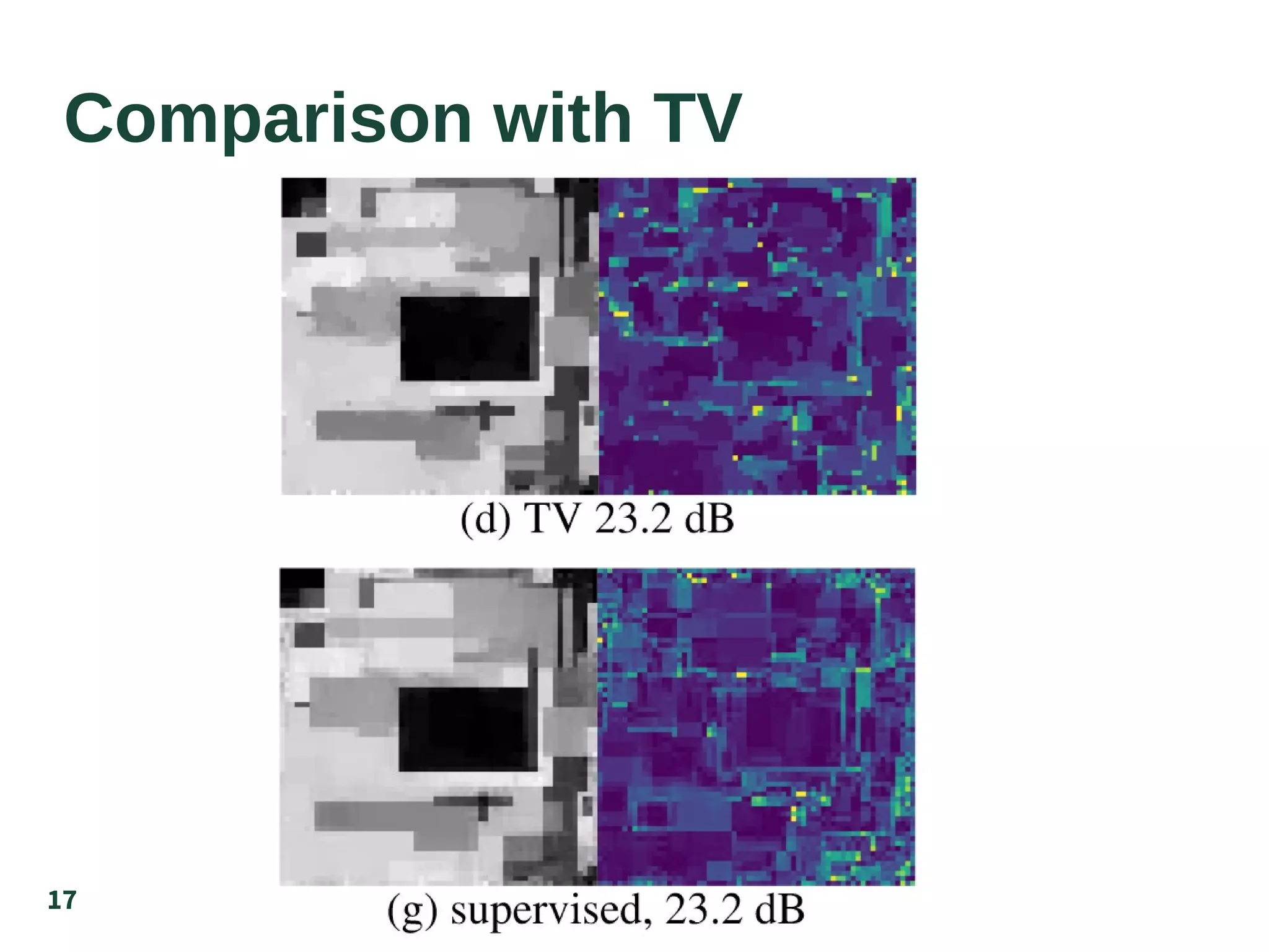
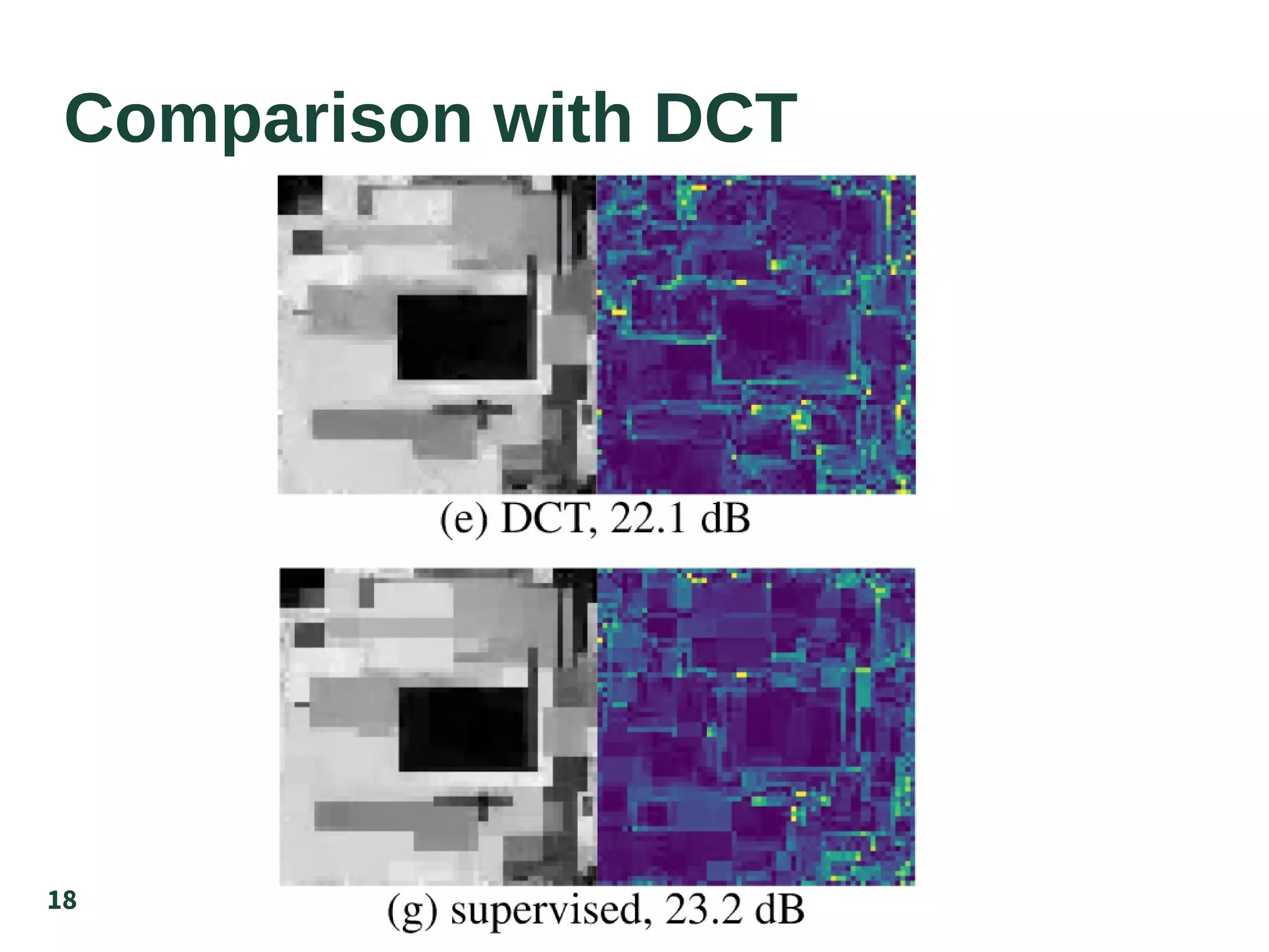
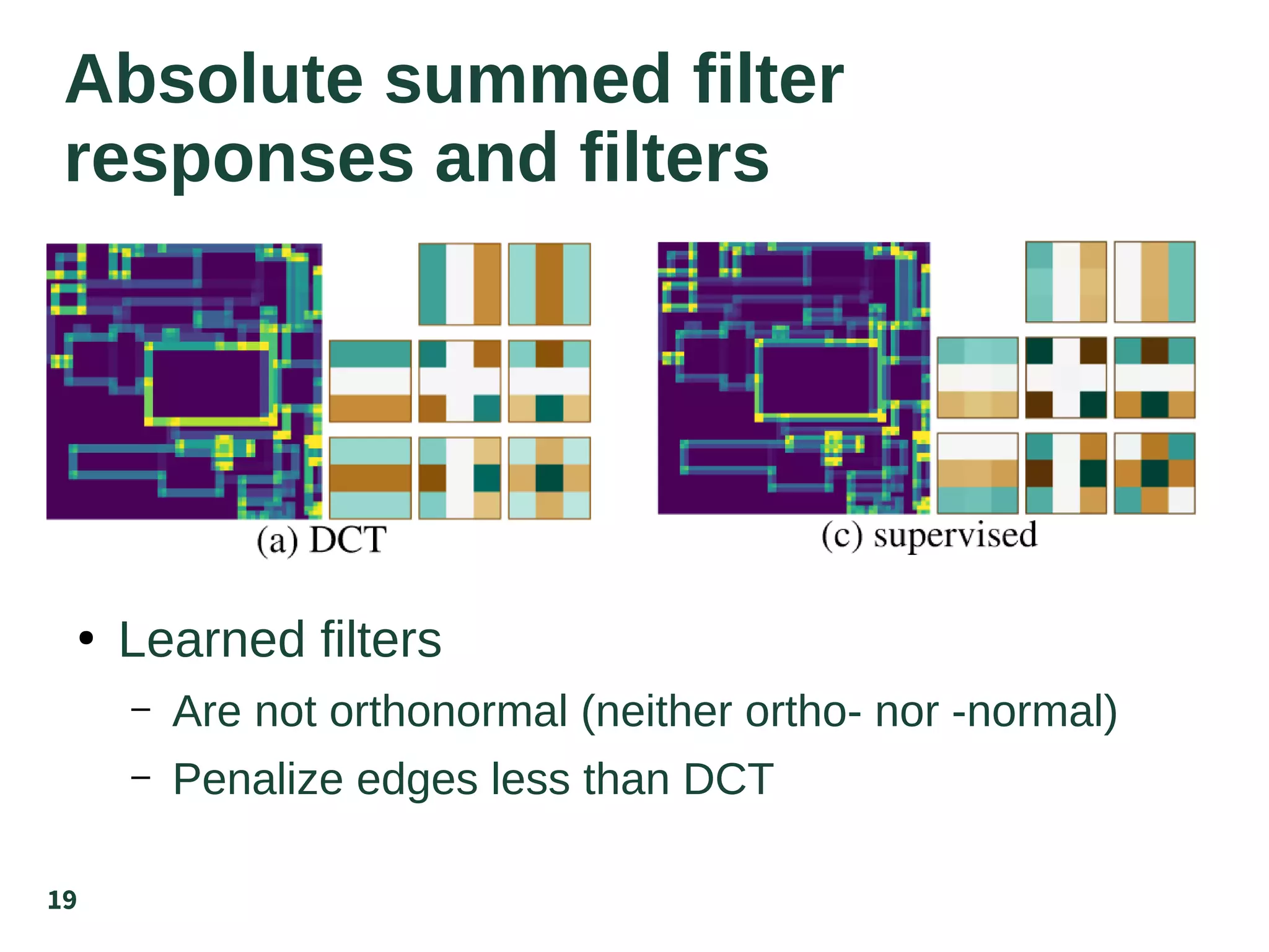
The document discusses the supervised learning of sparsity-promoting regularizers for denoising, comparing various methods such as learned operators with traditional techniques like TV and DCT. It presents a new approach involving gradient descent and provides results from denoising experiments using 64x64 images affected by Gaussian noise. The authors suggest future research directions, including comparisons with CNN-based denoising and extensions to nonuniqueness in reconstruction problems.









![14
Denoising experiment
●
Images are 64x64, range is [0,1]
●
Additive IID Gaussian noise, stdev=0.1
●
10 training, 10 testing](https://image.slidesharecdn.com/20200707siamislearnreg-200706234221/75/Supervised-Learning-of-Sparsity-Promoting-Regularizers-for-Denoising-14-2048.jpg)



![22
References
●
K. H. Jin, M. T. McCann, E. Froustey, and M. Unser, “Deep Convolutional Neural Network
for Inverse Problems in Imaging,” IEEE Transactions on Image Processing, vol. 26, no. 9,
pp. 4509–4522, Sep. 2017.
●
J. Adler and O. Öktem, “Solving ill-posed inverse problems using iterative deep neural
networks,” Inverse Problems, vol. 33, no. 12, p. 124007, Nov. 2017.
●
E. J. Candes, J. Romberg, and T. Tao, “Robust uncertainty principles: exact signal
reconstruction from highly incomplete frequency information,” IEEE Transactions on
Information Theory, vol. 52, no. 2, pp. 489–509, Feb. 2006.
●
G. Peyré and J. M. Fadili, “Learning analysis sparsity priors,” in Sampling Theory
and Applications, Singapore, Singapore, May 2011, p. 4.
●
J. Mairal, F. Bach, and J. Ponce, “Task-driven dictionary learning,”IEEE Transactions on
Pattern Analysis and Machine Intelligence, vol. 34, no. 4, pp. 791–804, Apr. 2012.
●
P. Sprechmann, R. Litman, T. Ben Yakar, A. M. Bronstein, and G. Sapiro, “Supervised
sparse analysis and synthesis operators,” inAdvances in Neural Information Processing
Systems 26, 2013, pp. 908–916.
●
Y. Chen, T. Pock, and H. Bischof, “Learning`1-based analysis and synthesis sparsity priors
using bi-level optimization,”arXiv:1401.4105 [cs.CV], Jan. 2014.
●
Y. Chen, R. Ranftl, and T. Pock, “Insights into analysis operator learning: From patch-
based sparse models to higher order MRFs,”IEEE Transactions on Image Processing, vol.
23, no. 3, pp. 1060–1072, Mar. 2014.
●
T. P. Minka, “Old and new matrix algebra useful for statistics,” MIT Media Lab, 2000.](https://image.slidesharecdn.com/20200707siamislearnreg-200706234221/75/Supervised-Learning-of-Sparsity-Promoting-Regularizers-for-Denoising-22-2048.jpg)















































