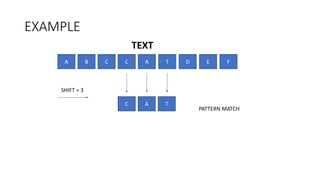
String matching algorithms try to find where a pattern string is found within a larger text string. The naive string matching algorithm compares characters one by one between the pattern and each substring of the text of the same length. The Rabin-Karp algorithm uses a rolling hash to quickly compare the hash of the pattern to the hash of each substring, only doing a full character comparison if the hashes match. Both algorithms output the starting positions in the text where the pattern is found.





![PSEUDO-CODE
• NaiveStringMatch(Text, Pattern):
• n = length(Text)
• m = length(Pattern)
• for i = 0 to n - m
• j = 0
• while j < m and Pattern[j] = Text[i + j]
• j = j + 1
• if j = m
• print "Pattern found at position", i](https://image.slidesharecdn.com/stringmatchingalgorithm-1-240318035616-5e667b51/85/String-Matching-algorithm-String-Matching-algorithm-String-Matching-algorithm-6-320.jpg)

![PSEUDO-CODE In this pseudo-code:
• T is the text
• P is the pattern
• d is the number of
characters in the input set.
• q is a prime number used as
modulus
• n = length[T]
• m = length[P]
• h = pow(d, m-1) mod q
• P = 0
• t0 = 0
• # Preprocessing: Compute the hash value of the pattern and the first substring of T
• for i = 1 to m
• P = (d*P + P[i]) mod q
• t0 = (d*t0 + T[i]) mod q
• # Matching: Slide the window through T and compare hash values
• for s = 0 to n-m
• if P = ts
• if P[1.....m] = T[s+1.....s+m] if s < n-m
• ts+1 = (d*(ts - T[s+1]*h) + T[s+m+1]) mod q](https://image.slidesharecdn.com/stringmatchingalgorithm-1-240318035616-5e667b51/85/String-Matching-algorithm-String-Matching-algorithm-String-Matching-algorithm-8-320.jpg)













































![Gp 27[string matching].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/gp27stringmatching-230422183348-6f0879e9-thumbnail.jpg?width=640&height=640&fit=bounds)




















