Report
Share
Recommended
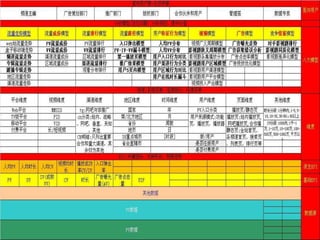
用户画像介绍
This document discusses several machine learning and big data topics including:
1. It discusses different streaming processing frameworks like Spark Streaming, Storm, and micro-batch processing.
2. It also discusses Elasticsearch and HBase for storage and analytics and how they differ in terms of being schema-free, using in-memory indexes, and supporting SQL queries.
3. Finally, it provides the results of different machine learning models like logistic regression, decision trees, and gradient boosted trees on a prediction problem and compares their precision, recall, and false positive rates.
视频网站全视角分析解决方案 初稿
分析目的 2
全站流量分析 3
全站流量日常分析 3
栏目布局优化分析 4
功能性分析 4
全站视频分析 4
视频概况分析 4
频道首页热点视频区域分析 5
短视频推荐分析 5
长视频推荐区域分析 6
全站首页热点区域视频分析 7
全站广告投放分析 8
日志结构 8
统计指标 8
点击广告用户特征 9
广告精准投放模型 9
用户行为模式分析 10
付费用户群体分类 10
用户首次付费行为影响因素 10
付费用户重复付费模式研究 10
免费客户转换为付费客户预测 10
数据科学家资源
This document lists various data science resources including:
1) Lists of data mining blogs and analytic websites maintained by others.
2) A list of data science resources including books, companies, training, and vendors maintained on the DataShaping website.
3) Vincent's favorite books on topics like natural language processing, statistics, data mining, and machine learning.
4) Internal resources on the Analyticbridge website including news, jobs, training courses, conferences, and more.
Recommended
用户画像介绍
This document discusses several machine learning and big data topics including:
1. It discusses different streaming processing frameworks like Spark Streaming, Storm, and micro-batch processing.
2. It also discusses Elasticsearch and HBase for storage and analytics and how they differ in terms of being schema-free, using in-memory indexes, and supporting SQL queries.
3. Finally, it provides the results of different machine learning models like logistic regression, decision trees, and gradient boosted trees on a prediction problem and compares their precision, recall, and false positive rates.
视频网站全视角分析解决方案 初稿
分析目的 2
全站流量分析 3
全站流量日常分析 3
栏目布局优化分析 4
功能性分析 4
全站视频分析 4
视频概况分析 4
频道首页热点视频区域分析 5
短视频推荐分析 5
长视频推荐区域分析 6
全站首页热点区域视频分析 7
全站广告投放分析 8
日志结构 8
统计指标 8
点击广告用户特征 9
广告精准投放模型 9
用户行为模式分析 10
付费用户群体分类 10
用户首次付费行为影响因素 10
付费用户重复付费模式研究 10
免费客户转换为付费客户预测 10
数据科学家资源
This document lists various data science resources including:
1) Lists of data mining blogs and analytic websites maintained by others.
2) A list of data science resources including books, companies, training, and vendors maintained on the DataShaping website.
3) Vincent's favorite books on topics like natural language processing, statistics, data mining, and machine learning.
4) Internal resources on the Analyticbridge website including news, jobs, training courses, conferences, and more.
How to Perform Churn Analysis for your Mobile Application?
For every marketer of mobile application, acquiring new customers certainly requires more effort in terms of time and money. On the other hand, firm can always focus on maintaining existing customer base and gain maximum out of them. If this is the case, then predictive analysis will be the correct approach for this situation.
The primary goal of this webinar is to predict segment of Mobile application users,
* Who will uninstall the app
* Remain inactive (which will be also termed as a churner) for quite long time and are expected to churn.
Churn analysis is the approach by which we will predict the likelihood of this event to occur.
Our webinar covers:
* How to extract data from Google Analytics using R
* How to build churn model in R
* Identifying the customer/subscriber segment that are classified based on past data pattern, who are likely to churn (Study customer behavior Patterns)
Watch Full Webinar - http://www.tatvic.com/webinar/churn-analysis-for-mobile-application/
Data Tactics Analytics Brown Bag (Aug 22, 2013)
This document provides an overview and agenda for a brown bag presentation on analytics services. The presentation includes introductions of the analytics team, discussions of why analytics are important both for business and practical reasons, and case studies of identifying smugglers and analyzing text data. The presentation emphasizes a philosophy of not being "data agnostic" and using modes of inquiry like induction and abduction rather than deduction.
W3CTech美团react专场-Thinking in React
拥抱未来但并不局限于标准的 React,有哪些叹为观止的设计以确保其易用性和高性能?为什么在双向绑定大行其道时 React 却使用单向数据流的设计?仅关注 UI 层的 React 其当前的生态圈还有哪些方面值得建设?
美团技术沙龙01 - 58到家服务的订单调度&数据分析技术
到家服务的订单,调度需要综合商家情况(是否有时间,当前位置)、订单情况(时间,地点)、用户情况(用户等级,历史消费记录)
为了满足业务需,在短短半年时间内从策略上,架构上做出了多个版本上的迭代。跟大家分享走过的路.未来迁移到云平台的思考.
美团点评技术沙龙09 - 外卖O2O的用户画像实践
美团外卖经过3年的飞速发展,达到了上亿用户,每天数百万订单的规模,留存了大量的用户数据。如何充分挖掘这些用户数据以更好地帮助外卖的发展是一个重大课题。同时外卖的高频O2O的特点也带来了一些新的问题需要解决。本报告将分享我们在助外卖吸引新的客户、留存已有用户以及用户订单数据挖掘的实践。
数据分析系统架构设计
数据分析平台及专题分析报告中新增的分析指标越来越多,体系建设越来越完善,但随着业务的发展、分析的深入,乐视数据分析指标体系建设仍将是未来一段时间的工作重点,对于分析指标特别的KPI指标的构建我们将围绕三个原则进行展开:
可量化:“可量化的才是可管理的”,这里是指我们要围绕我们的核心业务、用户、流程管理进行可量化的指标体系建设,我们把它划分为分为成本量化(时间成本、带宽成本、硬件成本、软件成本)、效益量化(流量效益、播放量效益、用户量效益)、效率量化(效益与成本比)、重点产品及功能可度量、关键业务流程可度量。
可评价:是指建立的指标能够对用户、产品或运维等优劣、好坏等进行综合评价
可优化:通过量化与评价体系确定产品状况与提升目标,建立优化目标并跟踪优化效果
数据部的工作目标是希望通过我们努力工作以及与相关部门的通力合作,力求达到以下几点目标:
分析并提升用户体验
分析并优化页面布局
分析与提升视频价值
分析并助力运维效果
为高层决策提供价值信息
美团技术沙龙03 - 实时数据仓库解决方案
美团网是为消费者提供本地生活服务的O2O公司。业务发展速度快,模式复杂,有大量的实时数据运营和分析需求。为了提高运营的效率,我们基于开源的Storm,提供了美团实时数据仓库解决方案。本次分享,将会介绍美团基于实时计算平台的"RtDW直播间"产品,以及在构建实时数据仓库过程中的经验总结。
美团点评技术沙龙09 - 一个用户行为分析产品的设计与实现
神策分析是一个可以私有化部署的用户行为分析产品,支持每个实例每天十亿级别用户行为数据的秒级导入与秒级查询延迟。本次分享会以产品的功能设计与性能指标为出发点,详细介绍整个系统的技术选型、整体架构、数据模型、技术实现,以及我们团队一年多的开发演进过程中所遇到的问题。
暴走漫画数据挖掘从0到1
暴走漫画是国内在年轻人中颇具影响力的文化公司,产品包括社区,日报,游戏,视频。然而,随着暴漫用户的增长,运营的工作越来越重,也越来越需要照顾不同的用户。这时候数据服务团队应运而生。来到暴漫后,主要主导了 3 个方面的数据服务:搜索,推荐。这次主要和大家分享一点实践方面的经验,包括技术架构的选择,算法策略的选择等。
Churn Modeling For Mobile Telecommunications
This document summarizes Salford Systems' participation in an international competition to predict customer churn for a major mobile provider. Salford Systems used an ensemble of decision tree models called TreeNet to predict churn with significantly higher accuracy than other methods. TreeNet models achieved a top decile lift of 3.01 and Gini coefficient of 0.400 on future churn predictions, substantially better than the average and second place method. The document outlines the data and task, TreeNet methodology, results, and conclusions that TreeNet was key to winning due to its superior predictive performance.
Presentation Churn Management
This document discusses churn management in mobile communications. It defines churn as customer attrition or loss and churn rate as the number of customers who discontinue service divided by the total number of customers. It identifies reasons for churn such as easy switching between providers and inadequate services. It discusses types of churn, data transformation for modeling, identifying customers' propensity to churn, and calculating customer profitability. Finally, it outlines strategies for reducing churn such as identifying valuable customers and developing win-back policies.
RHadoop, R meets Hadoop
(Presented by Antonio Piccolboni to Strata 2012 Conference, Feb 29 2012).
Rhadoop is an open source project spearheaded by Revolution Analytics to grant data scientists access to Hadoop’s scalability from their favorite language, R. RHadoop is comprised of three packages.
- rhdfs provides file level manipulation for HDFS, the Hadoop file system
- rhbase provides access to HBASE, the hadoop database
- rmr allows to write mapreduce programs in R
rmr allows R developers to program in the mapreduce framework, and to all developers provides an alternative way to implement mapreduce programs that strikes a delicate compromise betwen power and usability. It allows to write general mapreduce programs, offering the full power and ecosystem of an existing, established programming language. It doesn’t force you to replace the R interpreter with a special run-time—it is just a library. You can write logistic regression in half a page and even understand it. It feels and behaves almost like the usual R iteration and aggregation primitives. It is comprised of a handful of functions with a modest number of arguments and sensible defaults that combine in many useful ways. But there is no way to prove that an API works: one can only show examples of what it allows to do and we will do that covering a few from machine learning and statistics. Finally, we will discuss how to get involved.
churn prediction in telecom
The document discusses machine learning algorithms for predicting customer churn in a prepaid mobile network. It presents an overview of supervised and unsupervised learning techniques including support vector machines, k-nearest neighbors, neural networks, decision trees and naive Bayes. The document outlines features for a churn prediction model, describes a demo of the model using different algorithms, and evaluates the classification accuracy and churn rates.
Telecom Subscription, Churn and ARPU Analysis
This document discusses various use cases and analyses for a telecom company, including subscription activation and termination, CRM and billing, revenue segmentation by service and customer, customer churn analysis and reasons for churn, customer profiling, calculating average revenue per user (ARPU) and the shift to average revenue per account (ARPA), segmentation of postpaid and prepaid customers, analyzing tariff plan changes, and how customer segmentation can benefit operators by maximizing revenue and retention.
More Related Content
Viewers also liked
How to Perform Churn Analysis for your Mobile Application?
For every marketer of mobile application, acquiring new customers certainly requires more effort in terms of time and money. On the other hand, firm can always focus on maintaining existing customer base and gain maximum out of them. If this is the case, then predictive analysis will be the correct approach for this situation.
The primary goal of this webinar is to predict segment of Mobile application users,
* Who will uninstall the app
* Remain inactive (which will be also termed as a churner) for quite long time and are expected to churn.
Churn analysis is the approach by which we will predict the likelihood of this event to occur.
Our webinar covers:
* How to extract data from Google Analytics using R
* How to build churn model in R
* Identifying the customer/subscriber segment that are classified based on past data pattern, who are likely to churn (Study customer behavior Patterns)
Watch Full Webinar - http://www.tatvic.com/webinar/churn-analysis-for-mobile-application/
Data Tactics Analytics Brown Bag (Aug 22, 2013)
This document provides an overview and agenda for a brown bag presentation on analytics services. The presentation includes introductions of the analytics team, discussions of why analytics are important both for business and practical reasons, and case studies of identifying smugglers and analyzing text data. The presentation emphasizes a philosophy of not being "data agnostic" and using modes of inquiry like induction and abduction rather than deduction.
W3CTech美团react专场-Thinking in React
拥抱未来但并不局限于标准的 React,有哪些叹为观止的设计以确保其易用性和高性能?为什么在双向绑定大行其道时 React 却使用单向数据流的设计?仅关注 UI 层的 React 其当前的生态圈还有哪些方面值得建设?
美团技术沙龙01 - 58到家服务的订单调度&数据分析技术
到家服务的订单,调度需要综合商家情况(是否有时间,当前位置)、订单情况(时间,地点)、用户情况(用户等级,历史消费记录)
为了满足业务需,在短短半年时间内从策略上,架构上做出了多个版本上的迭代。跟大家分享走过的路.未来迁移到云平台的思考.
美团点评技术沙龙09 - 外卖O2O的用户画像实践
美团外卖经过3年的飞速发展,达到了上亿用户,每天数百万订单的规模,留存了大量的用户数据。如何充分挖掘这些用户数据以更好地帮助外卖的发展是一个重大课题。同时外卖的高频O2O的特点也带来了一些新的问题需要解决。本报告将分享我们在助外卖吸引新的客户、留存已有用户以及用户订单数据挖掘的实践。
数据分析系统架构设计
数据分析平台及专题分析报告中新增的分析指标越来越多,体系建设越来越完善,但随着业务的发展、分析的深入,乐视数据分析指标体系建设仍将是未来一段时间的工作重点,对于分析指标特别的KPI指标的构建我们将围绕三个原则进行展开:
可量化:“可量化的才是可管理的”,这里是指我们要围绕我们的核心业务、用户、流程管理进行可量化的指标体系建设,我们把它划分为分为成本量化(时间成本、带宽成本、硬件成本、软件成本)、效益量化(流量效益、播放量效益、用户量效益)、效率量化(效益与成本比)、重点产品及功能可度量、关键业务流程可度量。
可评价:是指建立的指标能够对用户、产品或运维等优劣、好坏等进行综合评价
可优化:通过量化与评价体系确定产品状况与提升目标,建立优化目标并跟踪优化效果
数据部的工作目标是希望通过我们努力工作以及与相关部门的通力合作,力求达到以下几点目标:
分析并提升用户体验
分析并优化页面布局
分析与提升视频价值
分析并助力运维效果
为高层决策提供价值信息
美团技术沙龙03 - 实时数据仓库解决方案
美团网是为消费者提供本地生活服务的O2O公司。业务发展速度快,模式复杂,有大量的实时数据运营和分析需求。为了提高运营的效率,我们基于开源的Storm,提供了美团实时数据仓库解决方案。本次分享,将会介绍美团基于实时计算平台的"RtDW直播间"产品,以及在构建实时数据仓库过程中的经验总结。
美团点评技术沙龙09 - 一个用户行为分析产品的设计与实现
神策分析是一个可以私有化部署的用户行为分析产品,支持每个实例每天十亿级别用户行为数据的秒级导入与秒级查询延迟。本次分享会以产品的功能设计与性能指标为出发点,详细介绍整个系统的技术选型、整体架构、数据模型、技术实现,以及我们团队一年多的开发演进过程中所遇到的问题。
暴走漫画数据挖掘从0到1
暴走漫画是国内在年轻人中颇具影响力的文化公司,产品包括社区,日报,游戏,视频。然而,随着暴漫用户的增长,运营的工作越来越重,也越来越需要照顾不同的用户。这时候数据服务团队应运而生。来到暴漫后,主要主导了 3 个方面的数据服务:搜索,推荐。这次主要和大家分享一点实践方面的经验,包括技术架构的选择,算法策略的选择等。
Churn Modeling For Mobile Telecommunications
This document summarizes Salford Systems' participation in an international competition to predict customer churn for a major mobile provider. Salford Systems used an ensemble of decision tree models called TreeNet to predict churn with significantly higher accuracy than other methods. TreeNet models achieved a top decile lift of 3.01 and Gini coefficient of 0.400 on future churn predictions, substantially better than the average and second place method. The document outlines the data and task, TreeNet methodology, results, and conclusions that TreeNet was key to winning due to its superior predictive performance.
Presentation Churn Management
This document discusses churn management in mobile communications. It defines churn as customer attrition or loss and churn rate as the number of customers who discontinue service divided by the total number of customers. It identifies reasons for churn such as easy switching between providers and inadequate services. It discusses types of churn, data transformation for modeling, identifying customers' propensity to churn, and calculating customer profitability. Finally, it outlines strategies for reducing churn such as identifying valuable customers and developing win-back policies.
RHadoop, R meets Hadoop
(Presented by Antonio Piccolboni to Strata 2012 Conference, Feb 29 2012).
Rhadoop is an open source project spearheaded by Revolution Analytics to grant data scientists access to Hadoop’s scalability from their favorite language, R. RHadoop is comprised of three packages.
- rhdfs provides file level manipulation for HDFS, the Hadoop file system
- rhbase provides access to HBASE, the hadoop database
- rmr allows to write mapreduce programs in R
rmr allows R developers to program in the mapreduce framework, and to all developers provides an alternative way to implement mapreduce programs that strikes a delicate compromise betwen power and usability. It allows to write general mapreduce programs, offering the full power and ecosystem of an existing, established programming language. It doesn’t force you to replace the R interpreter with a special run-time—it is just a library. You can write logistic regression in half a page and even understand it. It feels and behaves almost like the usual R iteration and aggregation primitives. It is comprised of a handful of functions with a modest number of arguments and sensible defaults that combine in many useful ways. But there is no way to prove that an API works: one can only show examples of what it allows to do and we will do that covering a few from machine learning and statistics. Finally, we will discuss how to get involved.
churn prediction in telecom
The document discusses machine learning algorithms for predicting customer churn in a prepaid mobile network. It presents an overview of supervised and unsupervised learning techniques including support vector machines, k-nearest neighbors, neural networks, decision trees and naive Bayes. The document outlines features for a churn prediction model, describes a demo of the model using different algorithms, and evaluates the classification accuracy and churn rates.
Telecom Subscription, Churn and ARPU Analysis
This document discusses various use cases and analyses for a telecom company, including subscription activation and termination, CRM and billing, revenue segmentation by service and customer, customer churn analysis and reasons for churn, customer profiling, calculating average revenue per user (ARPU) and the shift to average revenue per account (ARPA), segmentation of postpaid and prepaid customers, analyzing tariff plan changes, and how customer segmentation can benefit operators by maximizing revenue and retention.
Viewers also liked (20)
How to Perform Churn Analysis for your Mobile Application?
How to Perform Churn Analysis for your Mobile Application?
More from 学峰 司
春节分析报告
作为主编的我会考虑在春节假期不同时间段首页焦点图推不同的内容,特别是春晚专题,大年30央视春晚开始前我首页焦点图会推央视春晚内容时间安排预告和辽宁卫视春晚赵本山精彩片段;初一到初三我会推央视精彩片段,并且会上3个首页焦点图,春晚专题焦点图内容我会不断推新内容新标题,同时赵本山没上春晚我会推其以往的节目;初四到初六继续推春晚精彩视频,但焦点图个数减少为1个,同时关于央视春晚网络热议会推相关娱乐八卦,焦点图位置有讲究,在1-3位置上。
电影我会在春节期间每天一部经典电影和当下热映电影相结合的方式推广,且首页焦点图位置很有考究,放在4-5的位置,经典电影上焦点图后效果好的话我会推的时间长,否则换其他电影。
电视剧我会推热播剧,比如《宫2》,焦点图更新时间点在电视台播放完成后第一时间上焦点图,焦点图为最新一集,直接连到播放页;另外因为春节假期学生放假,我会抓住这点推《新还珠2》,为什么呢,一个是年轻的人喜好,另外从百度搜索风云榜中也印证了广大网民的对此剧关注的热度。
作为主编的我对焦点图的管理是规范和严格的,上不上焦点图是有依据的。比如焦点图名称出现错别字时对值班人员有严格的预防机制和问责机制,且一旦发现错误会在很短时间内进行纠正。焦点图名称上也是很有讲究的,文字长度规范,且能够吸引眼球。
微软BI开发工程师认证
Xuefeng Si earned two Microsoft certifications in 2010 - a Microsoft Certified IT Professional in Business Intelligence Developer on June 5, 2010 and a Microsoft Certified Technology Specialist in Microsoft SQL Server 2005, Business Intelligence Development on May 29, 2010. He successfully completed the exams required for these certifications, exam 446 on June 5, 2010 and exam 445 on May 29, 2010.