Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Makoto Kishimoto
936 views
some SHA1 implementation
some SHA1 implementation
Engineering
◦
Read more
3
Save
Share
Embed
Embed presentation
Download
Download to read offline
1
/ 18
2
/ 18
3
/ 18
4
/ 18
5
/ 18
6
/ 18
7
/ 18
8
/ 18
9
/ 18
10
/ 18
11
/ 18
12
/ 18
13
/ 18
14
/ 18
15
/ 18
16
/ 18
17
/ 18
18
/ 18
More Related Content
PPTX
Opnfv handson apex intro
by
Tomofumi Hayashi
PDF
AspectMock 最強のモッキングフレームワーク
by
kenjis
PDF
phpspecで始めるBDD
by
Yuuki Takezawa
PDF
FPGAで作るOpenFlow Switch (FPGAエクストリーム・コンピューティング 第6回) FPGAX#6
by
Kentaro Ebisawa
PDF
Pynqでカメラ画像をリアルタイムfastx コーナー検出
by
marsee101
PDF
OPNFVのコンポーネントと調べ方
by
Mibu Ryota
PPTX
20161120_HPCでFPGAを使ってみたい_fpgastartup
by
HPCシステムズ株式会社
PDF
OPNFV Handson Tokyo #1
by
Mibu Ryota
Opnfv handson apex intro
by
Tomofumi Hayashi
AspectMock 最強のモッキングフレームワーク
by
kenjis
phpspecで始めるBDD
by
Yuuki Takezawa
FPGAで作るOpenFlow Switch (FPGAエクストリーム・コンピューティング 第6回) FPGAX#6
by
Kentaro Ebisawa
Pynqでカメラ画像をリアルタイムfastx コーナー検出
by
marsee101
OPNFVのコンポーネントと調べ方
by
Mibu Ryota
20161120_HPCでFPGAを使ってみたい_fpgastartup
by
HPCシステムズ株式会社
OPNFV Handson Tokyo #1
by
Mibu Ryota
More from Makoto Kishimoto
PDF
CHP survey
by
Makoto Kishimoto
PDF
Visulan intro
by
Makoto Kishimoto
PDF
20151121
by
Makoto Kishimoto
PDF
Shizuoka go lang csp
by
Makoto Kishimoto
ODP
FZ and DAZ in denormals
by
Makoto Kishimoto
PDF
Tech oyaji ksmakoto_presen
by
Makoto Kishimoto
PDF
Subprocess no susume
by
Makoto Kishimoto
ODP
Node handson
by
Makoto Kishimoto
ODP
app-c.odp
by
Makoto Kishimoto
CHP survey
by
Makoto Kishimoto
Visulan intro
by
Makoto Kishimoto
20151121
by
Makoto Kishimoto
Shizuoka go lang csp
by
Makoto Kishimoto
FZ and DAZ in denormals
by
Makoto Kishimoto
Tech oyaji ksmakoto_presen
by
Makoto Kishimoto
Subprocess no susume
by
Makoto Kishimoto
Node handson
by
Makoto Kishimoto
app-c.odp
by
Makoto Kishimoto
some SHA1 implementation
1.
いくつかのSHA1実装の比較 岸本 誠
2.
CAUTION ● SHA1 ● 暗号学的ハッシュ関数たるべく設計された ● ハッシュアルゴリズム ● SHA1は既に非推奨です ● disclaimerは以下略
3.
最初のきっかけ
4.
というわけで元の話は ● ハードウェアをパイプライン化してスループッ トを改善した話 ● Verilog HDL でゲートレベルぐらいで記述して FPGAにマッピングして追試を考えた ● (まだやっていない)
5.
性能を上げてうれしいのか? ● スループット ● ファイルをディスクから読み出してるとかであれ ば、間違いなくボトルネックはそっち ● とはいえ、高速な通信だとかで、それがボトルネッ クなら改善する意味がある、というかしなければ ● レイテンシ ● ストリームが終わった瞬間の何秒後に答えが出るか ● 一応性能を上げれば上げただけ改善するけど ● 特にうれしいことはあるだろうか?
6.
ソフトウェア実装 ● ハードウェア実装の論理を理解確認するため ● RTレベル実装の結果の照合のため ● 検索していたらIntelのサイトの、 Improving the Performance
of the Secure Hash Algorithm (SHA-1) という解説に遭遇 ● https://software.intel.com/en- us/articles/improving-the-performance-of- the-secure-hash-algorithm-1
7.
Intelの記事
8.
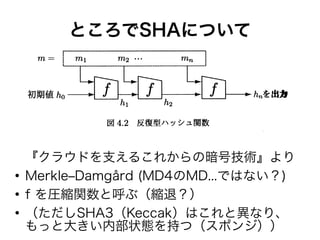
ところでSHAについて 『クラウドを支えるこれからの暗号技術』より ● Merkle–Damgård (MD4のMD...ではない?) ● f を圧縮関数と呼ぶ(縮退?) ● (ただしSHA3(Keccak)はこれと異なり、 もっと大きい内部状態を持つ(スポンジ))
9.
圧縮関数の詳細 ● (ウィキペディアを参照)
10.
実装方法を考える ● ループを全く展開せずコード量最小を狙う ● ループを全部展開する ● 前者はとりあえず不利そう ● ハードウェアでは、常に共通の動作で動き続け るモジュールと、タイミングを合わせてレジス タを書き換えるモジュール、というように最適 化できる(かも)
11.
以下の3種類を比較 ● ほどほどに展開した C コード ● 完全に展開した
C コード(スクリプト生成) ● Intelサイトにあった、SSEで最適化したコード ● ハードウェアと環境 ● 自宅のデスクサイドPC(FreeBSD) – AMD Phenom Ⅱ X4 905e ● SSSE3非対応 ● このMacBook(OS X) ● どちらも LLVM clang と NASM を使用
12.
コード解説 ● (コードを参照)
13.
測定方法 ● RDTSC で関数に入ってから出るまでを測定 ● /dev/urandom を
STDIN からブロックサイズ 毎で read ● 20万回のうち、後半10万回ぶん(headとtail で抽出) ● 不自然に大きいカウントは次のチャートからは 排除
14.
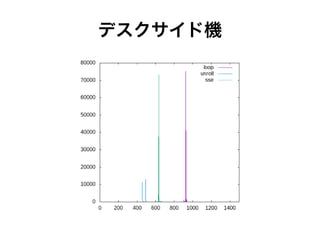
デスクサイド機
15.
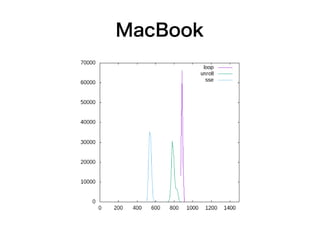
MacBook
16.
測定結果について ● ともあれ Intel の中の人が書いた
SSE 最適化 コードはやっぱり速い ● とはいえ2倍前後の違い ● キャッシュが暖まる? 前と後で微妙に傾向が 違うような感じもあった (ループのほうが速い)
17.
残りのテーマ ● 元のテーマであるハードウェア ● SHA2 512 にまで拡張できるか? ● Intel
の SSE のコードは実はギリギリ ● AVX? ● SHA3 はどうか? ● 内部状態は1600ビット ● あれ、あまりたいしたことない?
18.
(空白ページ) ● SlideShare対策の空白ページ
Download