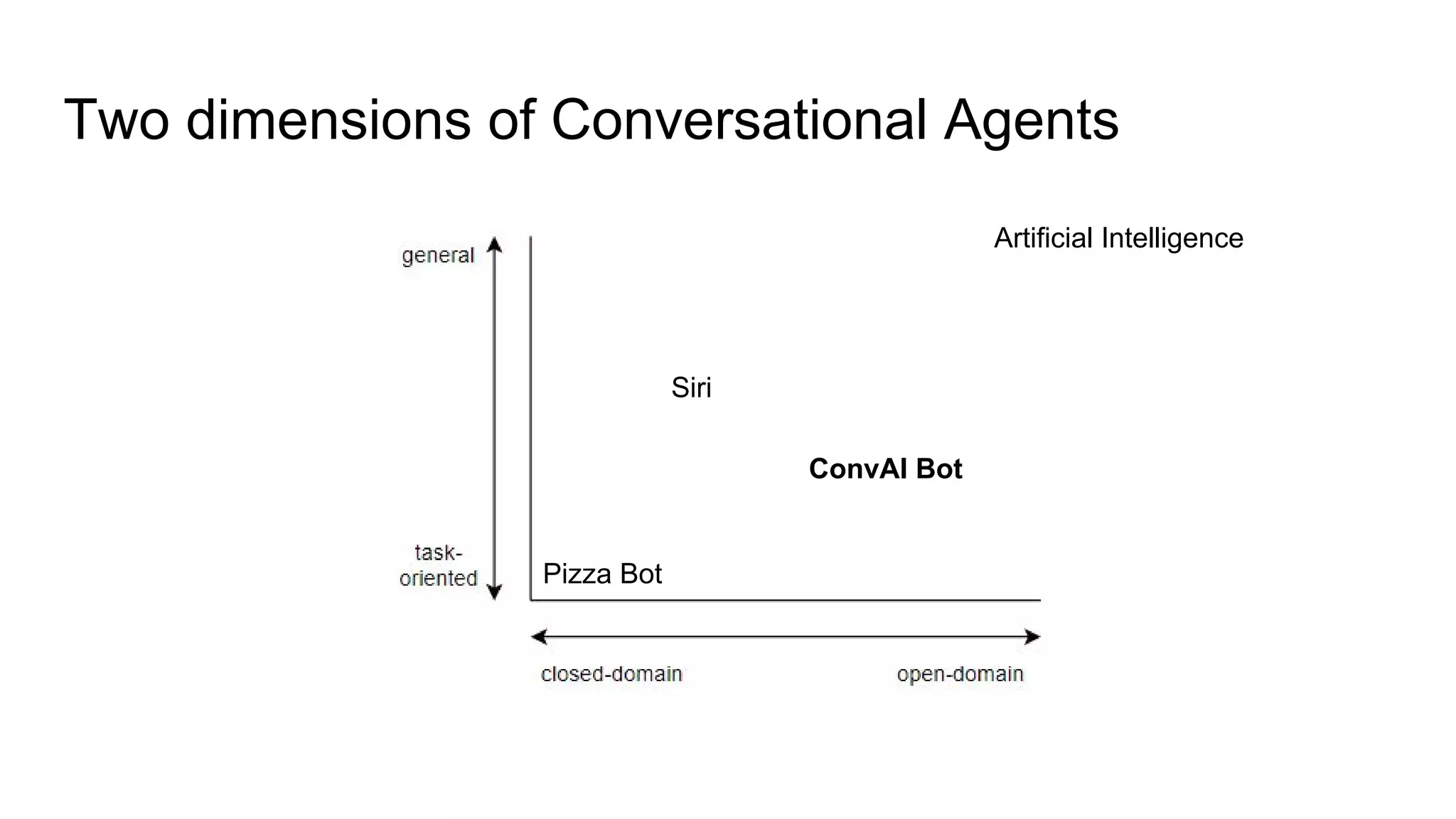
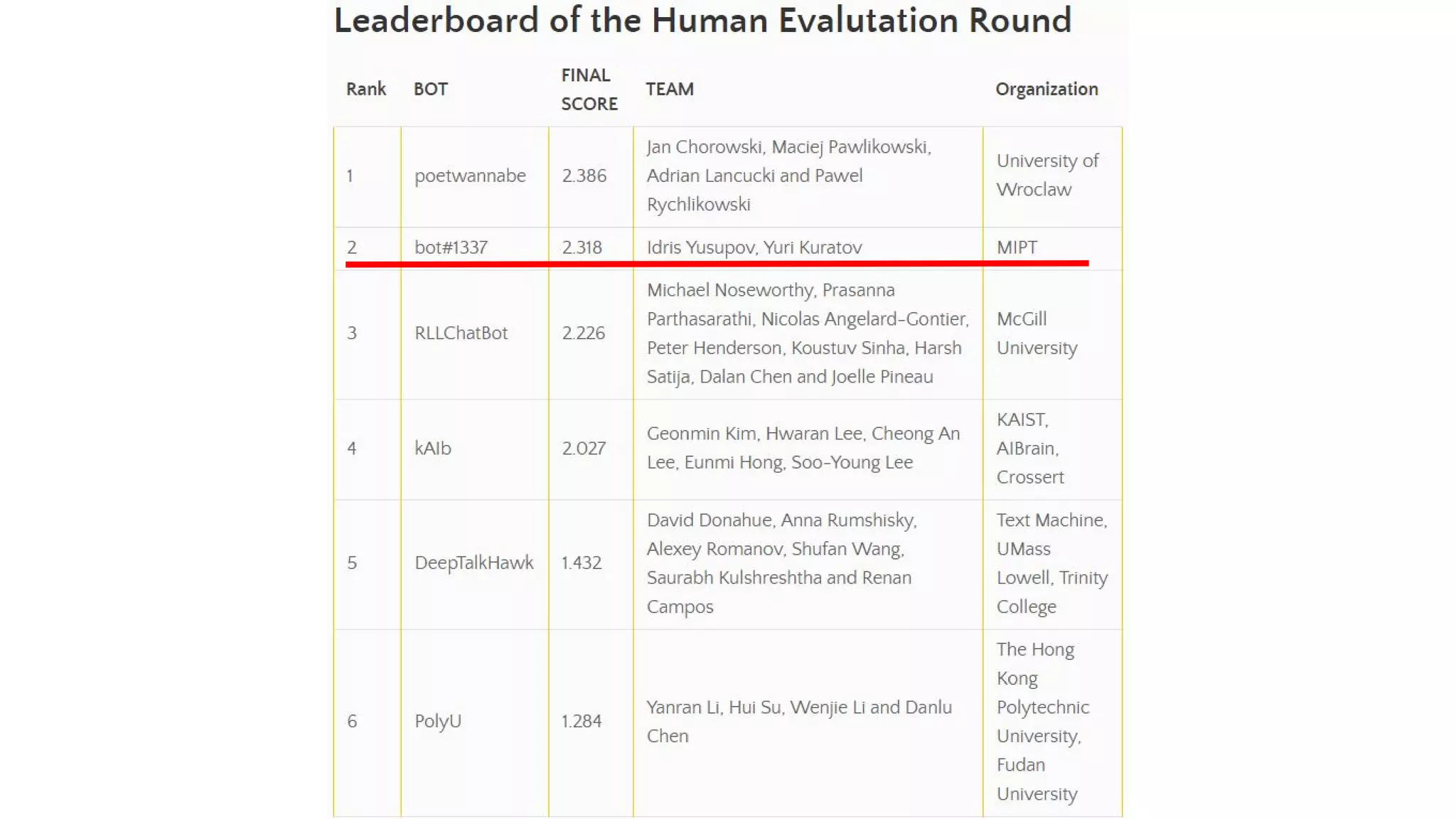
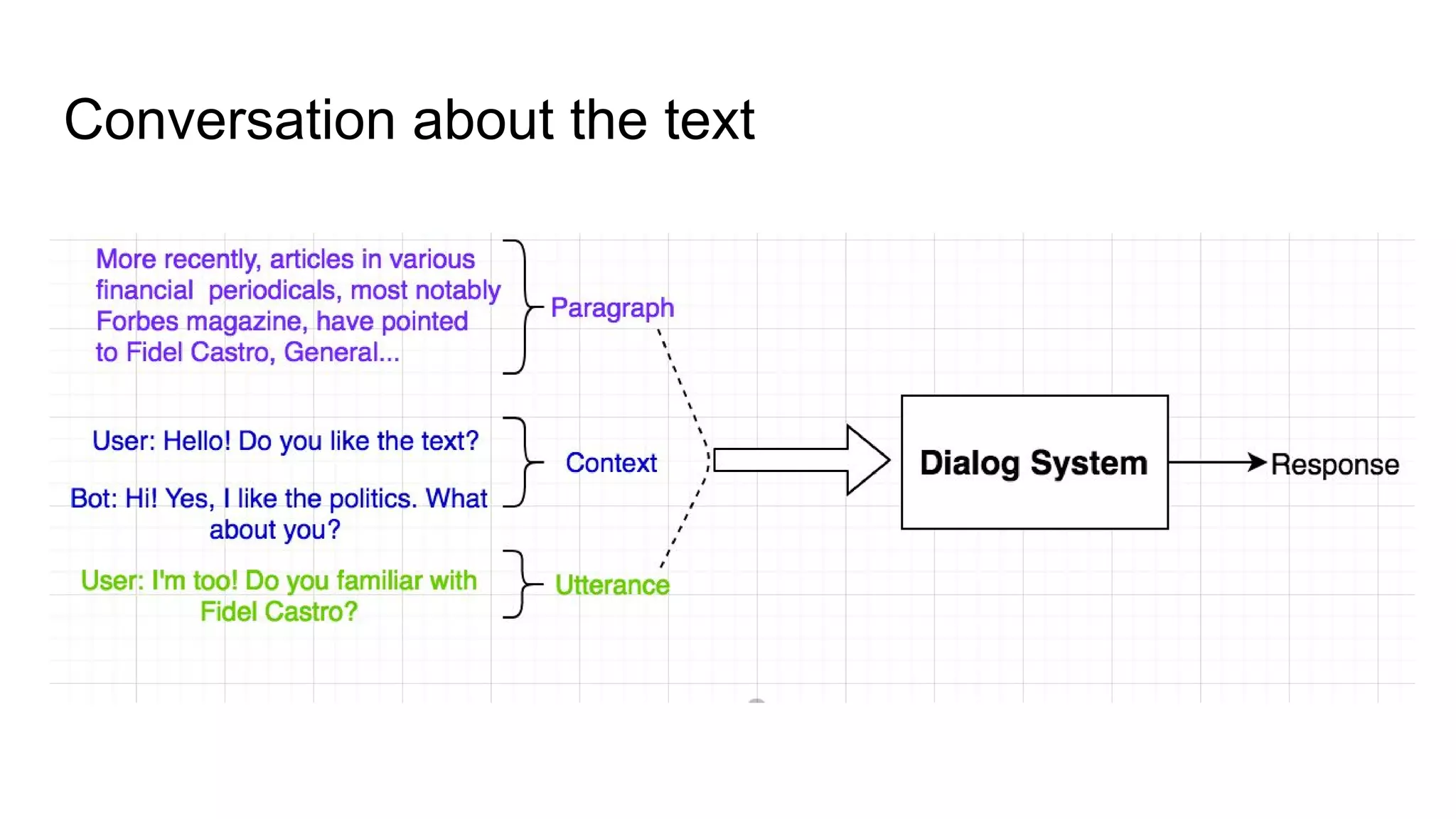
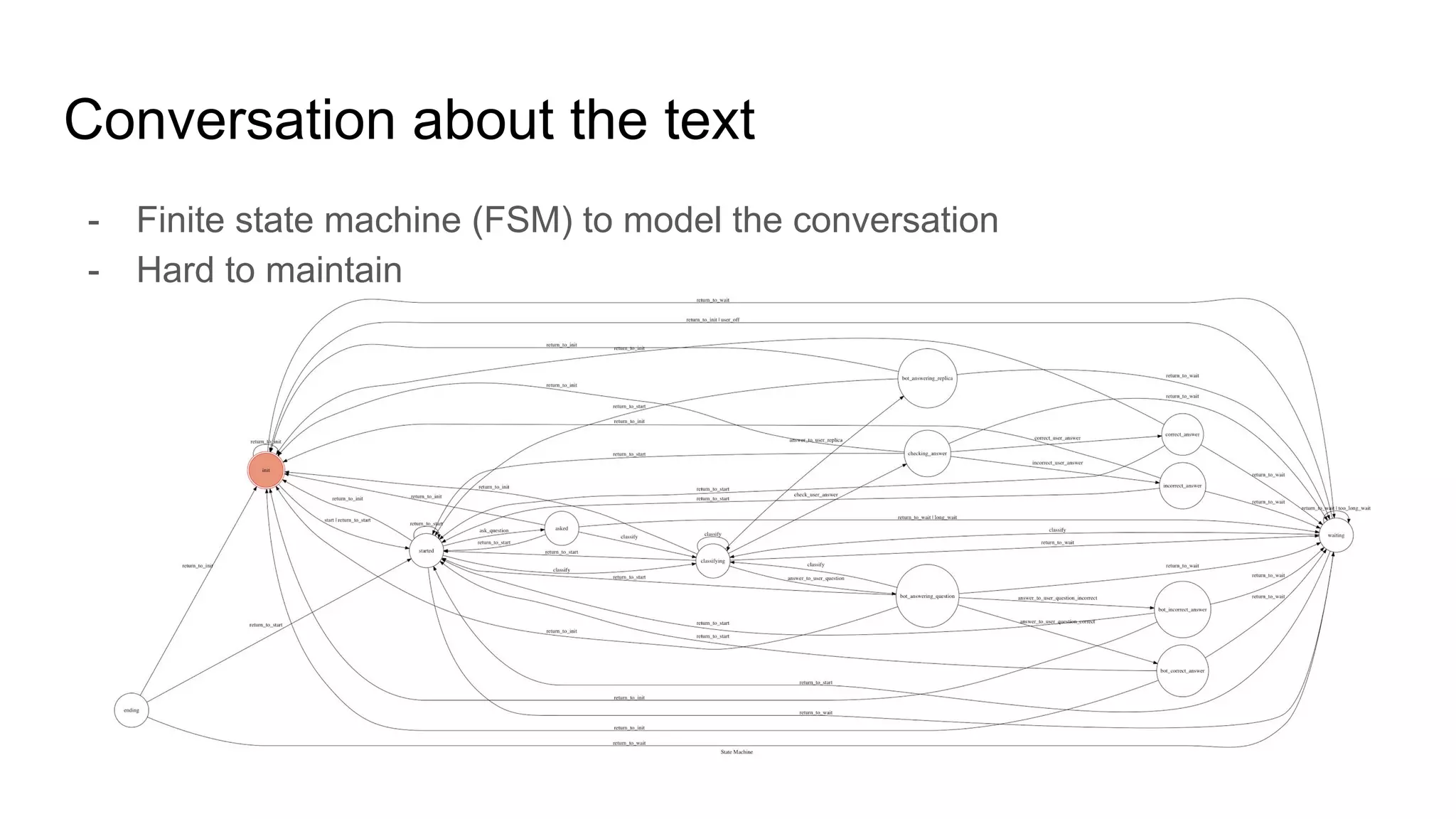
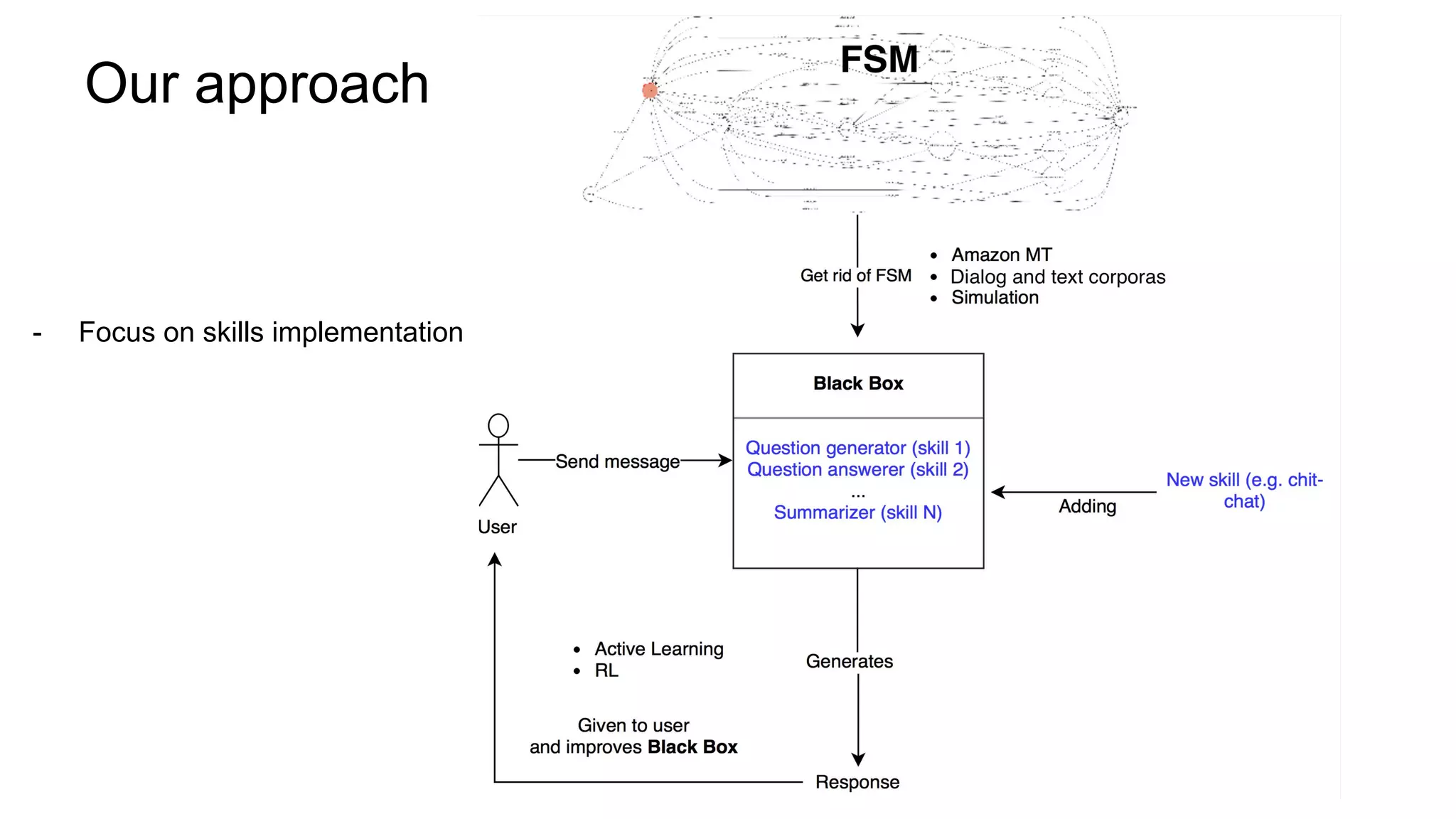
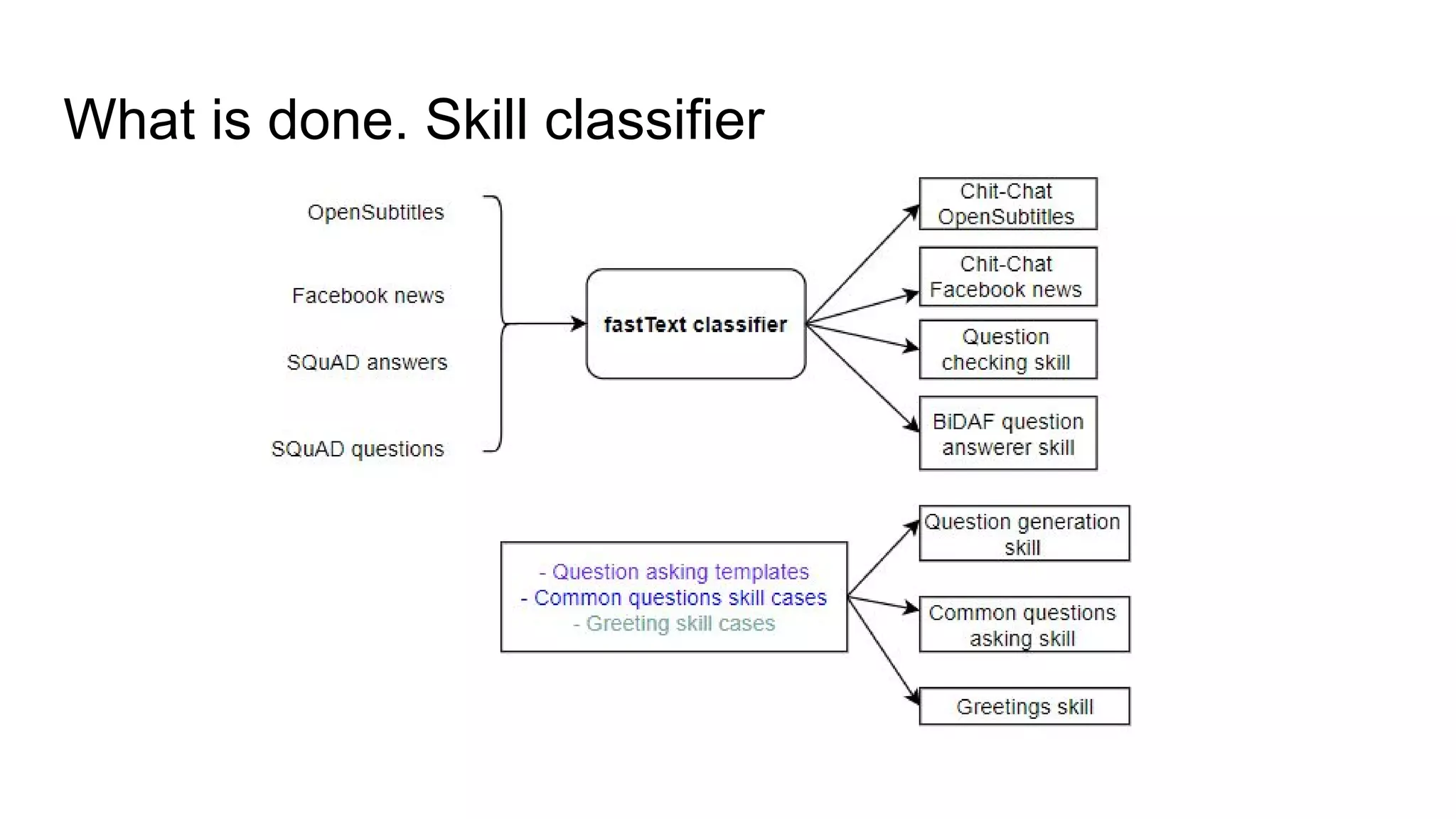
The document discusses the development of skill-based conversational agents, including various skills necessary for text-based interactions such as question generation, chit-chat, and summarization. It outlines a competition (ConvAI) evaluating conversational agents and presents their progress in classifier development and future research directions. The authors emphasize a focus on skill implementation rather than traditional finite state machines for managing these conversational skills.








![What is done. Dialog evaluation scorer
- 2 evaluation scorers were built by using ConvAI human evaluation dataset
- Current utterance quality scorer: [context, utterance] => (poor, good)
- Word level GRU, sequence length is 50
- Overall dialog quality scorer: [overall dialog] => (poor, neutral, good)
- Word level GRU, sequence length is a whole dialog](https://image.slidesharecdn.com/skill-basedconversationalagent-2-171019091327/75/Skill-based-Conversational-Agent-15-2048.jpg)


















































