Downloaded 29 times















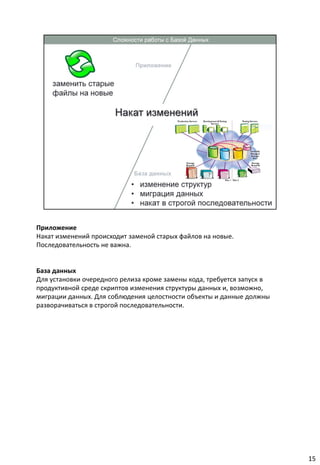















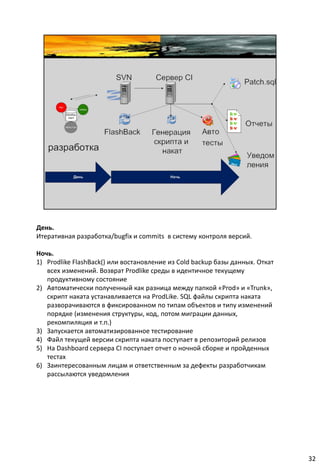
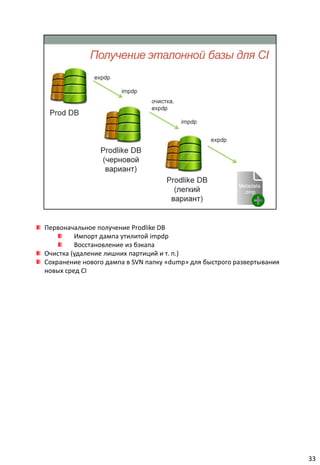

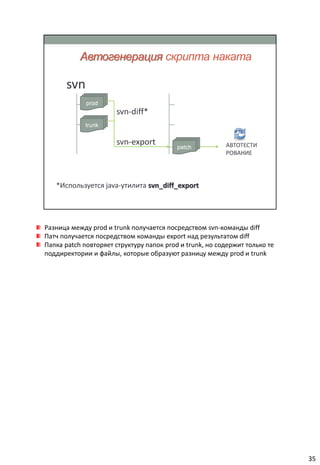
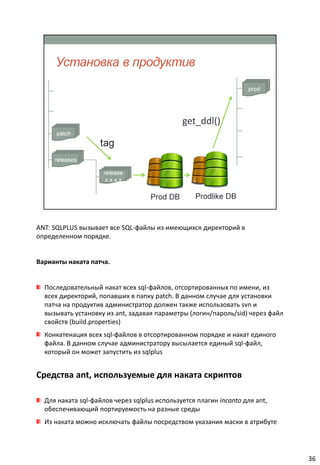






















Документ описывает концепцию непрерывной интеграции (CI) в разработке программного обеспечения, акцентируя внимание на важности автоматизации тестирования и развертывания. Он также анализирует сложности, с которыми сталкиваются команды без использования CI, и подчеркивает необходимость использования системы контроля версий для управления изменениями. В заключение, документ советует оптимизировать процессы CI и интегрировать их с тестированием для повышения эффективности работы команд разработки.















































