




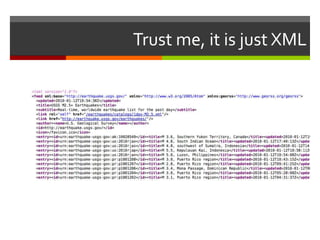


![def fetch_quakes():def fetch_quakes():api = bitly.Api(login=’ABCDEF', apikey=’12345678901234567890')rss = parse(urllib.urlopen(USGS_URL)).getroot() quakes = [] for element in rss.findall('{%s}entry' % USGS_NS): title = element.findtext('{%s}title' % USGS_NS) if (title.find("San Francisco Bay") > -1): point = element.findtext('{%s}point' % GEORSS_NS) points = point.split(None, 1) link = element.find('{%s}link' % USGS_NS)href = 'http://earthquakes.usgs.gov%s' % link.get('href')href = api.shorten(href) if (is_duplicate(href) is False):f = open(‘urls.txt', 'a')f.write('%s\n' % href)f.close() summary = element.findtext('{%s}summary' % USGS_NS) summary = summary.split("<br>")[1] summary = summary.replace(' at epicenter</p><p>', ' ') summary = strip_tags(summary)quakes.append({'title': element.findtext('{%s}title' % USGS_NS), 'link' : href, 'updated' : element.findtext('{%s}updated' % USGS_NS), 'long' : points[1], 'lat' : points[0], 'elev' : element.findtext('{%s}elev' % GEORSS_NS), 'summary' : summary}) return quakes](https://image.slidesharecdn.com/sfusgs-100117203232-phpapp01/85/SFUSGS-19-320.jpg)
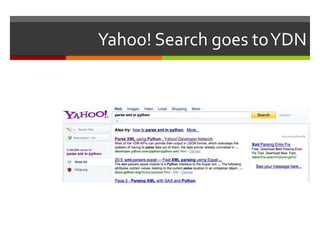
![def is_duplicate(url):def is_duplicate(url): from subprocess import callif(os.path.exists(‘urls.txt') is False): call(['/usr/bin/touch', ‘urls.txt'])r = call(['/bin/fgrep',url, ‘urls.txt']) if (r == 0): return True else: return False](https://image.slidesharecdn.com/sfusgs-100117203232-phpapp01/85/SFUSGS-20-320.jpg)
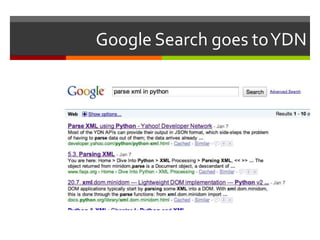
![def send_tweet(t):def send_tweet(t): import httplib2 username = ’ABCDEFG' password = ’12345678901234567890'msg = ('%s %s %s' % (t['title'], t['link'], t['summary'])) http = httplib2.Http()http.add_credentials(username, password) response = http.request( "http://twitter.com/statuses/update.xml", "POST",urllib.urlencode({"status": msg, "lat": t['lat'], "long": t['long']}) )SEE: http://code.google.com/p/httplib2/ps: you shouldn’t store your passwords like that…this is just an illustration](https://image.slidesharecdn.com/sfusgs-100117203232-phpapp01/85/SFUSGS-21-320.jpg)


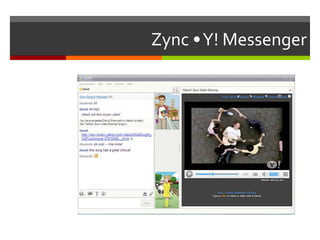
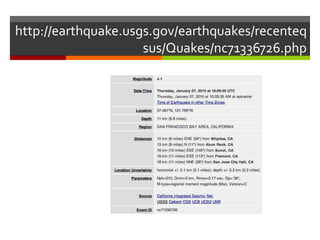
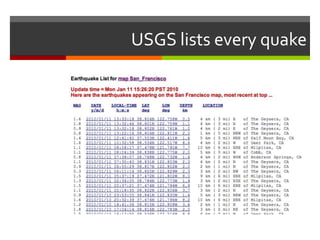
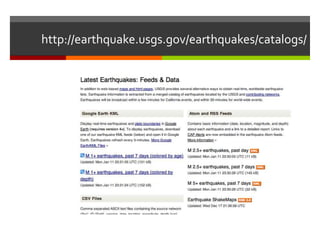
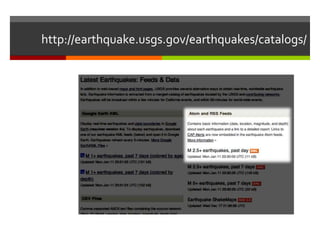
The document describes a program that automatically monitors USGS earthquake feeds, identifies local quakes near San Francisco, generates short URLs for the quake details, tweets summary information, and records tweeted quakes to avoid duplicates. It fetches XML earthquake data from USGS, parses it to find local quakes, generates and checks for duplicate bitly links, records link and tweets title, link and summary if not a duplicate quake.















































