Download as ODP, PPTX



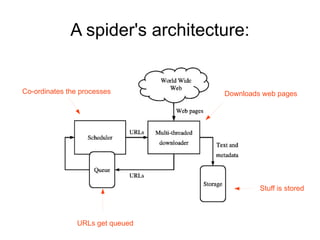













The document discusses search engine spiders, which are automated programs that crawl the web, index pages, and store them for search engines. It outlines the architecture and functioning of spiders, including their policies for crawling, the importance of respecting 'robots.txt', and the issues that arise from poorly designed spiders. Additionally, it introduces Web 3.0 and the concept of 'scutters' for machine-readable information exchange.



































































