Downloaded 100 times
















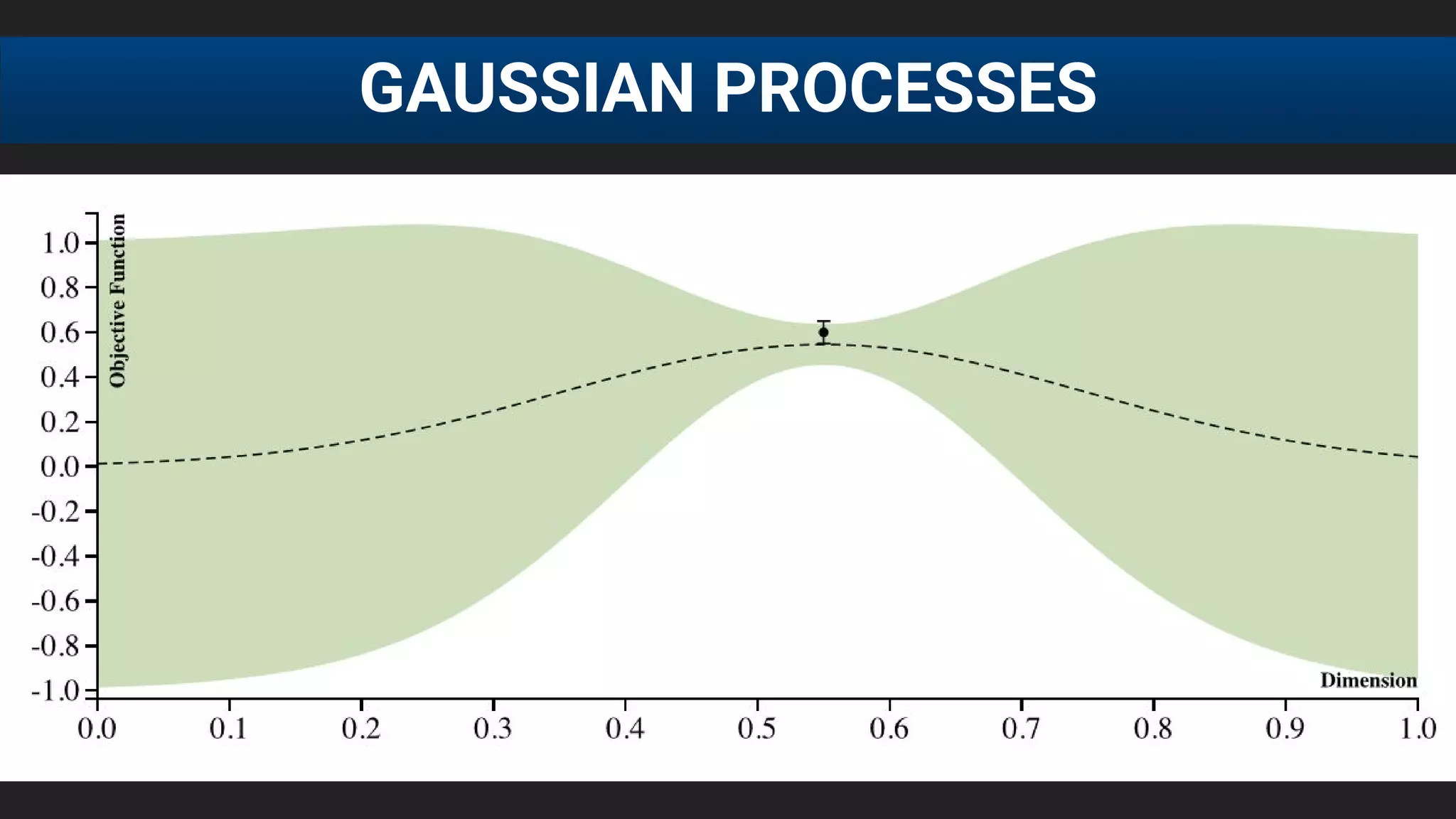
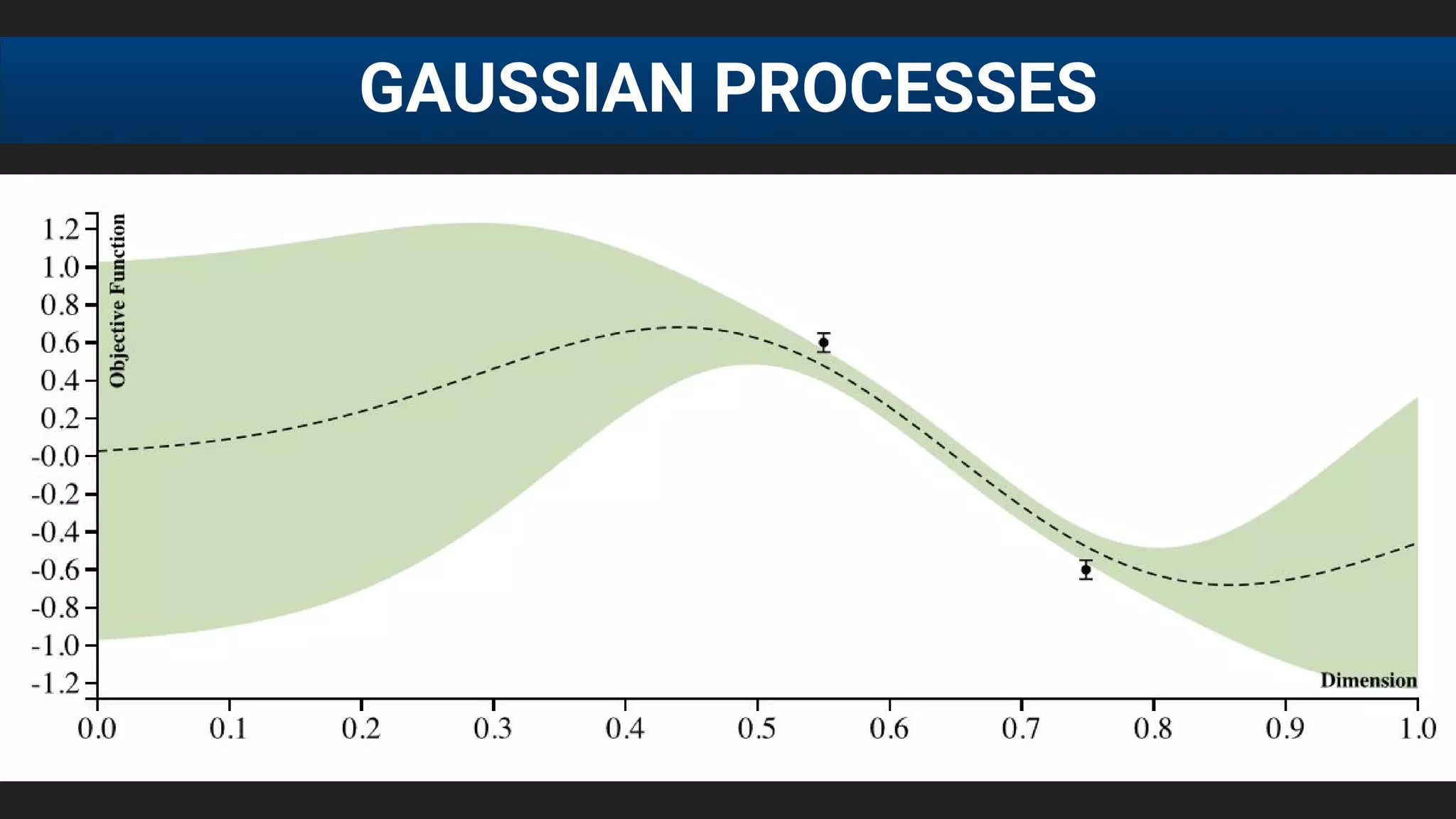
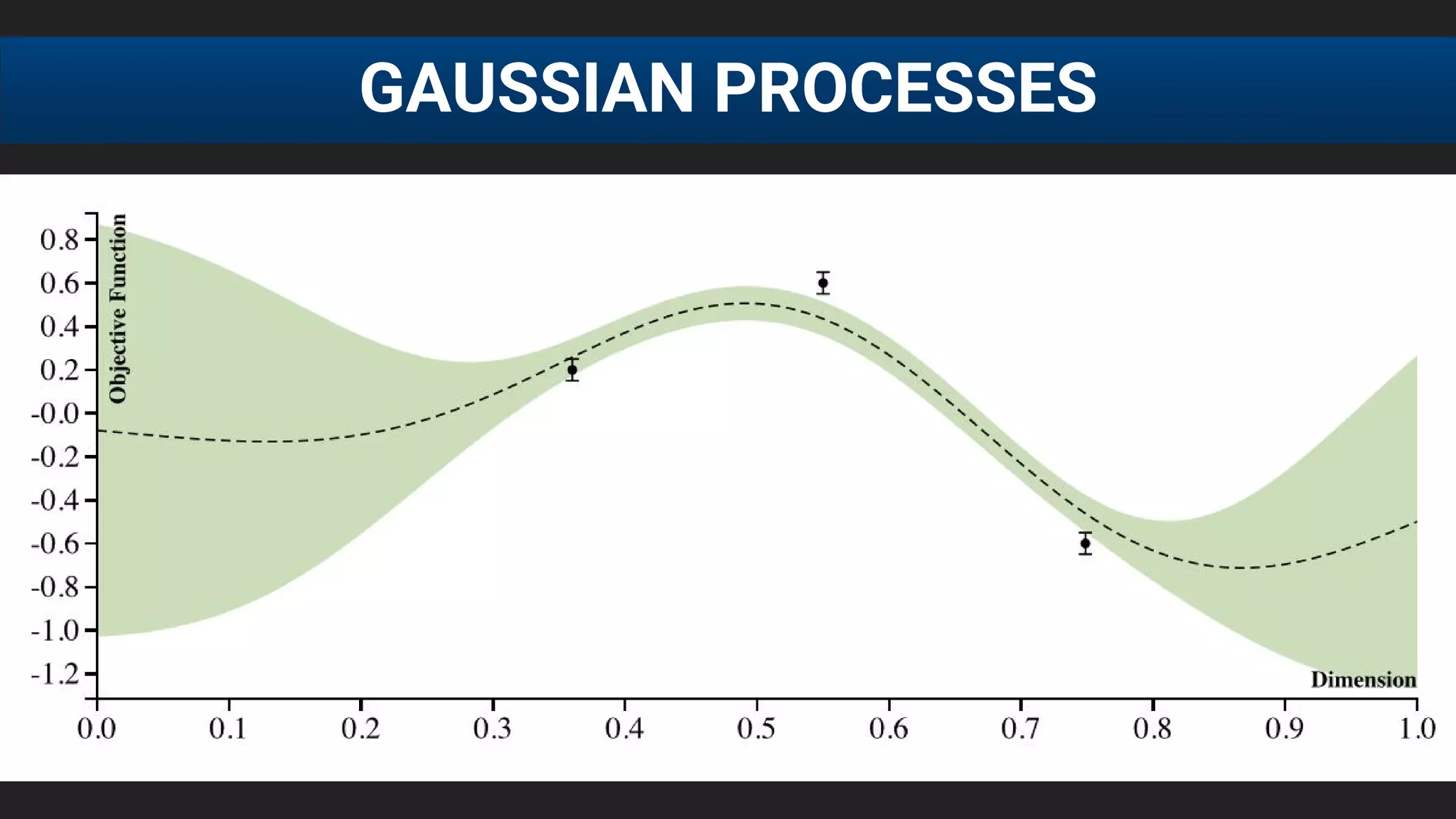
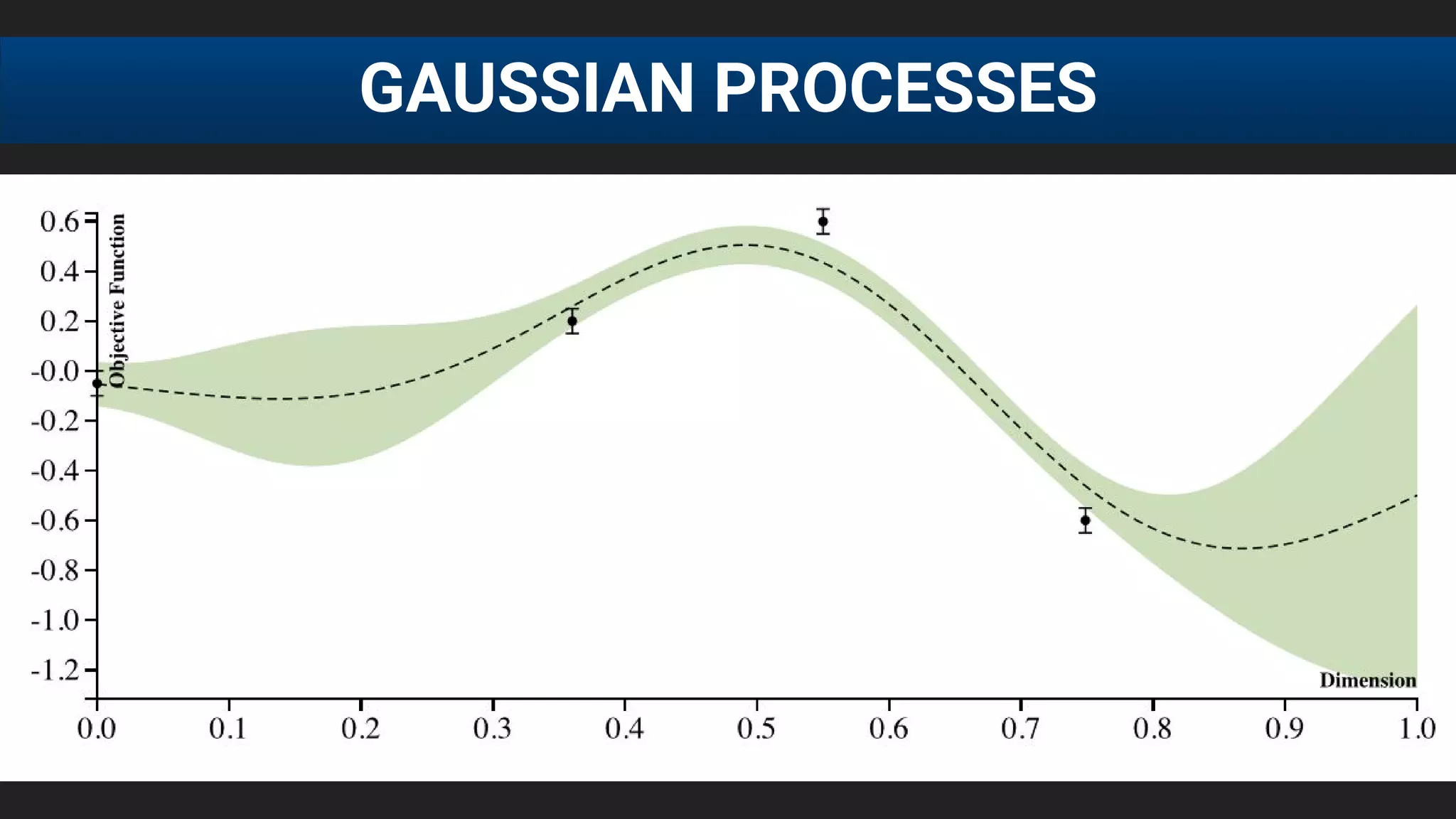
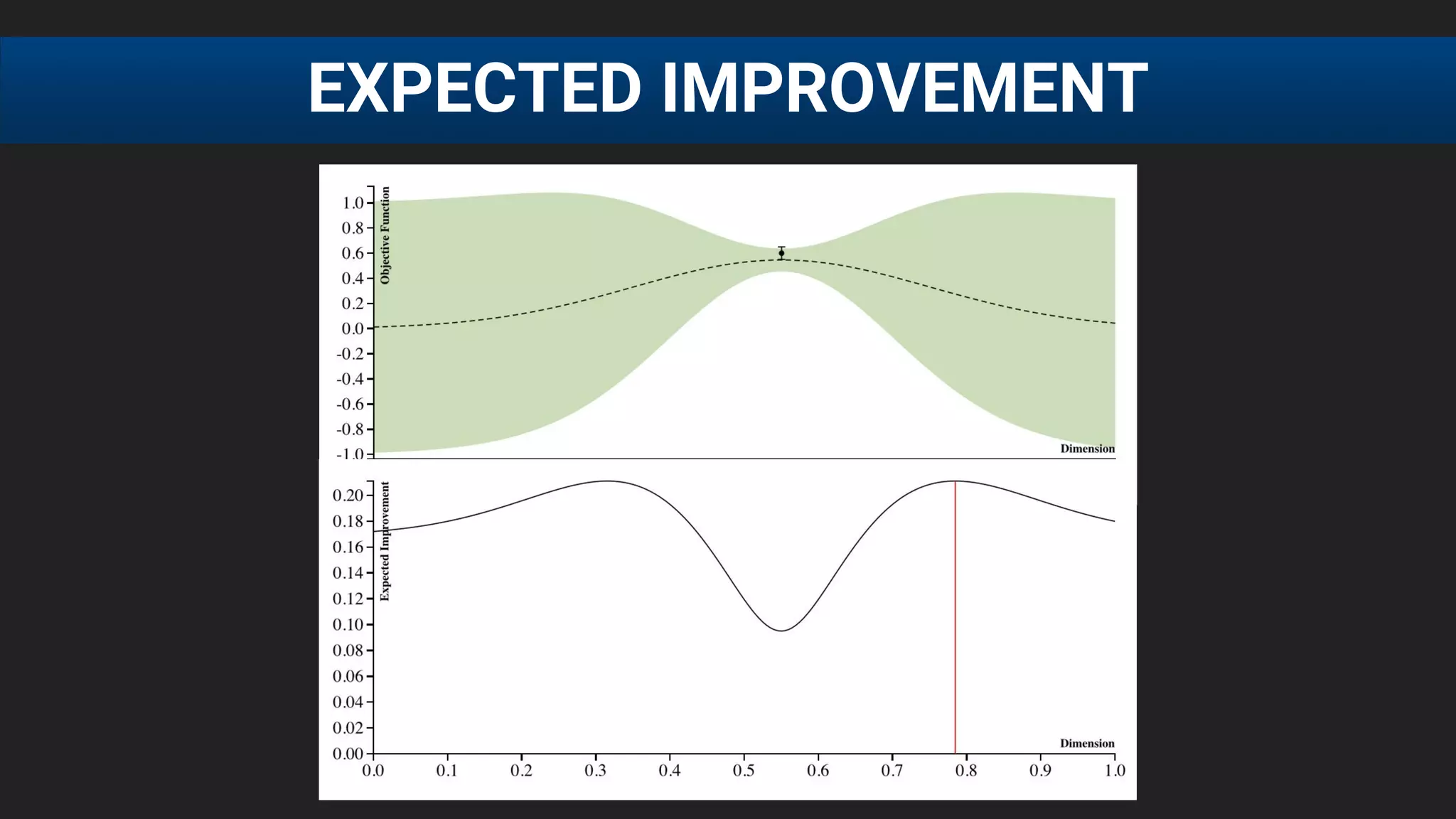
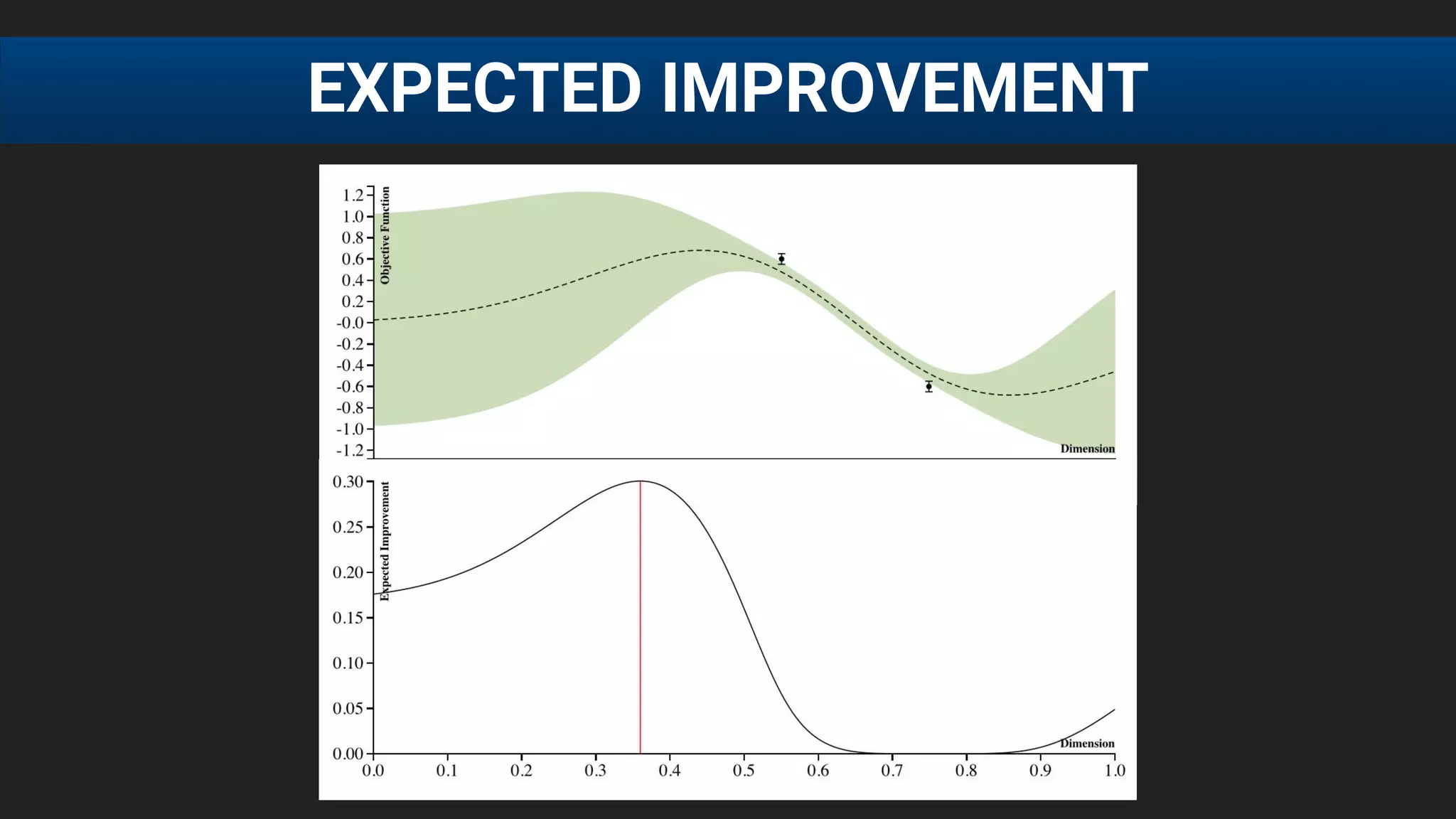
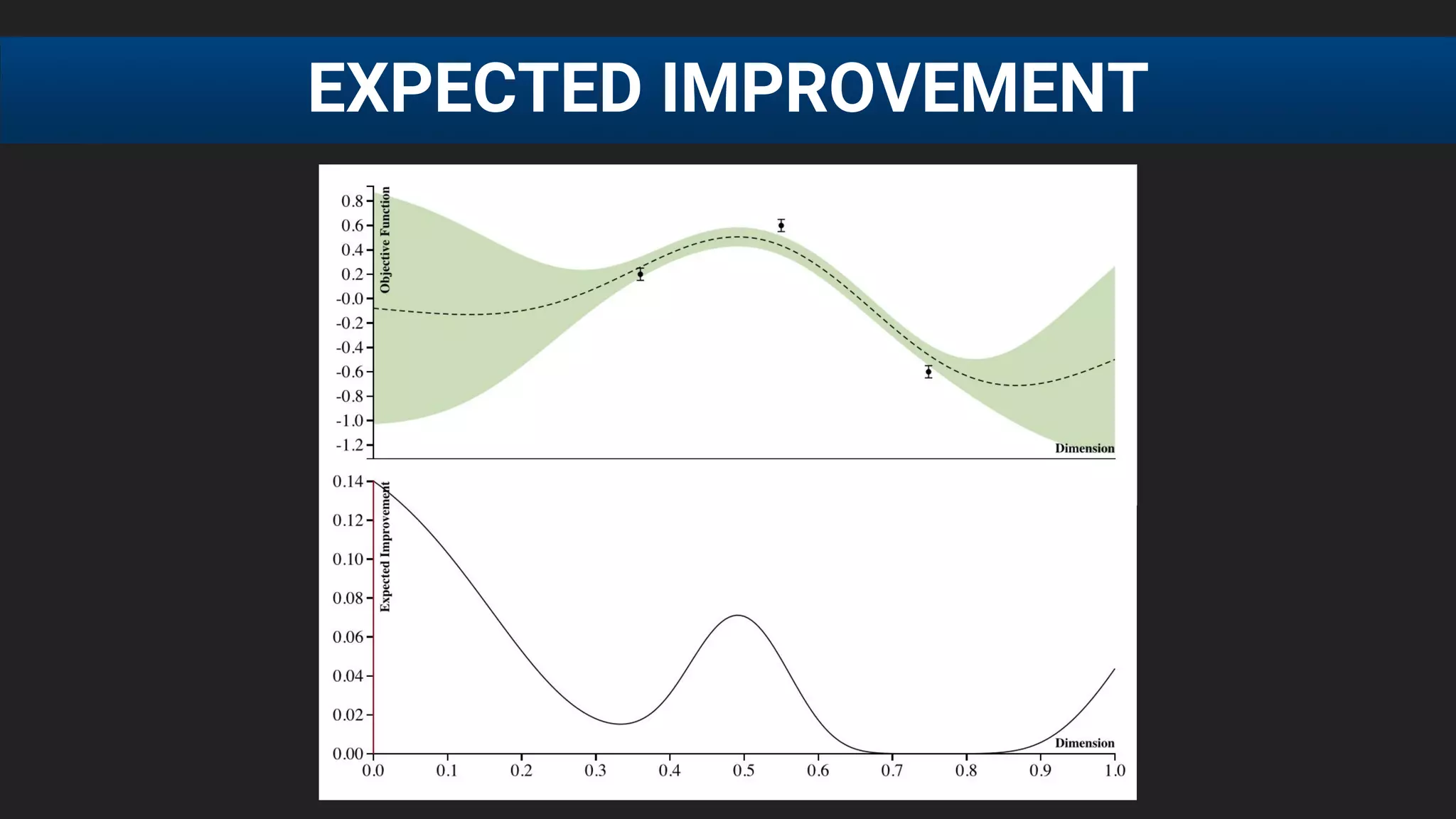
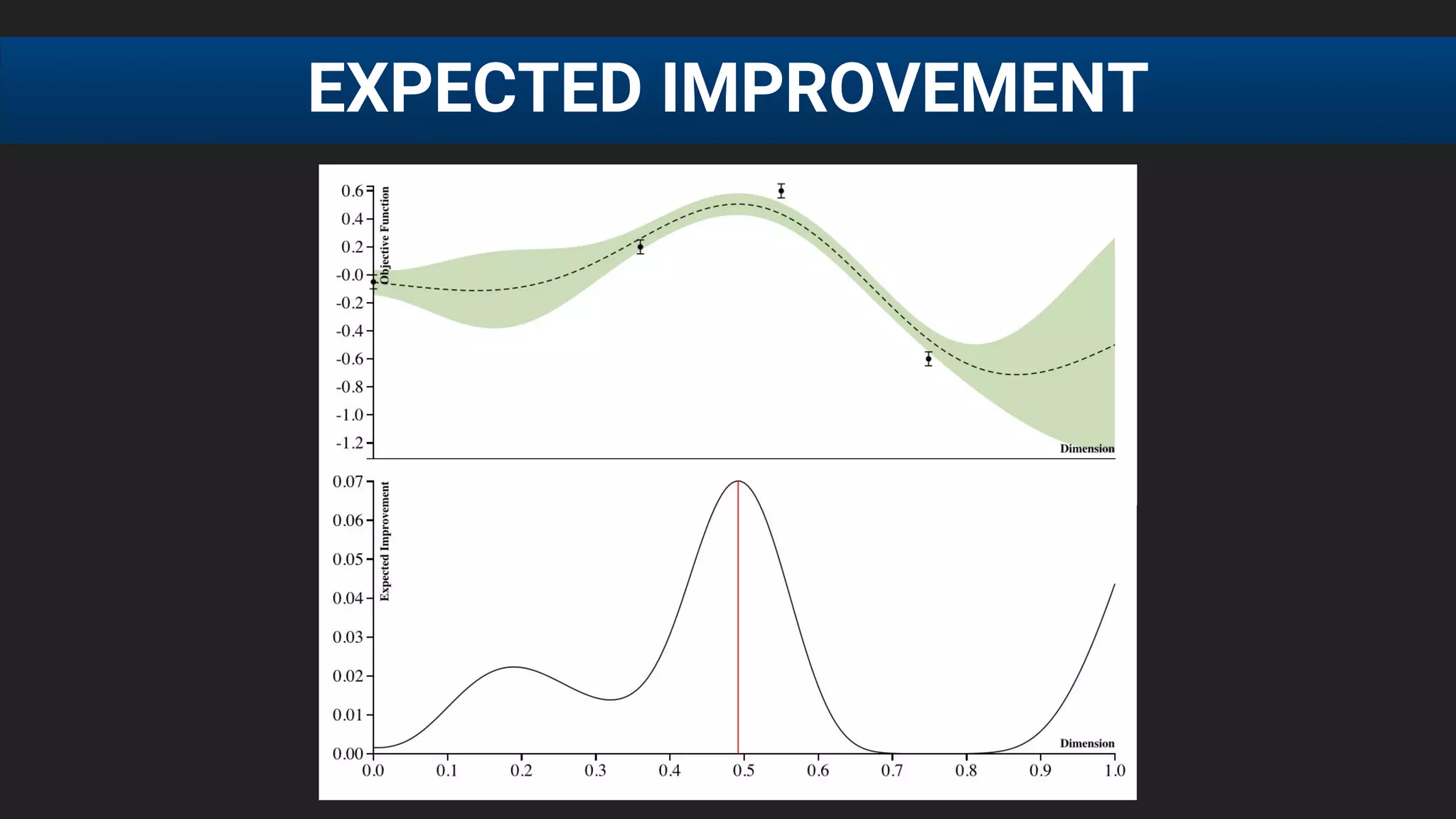


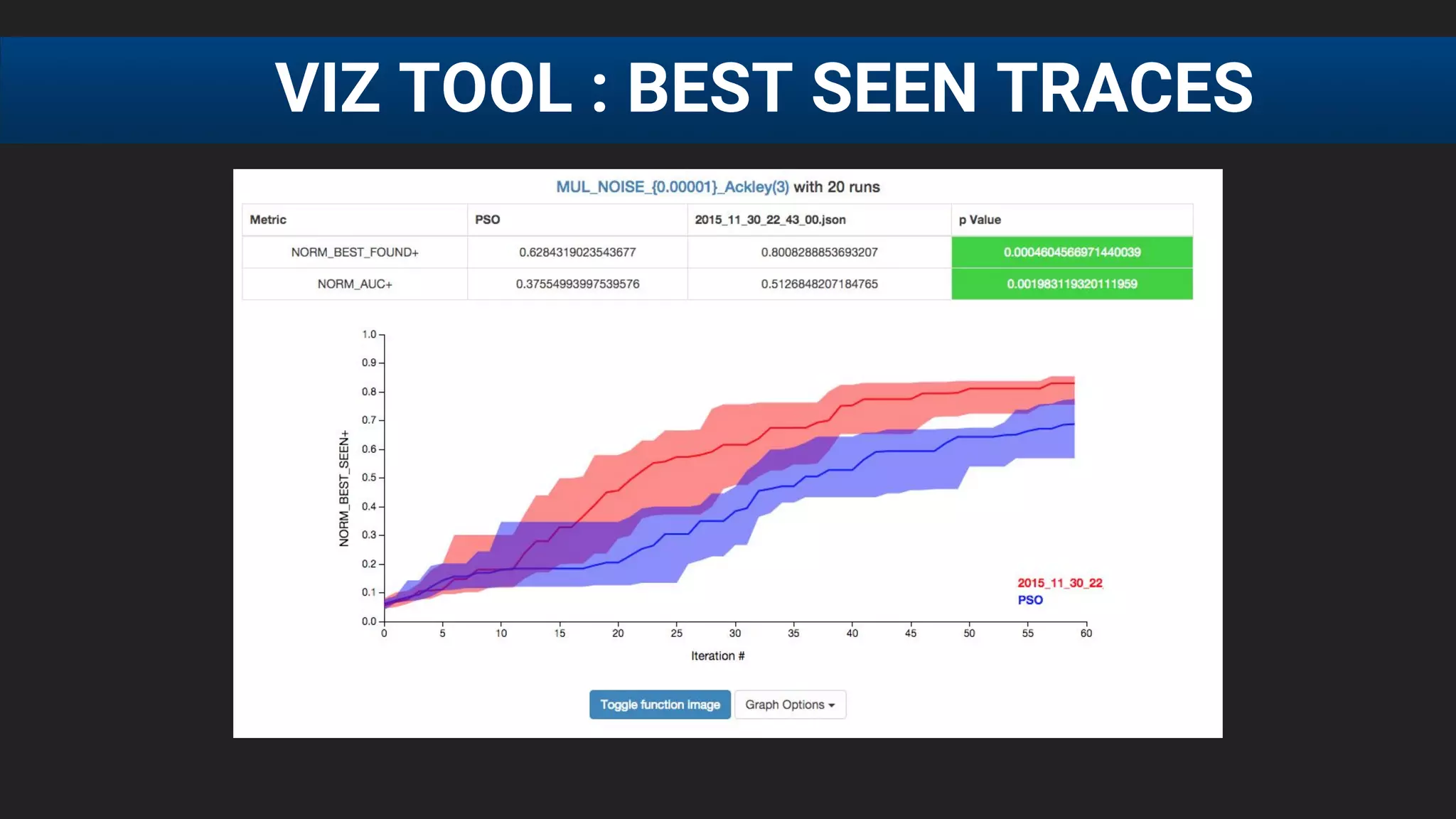
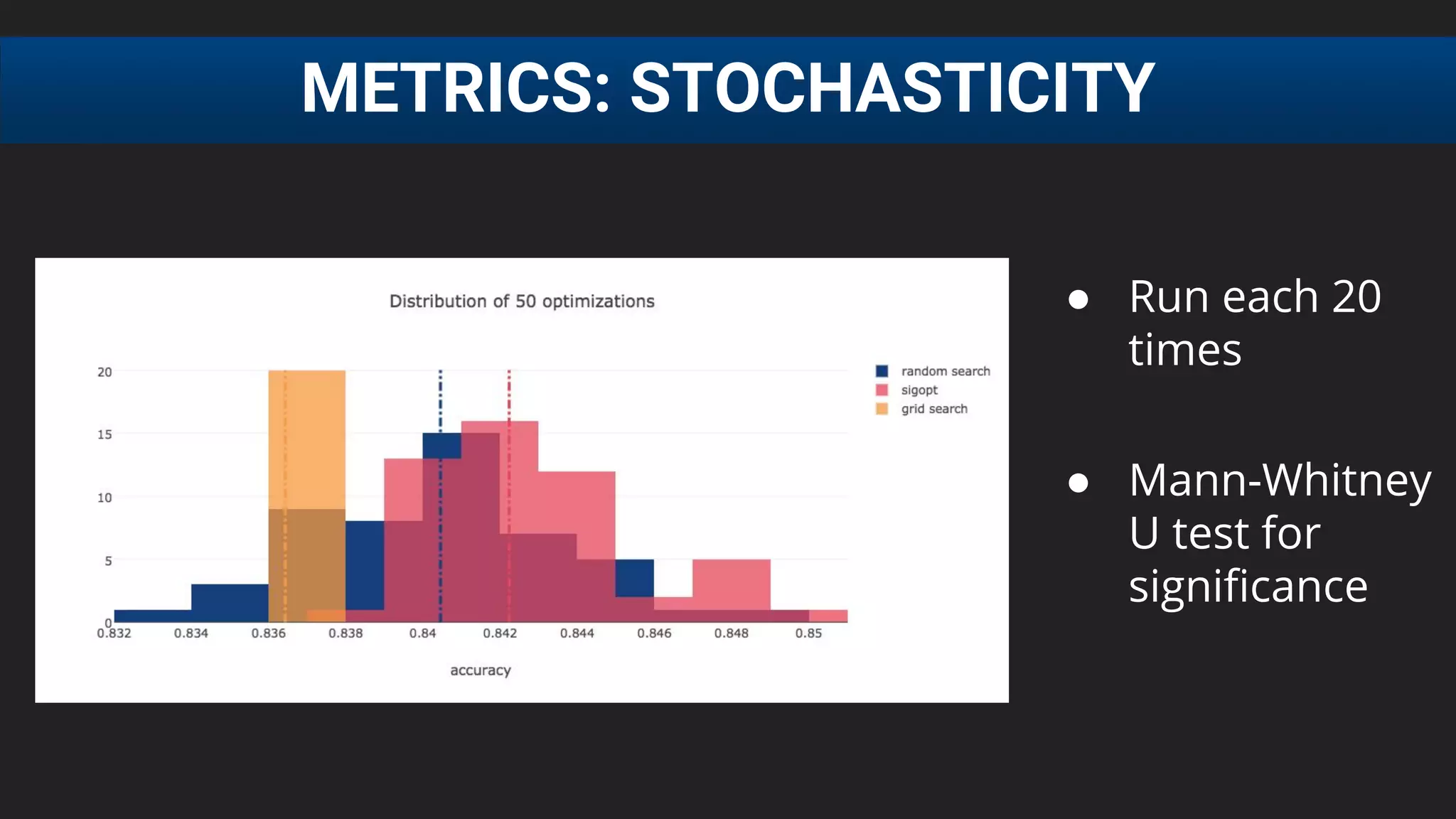










![● E[f (λ)] after 20 runs, each run consisting of 60 function
evaluations
● For Grid Search : 64 evenly spaced parameter
configurations (order shuffled randomly)
● SigOpt statistical significance over grid and rnd
(p = 0.0001, Mann-Whitney U test)
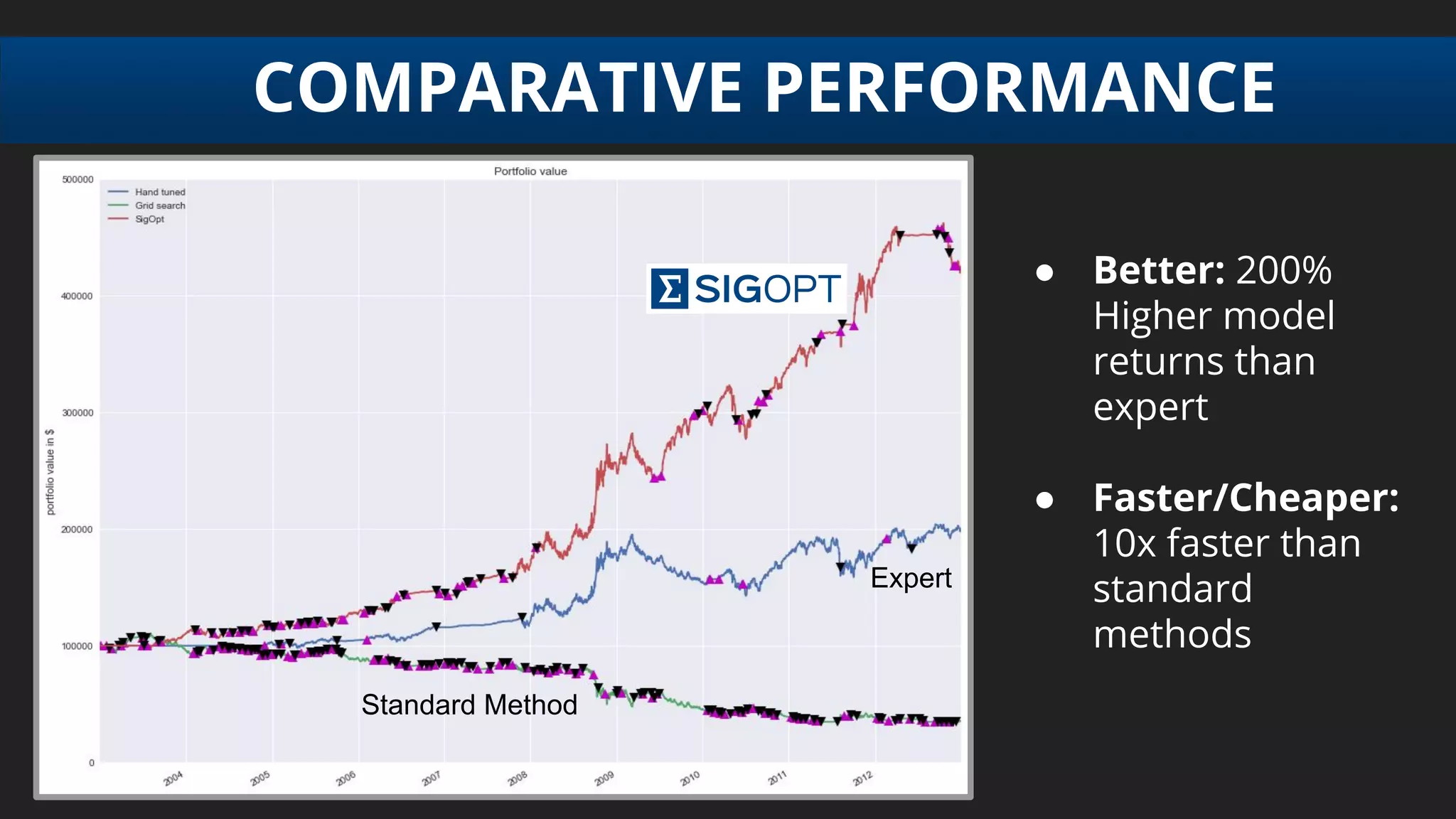
PERFORMANCE
SigOpt Rnd. Search Grid Search No Tuning (Baseline)
Best Found 0.8760 (+5.72%) 0.8673 (+4.67%) 0.8680 (+4.76%) 0.8286](https://image.slidesharecdn.com/odkukdaxqywrhdrnjabs-signature-0bea2a94f96cf5a9f536918d6ef0707d749c8f2c3c6861466fa273a7271fe4a0-poli-161114204535/75/Scott-Clark-Co-Founder-and-CEO-SigOpt-at-MLconf-SF-2016-64-2048.jpg)






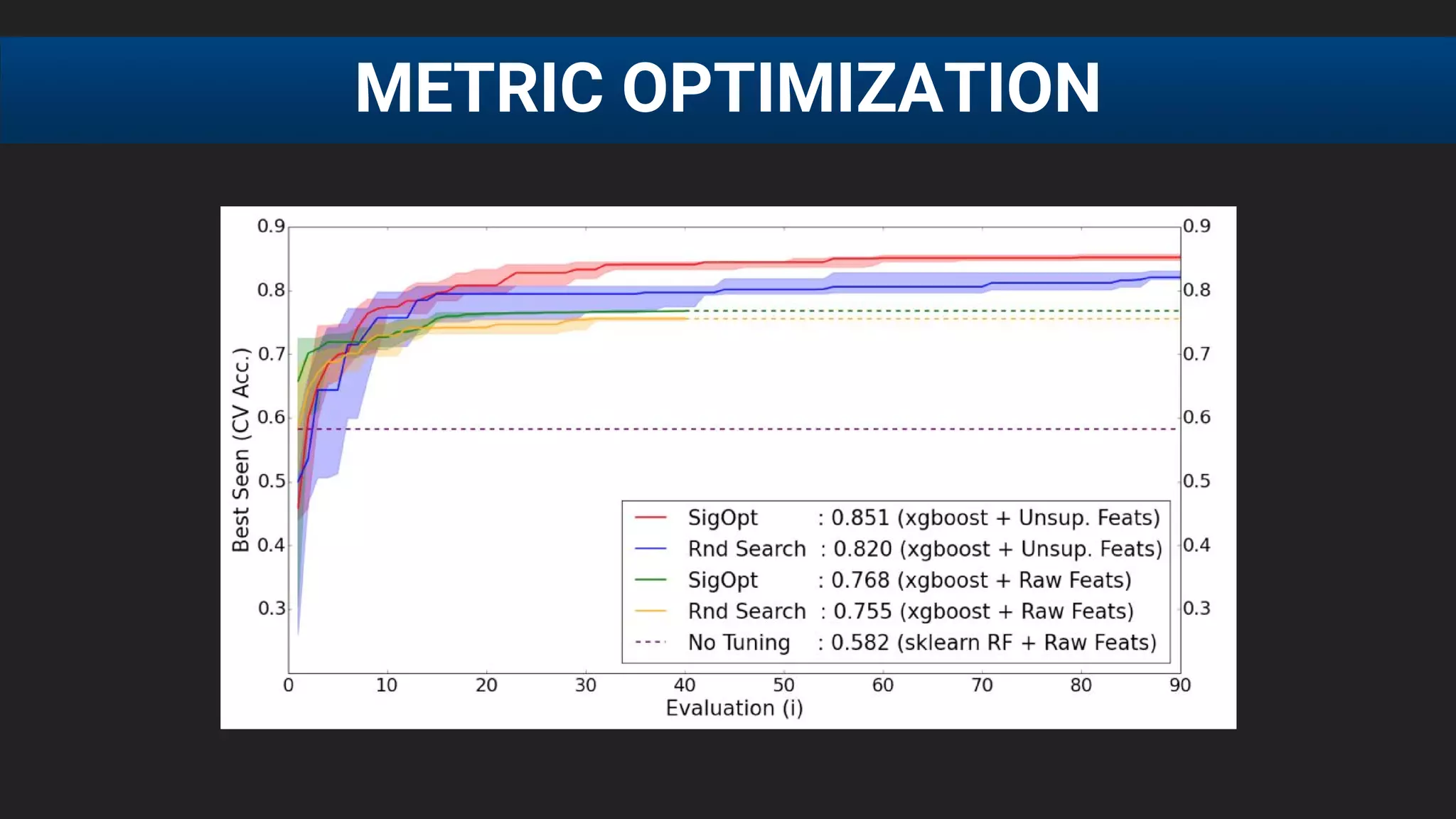



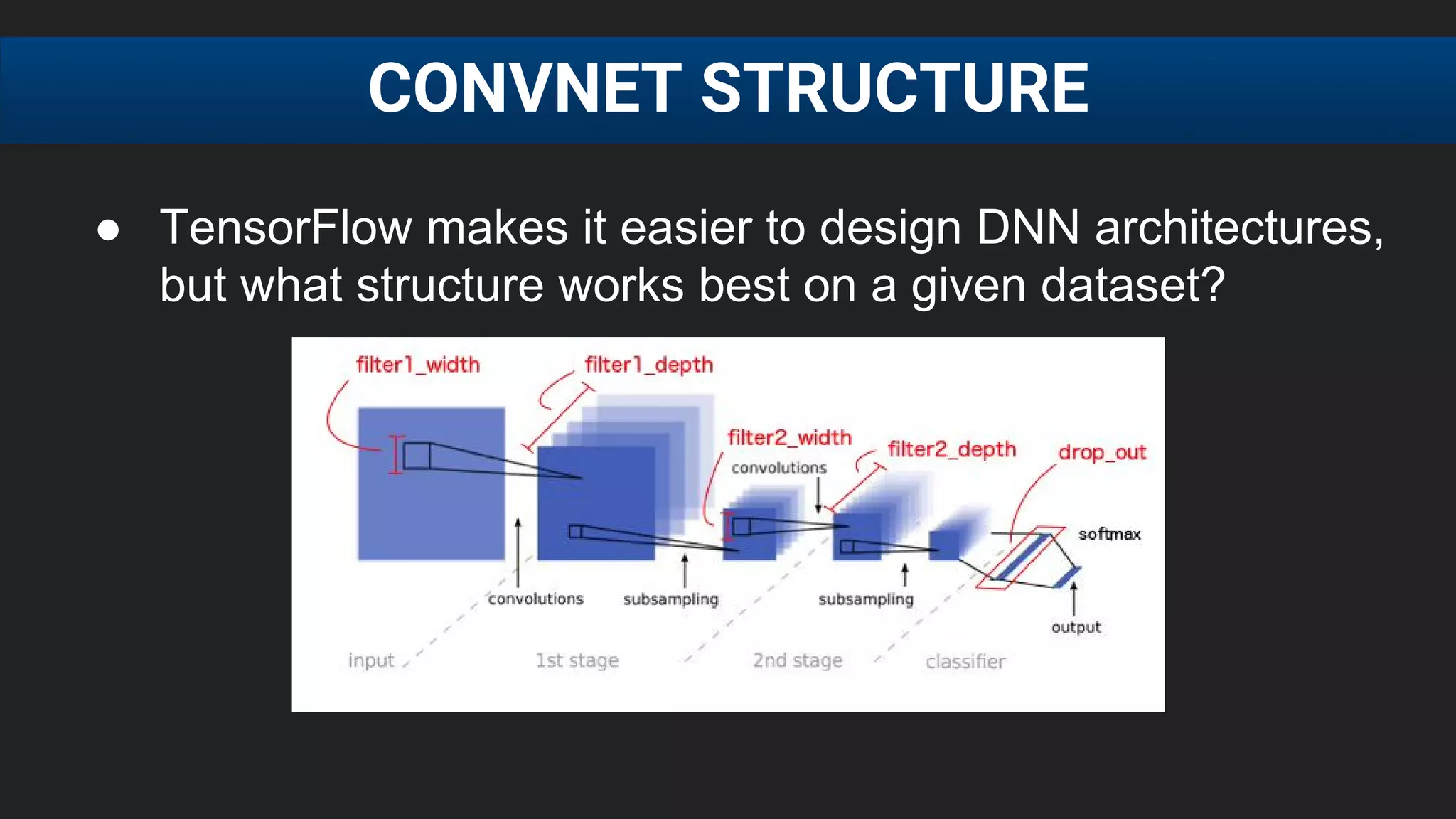


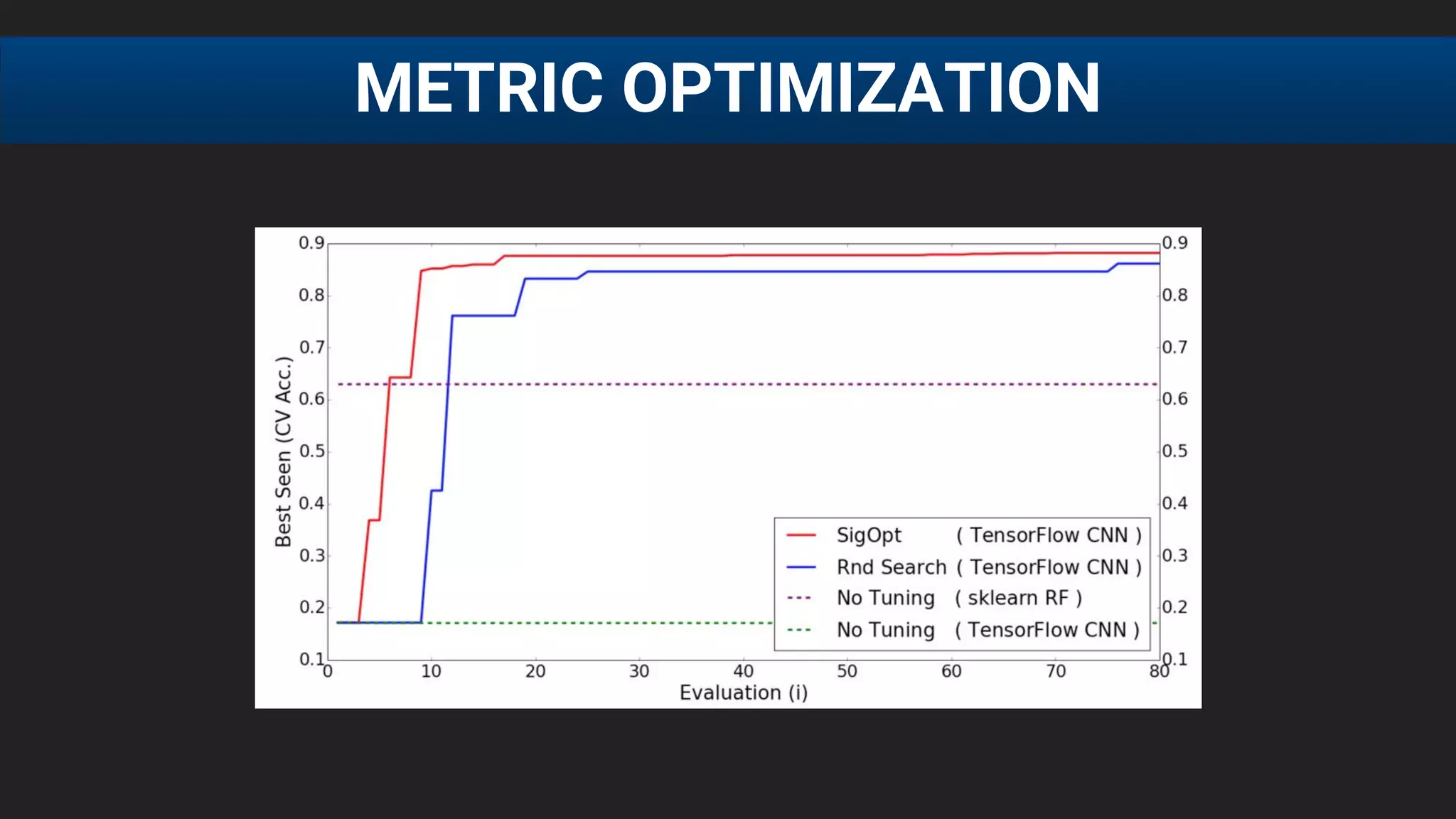
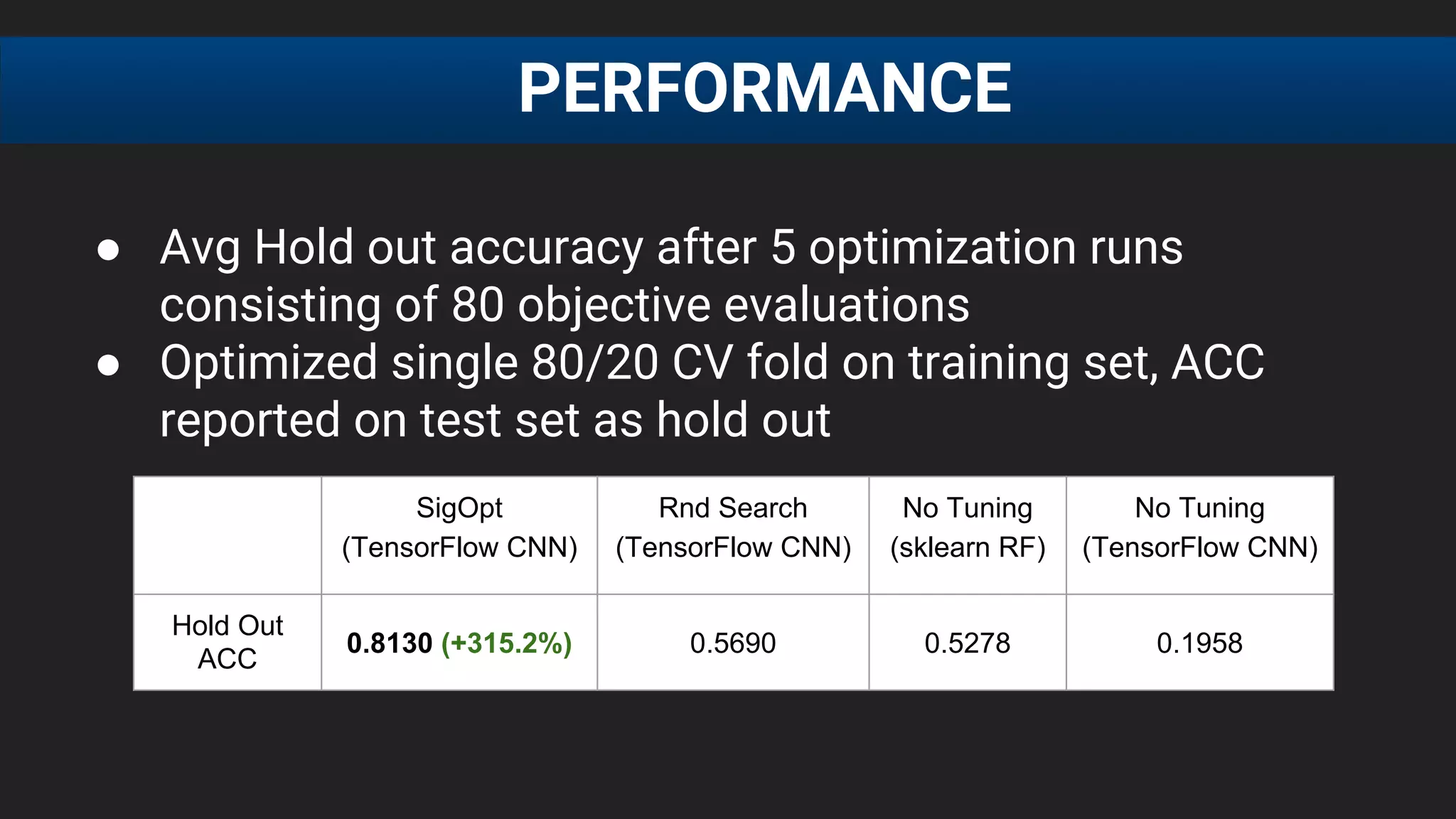


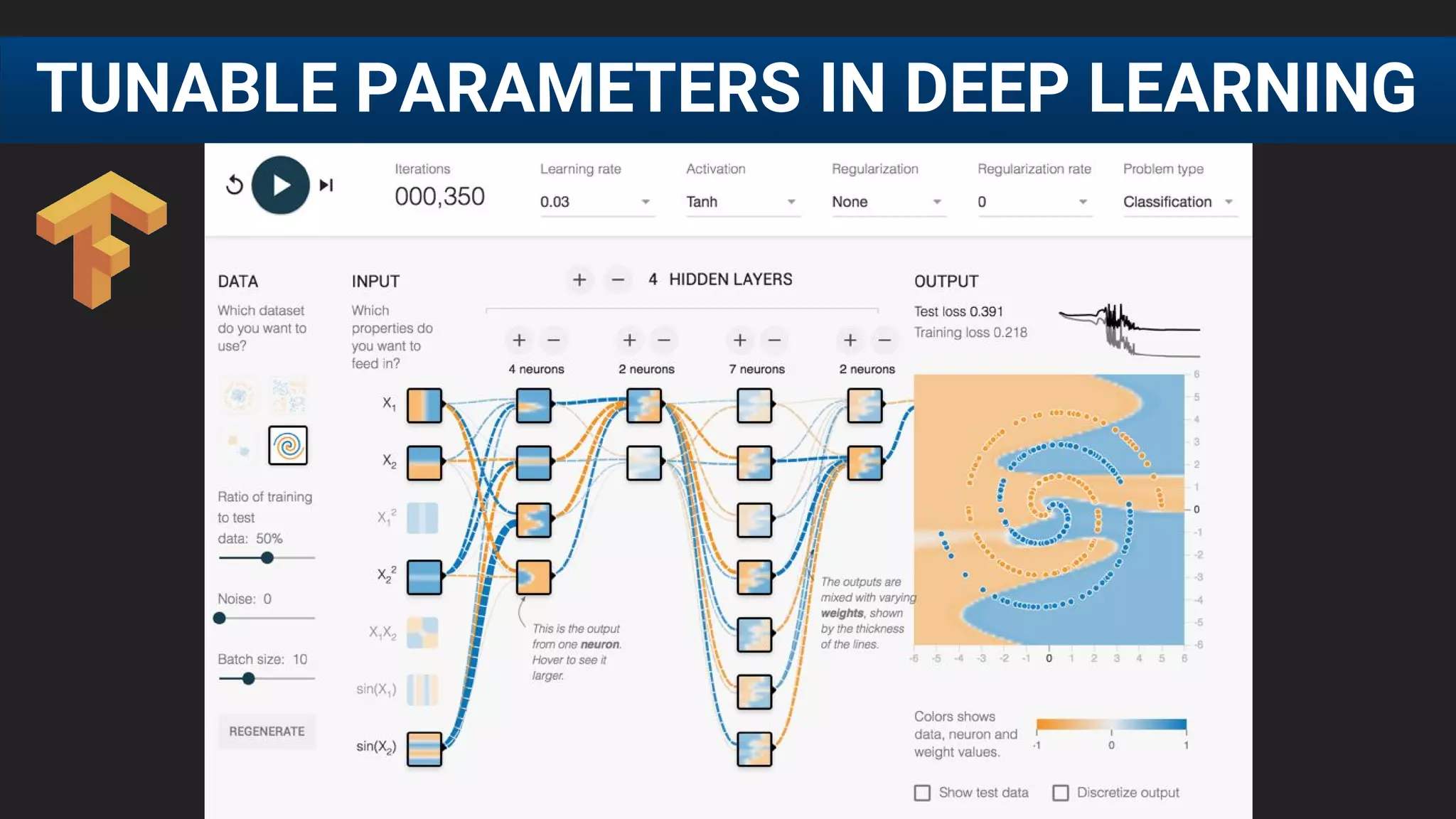
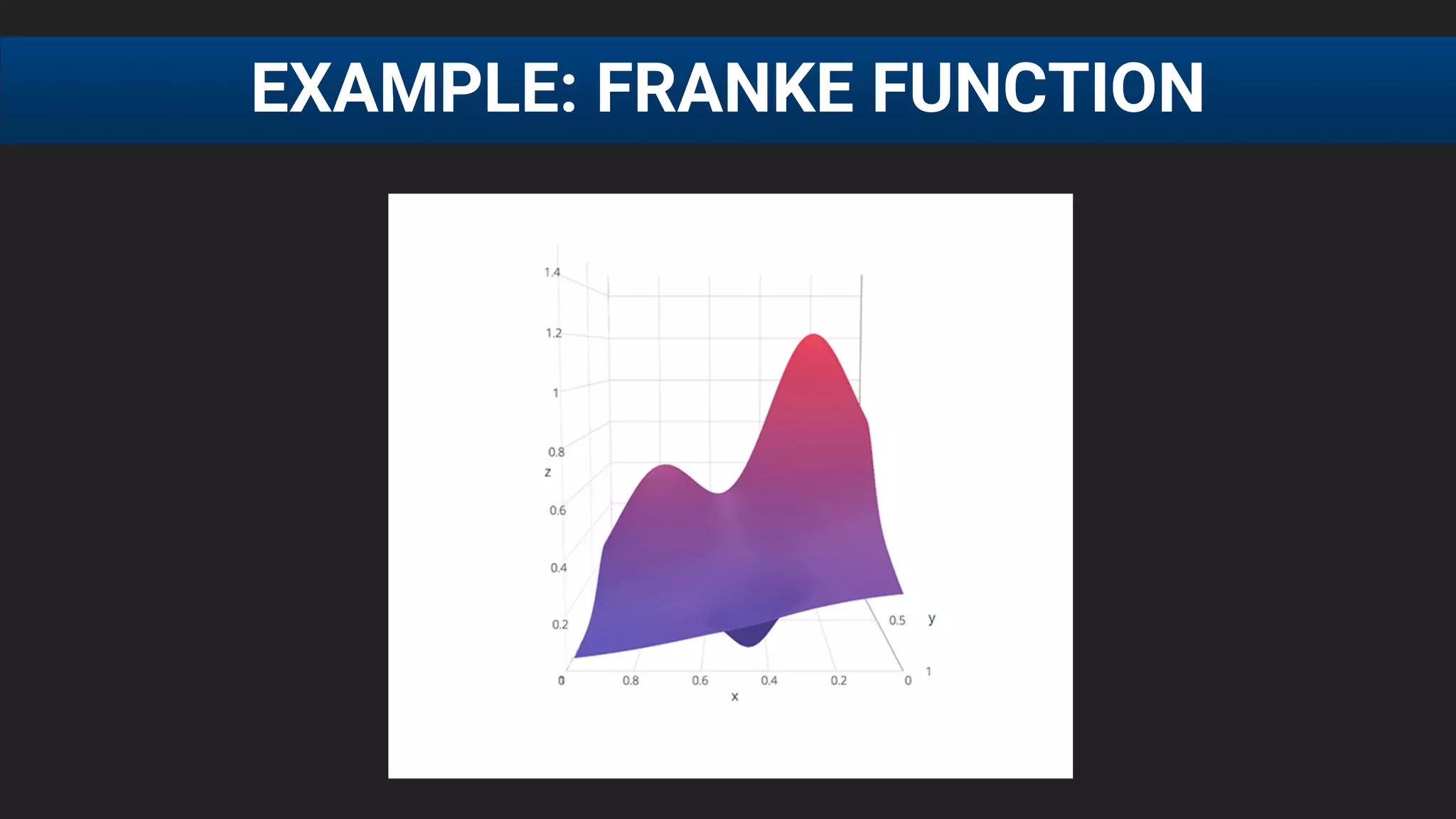
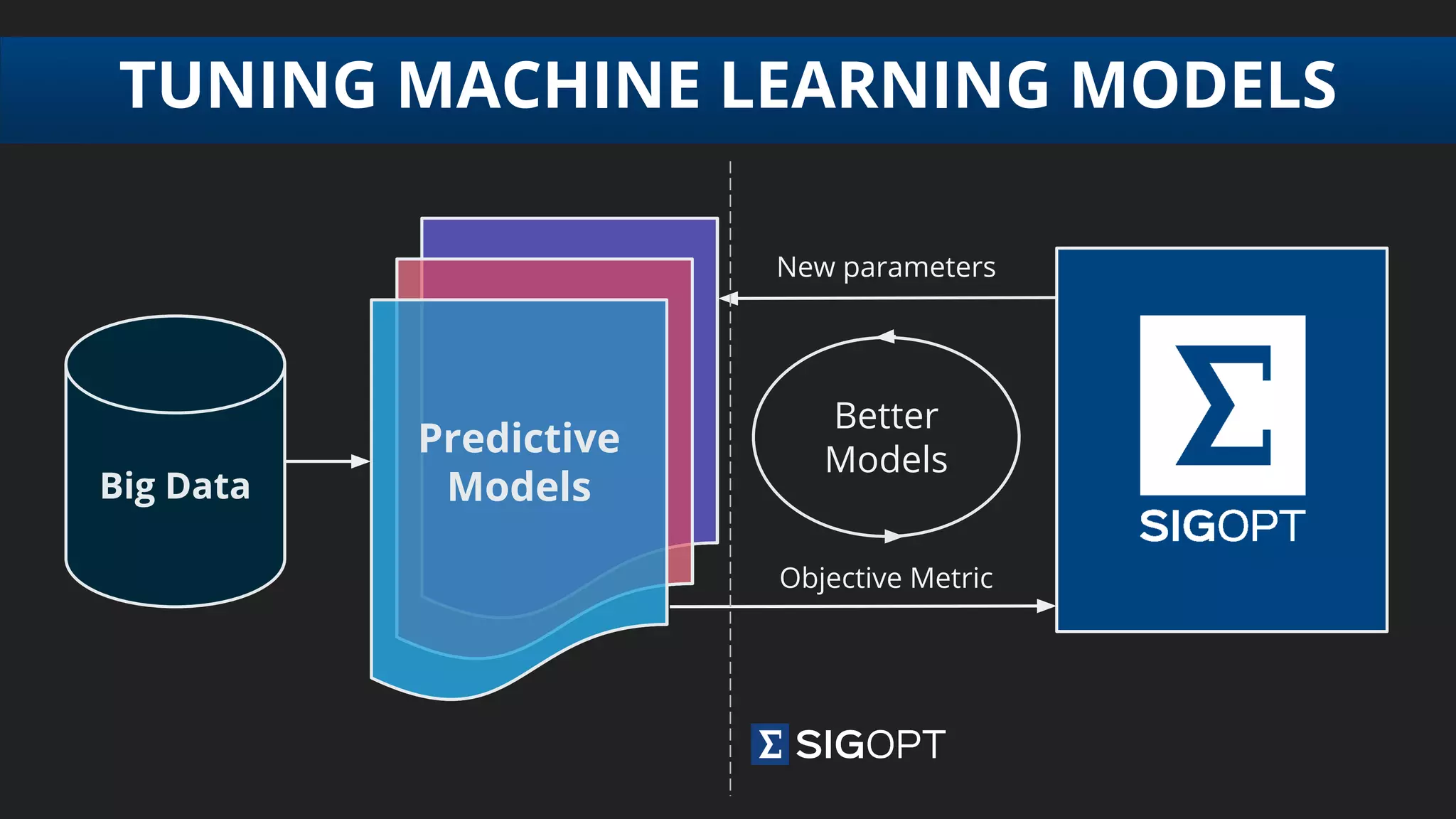
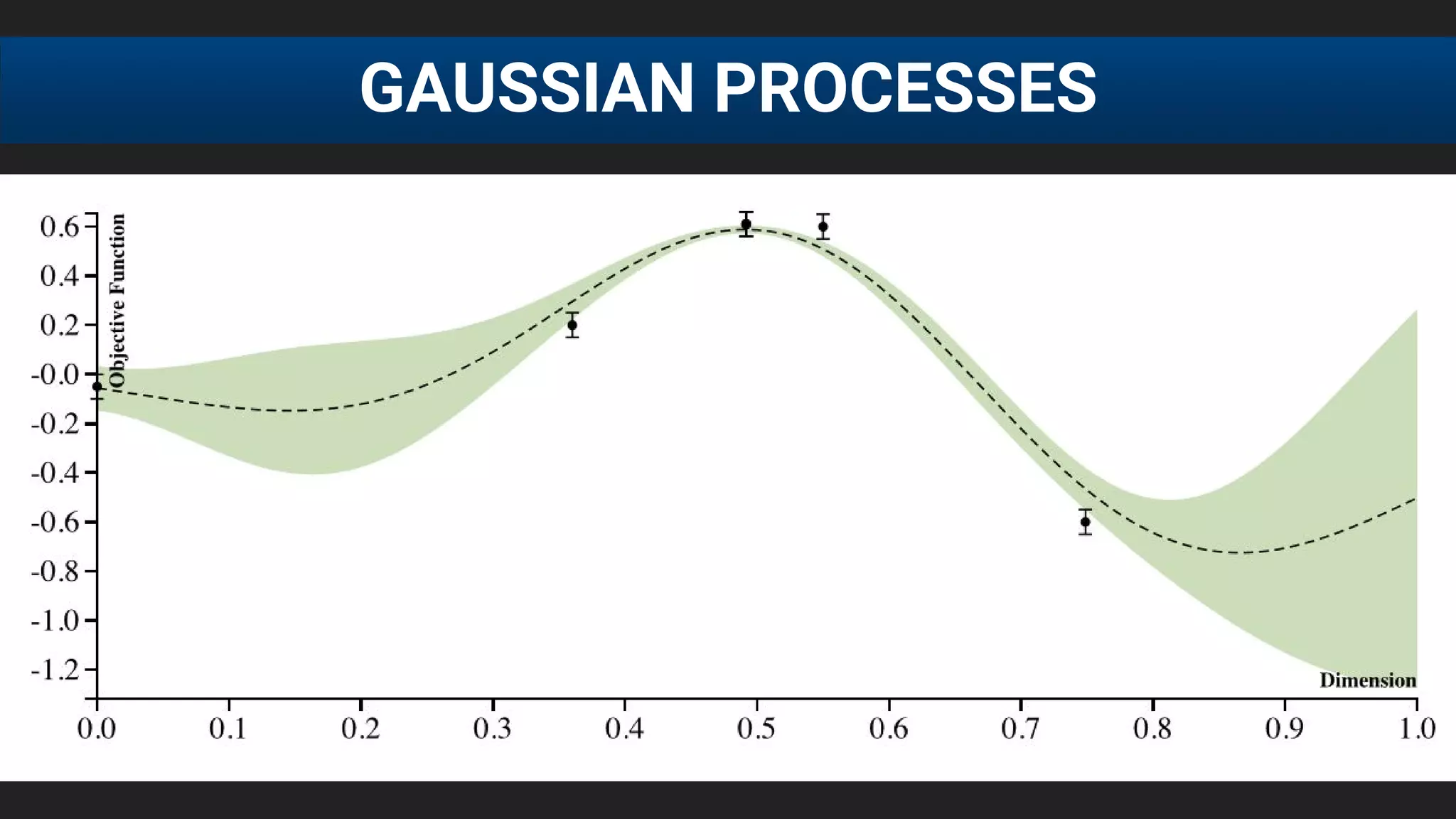
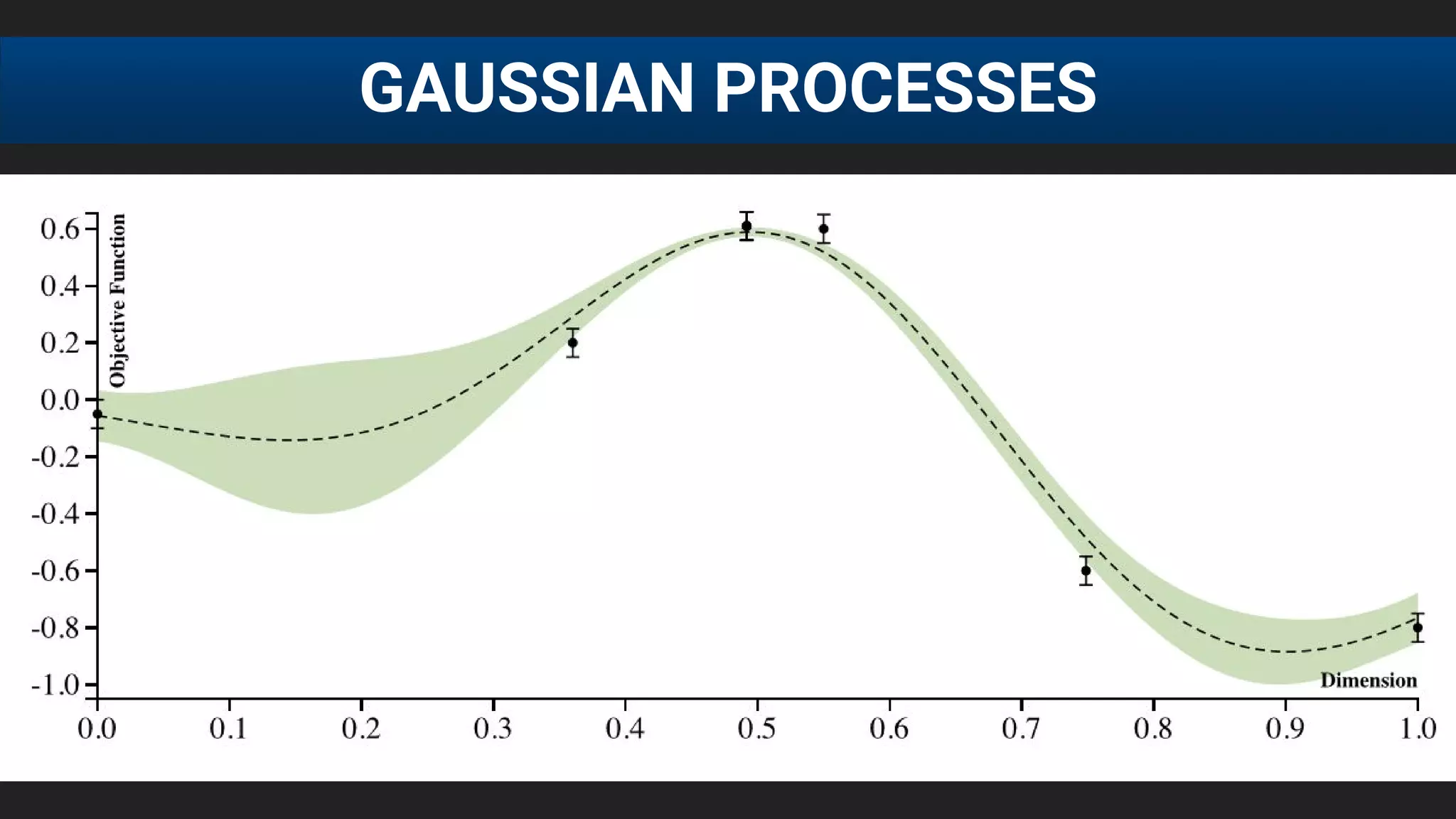
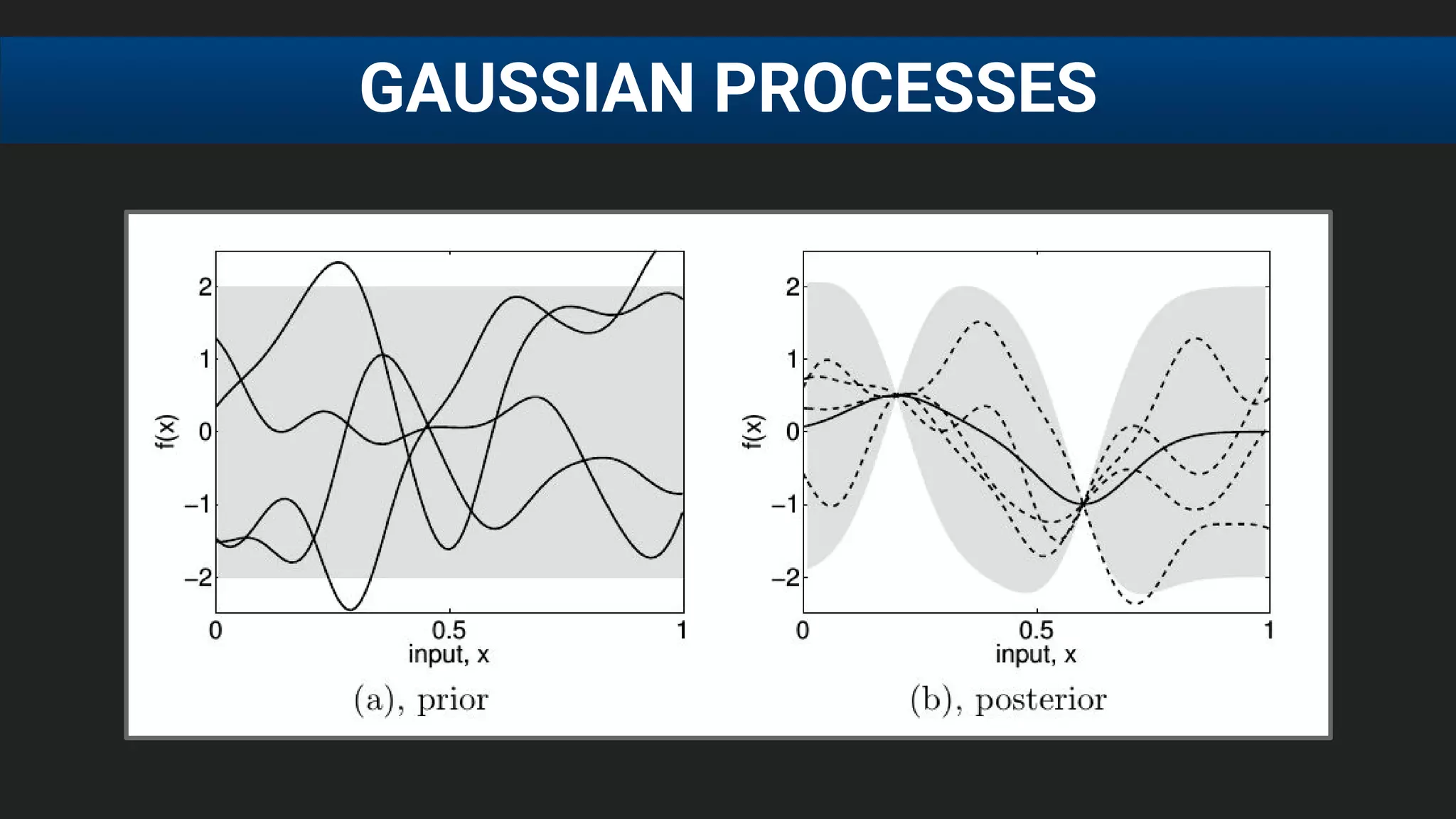
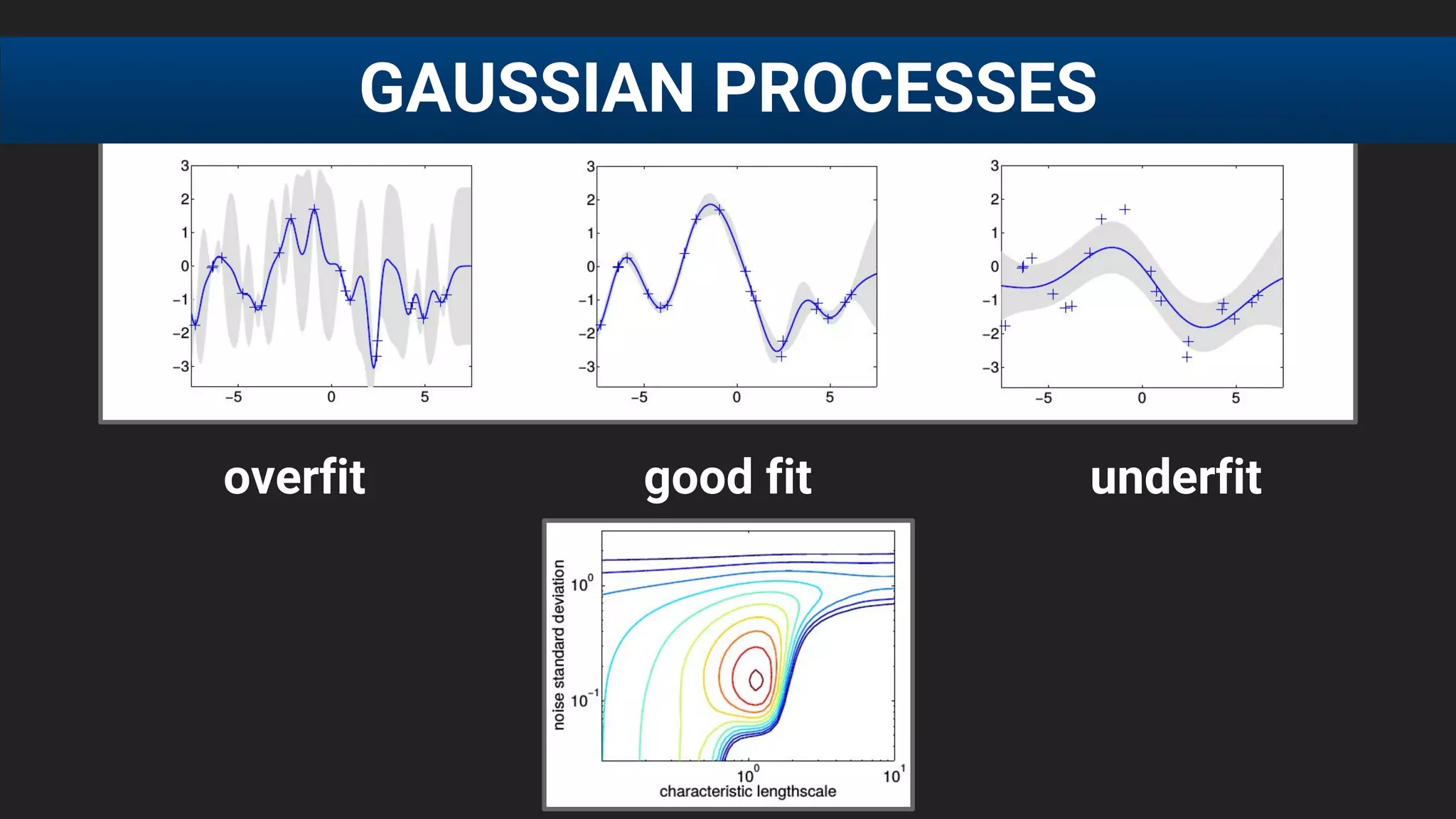
The document discusses the challenges of tuning machine learning models and introduces Bayesian global optimization as an efficient method for hyperparameter tuning. It details the process of building Gaussian processes to identify optimal parameters while minimizing costly evaluations, highlighting examples from real-world applications in loan default prediction and algorithmic trading. Additionally, it compares various tuning methods and underscores the performance improvements and cost savings that can be achieved using SigOpt's services.











































































































