Downloaded 10 times






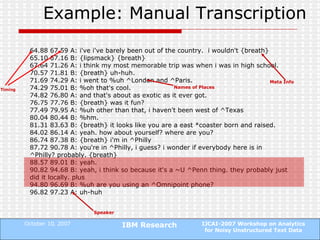






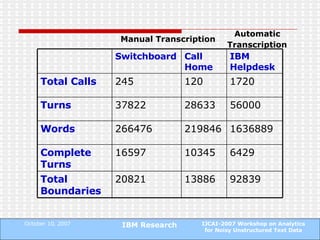
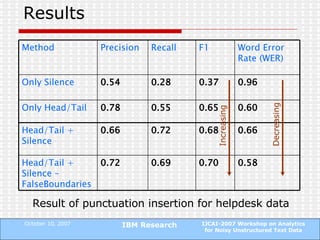


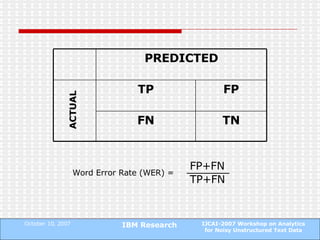
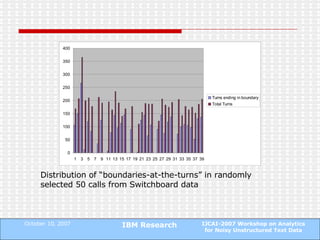
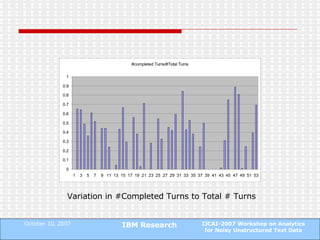



The document proposes a technique to automatically identify sentence boundaries in noisy transcriptions of conversational data using noisily labelled examples. The technique identifies n-grams that frequently occur at sentence boundaries in training data and marks boundaries before or after those n-grams in test data. Evaluating on manual and automatic transcriptions shows the technique improves over using silence information alone, with F1 scores rising from 0.55 to 0.72. Identifying sentence boundaries allows better part-of-speech tagging and noun phrase extraction, improving downstream natural language processing tasks.



































































