Downloaded 104 times



















![+
References
1. “Scalable Similarity-Based Neighborhood Methods with
MapReduce” by Sebastian Schelter, Christoph Boden and
Volker Markl. – RecSys 2012.
2. “Case Study Evaluation of Mahout as a Recommender Platform”
by Carlos E. Seminario and David C. Wilson - Workshop on
Recommendation Utility Evaluation: Beyond RMSE (RUE 2012)
3. http://mahout.apache.org/ - Apache Mahout Project Page
4. http://www.ibm.com/developerworks/java/library/j-mahout/ -
Introducing Apache Mahout
5. [VIDEO] “Collaborative filtering at scale” by Sean Owen
6. [BOOK] “Mahout in Action” by Owen et. al., Manning Pub.
© Varad Meru, 2013](https://image.slidesharecdn.com/recommenderengineitprojv1copy-130715003058-phpapp02/85/Large-scale-Parallel-Collaborative-Filtering-and-Clustering-using-MapReduce-for-Recommender-Engines-23-320.jpg)


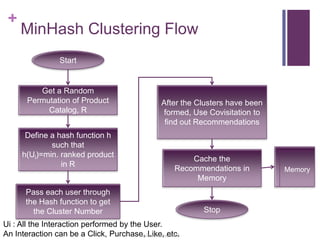
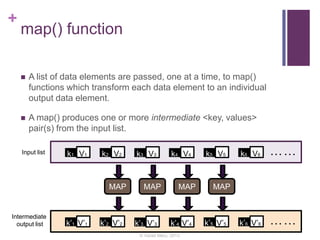
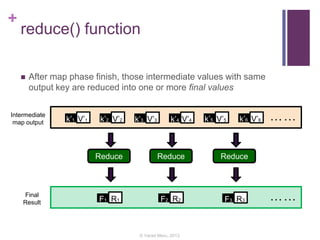
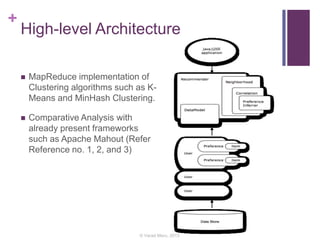
This document discusses building a recommender engine using clustering algorithms like K-Means and MinHash clustering with MapReduce. It provides an introduction to recommender systems and algorithms like collaborative filtering. It describes challenges in building large-scale recommender engines and how Hadoop MapReduce can be used to parallelize recommendation algorithms. The document outlines a proposed system to implement clustering algorithms on MapReduce and evaluate its performance against other frameworks like Apache Mahout using the Netflix dataset.

























































































