Downloaded 85 times








![Cosine Similarity
Cosine similarity is a measure of similarity between two vectors. Mathematically, it is calculated by taking the dot product of the two vectors and dividing by the product of
their magnitude’s
cosine_similarity(x,y)=dot(x,y)/(||x|| * ||y||)
where
• x and y are two vectors
• dot(x,y) is the dot product of the two vectors
• ||x|| and ||y|| are the magnitudes of the vectors
To illustrate cosine similarity with a hypothetical example, let's say we have two vectors x and y:
x = [3, 2] (This represents vector x with two components, 3 and 2)
y = [1, 4] (This represents vector y with two components, 1 and 4)
Calculate the dot product of x and y: x • y = (3 * 1) + (2 * 4) = 3 + 8 = 11
Calculate the magnitudes of vectors x and y:
||x|| = √(3^2 + 2^2) = √(9 + 4) = √13
||y|| = √(1^2 + 4^2) = √(1 + 16) = √17
Calculate the cosine similarity:
cos(θ) = (x • y) / (||x|| * ||y||) = 11 / (√13 * √17) ≈ 0.745](https://image.slidesharecdn.com/ragpatternsandvectorsearchingenerativeai-240326152622-d550d821/85/RAG-Patterns-and-Vector-Search-in-Generative-AI-10-320.jpg)


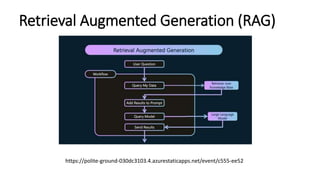
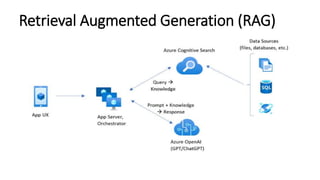
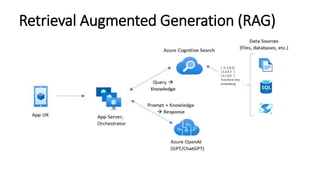




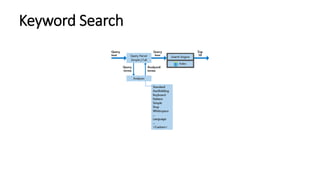
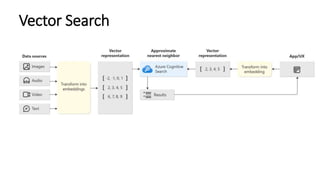
The document discusses various search methods in generative AI, including keyword search, vector search, and hybrid search, highlighting their pros and cons. It covers applications of hybrid search in product recommendations and anomaly detection, along with a brief explanation of cosine similarity and various vector databases. Additionally, it addresses the capabilities of Azure Cognitive Search and references resources for building retrieval augmented generation applications.























































































