Download as PDF, PPTX








![CRUD - Read
db.collection.find(query, projection)
db.inventory.find( {} ) SELECT * FROM inventory
db.inventory.find( { status: "D" } ) SELECT * FROM inventory WHERE status = "D"
db.inventory.find( { status: {
$in: [ "A", "D" ] } } )
SELECT * FROM inventory WHERE status in ("A", "D")
db.inventory.find( { status: "A", qty:
{ $lt: 30 } } )
SELECT * FROM inventory WHERE status = "A" AND qty < 30
db.inventory.find( {
status: "A", $or: [ { qty:
{ $lt: 30 } }, { item: /^p/ }
] } )
SELECT * FROM inventory WHERE status = "A" AND ( qty <
30 OR item LIKE "p%")](https://image.slidesharecdn.com/quickoverviewonmongodb-180302174201/85/Quick-overview-on-mongo-db-8-320.jpg)










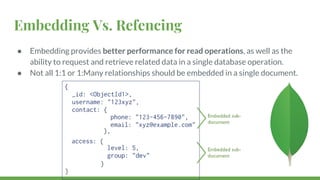
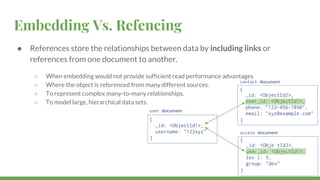





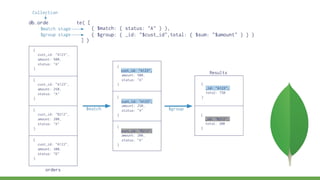



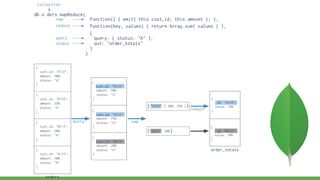


This document provides a quick overview of MongoDB, including: - MongoDB trades off ACID compliance for availability and scalability. - CRUD operations allow creating, reading, updating, and deleting documents. Indexes improve query performance. - Embedded documents and references model one-to-one and one-to-many relationships. - Aggregation operations group and transform data from multiple documents. Map-reduce is an alternative but less efficient.



































































