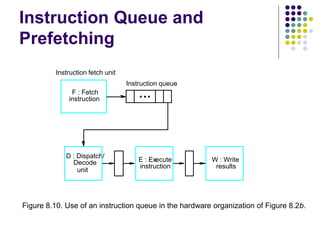
The document discusses various types of hazards that can cause pipelines to stall, including data hazards that occur when an instruction depends on the result of a previous instruction, instruction hazards caused by delays in instruction availability, and structural hazards when two instructions require the same hardware resource. It provides examples of how forwarding can resolve data hazards by passing instruction results directly to dependent instructions. It also covers branch penalties and ways to reduce them such as branch prediction and instruction queues.