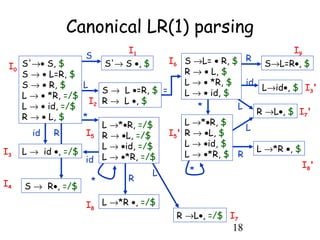
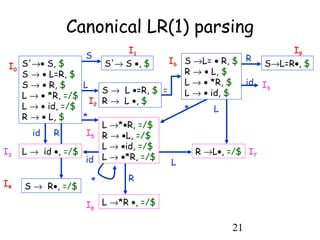
LR parsing techniques include SLR, Canonical LR, and LALR(1) parsing. SLR parsing uses LR(0) items and the FOLLOW set to resolve conflicts, but may introduce conflicts. Canonical LR parsing uses LR(1) items which include lookahead information to avoid conflicts found in SLR parsing. LALR(1) parsing reduces the number of states compared to Canonical LR by merging states with the same core items. LALR(1) can introduce reduce/reduce conflicts, while SLR and Canonical LR can have shift/reduce conflicts.







![8
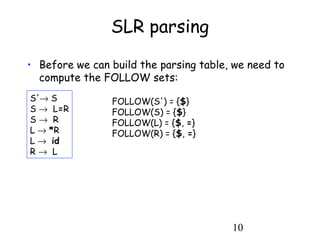
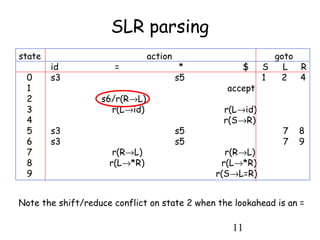
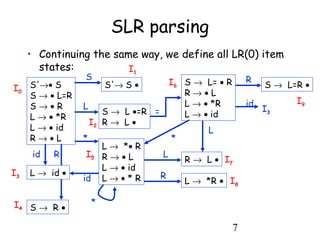
SLR parsing
• The automaton and the FOLLOW sets tell us how
to build the parsing table:
– Shift actions
• If from state i, you can go to state j when parsing a
token t, then slot [i,t] of the table should contain
action "shift and go to state j", written sj
– Reduce actions
• If a state i contains a handle A→α•, then slot [i, t] of
the table should contain action "reduce using A→α",
for all tokens t that are in FOLLOW (A). This is
written r(A→α)
– The reasoning is that if the lookahead is a symbol that
may follow A, then a reduction A→α should lead closer
to a successful parse.
• continued on next slide](https://image.slidesharecdn.com/presentationmamsaimakanwal-180318165313/85/Presentation-mam-saima-kanwal-8-320.jpg)