Download as PDF, PPTX


![10
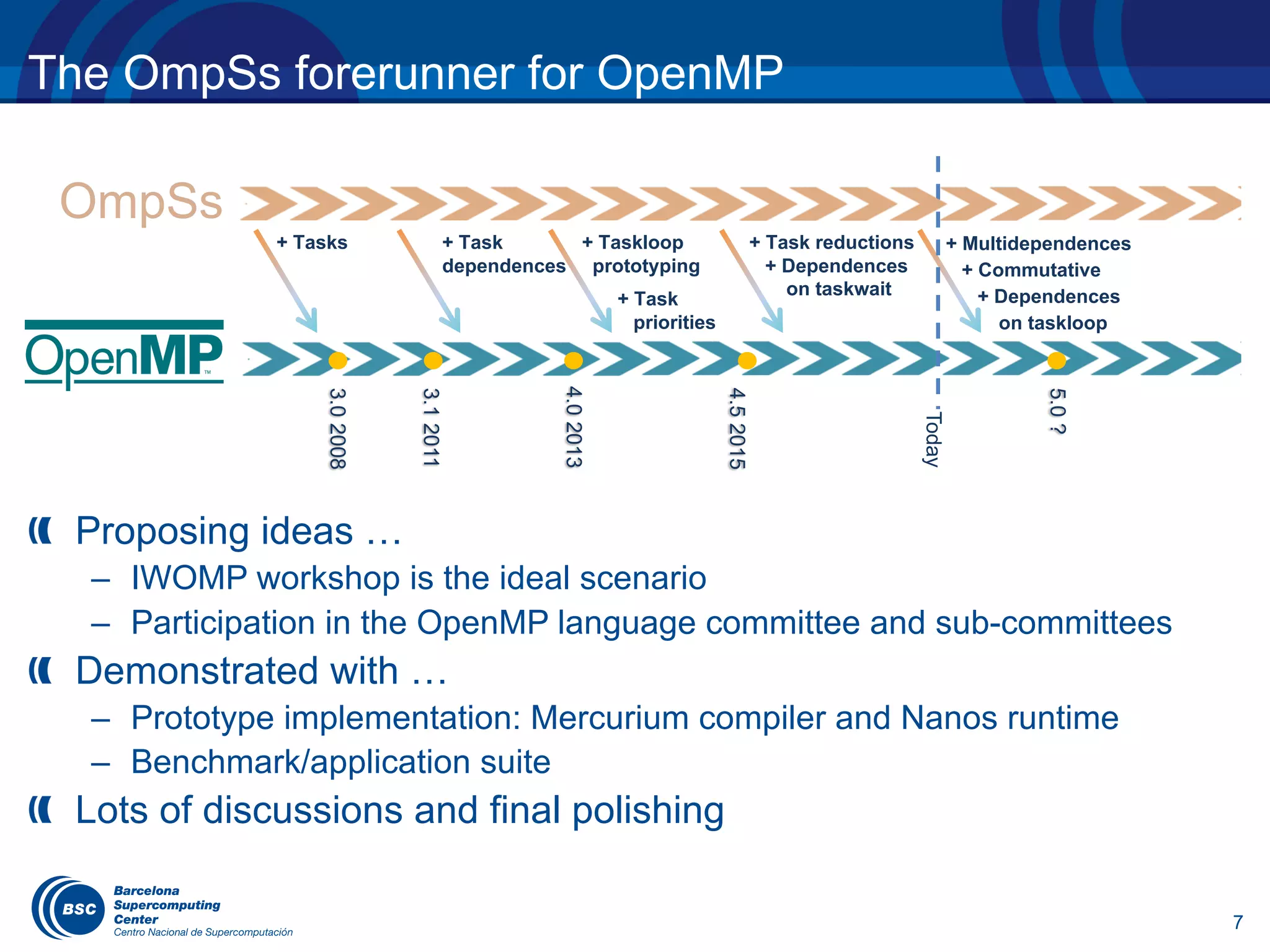
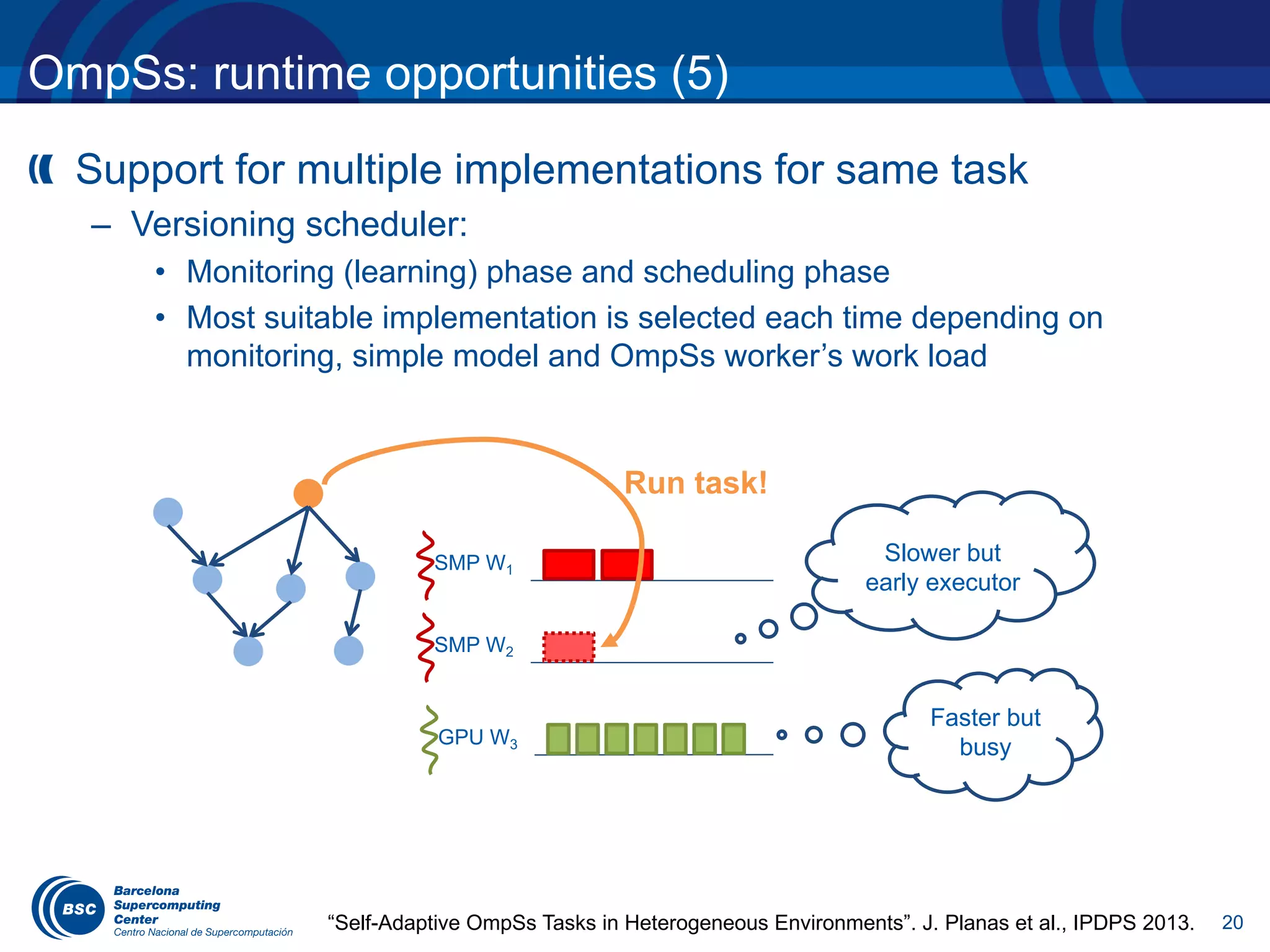
OmpSs influencing tasking model evolution (3)
Tasks become chunks of iterations of one or more associated
loops
Dependences between tasks generated in the same or
different taskloop construct under discussion
tasks out of loops and granularity control (4.5)
#pragma omp taskloop [num_tasks(value) | grainsize(value)]
for-loops
#pragma omp taskloop block(2) grainsize(B, B)
depend(in : block[i-1][j], block[i][j-1])
depend(in : block[i+1][j], block[i][j+1])
depend(out: block[i][j])
for (i=1; i<n i++)
for (j=1; j<n;j++)
foo(i, j);
T T T T
T T T T
T T T T
T T T T](https://image.slidesharecdn.com/eduardayguadeucm2017-170405041719/75/OpenMP-tasking-model-from-the-standard-to-the-classroom-11-2048.jpg)
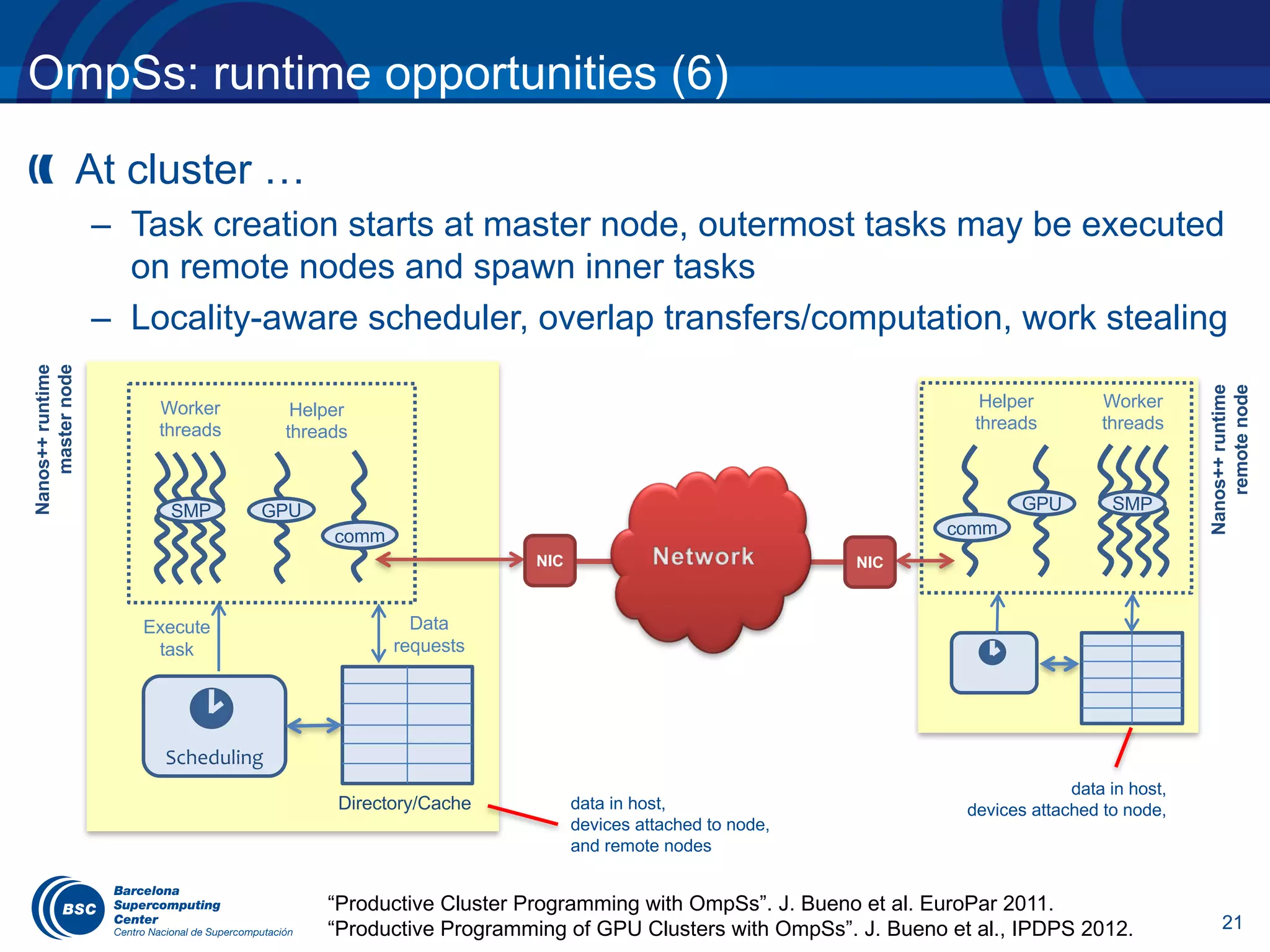
![11
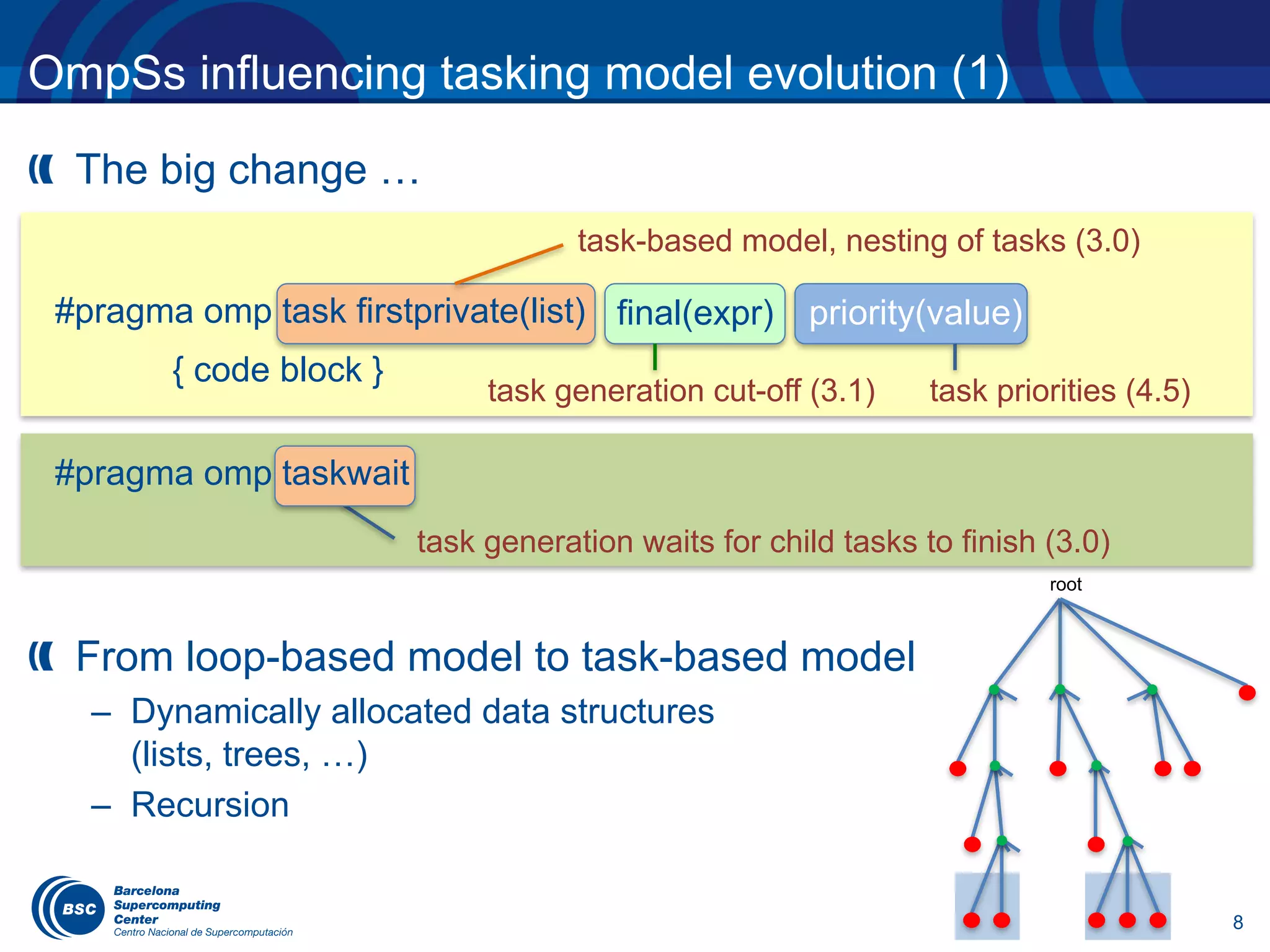
OmpSs influencing tasking model evolution (4)
Reduction operations on task and taskloop not yet supported,
currently in discussion
#pragma omp taskgroup reduction(+: res)
{
while (node) {
#pragma omp task in_reduction(+: res)
res += node->value;
node = node->next;
}
}
#pragma omp taskloop grainsize(BS) reduction(+: res)
for (i = 0; i < N; ++i) {
res += foo(v[i]);
}](https://image.slidesharecdn.com/eduardayguadeucm2017-170405041719/75/OpenMP-tasking-model-from-the-standard-to-the-classroom-12-2048.jpg)
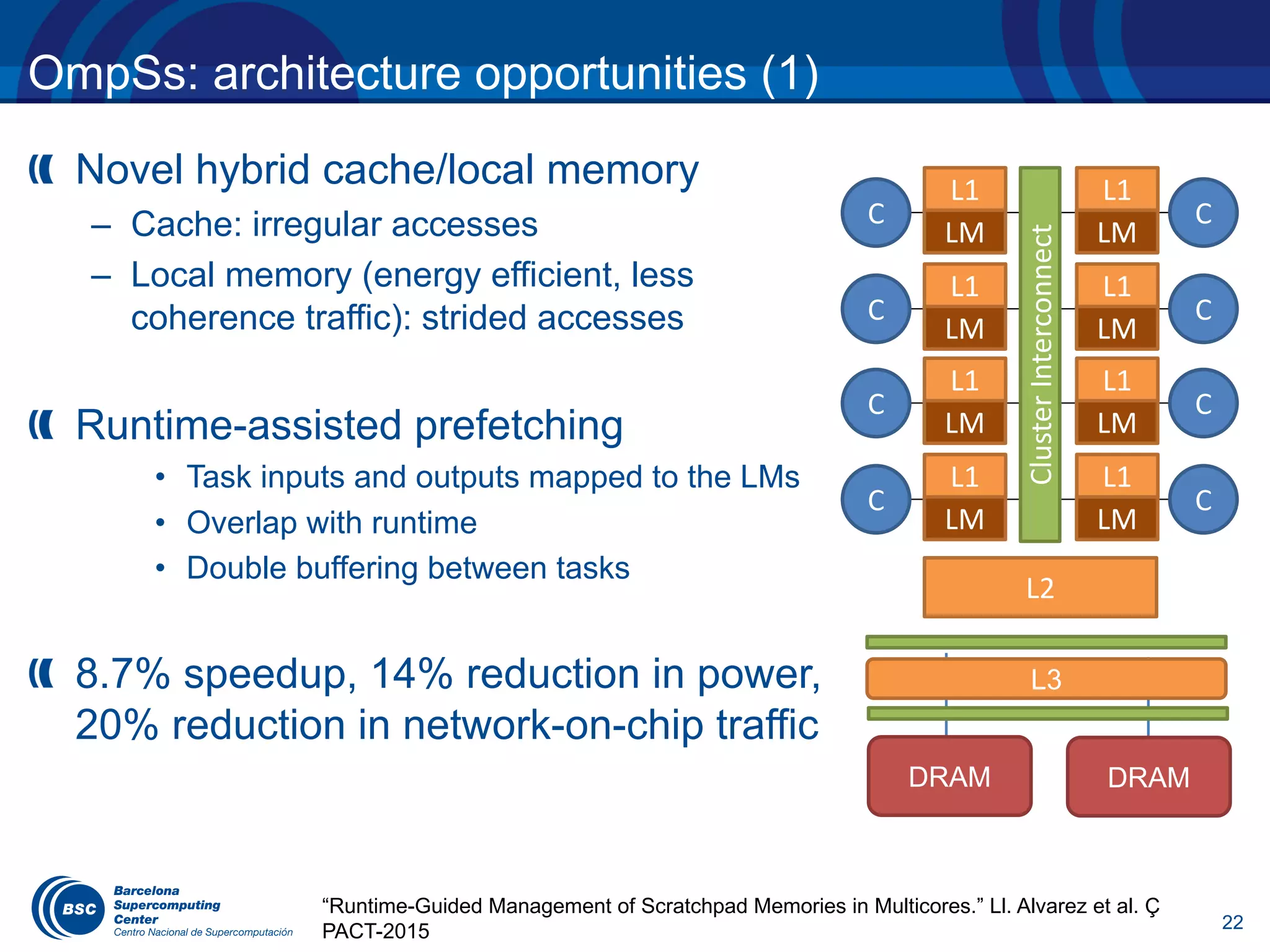
![12
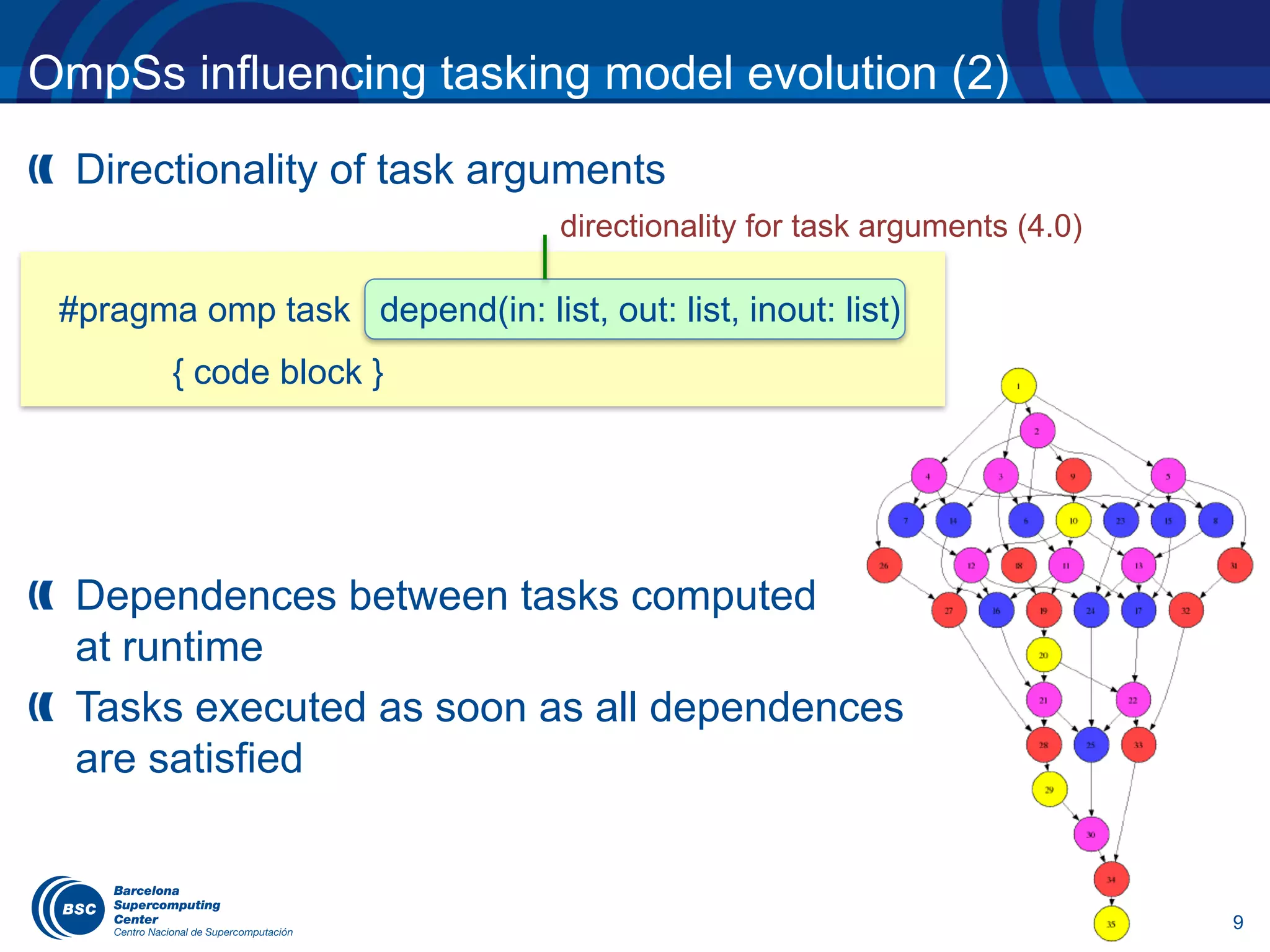
OmpSs influencing tasking model evolution (5)
The number of task dependences have to be constant at
compile time à multidependences proposal under discussion
for (i = 0; i < l.size(); ++i) {
#pragma omp task depend(inout: l[i]) // T1
{ ... }
}
#pragma omp task depend(in: {l[j], j=0:l.size()}) // T2
for (i = 0; i < l.size(); ++i) {
...
}
Defines an iterator with a range of values that only exists
in the context of the directive. Equivalent to:
depend(in: l[0], l[1], ..., l[l.size()-1])
T1 T1 T1 T1
T2
…](https://image.slidesharecdn.com/eduardayguadeucm2017-170405041719/75/OpenMP-tasking-model-from-the-standard-to-the-classroom-13-2048.jpg)
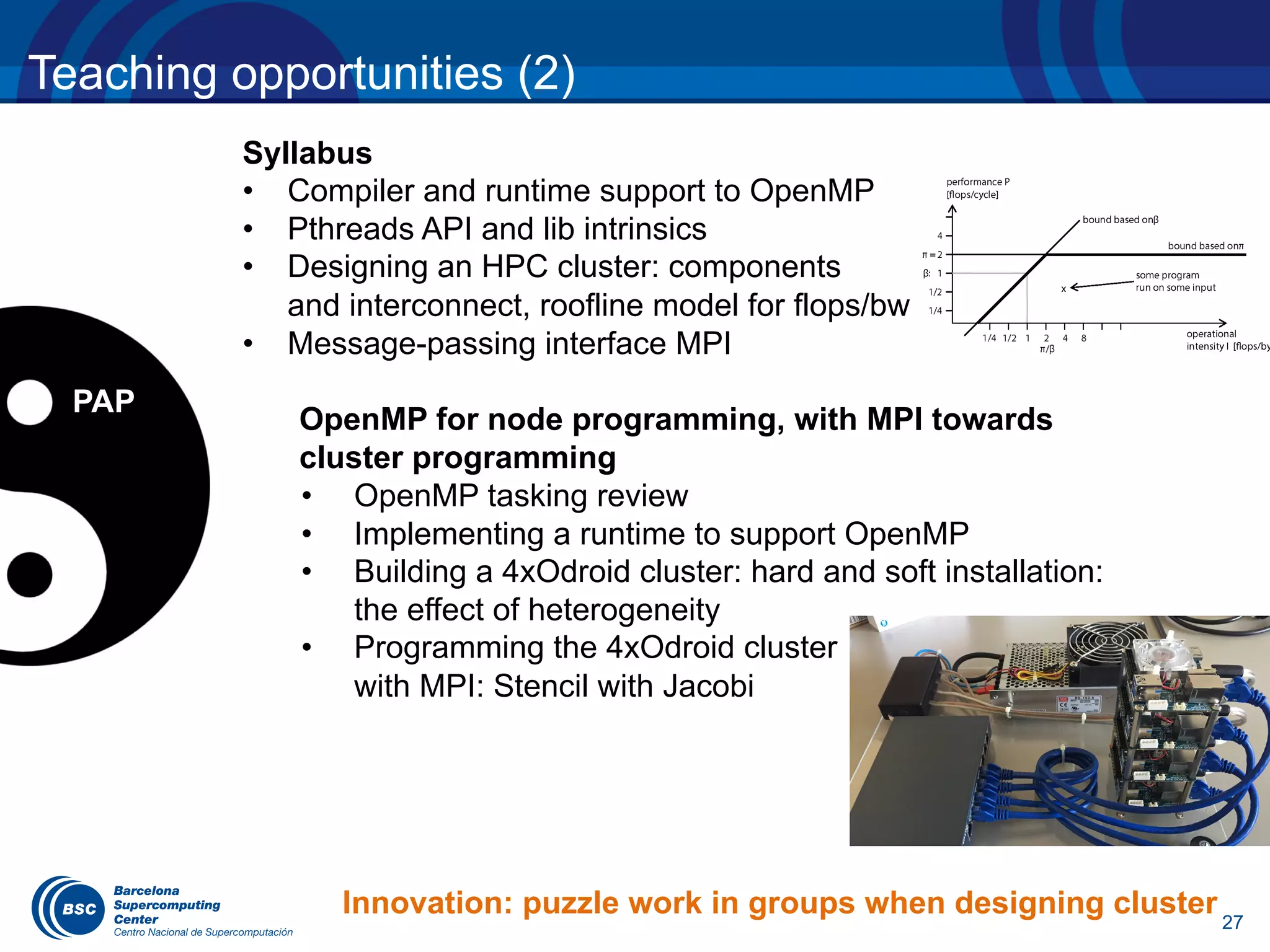
![13
OmpSs influencing tasking model evolution (6)
New dependence type that relaxes the execution order of
commutative tasks but keeping mutual exclusion between
them
T1
T3
T2
T2
for (i = 0; i < l.size(); ++i) {
#pragma omp task depend(out: l[i])
// T1
}
for (i = 0; i < l.size(); ++i) {
#pragma omp task shared(x) depend(in: l[i])
depend(inout: x)
// T2
}
#pragma omp task shared(x) depend(in: x) // T3
for (i = 0; i < l.size(); ++i) {
...
}
T1
T1
T1
T2
T2](https://image.slidesharecdn.com/eduardayguadeucm2017-170405041719/75/OpenMP-tasking-model-from-the-standard-to-the-classroom-14-2048.jpg)
![14
OmpSs influencing tasking model evolution (6)
New dependence type that relaxes the execution order of
commutative tasks but keeping mutual exclusion between
them
T1
T3
T2
T2
for (i = 0; i < l.size(); ++i) {
#pragma omp task depend(out: l[i])
// T1
}
for (i = 0; i < l.size(); ++i) {
#pragma omp task shared(x) depend(in: l[i])
depend(commutative: x)
// T2
}
#pragma omp task shared(x) depend(in: x) // T3
for (i = 0; i < l.size(); ++i) {
...
}
T1
T1
T1
T2
T2](https://image.slidesharecdn.com/eduardayguadeucm2017-170405041719/75/OpenMP-tasking-model-from-the-standard-to-the-classroom-15-2048.jpg)
![Example: nbody
#pragma omp target device(smp) copy_deps
#pragma omp task depend(out: [size]out), in: [npart]part)
void comp_force (int size, float time, int npart, Part* part, Particle *out, int gid);
#pragma omp target device(fpga) ndrange(1,size,128) copy_deps implements (comp_force)
#pragma omp task depend(out: [size]out), in: [npart]part)
__kernel void comp_force_opencl (int size, float time, int npart, __global Part* part,
__global Part* out, int gid);
#pragma omp target device(cuda) ndrange(1,size,128) copy_deps implements (comp_force)
#pragma omp task depend(out: [size]out), in: [npart]part)
__global__ void comp_force_cuda (int size, float time, int npar, Part* part, Particle *out, int gid);
void Particle_array_calculate_forces(Particle* input, Particle *output, int npart, float time) {
for (int i = 0; i < npart; i += BS )
comp_force (BS, time, npart, input, &output[i], i);
}](https://image.slidesharecdn.com/eduardayguadeucm2017-170405041719/75/OpenMP-tasking-model-from-the-standard-to-the-classroom-20-2048.jpg)






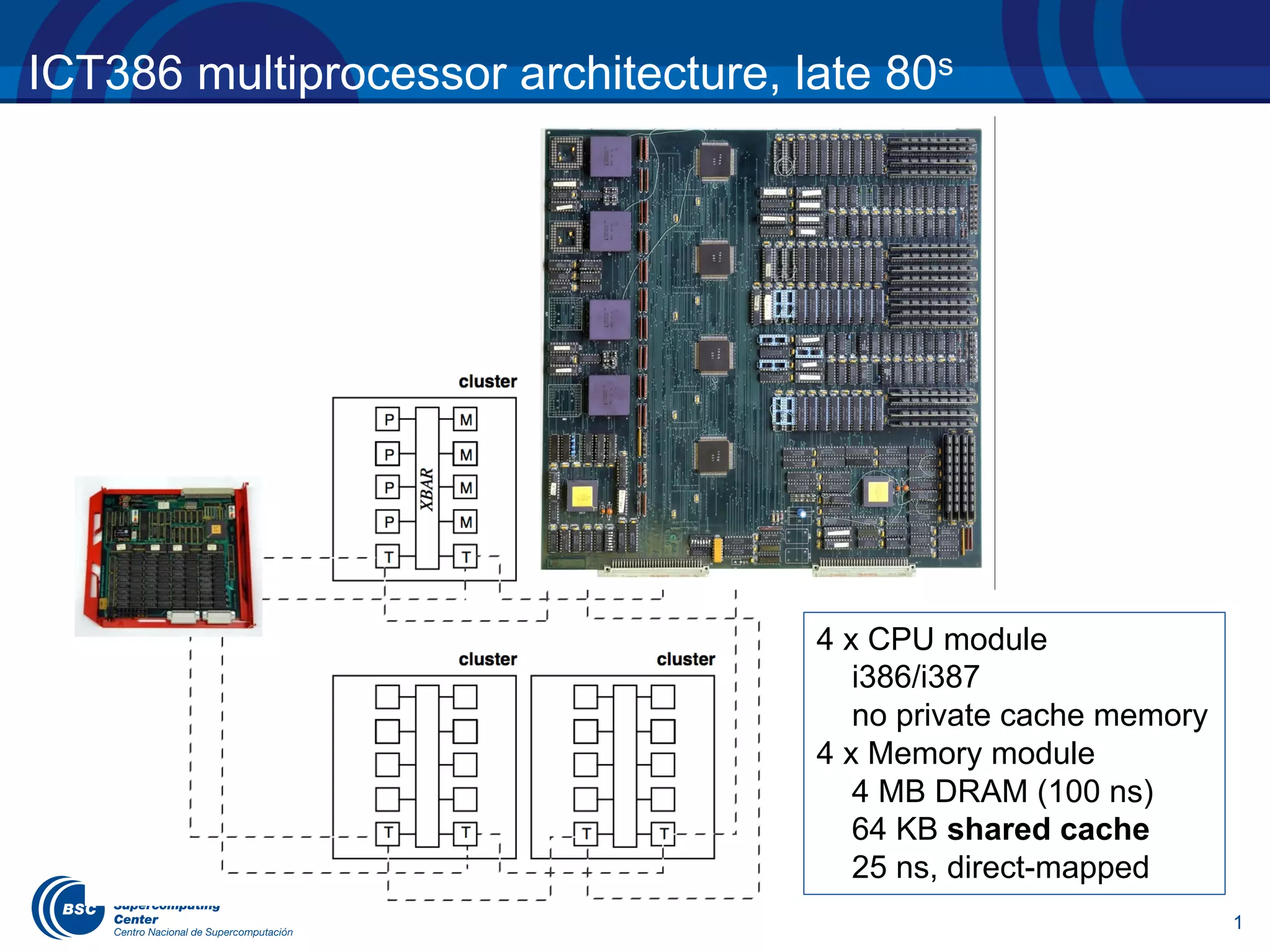
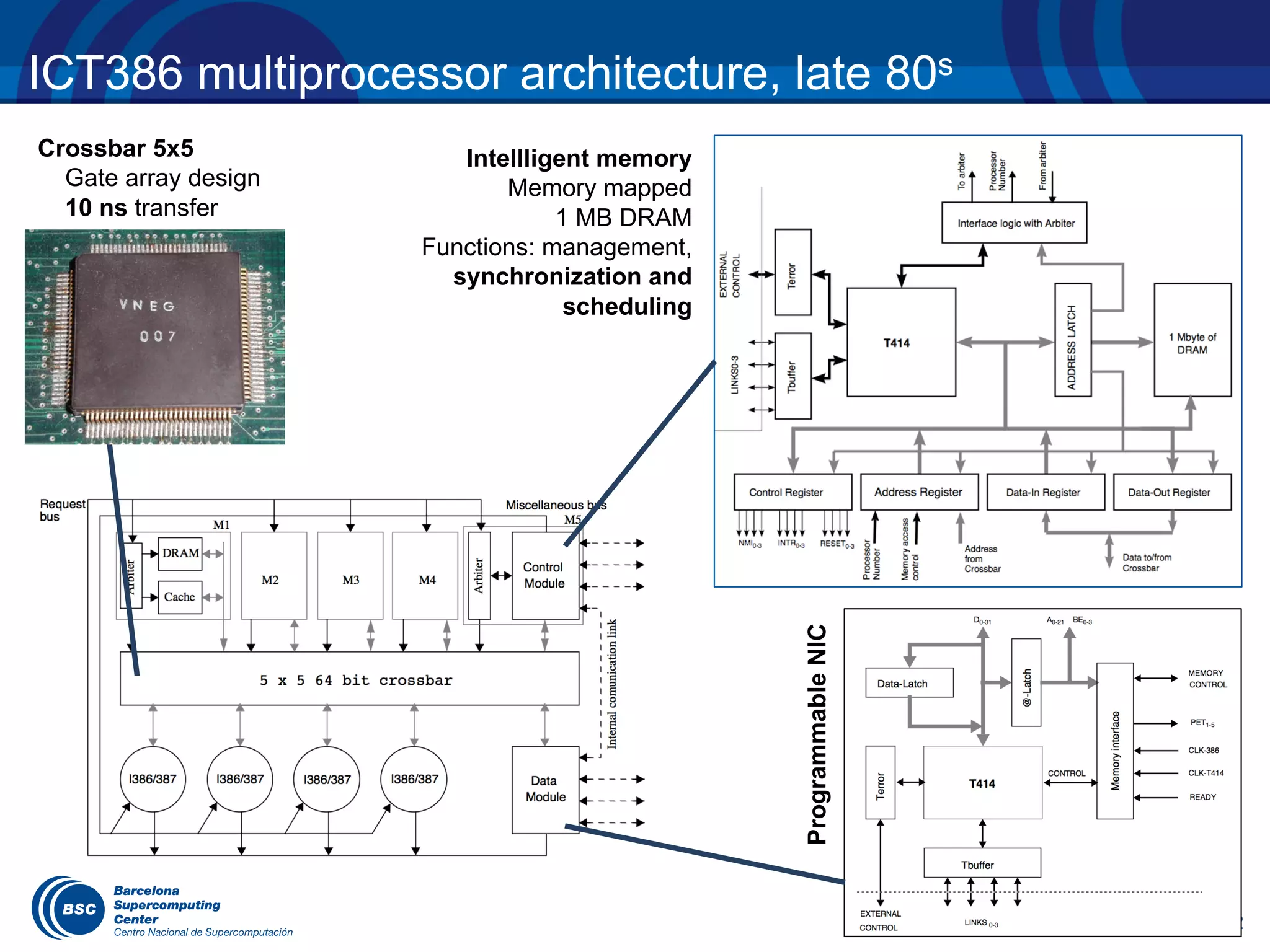
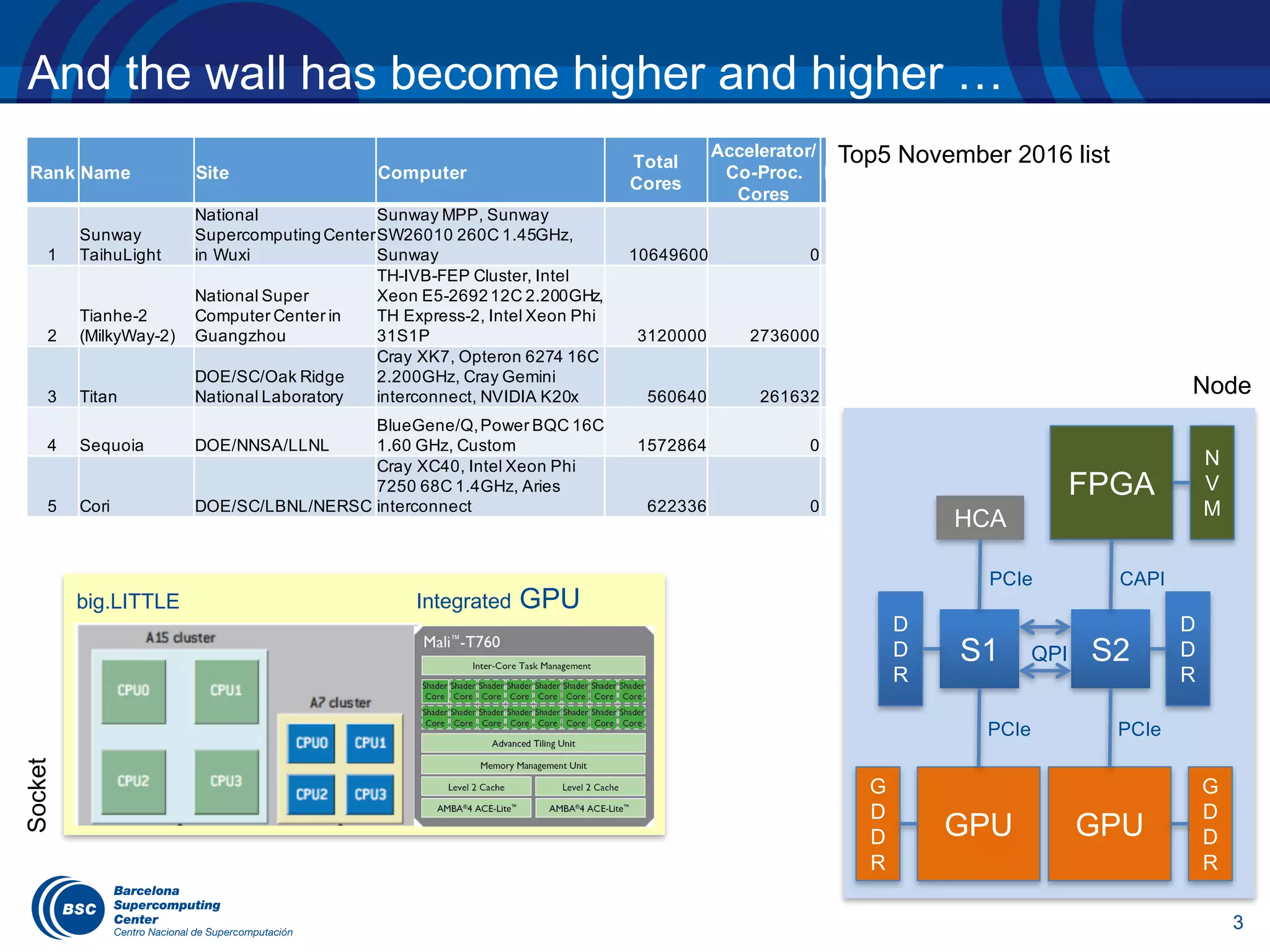
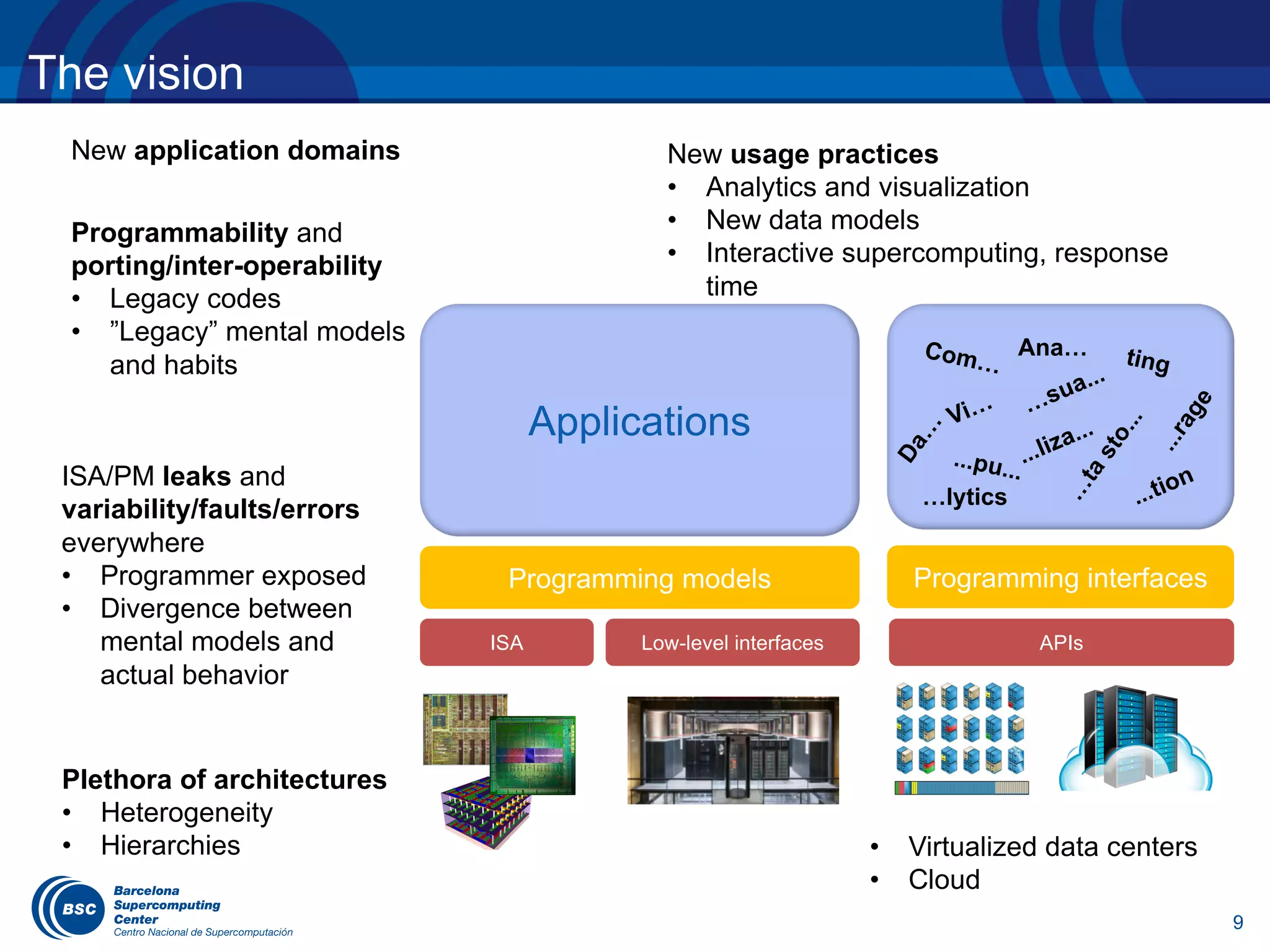
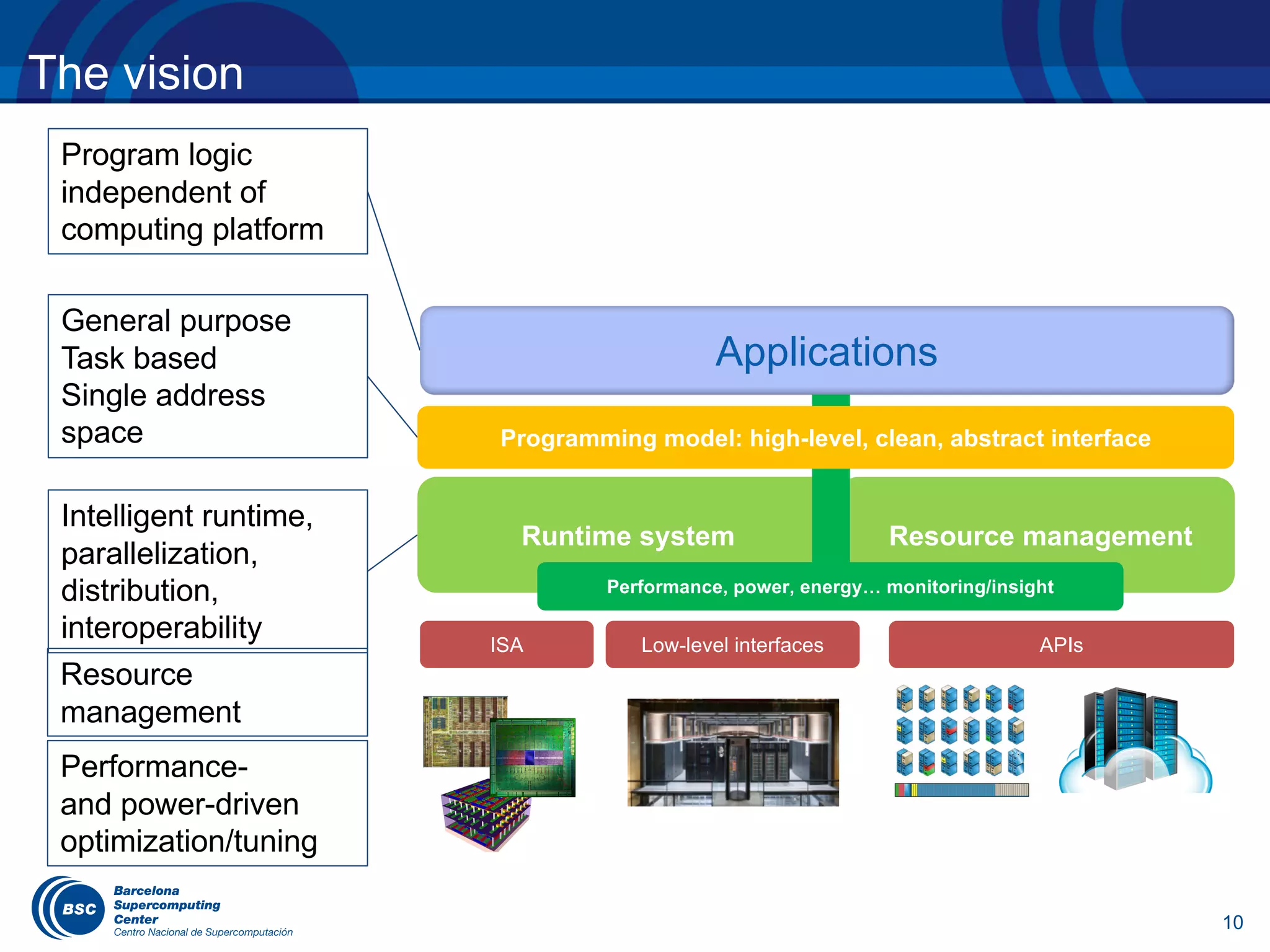
The document discusses the evolution of the OpenMP tasking model, its architecture, and significant computational developments from the late 80s to the present, emphasizing runtime opportunities and educational aspects. It details various high-performance computing architectures, including their specifications, performance metrics, and the influence of OMPSs on task management and parallel programming. Teaching opportunities related to parallelism and architectures in computer science courses are also highlighted.























































































