




![Š *XLGH WR WKH ,663Š %.Š 6HFRQG (GLWLRQ
+DUROG ) 7LSWRQ (GLWRU
,6%1
,62 /HDGHUVKLS (VVHQWLDO 3ULQFLSOHV IRU 6XFFHVV
7RGG )LW]JHUDOG DQG 0LFNL .UDXVH (GLWRUV
,6%1 ;
2I¿FLDO ,6](https://image.slidesharecdn.com/o-cissp-120802024659-phpapp01/85/OOO-5-320.jpg)







![Foreword
Foreword to CBK Study Guide 2009
In today’s connected world, business, government, and consumers all want the ability
to access information, communicate, and execute transactions immediately with
the assurance of real-world security. However, every advance in connectivity and
convenience also brings new threats to privacy and security in the global virtual
environment. That’s why information security has become critical to mitigating
risks that can destroy a company’s reputation, violate a consumer’s privacy, compromise
intellectual property, and, in some cases, endanger lives.
Most organizations now understand that technology alone cannot secure their
data. In ever-increasing numbers, they are seeking seasoned professionals who can
create and implement a comprehensive information security program, obtain sup-
port and funding for the program, and make every employee a security-conscious
citizen, all while meeting necessary regulatory standards.
Educating and certifying the knowledge and experience of information
security professionals has been the mission of the International Information
Systems Security Certification Consortium [(ISC)2] since its inception. Formed
in 1989 by multiple IT associations to develop an accepted industry standard
for the practice of information security, (ISC)2 created the fi rst and only CBK,
a continuously updated compendium of knowledge areas critical to being a pro-
fessional. (ISC)2 has certified security professionals and practitioners in more
than 130 countries across the globe. It is the largest body of information security
professionals in the world.
Information security only continues to grow in size and significance and has
become a business imperative for organizations of all sizes. With the increasing
importance of security, educated, qualified, and experienced information security
professionals are viewed as the answer to an organization’s security challenges.
Responsibilities are increasing as well—information security professionals are
under increasing pressure to secure not only the perimeter of the organization, but
all the data and systems within the organization. Whether researching new tech-
nologies or implementing information risk management initiatives, information
vii
© 2010 by Taylor and Francis Group, LLC](https://image.slidesharecdn.com/o-cissp-120802024659-phpapp01/85/OOO-13-320.jpg)
















































































































































































![Application Security ◾ 169
–d ds:100 11f
B8 19 06 BA CF 03 05 FA-0A 3B 06 02 00 72 1B B4
.........;...r..
09 BA 18 01 CD 21 CD 20–4E 6F 74 20 65 6E 6F 75 .....!. Not
enou
–u ds:100 11f
0AEA:0100 B81906 MOV AX,0619
0AEA:0103 BACF03 MOV DX,03CF
0AEA:0106 05FA0A ADD AX,0AFA
0AEA:0109 3B060200 CMP AX,[0002]
0AEA:010D 721B JB 012A
0AEA:010F B409 MOV AH,09
0AEA:0111 BA1801 MOV DX,0118
0AEA:0114 CD21 INT 21
0AEA:0116 CD20 INT 20
0AEA:0118 4E DEC SI
0AEA:0119 6F DB 6F
0AEA:011A 7420 JZ 013C
0AEA:011C 65 DB 65
0AEA:011D 6E DB 6E
0AEA:011E 6F DB 6F
0AEA:011F 7567 JNZ 0188
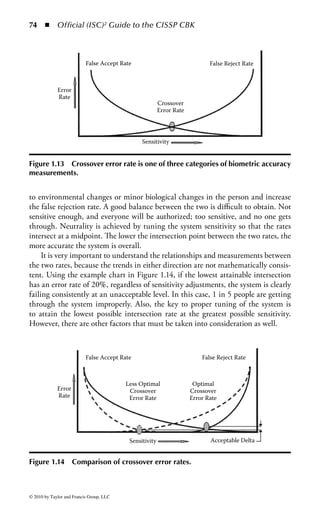
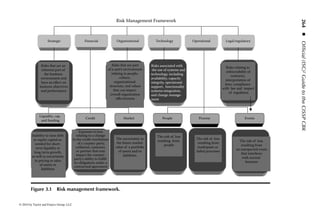
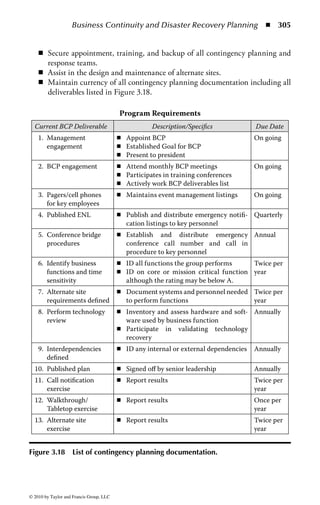
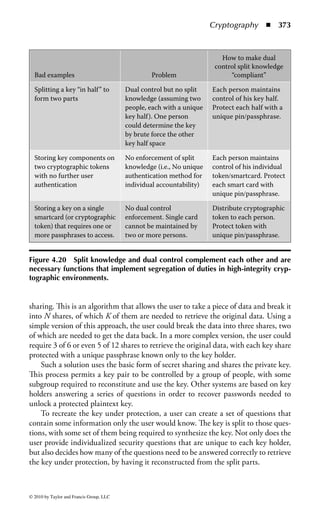
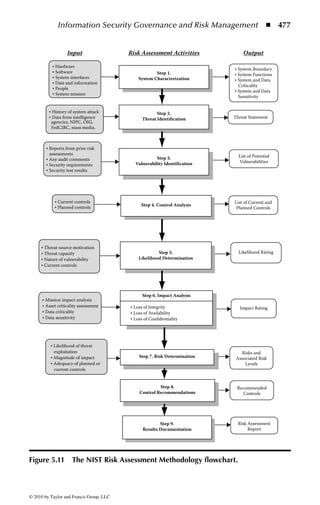
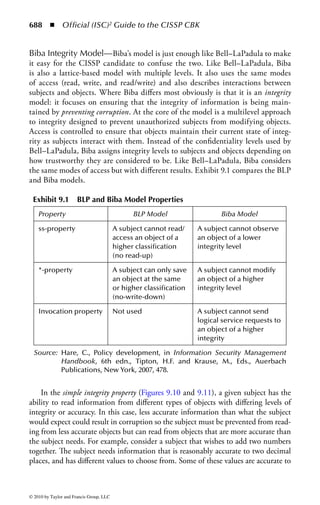
Figure 2.1 Display of the same section of a program file, first as data and then
as an assembly language listing.
numbers. You will notice in the second part of Figure 2.1 a column of codes that
might almost be words: MOV (move), CMP (compare), DEC (decrement), and
ADD. Assembly language added these mnemonics because “MOV to register AX”
makes more sense to a programmer than simply B8h or 10111000. An assembler
program also takes care of details regarding addressing in memory so that every
time a minor change is made to a program, all the memory references and locations
do not have to be manually changed.
© 2010 by Taylor and Francis Group, LLC](https://image.slidesharecdn.com/o-cissp-120802024659-phpapp01/85/OOO-196-320.jpg)















































































































































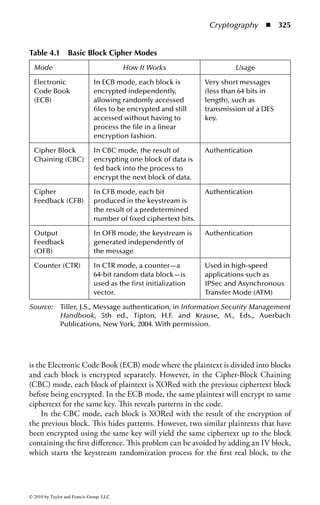













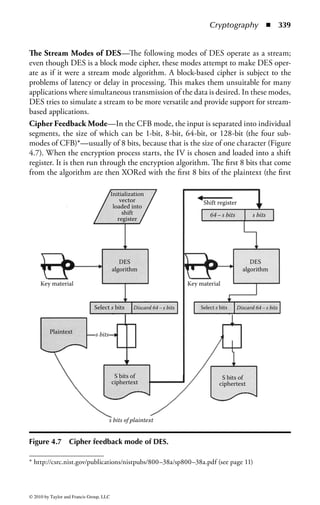
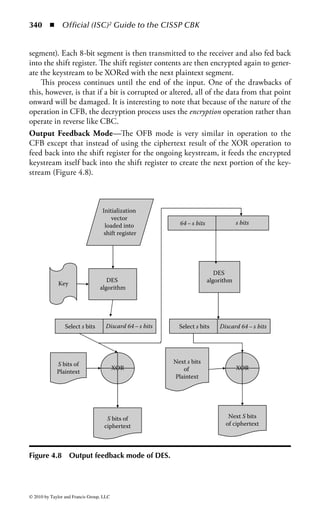



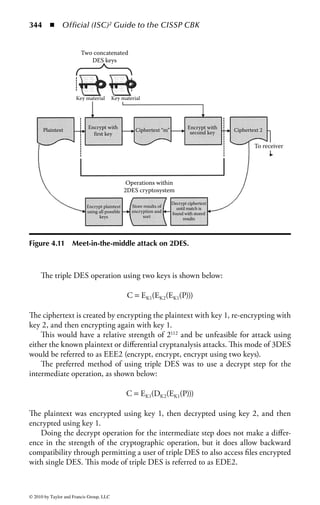


















































































































































































































































































































































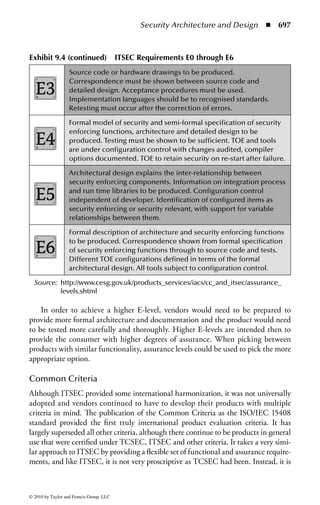








































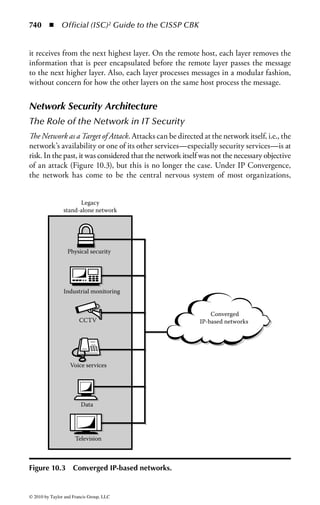









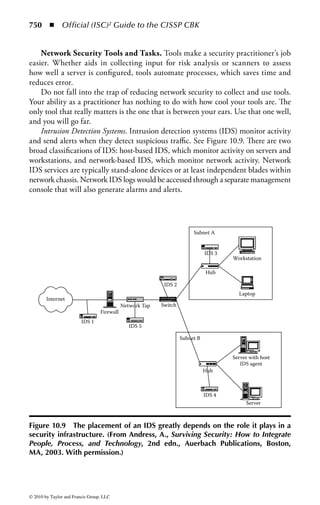





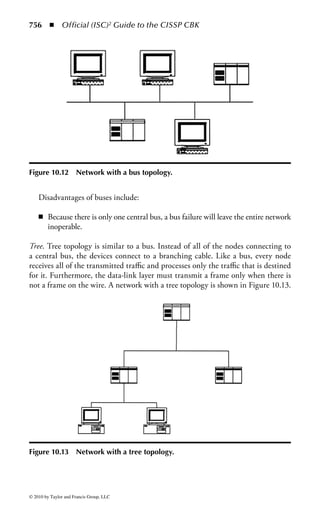



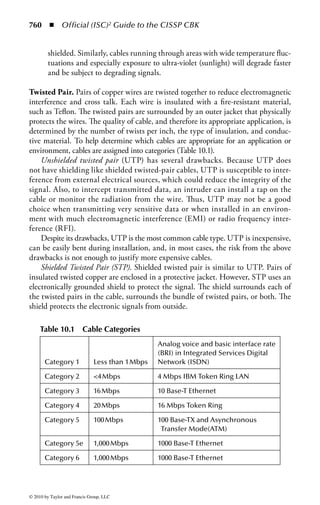





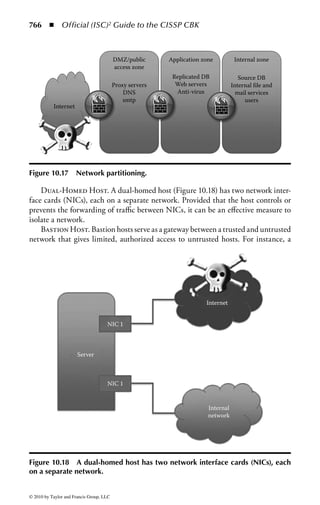








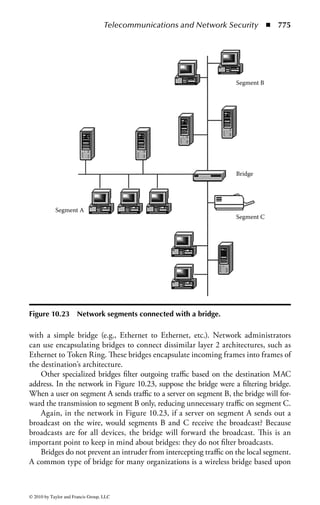















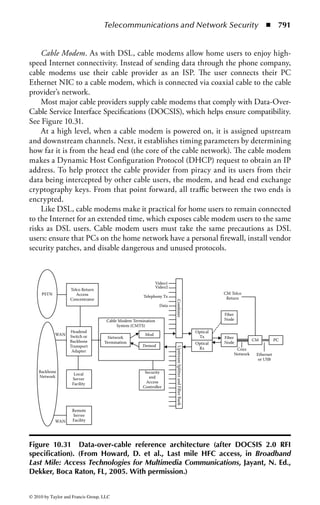
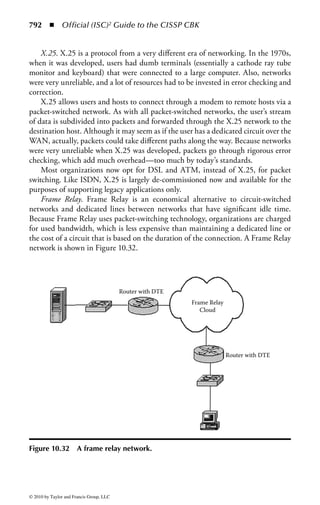












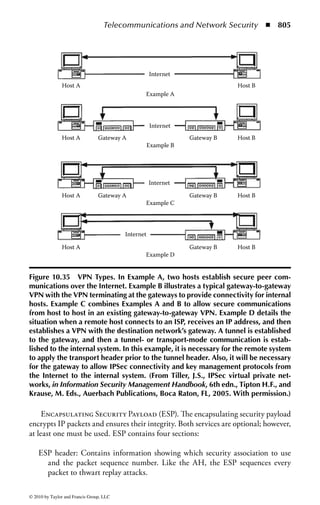






















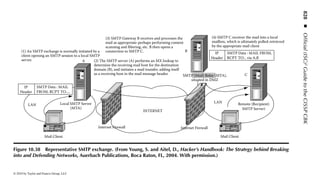





















































































This document is the official guide to the CISSP Common Body of Knowledge (CBK) published by (ISC)2. It contains 10 domains of knowledge needed to obtain the CISSP certification. The second edition was edited by Harold F. Tipton and contains contributions from other security experts. The guide aims to educate information security professionals according to the latest CBK.























































