





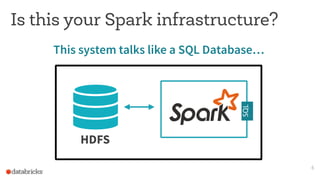
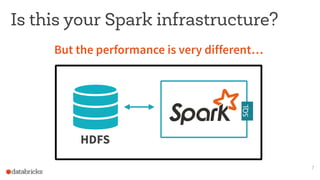
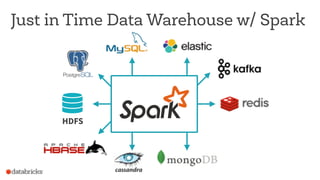















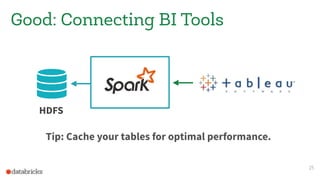
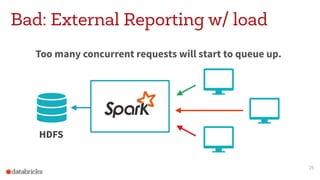
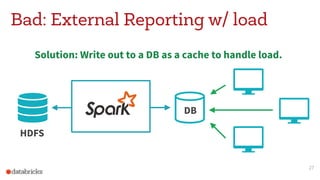










This document discusses appropriate and inappropriate use cases for Apache Spark based on the type of data and workload. It provides examples of good uses, such as batch processing, ETL, and machine learning/data science. It also gives examples of bad uses, such as random access queries, frequent incremental updates, and low latency stream processing. The document recommends using a database instead of Spark for random access, updates, and serving live queries. It suggests using message queues instead of files for low latency stream processing. The goal is to help users understand how to properly leverage Spark for big data workloads.










































































































