Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Yahoo!デベロッパーネットワーク
PDF, PPTX
5,618 views
ネットワークの自動化・監視の取り組みについて #netopscoding #npstudy
NetOpsCoding#5 × ネットワークプログラマビリティ勉強会#13で話してきた。 ネットワークの自動化・監視の取り組みについての発表資料となります。
Technology
◦
Read more
7
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 48
2
/ 48
3
/ 48
4
/ 48
5
/ 48
6
/ 48
7
/ 48
8
/ 48
9
/ 48
10
/ 48
11
/ 48
12
/ 48
13
/ 48
14
/ 48
15
/ 48
16
/ 48
17
/ 48
18
/ 48
19
/ 48
20
/ 48
21
/ 48
22
/ 48
23
/ 48
24
/ 48
25
/ 48
26
/ 48
27
/ 48
28
/ 48
29
/ 48
30
/ 48
31
/ 48
32
/ 48
33
/ 48
34
/ 48
35
/ 48
36
/ 48
37
/ 48
38
/ 48
39
/ 48
40
/ 48
41
/ 48
42
/ 48
43
/ 48
44
/ 48
45
/ 48
46
/ 48
47
/ 48
48
/ 48
More Related Content
PDF
いつやるの?Git入門 v1.1.0
by
Masakazu Matsushita
PDF
なぜディスクレスハイパーバイザに至ったのか / Why did we select to the diskless hypervisor? #builde...
by
whywaita
PDF
ネットワーク ゲームにおけるTCPとUDPの使い分け
by
モノビット エンジン
PDF
目grep入門 +解説
by
murachue
PDF
無料で仮想Junos環境を手元に作ろう
by
akira6592
PDF
大規模サービスを支えるネットワークインフラの全貌
by
LINE Corporation
PDF
Grafana LokiではじめるKubernetesロギングハンズオン(NTT Tech Conference #4 ハンズオン資料)
by
NTT DATA Technology & Innovation
PDF
ロードバランスへの長い道
by
Jun Kato
いつやるの?Git入門 v1.1.0
by
Masakazu Matsushita
なぜディスクレスハイパーバイザに至ったのか / Why did we select to the diskless hypervisor? #builde...
by
whywaita
ネットワーク ゲームにおけるTCPとUDPの使い分け
by
モノビット エンジン
目grep入門 +解説
by
murachue
無料で仮想Junos環境を手元に作ろう
by
akira6592
大規模サービスを支えるネットワークインフラの全貌
by
LINE Corporation
Grafana LokiではじめるKubernetesロギングハンズオン(NTT Tech Conference #4 ハンズオン資料)
by
NTT DATA Technology & Innovation
ロードバランスへの長い道
by
Jun Kato
What's hot
PDF
インターネットの仕組みとISPの構造
by
Taiji Tsuchiya
PDF
知っているようで知らないNeutron -仮想ルータの冗長と分散- - OpenStack最新情報セミナー 2016年3月
by
VirtualTech Japan Inc.
PDF
CyberAgentのインフラについて メディア事業編 #catechchallenge
by
whywaita
PDF
Protocol Buffers 入門
by
Yuichi Ito
PDF
20111015 勉強会 (PCIe / SR-IOV)
by
Kentaro Ebisawa
PDF
Ethernetの受信処理
by
Takuya ASADA
PPTX
FD.io VPP事始め
by
tetsusat
PPTX
コンテナネットワーキング(CNI)最前線
by
Motonori Shindo
PDF
Docker入門-基礎編 いまから始めるDocker管理【2nd Edition】
by
Masahito Zembutsu
PDF
ネットワーク自動化、なに使う? ~自動化ツール紹介~(2017/08/18追加開催)
by
akira6592
PDF
DockerとKubernetesをかけめぐる
by
Kohei Tokunaga
PPTX
分散システムについて語らせてくれ
by
Kumazaki Hiroki
PDF
何となく勉強した気分になれるパーサ入門
by
masayoshi takahashi
PDF
BuildKitの概要と最近の機能
by
Kohei Tokunaga
PPTX
「関心の分離」と「疎結合」 ソフトウェアアーキテクチャのひとかけら
by
Atsushi Nakamura
PDF
テスト文字列に「うんこ」と入れるな
by
Kentaro Matsui
PDF
ネットワークでなぜ遅延が生じるのか
by
Jun Kato
PDF
JavaでCPUを使い倒す! ~Java 9 以降の CPU 最適化を覗いてみる~(NTTデータ テクノロジーカンファレンス 2019 講演資料、2019...
by
NTT DATA Technology & Innovation
PDF
例外設計における大罪
by
Takuto Wada
PDF
MRU : Monobit Reliable UDP ~5G世代のモバイルゲームに最適な通信プロトコルを目指して~
by
モノビット エンジン
インターネットの仕組みとISPの構造
by
Taiji Tsuchiya
知っているようで知らないNeutron -仮想ルータの冗長と分散- - OpenStack最新情報セミナー 2016年3月
by
VirtualTech Japan Inc.
CyberAgentのインフラについて メディア事業編 #catechchallenge
by
whywaita
Protocol Buffers 入門
by
Yuichi Ito
20111015 勉強会 (PCIe / SR-IOV)
by
Kentaro Ebisawa
Ethernetの受信処理
by
Takuya ASADA
FD.io VPP事始め
by
tetsusat
コンテナネットワーキング(CNI)最前線
by
Motonori Shindo
Docker入門-基礎編 いまから始めるDocker管理【2nd Edition】
by
Masahito Zembutsu
ネットワーク自動化、なに使う? ~自動化ツール紹介~(2017/08/18追加開催)
by
akira6592
DockerとKubernetesをかけめぐる
by
Kohei Tokunaga
分散システムについて語らせてくれ
by
Kumazaki Hiroki
何となく勉強した気分になれるパーサ入門
by
masayoshi takahashi
BuildKitの概要と最近の機能
by
Kohei Tokunaga
「関心の分離」と「疎結合」 ソフトウェアアーキテクチャのひとかけら
by
Atsushi Nakamura
テスト文字列に「うんこ」と入れるな
by
Kentaro Matsui
ネットワークでなぜ遅延が生じるのか
by
Jun Kato
JavaでCPUを使い倒す! ~Java 9 以降の CPU 最適化を覗いてみる~(NTTデータ テクノロジーカンファレンス 2019 講演資料、2019...
by
NTT DATA Technology & Innovation
例外設計における大罪
by
Takuto Wada
MRU : Monobit Reliable UDP ~5G世代のモバイルゲームに最適な通信プロトコルを目指して~
by
モノビット エンジン
Viewers also liked
PDF
パケットキャプチャでインフラ主導のデバッグ環境を作る
by
cloretsblack
PDF
NetOpsCoding#5 introduction
by
Taiji Tsuchiya
PPTX
Telemetry事始め
by
npsg
PPTX
Ansible x napalm x nso 解説・比較パネルディスカッション nso
by
Akira Iwamoto
PDF
ネットワーク自動化ツール紹介(Ansible・NAPALM編)
by
akira6592
PDF
生産性を高める 1on1
by
Satoshi Yoshinaga
PDF
[DO02] Jenkins PipelineとBlue Oceanによる、フルスクラッチからの継続的デリバリ
by
de:code 2017
PPTX
ラズパイ2で動く Docker PaaS
by
npsg
PPTX
Apache Spark+Zeppelinでアドホックなネットワーク解析
by
npsg
PPTX
いんふらフレンズ
by
Miho Yamamoto
PDF
API イントロダクション APIC-EM, Prime Infrastructure & CMX
by
npsg
PPTX
CDP Indicator
by
npsg
PPTX
ネットワークプログラマビリティ勉強会 これまでのおさらい
by
npsg
PPTX
ラズパイ2で動く Docker PaaSを作ってみたよ
by
npsg
PPTX
VPP事始め
by
npsg
PDF
Lagopus + DockerのDPDK接続
by
Tomoya Hibi
PPTX
ネットワークプログラマビリティ勉強会
by
Tomoya Hibi
PDF
物理ネットワーク受け入れテストの自動化を考える
by
skipping classes
PDF
自動化と画面を考えてみました
by
skipping classes
PDF
Contiv
by
Shogo Katsurada
パケットキャプチャでインフラ主導のデバッグ環境を作る
by
cloretsblack
NetOpsCoding#5 introduction
by
Taiji Tsuchiya
Telemetry事始め
by
npsg
Ansible x napalm x nso 解説・比較パネルディスカッション nso
by
Akira Iwamoto
ネットワーク自動化ツール紹介(Ansible・NAPALM編)
by
akira6592
生産性を高める 1on1
by
Satoshi Yoshinaga
[DO02] Jenkins PipelineとBlue Oceanによる、フルスクラッチからの継続的デリバリ
by
de:code 2017
ラズパイ2で動く Docker PaaS
by
npsg
Apache Spark+Zeppelinでアドホックなネットワーク解析
by
npsg
いんふらフレンズ
by
Miho Yamamoto
API イントロダクション APIC-EM, Prime Infrastructure & CMX
by
npsg
CDP Indicator
by
npsg
ネットワークプログラマビリティ勉強会 これまでのおさらい
by
npsg
ラズパイ2で動く Docker PaaSを作ってみたよ
by
npsg
VPP事始め
by
npsg
Lagopus + DockerのDPDK接続
by
Tomoya Hibi
ネットワークプログラマビリティ勉強会
by
Tomoya Hibi
物理ネットワーク受け入れテストの自動化を考える
by
skipping classes
自動化と画面を考えてみました
by
skipping classes
Contiv
by
Shogo Katsurada
Similar to ネットワークの自動化・監視の取り組みについて #netopscoding #npstudy
PDF
ヤフーを支えるデータセンタネットワーク
by
Yahoo!デベロッパーネットワーク
PPTX
チケット駆動のサーバ/インフラ運用における問題点と手動作業の自動化
by
Masato Igeta
PDF
Cloud operator days tokyo 2020講演資料_少人数チームでの機械学習製品の効率的な開発と運用
by
Preferred Networks
PDF
ご注文は監視自動化ですか?
by
Masahito Zembutsu
PPTX
YJTC18 A-1 データセンタネットワークの取り組み
by
Yahoo!デベロッパーネットワーク
PDF
チケット駆動のサーバ/インフラ運用における問題点と手動作業の自動化
by
Rakuten Group, Inc.
PDF
弊社IoT事例とAlexaSkil開発レシピ
by
Takashi Kozu
PDF
DevOpsのはじめの一歩 〜監視の変遷〜
by
Akihiro Kuwano
PDF
Serverless Application Security on AWS
by
Amazon Web Services Japan
PDF
CODT2020 ビジネスプラットフォームを支えるCI/CDパイプライン ~エンタープライズのDevOpsを加速させる運用改善Tips~
by
Yuki Ando
PDF
ネットワーク運用自動化お悩み相談会
by
Yuya Rin
PDF
【Interop tokyo 2014】 Cisco SDNの進化とアプリケーションモデル標準化への取り組み
by
シスコシステムズ合同会社
PDF
Yahoo! JAPANのサービス開発を10倍早くした社内PaaS構築の今とこれから
by
Yahoo!デベロッパーネットワーク
PDF
DevSecOps 時代の WafCharm
by
Yuto Ichikawa
PDF
データセンター進化論:SDNは今オープンに ~攻めるITインフラにの絶対条件とは?~
by
Brocade
PDF
今、本当に“オープン”が必要なそのワケ ブロケードが考えるNFVの今、SDNへの未来とは?
by
Brocade
PDF
cloudpack監視・運用保守のなかで生まれた自社開発の取り組みと知見
by
shuichi takahashi
PDF
hb-agent 秘伝のタレからソースコードへ (ITインフラ 業務自動化現状確認会 ) #infra_auto
by
Yuichiro Saito
PDF
【STech I USA】2026.1.28 FYUZ 2025 in Dublin フィードバックウェビナー
by
Sojitz Tech-Innovation USA
PDF
No SSH (@nojima; KMC関東例会)
by
京大 マイコンクラブ
ヤフーを支えるデータセンタネットワーク
by
Yahoo!デベロッパーネットワーク
チケット駆動のサーバ/インフラ運用における問題点と手動作業の自動化
by
Masato Igeta
Cloud operator days tokyo 2020講演資料_少人数チームでの機械学習製品の効率的な開発と運用
by
Preferred Networks
ご注文は監視自動化ですか?
by
Masahito Zembutsu
YJTC18 A-1 データセンタネットワークの取り組み
by
Yahoo!デベロッパーネットワーク
チケット駆動のサーバ/インフラ運用における問題点と手動作業の自動化
by
Rakuten Group, Inc.
弊社IoT事例とAlexaSkil開発レシピ
by
Takashi Kozu
DevOpsのはじめの一歩 〜監視の変遷〜
by
Akihiro Kuwano
Serverless Application Security on AWS
by
Amazon Web Services Japan
CODT2020 ビジネスプラットフォームを支えるCI/CDパイプライン ~エンタープライズのDevOpsを加速させる運用改善Tips~
by
Yuki Ando
ネットワーク運用自動化お悩み相談会
by
Yuya Rin
【Interop tokyo 2014】 Cisco SDNの進化とアプリケーションモデル標準化への取り組み
by
シスコシステムズ合同会社
Yahoo! JAPANのサービス開発を10倍早くした社内PaaS構築の今とこれから
by
Yahoo!デベロッパーネットワーク
DevSecOps 時代の WafCharm
by
Yuto Ichikawa
データセンター進化論:SDNは今オープンに ~攻めるITインフラにの絶対条件とは?~
by
Brocade
今、本当に“オープン”が必要なそのワケ ブロケードが考えるNFVの今、SDNへの未来とは?
by
Brocade
cloudpack監視・運用保守のなかで生まれた自社開発の取り組みと知見
by
shuichi takahashi
hb-agent 秘伝のタレからソースコードへ (ITインフラ 業務自動化現状確認会 ) #infra_auto
by
Yuichiro Saito
【STech I USA】2026.1.28 FYUZ 2025 in Dublin フィードバックウェビナー
by
Sojitz Tech-Innovation USA
No SSH (@nojima; KMC関東例会)
by
京大 マイコンクラブ
More from Yahoo!デベロッパーネットワーク
PDF
ゼロから始める転移学習
by
Yahoo!デベロッパーネットワーク
PDF
継続的なモデルモニタリングを実現するKubernetes Operator
by
Yahoo!デベロッパーネットワーク
PDF
ヤフーでは開発迅速性と品質のバランスをどう取ってるか
by
Yahoo!デベロッパーネットワーク
PDF
オンプレML基盤on Kubernetes パネルディスカッション
by
Yahoo!デベロッパーネットワーク
PDF
LakeTahoe
by
Yahoo!デベロッパーネットワーク
PDF
オンプレML基盤on Kubernetes 〜Yahoo! JAPAN AIPF〜
by
Yahoo!デベロッパーネットワーク
PDF
Persistent-memory-native Database High-availability Feature
by
Yahoo!デベロッパーネットワーク
PDF
データの価値を最大化させるためのデザイン~データビジュアライゼーションの方法~ #devsumi 17-E-2
by
Yahoo!デベロッパーネットワーク
PDF
eコマースと実店舗の相互利益を目指したデザイン #yjtc
by
Yahoo!デベロッパーネットワーク
PDF
ヤフーを支えるセキュリティ ~サイバー攻撃を防ぐエンジニアの仕事とは~ #yjtc
by
Yahoo!デベロッパーネットワーク
PDF
Yahoo! JAPANのIaaSを支えるKubernetesクラスタ、アップデート自動化への挑戦 #yjtc
by
Yahoo!デベロッパーネットワーク
PDF
ビッグデータから人々のムードを捉える #yjtc
by
Yahoo!デベロッパーネットワーク
PDF
サイエンス領域におけるMLOpsの取り組み #yjtc
by
Yahoo!デベロッパーネットワーク
PDF
ヤフーのAIプラットフォーム紹介 ~AIテックカンパニーを支えるデータ基盤~ #yjtc
by
Yahoo!デベロッパーネットワーク
PDF
Yahoo! JAPAN Tech Conference 2022 Day2 Keynote #yjtc
by
Yahoo!デベロッパーネットワーク
PDF
新技術を使った次世代の商品の見せ方 ~ヤフオク!のマルチビュー機能~ #yjtc
by
Yahoo!デベロッパーネットワーク
PDF
PC版Yahoo!メールリニューアル ~サービスのUI/UX統合と改善プロセス~ #yjtc
by
Yahoo!デベロッパーネットワーク
PDF
モブデザインによる多職種チームのコミュニケーション改善 #yjtc
by
Yahoo!デベロッパーネットワーク
PDF
「新しいおうち探し」のためのAIアシスト検索 #yjtc
by
Yahoo!デベロッパーネットワーク
PDF
ユーザーの地域を考慮した検索入力補助機能の改善の試み #yjtc
by
Yahoo!デベロッパーネットワーク
ゼロから始める転移学習
by
Yahoo!デベロッパーネットワーク
継続的なモデルモニタリングを実現するKubernetes Operator
by
Yahoo!デベロッパーネットワーク
ヤフーでは開発迅速性と品質のバランスをどう取ってるか
by
Yahoo!デベロッパーネットワーク
オンプレML基盤on Kubernetes パネルディスカッション
by
Yahoo!デベロッパーネットワーク
LakeTahoe
by
Yahoo!デベロッパーネットワーク
オンプレML基盤on Kubernetes 〜Yahoo! JAPAN AIPF〜
by
Yahoo!デベロッパーネットワーク
Persistent-memory-native Database High-availability Feature
by
Yahoo!デベロッパーネットワーク
データの価値を最大化させるためのデザイン~データビジュアライゼーションの方法~ #devsumi 17-E-2
by
Yahoo!デベロッパーネットワーク
eコマースと実店舗の相互利益を目指したデザイン #yjtc
by
Yahoo!デベロッパーネットワーク
ヤフーを支えるセキュリティ ~サイバー攻撃を防ぐエンジニアの仕事とは~ #yjtc
by
Yahoo!デベロッパーネットワーク
Yahoo! JAPANのIaaSを支えるKubernetesクラスタ、アップデート自動化への挑戦 #yjtc
by
Yahoo!デベロッパーネットワーク
ビッグデータから人々のムードを捉える #yjtc
by
Yahoo!デベロッパーネットワーク
サイエンス領域におけるMLOpsの取り組み #yjtc
by
Yahoo!デベロッパーネットワーク
ヤフーのAIプラットフォーム紹介 ~AIテックカンパニーを支えるデータ基盤~ #yjtc
by
Yahoo!デベロッパーネットワーク
Yahoo! JAPAN Tech Conference 2022 Day2 Keynote #yjtc
by
Yahoo!デベロッパーネットワーク
新技術を使った次世代の商品の見せ方 ~ヤフオク!のマルチビュー機能~ #yjtc
by
Yahoo!デベロッパーネットワーク
PC版Yahoo!メールリニューアル ~サービスのUI/UX統合と改善プロセス~ #yjtc
by
Yahoo!デベロッパーネットワーク
モブデザインによる多職種チームのコミュニケーション改善 #yjtc
by
Yahoo!デベロッパーネットワーク
「新しいおうち探し」のためのAIアシスト検索 #yjtc
by
Yahoo!デベロッパーネットワーク
ユーザーの地域を考慮した検索入力補助機能の改善の試み #yjtc
by
Yahoo!デベロッパーネットワーク
ネットワークの自動化・監視の取り組みについて #netopscoding #npstudy
1.
P オペレーション自動化と監視の取り組み ヤフー株式会社 サイトオペレーション本部 インフラ技術3部 安藤 格也
2.
P自己紹介 安藤 格也(あんどう
かくや) servak 2011年入社 決済チームで開発、運用 2015/10にNWチーム(現職)に異動 2
3.
P目次 オペレーション自動化 ネットワーク監視 3
4.
PP オペレーション自動化 4
5.
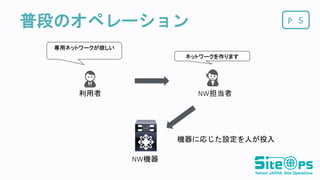
P普段のオペレーション 5 利用者 NW担当者 専用ネットワークが欲しい ネットワークを作ります 機器に応じた設定を人が投入 NW機器
6.
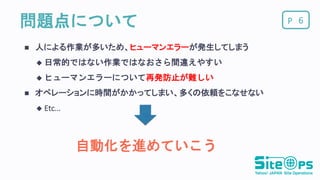
P問題点について 人による作業が多いため、ヒューマンエラーが発生してしまう 日常的ではない作業ではなおさら間違えやすい
ヒューマンエラーについて再発防止が難しい オペレーションに時間がかかってしまい、多くの依頼をこなせない Etc... 6 自動化を進めていこう
7.
P自動化の方針について NW機器とのやりとりはCLI(SSH, TELNET),
SNMP CLIだとプログラムで扱いやすい形(JSON, XMLなど)になっていない SNMPだと取得できる情報が不十分になってしまう 新しい機器、バージョンだとWebAPI、Netconfに対応しているもの もあるが、古い機器でのオペレーションがまだ圧倒的に多い 7 極力構造化されたAPIを利用 出来ないところは努力!
8.
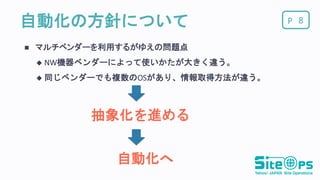
P自動化の方針について マルチベンダーを利用するがゆえの問題点 NW機器ベンダーによって使いかたが大きく違う。
同じベンダーでも複数のOSがあり、情報取得方法が違う。 8 抽象化を進める 自動化へ
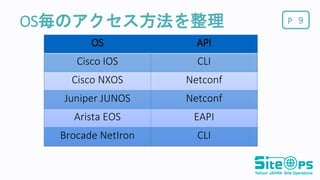
9.
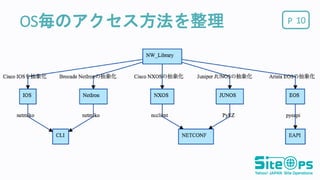
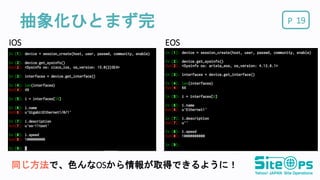
POS毎のアクセス方法を整理 9 OS API Cisco
IOS CLI Cisco NXOS Netconf Juniper JUNOS Netconf Arista EOS EAPI Brocade NetIron CLI
10.
POS毎のアクセス方法を整理 10
11.
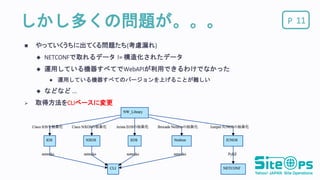
Pしかし多くの問題が。。。 11 やっていくうちに出てくる問題たち(考慮漏れ)
NETCONFで取れるデータ != 構造化されたデータ 運用している機器すべてでWebAPIが利用できるわけでなかった 運用している機器すべてのバージョンを上げることが難しい などなど ... 取得方法をCLIベースに変更
12.
P次のステップへ 12 ログイン時にOSを意識する必要性は無くなった
コマンド、コマンド結果は未だOSを意識する必要が残った => 抽象化は不完全
13.
P共通モデルの定義 取得したい内容を共通モデル化 コマンド結果の定義化
コアとなる考えのみ定義 すべてのOSで扱えるもの 13
14.
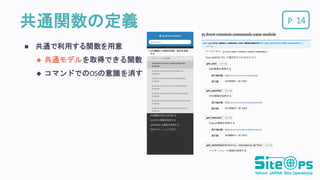
P共通関数の定義 14 共通で利用する関数を用意
共通モデルを取得できる関数 コマンドでのOSの意識を消す
15.
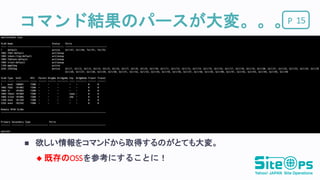
Pコマンド結果のパースが大変。。。 15 欲しい情報をコマンドから取得するのがとても大変。
既存のOSSを参考にすることに!
16.
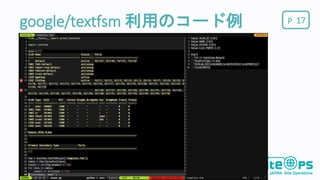
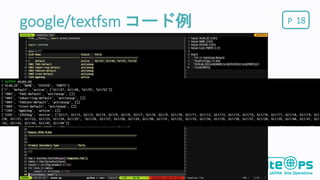
Pgoogle/textfsm 16 CLIの結果を解析するライブラリ
テンプレート(独自DSL)を記載すると簡単にCLIをパース出来る 多くのテンプレート実装が用意されている Networktocode Orgが多くのテンプレートを用意してくれてる https://github.com/networktocode/ntc-templates/tree/master/templates OSSとして公開されている https://github.com/google/textfsm
17.
Pgoogle/textfsm 利用のコード例 17
18.
Pgoogle/textfsm コード例 18
19.
P抽象化ひとまず完 19 IOS EOS 同じ方法で、色んなOSから情報が取得できるように!
20.
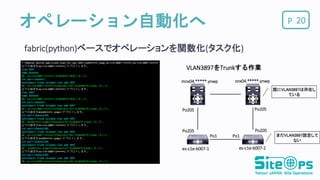
Pオペレーション自動化へ fabric(python)ベースでオペレーションを関数化(タスク化) 20 VLAN3897をTrunkする作業 既にVLAN3897は存在し ている Po1 Po1 Po205Po205 Po205 Po205 まだVLAN3897設定して ない mnx04.*****.ynwp
snx04.*****.ynwp es-c1e-b007-1 es-c1e-b007-2
21.
Pメンテナンスの自動化 メンテナンスで行う内容 トラフィック寄せ(OSPF,
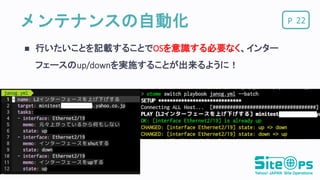
VRRP) インターフェースのダウンアップ YAMLファイルに上記の内容を記載することでその状態にしてくれ るコマンドを作成 設定を流すだけでなく、Before, Afterの状態を確認する YAMLファイルも機器から情報を取得し自動生成 21
22.
Pメンテナンスの自動化 行いたいことを記載することでOSを意識する必要なく、インター フェースのup/downを実施することが出来るように! 22
23.
Pまとめ 抽象化レイヤーの作成を行ったため、オペレーション自動化する 際のコーディングがとても楽に! 抽象化レイヤーのコードカバレッジが90%以上になるほどテストを しっかりしたことも有り、バグがとても少なくなった
ベンダー毎に取り扱っている情報が違うため、すべてに置いて共 通化は出来なかったが重要概念はしっかり共通化できた 23
24.
PP ネットワーク監視 24
25.
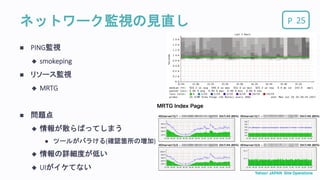
Pネットワーク監視の見直し 25 PING監視
smokeping リソース監視 MRTG 問題点 情報が散らばってしまう ツールがバラける(確認箇所の増加) 情報の詳細度が低い UIがイケてない
26.
Pネットワーク監視でやったこと PING監視 パケットが落ちていないこと
複数拠点から NW機器のリソース監視 トラフィック使用率 トラフィックが溢れていないこと SFP故障によるパケットのドロップ 監視のHA化 26
27.
P利用したツール Prometheus Alertmanager
Grafana 27
28.
PPrometheusとは Pull型(HTTP)のメトリクス監視ツール Inspired
by Google’s Borgmon Alert管理機能を標準装備 Alertを発生させることが出来るし、管理ができる 多彩なService Discoveryに対応 OpenStack, Kubernetes, StaticFile ... 監視対象を自動的に見つけてくれる 公式で様々なメトリクス取得方法を提供 snmp_exporter, blackbox_exporter, node_exporter ... 28
29.
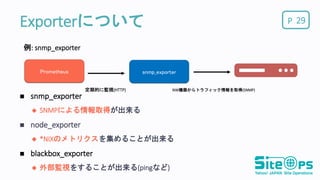
PExporterについて snmp_exporter SNMPによる情報取得が出来る
node_exporter *NIXのメトリクスを集めることが出来る blackbox_exporter 外部監視をすることが出来る(pingなど) 29 Prometheus snmp_exporter 定期的に監視(HTTP) NW機器からトラフィック情報を取得(SNMP) 例: snmp_exporter
30.
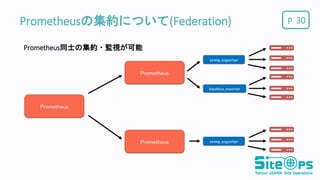
P Prometheus Prometheusの集約について(Federation) 30 Prometheus同士の集約・監視が可能 Prometheus Prometheus snmp_exporter snmp_exporter blackbox_exporter
31.
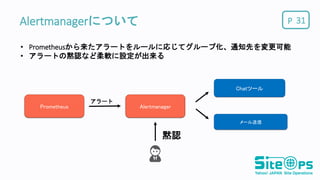
P Prometheus Alertmanagerについて 31 • Prometheusから来たアラートをルールに応じてグループ化、通知先を変更可能 •
アラートの黙認など柔軟に設定が出来る Alertmanager Chatツール メール送信 黙認 アラート
32.
Pネットワーク監視でやったこと PING監視 パケットが落ちていないこと
複数拠点から NW機器のリソース監視 トラフィック使用率 トラフィックが溢れていないこと SFP故障によるパケットのドロップ 監視のHA化 32
33.
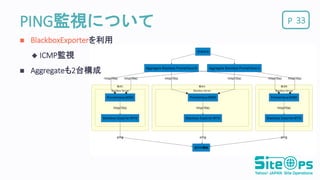
PPING監視について 33 BlackboxExporterを利用
ICMP監視 Aggregateも2台構成
34.
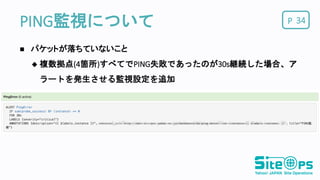
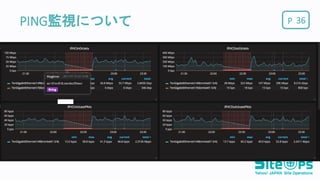
PPING監視について 34 パケットが落ちていないこと
複数拠点(4箇所)すべてでPING失敗であったのが30s継続した場合、ア ラートを発生させる監視設定を追加
35.
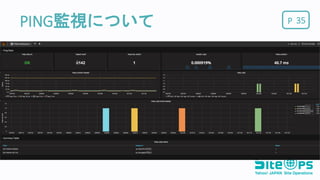
PPING監視について 35
36.
PPING監視について 36
37.
Pネットワーク監視でやったこと PING監視 パケットが落ちていないこと
複数拠点から NW機器のリソース監視 トラフィック使用率 トラフィックが溢れていないこと SFP故障によるパケットのドロップ 監視のHA化 37
38.
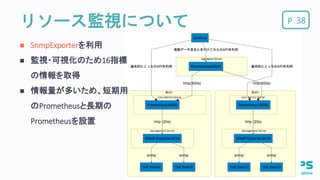
Pリソース監視について 38 SnmpExporterを利用
監視・可視化のため16指標 の情報を取得 情報量が多いため、短期用 のPrometheusと長期の Prometheusを設置
39.
Pリソース監視について 39
40.
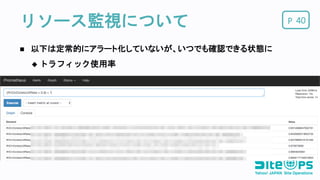
Pリソース監視について 40 以下は定常的にアラート化していないが、いつでも確認できる状態に
トラフィック使用率
41.
Pリソース監視について 41 トラフィック溢れによるパケットのドロップ
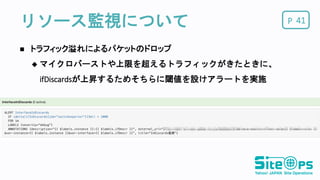
マイクロバーストや上限を超えるトラフィックがきたときに、 ifDiscardsが上昇するためそちらに閾値を設けアラートを実施
42.
Pリソース監視について 42 SFP故障によるパケットのドロップ
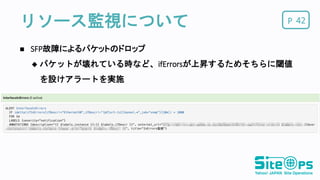
パケットが壊れている時など、ifErrorsが上昇するためそちらに閾値 を設けアラートを実施
43.
Pネットワーク監視でやったこと PING監視 パケットが落ちていないこと
複数拠点から NW機器のリソース監視 トラフィック使用率 トラフィックが溢れていないこと SFP故障によるパケットのドロップ 監視のHA化 43
44.
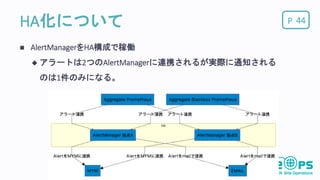
PHA化について 44 AlertManagerをHA構成で稼働
アラートは2つのAlertManagerに連携されるが実際に通知される のは1件のみになる。
45.
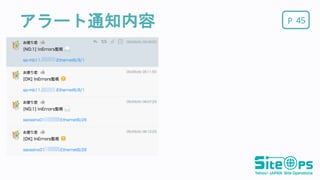
Pアラート通知内容 45
46.
Pまとめ 情報を集約することで、適切なアラートだけ上げることが出来るようになった。 アラートに応じて、条件を細かく指定できることが良かった。
Alertmanagerによりアラートをグループ化することが出来るため、一気にア ラートが来たときもグループでまとまりわかりやすくなった。 46
47.
P今後について 監視ツールとしての信頼性を高めていく まだsmokeping,
MRTGを利用して監視通知を上げている状態でもあるため、 それを完全に切り替えていきたい。 長期データの保持について考えていく 47
48.
P ご清聴ありがとうございました 48
Download
























































![[DO02] Jenkins PipelineとBlue Oceanによる、フルスクラッチからの継続的デリバリ](https://cdn.slidesharecdn.com/ss_thumbnails/do02-170616023407-thumbnail.jpg?width=640&height=640&fit=bounds)




















































