Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Mikiya Okuno
PDF, PPTX
6,345 views
MySQL Cluster 新機能解説 7.5 and beyond
db tech showcase 2017 tokyoで使った資料です。
Software
◦
Read more
3
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 58
2
/ 58
3
/ 58
4
/ 58
5
/ 58
6
/ 58
7
/ 58
8
/ 58
9
/ 58
10
/ 58
11
/ 58
12
/ 58
13
/ 58
14
/ 58
15
/ 58
16
/ 58
17
/ 58
18
/ 58
19
/ 58
20
/ 58
21
/ 58
22
/ 58
23
/ 58
24
/ 58
25
/ 58
26
/ 58
27
/ 58
28
/ 58
29
/ 58
30
/ 58
31
/ 58
32
/ 58
33
/ 58
34
/ 58
35
/ 58
36
/ 58
37
/ 58
38
/ 58
39
/ 58
40
/ 58
41
/ 58
42
/ 58
43
/ 58
44
/ 58
45
/ 58
46
/ 58
47
/ 58
48
/ 58
49
/ 58
50
/ 58
51
/ 58
52
/ 58
53
/ 58
54
/ 58
55
/ 58
56
/ 58
57
/ 58
58
/ 58
More Related Content
PDF
MySQLバックアップの基本
by
yoyamasaki
PDF
MySQL Cluster 解説 & MySQL Cluster 7.3 最新情報
by
yoyamasaki
PDF
Percona ServerをMySQL 5.6と5.7用に作るエンジニアリング(そしてMongoDBのヒント)
by
Colin Charles
PPTX
MySQLの運用でありがちなこと
by
Hiroaki Sano
PDF
[db tech showcase Tokyo 2017] D21: ついに Red Hat Enterprise Linuxで SQL Serverが使...
by
Insight Technology, Inc.
PDF
Yahoo! JAPANのプライベートRDBクラウドとマルチライター型 MySQL #dbts2017 #dbtsOSS
by
Yahoo!デベロッパーネットワーク
PDF
[C21] MySQL Cluster徹底活用術 by Mikiya Okuno
by
Insight Technology, Inc.
PDF
Db tech showcase2015 how to replicate between clusters
by
Hiroaki Kubota
MySQLバックアップの基本
by
yoyamasaki
MySQL Cluster 解説 & MySQL Cluster 7.3 最新情報
by
yoyamasaki
Percona ServerをMySQL 5.6と5.7用に作るエンジニアリング(そしてMongoDBのヒント)
by
Colin Charles
MySQLの運用でありがちなこと
by
Hiroaki Sano
[db tech showcase Tokyo 2017] D21: ついに Red Hat Enterprise Linuxで SQL Serverが使...
by
Insight Technology, Inc.
Yahoo! JAPANのプライベートRDBクラウドとマルチライター型 MySQL #dbts2017 #dbtsOSS
by
Yahoo!デベロッパーネットワーク
[C21] MySQL Cluster徹底活用術 by Mikiya Okuno
by
Insight Technology, Inc.
Db tech showcase2015 how to replicate between clusters
by
Hiroaki Kubota
What's hot
PDF
[db tech showcase Tokyo 2015] A33:Amazon Aurora Deep Dive by アマゾン データ サービス ジャ...
by
Insight Technology, Inc.
PDF
MySQL カジュアル 福岡 03
by
Aya Komuro
PDF
MySQL Cluster 7.4で楽しむスケールアウト @DB Tech Showcase 2015/06
by
Mikiya Okuno
PDF
MySQLのNoSQL機能 - MySQL JSON & HTTP Plugin for MySQL
by
Ryusuke Kajiyama
PDF
MySQL のオンラインバックアップ & リカバリ
by
k_teru
PDF
LINEのMySQL運用について
by
LINE Corporation
PDF
Cassandraとh baseの比較して入門するno sql
by
Yutuki r
PDF
MySQL 初めてのチューニング
by
Craft works
PDF
[db tech showcase Tokyo 2017] E26: 窓は開かれた! SQL Server on Linux で拡がる可能性 by 日本マ...
by
Insight Technology, Inc.
PDF
[db tech showcase Tokyo 2014] C34:[楽天] 詳説 楽天のデータベースアーキテクチャ史 -シングルノードから仮想化フラッシ...
by
Insight Technology, Inc.
PDF
PHP開発者のためのNoSQL入門
by
じゅん なかざ
PPT
20170329 D3 DBAが夜間メンテをしなくなった日 発表資料
by
dcubeio
PDF
データベース技術の羅針盤
by
Yoshinori Matsunobu
PPTX
Persistence on Azure - Microsoft Azure の永続化
by
Takekazu Omi
PDF
MySQLを割と一人で300台管理する技術
by
yoku0825
PPTX
MySQL Clusterを運用して10ヶ月間
by
hiroi10
PDF
PostgreSQL10徹底解説
by
Masahiko Sawada
PDF
スマートフォン×Cassandraによるハイパフォーマンス基盤の構築事例
by
terurou
PDF
Couchbase introduction-20150611
by
Couchbase Japan KK
PDF
S10 日本東西リージョンでのディザスタ リカバリ環境の実現
by
Microsoft Azure Japan
[db tech showcase Tokyo 2015] A33:Amazon Aurora Deep Dive by アマゾン データ サービス ジャ...
by
Insight Technology, Inc.
MySQL カジュアル 福岡 03
by
Aya Komuro
MySQL Cluster 7.4で楽しむスケールアウト @DB Tech Showcase 2015/06
by
Mikiya Okuno
MySQLのNoSQL機能 - MySQL JSON & HTTP Plugin for MySQL
by
Ryusuke Kajiyama
MySQL のオンラインバックアップ & リカバリ
by
k_teru
LINEのMySQL運用について
by
LINE Corporation
Cassandraとh baseの比較して入門するno sql
by
Yutuki r
MySQL 初めてのチューニング
by
Craft works
[db tech showcase Tokyo 2017] E26: 窓は開かれた! SQL Server on Linux で拡がる可能性 by 日本マ...
by
Insight Technology, Inc.
[db tech showcase Tokyo 2014] C34:[楽天] 詳説 楽天のデータベースアーキテクチャ史 -シングルノードから仮想化フラッシ...
by
Insight Technology, Inc.
PHP開発者のためのNoSQL入門
by
じゅん なかざ
20170329 D3 DBAが夜間メンテをしなくなった日 発表資料
by
dcubeio
データベース技術の羅針盤
by
Yoshinori Matsunobu
Persistence on Azure - Microsoft Azure の永続化
by
Takekazu Omi
MySQLを割と一人で300台管理する技術
by
yoku0825
MySQL Clusterを運用して10ヶ月間
by
hiroi10
PostgreSQL10徹底解説
by
Masahiko Sawada
スマートフォン×Cassandraによるハイパフォーマンス基盤の構築事例
by
terurou
Couchbase introduction-20150611
by
Couchbase Japan KK
S10 日本東西リージョンでのディザスタ リカバリ環境の実現
by
Microsoft Azure Japan
Viewers also liked
PDF
カジュアルにMySQL Clusterを使ってみよう@MySQL Cluster Casual Talks 2013.09
by
Mikiya Okuno
PPTX
エフェクト用 Shader 機能紹介
by
Hajime Sanno
PPTX
HttpClient詳解、或いは非同期の落とし穴について
by
Yoshifumi Kawai
PDF
エンジニアがデザインやってみた @ Aimning MeetUp 2017/10
by
Hidenori Doi
PPTX
エフェクトにしっかり色を付ける方法
by
kmasaki
PDF
Binary Reading in C#
by
Yoshifumi Kawai
PDF
【Unite 2017 Tokyo】「黒騎士と白の魔王」にみるC#で統一したサーバー/クライアント開発と現実的なUniRx使いこなし術
by
Unity Technologies Japan K.K.
PDF
ICLR2017読み会 Data Noising as Smoothing in Neural Network Language Models @Dena
by
Takanori Nakai
PDF
言葉のもつ広がりを、モデルの学習に活かそう -one-hot to distribution in language modeling-
by
Takahiro Kubo
PDF
ICLR読み会 奥村純 20170617
by
Jun Okumura
PDF
[ICLR2017読み会 @ DeNA] ICLR2017紹介
by
Takeru Miyato
PDF
Semi-Supervised Classification with Graph Convolutional Networks @ICLR2017読み会
by
Eiji Sekiya
PDF
ZeroFormatterに見るC#で最速のシリアライザを作成する100億の方法
by
Yoshifumi Kawai
PPTX
医療データ解析界隈から見たICLR2017
by
RIKEN, Medical Sciences Innovation Hub Program (MIH)
PDF
170614 iclr reading-public
by
Katsuhiko Ishiguro
PPTX
RuntimeUnitTestToolkit for Unity
by
Yoshifumi Kawai
PDF
NextGen Server/Client Architecture - gRPC + Unity + C#
by
Yoshifumi Kawai
PDF
Q prop
by
Reiji Hatsugai
PDF
「黒騎士と白の魔王」gRPCによるHTTP/2 - API, Streamingの実践
by
Yoshifumi Kawai
PPTX
Deep parking
by
Shintaro Shiba
カジュアルにMySQL Clusterを使ってみよう@MySQL Cluster Casual Talks 2013.09
by
Mikiya Okuno
エフェクト用 Shader 機能紹介
by
Hajime Sanno
HttpClient詳解、或いは非同期の落とし穴について
by
Yoshifumi Kawai
エンジニアがデザインやってみた @ Aimning MeetUp 2017/10
by
Hidenori Doi
エフェクトにしっかり色を付ける方法
by
kmasaki
Binary Reading in C#
by
Yoshifumi Kawai
【Unite 2017 Tokyo】「黒騎士と白の魔王」にみるC#で統一したサーバー/クライアント開発と現実的なUniRx使いこなし術
by
Unity Technologies Japan K.K.
ICLR2017読み会 Data Noising as Smoothing in Neural Network Language Models @Dena
by
Takanori Nakai
言葉のもつ広がりを、モデルの学習に活かそう -one-hot to distribution in language modeling-
by
Takahiro Kubo
ICLR読み会 奥村純 20170617
by
Jun Okumura
[ICLR2017読み会 @ DeNA] ICLR2017紹介
by
Takeru Miyato
Semi-Supervised Classification with Graph Convolutional Networks @ICLR2017読み会
by
Eiji Sekiya
ZeroFormatterに見るC#で最速のシリアライザを作成する100億の方法
by
Yoshifumi Kawai
医療データ解析界隈から見たICLR2017
by
RIKEN, Medical Sciences Innovation Hub Program (MIH)
170614 iclr reading-public
by
Katsuhiko Ishiguro
RuntimeUnitTestToolkit for Unity
by
Yoshifumi Kawai
NextGen Server/Client Architecture - gRPC + Unity + C#
by
Yoshifumi Kawai
Q prop
by
Reiji Hatsugai
「黒騎士と白の魔王」gRPCによるHTTP/2 - API, Streamingの実践
by
Yoshifumi Kawai
Deep parking
by
Shintaro Shiba
Similar to MySQL Cluster 新機能解説 7.5 and beyond
PDF
さいきんのMySQLに関する取り組み(仮)
by
Takanori Sejima
PPTX
20140518 JJUG MySQL Clsuter as NoSQL
by
Ryusuke Kajiyama
PDF
MySQL最新動向と便利ツールMySQL Workbench
by
yoyamasaki
PDF
MySQL Cluster7.3 GAリリース記念セミナー! MySQL & NoSQL 圧倒的な進化を続けるMySQLの最新機能!
by
yoyamasaki
PDF
SQL+NoSQL!? それならMySQL Clusterでしょ。
by
yoyamasaki
PDF
[db tech showcase Tokyo 2015] C17:MySQL Cluster ユーザー事例紹介~JR東日本情報システム様における導入事例...
by
Insight Technology, Inc.
PDF
No sql with mysql cluster (MyNA・JPUG合同DB勉強会)
by
Shinya Sugiyama
PDF
What's New in MySQL 5.7 Replication
by
Mikiya Okuno
PDF
MySQL 5.5 Update #denatech
by
Mikiya Okuno
PDF
Mongo dbを知ろう devlove関西
by
Ryuji Tamagawa
PPTX
LINEのMySQL運用について 修正版
by
LINE Corporation
PDF
What's New in MySQL 5.7 InnoDB
by
Mikiya Okuno
PDF
20150920 中国地方db勉強会
by
yoyamasaki
PDF
5分で作るMySQL Cluster環境
by
yoyamasaki
PDF
5分で作るMySQL Cluster環境
by
yoyamasaki
PDF
MySQL Technology Cafe No3
by
DAISUKE INAGAKI
PDF
Rds徹底入門
by
Junpei Nakada
PDF
20190530 osc hokkaido_public
by
DAISUKE INAGAKI
PDF
[D37]MySQLの真のイノベーションはこれだ!MySQL 5.7と「実験室」 by Ryusuke Kajiyama
by
Insight Technology, Inc.
PDF
Enter the-dolphine
by
Mikiya Okuno
さいきんのMySQLに関する取り組み(仮)
by
Takanori Sejima
20140518 JJUG MySQL Clsuter as NoSQL
by
Ryusuke Kajiyama
MySQL最新動向と便利ツールMySQL Workbench
by
yoyamasaki
MySQL Cluster7.3 GAリリース記念セミナー! MySQL & NoSQL 圧倒的な進化を続けるMySQLの最新機能!
by
yoyamasaki
SQL+NoSQL!? それならMySQL Clusterでしょ。
by
yoyamasaki
[db tech showcase Tokyo 2015] C17:MySQL Cluster ユーザー事例紹介~JR東日本情報システム様における導入事例...
by
Insight Technology, Inc.
No sql with mysql cluster (MyNA・JPUG合同DB勉強会)
by
Shinya Sugiyama
What's New in MySQL 5.7 Replication
by
Mikiya Okuno
MySQL 5.5 Update #denatech
by
Mikiya Okuno
Mongo dbを知ろう devlove関西
by
Ryuji Tamagawa
LINEのMySQL運用について 修正版
by
LINE Corporation
What's New in MySQL 5.7 InnoDB
by
Mikiya Okuno
20150920 中国地方db勉強会
by
yoyamasaki
5分で作るMySQL Cluster環境
by
yoyamasaki
5分で作るMySQL Cluster環境
by
yoyamasaki
MySQL Technology Cafe No3
by
DAISUKE INAGAKI
Rds徹底入門
by
Junpei Nakada
20190530 osc hokkaido_public
by
DAISUKE INAGAKI
[D37]MySQLの真のイノベーションはこれだ!MySQL 5.7と「実験室」 by Ryusuke Kajiyama
by
Insight Technology, Inc.
Enter the-dolphine
by
Mikiya Okuno
More from Mikiya Okuno
PDF
サポート一筋24+年のエンジニア、サポートのイロハは E4500に教わった。 Sun Microsystems 勉強会〜1994年頃から2000年頃の思い...
by
Mikiya Okuno
PDF
MySQL 5.7 トラブルシューティング 性能解析入門編
by
Mikiya Okuno
PDF
私は如何にして詳解 MySQL 5.7を執筆するに至ったか
by
Mikiya Okuno
PDF
リレーショナルデータベースとの上手な付き合い方
by
Mikiya Okuno
PDF
リレーショナルデータベースとの上手な付き合い方 long version
by
Mikiya Okuno
PDF
What's New in MySQL 5.7 Security
by
Mikiya Okuno
PDF
とあるギークのキーボード遍歴
by
Mikiya Okuno
PDF
MySQLアーキテクチャ図解講座
by
Mikiya Okuno
PDF
What's New in MySQL 5.7 Optimizer @MySQL User Conference Tokyo 2015
by
Mikiya Okuno
PDF
なぜ、いま リレーショナルモデルなのか(理論から学ぶデータベース実践入門読書会スペシャル)
by
Mikiya Okuno
PDF
なぜ、いまリレーショナルモデルなのか
by
Mikiya Okuno
PDF
データモデルについて知っておくべき7つのこと 〜NoSQLに手を出す前に〜
by
Mikiya Okuno
PDF
人類は如何にして大切な データベースを守るべきか
by
Mikiya Okuno
PDF
RDBにおけるバリデーションをリレーショナルモデルから考える
by
Mikiya Okuno
PDF
リレーショナルな正しいデータベース設計
by
Mikiya Okuno
PDF
あなたが知らない リレーショナルモデル
by
Mikiya Okuno
PDF
MySQLトラブル解析入門
by
Mikiya Okuno
PDF
データベース設計徹底指南
by
Mikiya Okuno
PDF
Mysql toranomaki
by
Mikiya Okuno
ODP
MySQl 5.6新機能解説@第一回 中国地方DB勉強会
by
Mikiya Okuno
サポート一筋24+年のエンジニア、サポートのイロハは E4500に教わった。 Sun Microsystems 勉強会〜1994年頃から2000年頃の思い...
by
Mikiya Okuno
MySQL 5.7 トラブルシューティング 性能解析入門編
by
Mikiya Okuno
私は如何にして詳解 MySQL 5.7を執筆するに至ったか
by
Mikiya Okuno
リレーショナルデータベースとの上手な付き合い方
by
Mikiya Okuno
リレーショナルデータベースとの上手な付き合い方 long version
by
Mikiya Okuno
What's New in MySQL 5.7 Security
by
Mikiya Okuno
とあるギークのキーボード遍歴
by
Mikiya Okuno
MySQLアーキテクチャ図解講座
by
Mikiya Okuno
What's New in MySQL 5.7 Optimizer @MySQL User Conference Tokyo 2015
by
Mikiya Okuno
なぜ、いま リレーショナルモデルなのか(理論から学ぶデータベース実践入門読書会スペシャル)
by
Mikiya Okuno
なぜ、いまリレーショナルモデルなのか
by
Mikiya Okuno
データモデルについて知っておくべき7つのこと 〜NoSQLに手を出す前に〜
by
Mikiya Okuno
人類は如何にして大切な データベースを守るべきか
by
Mikiya Okuno
RDBにおけるバリデーションをリレーショナルモデルから考える
by
Mikiya Okuno
リレーショナルな正しいデータベース設計
by
Mikiya Okuno
あなたが知らない リレーショナルモデル
by
Mikiya Okuno
MySQLトラブル解析入門
by
Mikiya Okuno
データベース設計徹底指南
by
Mikiya Okuno
Mysql toranomaki
by
Mikiya Okuno
MySQl 5.6新機能解説@第一回 中国地方DB勉強会
by
Mikiya Okuno
MySQL Cluster 新機能解説 7.5 and beyond
1.
MySQL ClusterMySQL Cluster 新機能解説新機能解説 7.5
and beyond7.5 and beyond 奥野 幹也 Twitter: @nippondanji mikiya (dot) okuno (at) gmail (dot) com @DBTS-Tokyo 2017
2.
免責事項 本プレゼンテーションにおいて示されている見解 は、私自身の見解であって、オラクル・コーポ レーションの見解を必ずしも反映したものではあ りません。ご了承ください。
3.
自己紹介 ● MySQL サポートエンジニア – 日々のしごと ●
トラブルシューティング全般 ● Q&A 回答 ● パフォーマンスチューニング など ● ライフワーク – 自由なソフトウェアの普及 – 趣味はリカンベントに乗ること ● 最近は執筆と子育ての日々・・・ ● ブログ – 漢のコンピュータ道 – http://nippondanji.blogspot.com/
4.
MySQL Cluster の ネーミングについて
5.
MySQL “NDB” Cluster ●
マニュアル上での表記が変更 – MySQL Cluster MySQL→ NDB Cluster – https://dev.mysql.com/doc/refman/en/mysql-cluster.html ● MySQL InnoDB Cluster との明確化 ● 製品名としての変更は(今のところ)ナシ – MySQL Cluster Carrier Grade Edition – https://www.mysql.com/products/cluster/ – ややこしや〜 本セッションでは MySQL NDB Cluster に統一
6.
MySQL NDB Cluster 7.5
新機能概要
7.
MySQL NDB Cluster
7.5 新機能概要 ● MySQL 5.7 との統合 ● インデックス統計情報の改良 ● ndbinfo の拡充 ● バックアップレプリカからの参照 ● 全データノードへのレプリカ ● テーブルの容量制限改善 ● ndb_restore コマンドの SQL 出力 2016 年 10 月リリース
8.
MySQL 5.7 との統合
9.
MySQL 5.7 との統合 ● MySQL
サーバーの最新版 – 2015 年 10 月リリース – 175 を超える新機能搭載 ● SQL ノード= NDB ストレージエンジンつき MySQL サー バー – ストレージエンジンを変更するだけで同じ SQL でアクセス 可能 – MySQL NDB Cluster でもメリットの享受が可能 ● MySQL NDB Cluster 7.5 MySQL 5.7→ ● MySQL NDB Cluster 7.3, 7.4 MySQL 5.6→ ● MySQL NDB Cluster 7.2 MySQL 5.5→
10.
MySQL 5.7 の機能 ●
レプリケーション関連 ● InnoDB 関連 ● オプティマイザー関連 ● セキュリティ関連 ● パフォーマンススキーマ関連 ● GIS 関連 ● JSON 関連 ● etc etc...
11.
詳解 MySQL 5.7 止まらぬ進化に乗り遅れないためのテクニカルガイド ● MySQL
5.7 の新機能を網羅的に解説 – 175 の新機能 – WorkLog/Bug Id つき – コンセプト、仕組み、使い方 ● 新機能の理解に必要な前提知識 – 古いバージョンでも適用可能 – アーキテクチャを理解することで 本物の理解を
12.
MySQL 5.7 との 統合による具体的な 改善点
13.
Records-per-key 最適化 ● オプティマイザが JOIN
のときに参照する情報 ● 外部表の 1 行に対して、内部表から平均何行がマッチする か – ストレージエンジンが値を返す – MySQL 5.7 においてデータ型が INT から FLOAT に変更 ● より正確な JOIN のコスト見積が可能に ● MySQL NDB Cluster 7.5 も FLOAT に対応
14.
その他のオプティマイザ関連の 新機能 ● EXPLAIN FOR CONNECTION ● 新しいコストモデル ●
オプティマイザヒント ● ディスクベースのテンポラリテーブルを InnoDB 化 ● UNION ALL がテンポラリテーブル不要に ● コストに WHERE 句による絞り込みを考慮 ● GROUP BY の動作を SQL 標準準拠に ● FROM 句のサブクエリでテンポラリテーブルが不要な場合 作成しないように etc etc
15.
パフォーマンススキーマと sys スキーマ ● パフォーマンス・スキーマ –
種々の統計情報を取得 – 主にパフォーマンス解析に利用 – 情報の種類が多すぎて使いこなすのが難しいのが難点 – バージョンが上がるごとに情報の種類が増加 ● sys スキーマ – パフォーマンス・スキーマと情報スキーマを横断的にアク セスするビューのコレクション – パフォーマンス・スキーマよりも直感的に利用可能 – MySQL 5.7 で追加 ● 元々は独立したプロジェクトだった ● MySQL 5.6 用もあり
16.
MySQL NDB Cluster
とは 無関係の MySQL 5.7 の変更点 ● InnoDB 全般 – SQL ノード上で併用する場合は利点あり – ディスク上のテンポラリテーブルが InnoDB になった点は メリットあり ● レプリケーションのサポートされていない機能 – GTID – 準同期レプリケーション – マルチスレッドスレーブ – マルチソースレプリケーション ● MySQL NDB Cluster には無い機能 – 空間インデックス – フルテキストインデックス
17.
ndbinfo の拡充
18.
ndbinfo とは ● MySQL NDB
Cluster 用の情報取得ツール ● ndbinfo スキーマに各種テーブルがある ● データノードからメタデータや統計情報を取得
19.
MySQL NDB Cluster
7.5 における改良点 ● config_params… パラメーターの説明やデフォルト値、 データ型などが追加 ● config_values… 現在のパラメーターの設定値を格納。 ● dict_obj_info... 各種データベースオブジェクトの情報。 ● table_distribution_status... テーブルの LCP 状況等 ● table_fragments... テーブルごとのフラグメントの状態 ● table_info... テーブルの各種情報 ● table_replicas... レプリカの状態
20.
バックアップレプリカ からの参照
21.
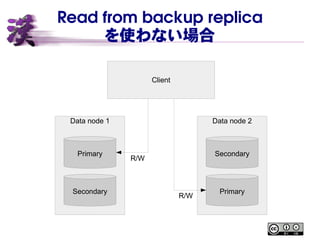
Read from backup
replica ● これまではプライマリーレプリカのみ R/W 可能 ● プライマリーレプリカを各データノードに分散させることで、 負荷も分散 ● MySQL NDB Cluster 7.5 より、バックアップレプリカからの 参照が可能に – ただしデフォルトではこれまで通りプライマリーのみにアク セス可能 – テーブル作成時に指定した場合のみ
22.
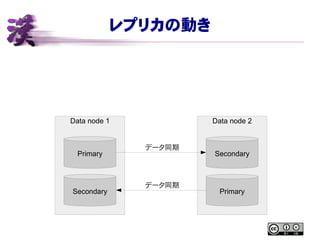
レプリカの動き Data node 1
Data node 2 Primary Secondary Primary Secondary データ同期 データ同期
23.
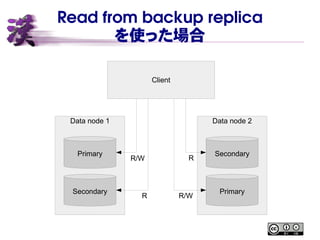
Read from backup
replica を使わない場合 Data node 1 Data node 2 Primary Secondary Primary Secondary Client R/W R/W
24.
Read from backup
replica を使った場合 Data node 1 Data node 2 Primary Secondary Primary Secondary Client R/W R/W R R
25.
全データノードへの レプリカ
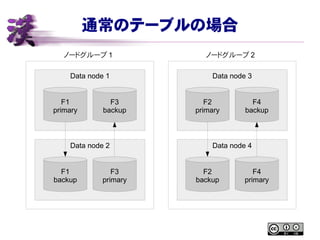
26.
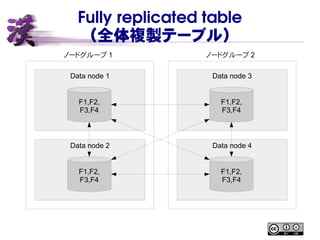
通常のテーブルの場合 ノードグループ 1 ノードグループ
2 Data node 1 Data node 2 Data node 3 Data node 4 F1 primary F3 backup F1 backup F3 primary F2 backup F4 primary F2 primary F4 backup
27.
Fully replicated table (全体複製テーブル) ノードグループ
1 ノードグループ 2 Data node 1 Data node 2 Data node 3 Data node 4 F1,F2, F3,F4 F1,F2, F3,F4 F1,F2, F3,F4 F1,F2, F3,F4
28.
テーブルサイズの 制限の改善
29.
テーブルサイズの制限 ● MySQL NDB Cluster
7.4 まで – FIXED フォーマット部分はフラグメントあたり 16GB まで – フラグメント数はデータノード数と同じ ● MySQL NDB Cluster 7.5 – FIXED フォーマット部分のデータサイズは 128TB まで – ただしデータノードごとの DataMemory の上限が 1TB ● データノードは 48 ノードなので、実質的な上限は 48TB ● レプリカ数2なら 24TB
30.
ndb_restore コマンドの SQL 出力
31.
ndb_restore コマンドの SQL 出力 ● ndb_restore
は、ネイティブバックアップをリストアするツー ル – データノードへクライアントとして接続してリストア – バックアップはメタデータ、データ、ログから構成される – データ部分を CSV で、ログをテキストで出力する機能が あった ● MySQL NDB Cluster 7.5 において、ログの出力が SQL 対 応 – InnoDB など、他のストレージエンジンへのデータ移行に – InnoDB へのレプリケーションのセットアップ
32.
MySQL Cluster 7.6DMR の紹介
33.
MySQL Cluster 7.6
DRM 登場 ● MySQL Cluster 7.6 Development Milestone Release とは? – Release Candidate になる前のバージョン – 機能の追加・削除が予告なく変更される場合有り ● 準備が整った機能から順番に統合される – キャンセルされる場合もあり ● MySQL Cluster 7.6.3 dmr – 2017 年 7 月 5 日リリース ● 正式版ではありません! – https://lists.mysql.com/announce/1185
34.
MySQL NDB Cluster
7.6 の (予定された)新機能概要 ● ディスク型テーブルの新フォーマット ● メモリ割り当て設定の改善 ● ndbinfo の拡充 ● CSV データのインポートツール ● 新しいモニタリングツール ● LCP のスループット安定化 ● SPJ の改良 ● システム名の指定
35.
ディスク型テーブルの 新フォーマット
36.
ディスク型テーブルの 新フォーマット ● ページチェックサムの追加 ● CREATE TABLE
SCHEMA VERSION ID の導入 – DROP/CREATE により、 Table ID が再利用されてしまう – 同じ Table ID を持ったエクステントが CREATE 後のテー ブルのものだと誤って判定されてしまう ● イニシャルローリングリスタートにより新しいフォーマットへ変 更 – 古いフォーマットを持つバージョンにはダウングレードでき ない
37.
メモリ割り当て 設定の改善
38.
IndexMemory の廃止 ● DataMemory から動的に割り当て –
必要な分だけが割り当てられるように – 無駄がない – 設定がちょっとだけシンプルに ● DataMemory だけサイジングすれば OK
39.
DataMemory から SharedGlobalMemory へ ●
メモリ割り当て先の変更 ● DataMemory – データの格納に関する部分に特化 ● SharedGlobalMemory – トランザクション処理に関するメモリはこちらから割り当て – 以前より多く必要になるかも ● 変更されたものの例 – レプリケーション用イベントバッファ – ファイルの初期化処理用バッファ – オフラインのインデックス作成用バッファ etc storage/ndb/src/kernel/blocks/record_types.hpp
40.
ndbinfo の拡充
41.
ndbinfo に2つのテーブルが追加 ● config_nodes – config.ini
内で定義されたノードの一覧 ● processes – 現在接続中のプロセス(ノード)一覧 ndb_mgm -e SHOW の代わりに使うと便利
42.
CSV データの インポートツール ndb_import
43.
ndb_import ● LOAD DATA INFILE
のように CSV データをテーブルに取 り込むツール ● データノードへ直接接続 – 高速! – API ノードのひとつとして動作 – データノードへの接続数、接続あたりのスレッド数を指定 可能 ndb_import -c connectstring db_name table_name.csv
44.
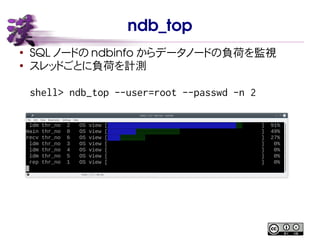
モニタリングツール ndb_top
45.
ndb_top ● SQL ノードの ndbinfo
からデータノードの負荷を監視 ● スレッドごとに負荷を計測 shell> ndb_top --user=root --passwd -n 2
46.
LCP のスループット 安定化
47.
LCP とは ● Local checkpoint
の略 ● データノードは定期的に DataMemory 上のデータを、ファ イルへ書き出している – 全体を順次スキャン – 2 世代分のデータがファイルに保存 – かなりの I/O が発生する ● GCP ( Global checkpoint )とセットでデータを復元 – GCP = Redo logging
48.
LCP のスループット安定化 ● LCP は
I/O が遅いと自動的にスループットを調整する機能 がある ● 7.5 までのバージョンでは、 LDM スレッドごとに I/O 遅延を モニタリングし、スループットを調整していた – 他の LDM スレッドはスループットを調整しないかも知れ ない – LDM = Local Data Manager ● 7.6 では I/O 遅延のモニタリングをデータノード全体で統一 して行うようになった – より正確にサーバー全体の I/O の状況を反映するように なった。
49.
SPJ の改良
50.
SPJ とは ● Select-Project-Join の略 –
別名 Pushdown Join ● データノード上で JOIN を実行し、結果を SQL ノードへ返す – 非常に高速! – データノード・ SQL ノード間のラウンドトリップを省略 – 複数のデータノード上で JOIN を並列実行
51.
Pushdown Join が効率化 ● DBSPJ
カーネルブロックのシグナル周りの改良 – 余分なシグナルが送信されないように – シグナルフォーマットをコンパクトに ● ロードバランスの改善 – LDM スレッド数が、 TC スレッド数で割り切れない場 合、 DBSPJ の負荷に偏りが生じていた – その場合、 DBSPJ ブロックをラウンドロビンで使うようにす ることで、スレッドごとの負荷を平坦化
52.
システム名の 指定が可能に
53.
システム名とは ● クラスタを識別するためのタグのようなもの ● config.ini
内で指定 [System] Name = system_name ● SHOW GLOBAL STATUS LIKE ‘Ndb_system_name’ で 参照
54.
まとめ
55.
MySQL “NDB” Cluster
は 着々と進化中!! ● MySQL NDB Cluster 7.5 、 7.6DMR で着実な進化 – 派手な変更は無いが、役立つ新機能が多数 ● 機能面 – MySQL 5.7 との統合により充実 – ndb_top 、 ndb_import などの新しいツール ● 性能面 – オプティマイザの改善により、 SQL 実行が高速化 – LCP スループットの安定 – バックアップレプリカらからの参照 – DBSPJ の改良 ● 運用面 – ndbinfo による監視の充実 – システム名による識別
56.
宣伝:書籍が出ます! Pro MySQL NDB
Cluster ● Pro MySQL NDB Cluster / Apress Media – MySQL NDB Cluster 7.5 の解説書 – 同僚の Jesper との共著 – 英語です。 – お値段は $49.99
57.
Q&Aご静聴ありがとうございました。
58.
宣伝:サポートエンジニア募集中!! ● MySQL サポートチームで一緒に働いてみませんか?! ● 技術力が物を言うポジションです! – 技術力に自信のある方、技術を磨きたい方歓迎 –
L1 から L3 までの問い合わせをすべて受け持ち ● クエリのチューニングなども行います ● オープンソースなのでソースコード見放題!! – 英語より技術力重視 ● 普段の業務は日本語オンリーです。 ● 日本の顧客がターゲットです。 ● 上司は海外 – やりとりは英語のみ – TOEIC 700 程度が目安 ● 在宅勤務可能
Download
















































![システム名とは
● クラスタを識別するためのタグのようなもの
● config.ini 内で指定
[System]
Name = system_name
●
SHOW GLOBAL STATUS LIKE ‘Ndb_system_name’ で
参照](https://image.slidesharecdn.com/mysql-cluster-75-and-beyond-170907022234/85/MySQL-Cluster-7-5-and-beyond-53-320.jpg)









![[db tech showcase Tokyo 2017] D21: ついに Red Hat Enterprise Linuxで SQL Serverが使...](https://cdn.slidesharecdn.com/ss_thumbnails/d21-170912022444-thumbnail.jpg?width=640&height=640&fit=bounds)

![[C21] MySQL Cluster徹底活用術 by Mikiya Okuno](https://cdn.slidesharecdn.com/ss_thumbnails/c21mysql-cluster-techniques-rev3-131206023325-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

![[db tech showcase Tokyo 2015] A33:Amazon Aurora Deep Dive by アマゾン データ サービス ジャ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015a34amazon-auroraamazondataservicejapan-150623010528-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)







![[db tech showcase Tokyo 2017] E26: 窓は開かれた! SQL Server on Linux で拡がる可能性 by 日本マ...](https://cdn.slidesharecdn.com/ss_thumbnails/e26-170912024421-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2014] C34:[楽天] 詳説 楽天のデータベースアーキテクチャ史 -シングルノードから仮想化フラッシ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtstokyo2014c34hardware-141211191008-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)




















![[ICLR2017読み会 @ DeNA] ICLR2017紹介](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2017denaiclr2017-170616173153-thumbnail.jpg?width=640&height=640&fit=bounds)














![[db tech showcase Tokyo 2015] C17:MySQL Cluster ユーザー事例紹介~JR東日本情報システム様における導入事例...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015c17mysql-clusterhp-150619091220-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)












![[D37]MySQLの真のイノベーションはこれだ!MySQL 5.7と「実験室」 by Ryusuke Kajiyama](https://cdn.slidesharecdn.com/ss_thumbnails/20131115dbtechshowcasemysql57-131119201938-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)




















