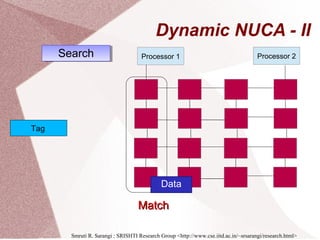
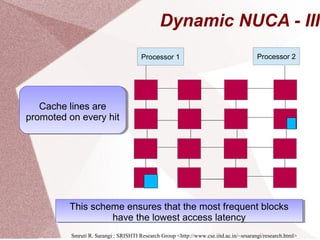
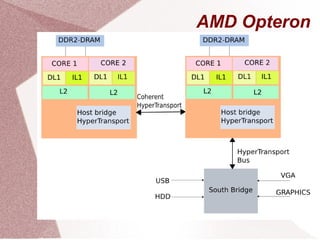
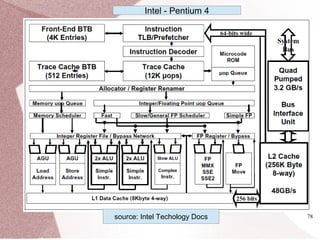
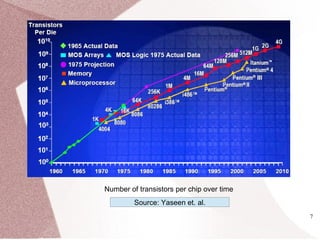
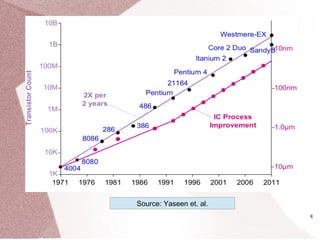
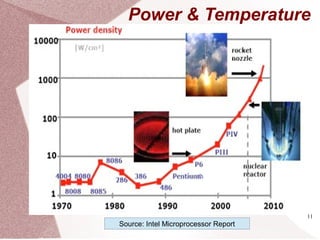
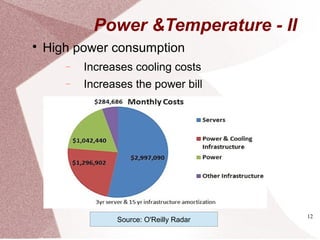
The document discusses multicore processors, including their architecture, design, examples, and challenges. It covers Moore's Law, the advantages and issues of multicore processors, and the importance of parallel programming and cache coherence. Additionally, it outlines memory consistency models and introduces concepts related to multiprocessor design and cache organization.













![20
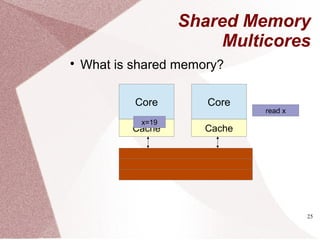
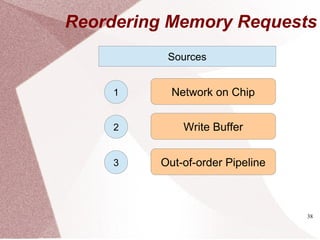
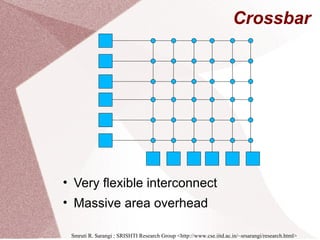
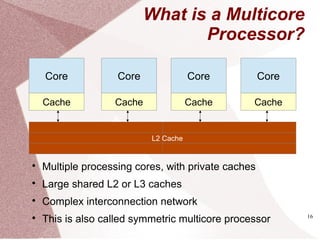
Parallel Programs
for (i=0;i<n;i++)
c[i] = a[i] * b[i]
parallel_for(i=0;i<n;i++)
c[i] = a[i] * b[i]
SequentialSequential ParallelParallel
What if ???
parallel_for(i=0;i<n;i++)
c[d[i]] = a[i] * b[i]
Is the loop still parallel?](https://image.slidesharecdn.com/multicore-procs-170123112849/85/Multicore-Processors-20-320.jpg)

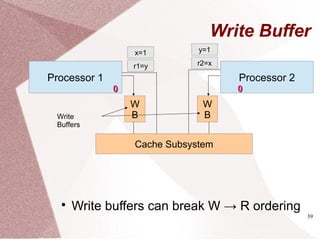
![22
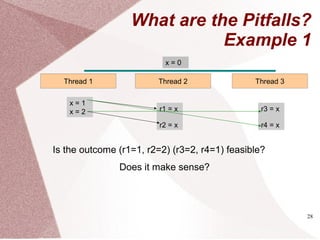
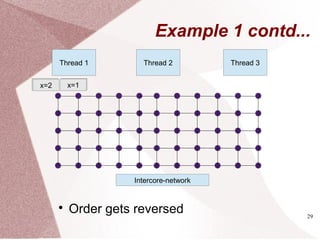
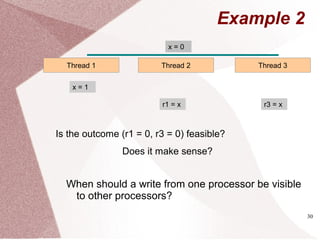
Finding Parallelism- II
Discovering parallelism: manually
− Write explicitly parallel algorithms
− Restructure loops
for (i=0;i<n-1;i++)
a[i] = a[i] * a[i+1]
a_copy = copy(a)
parallel_for(i=0;i<n-1;i++)
a[i] = a_copy[i] *
a_copy[i+1]
SequentialSequential ParallelParallel
Example](https://image.slidesharecdn.com/multicore-procs-170123112849/85/Multicore-Processors-22-320.jpg)