Download to read offline




![
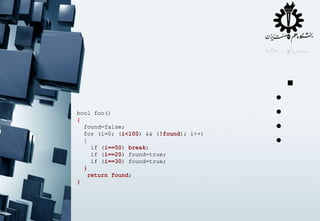
int *a = new ….
.
.
.
If (a>22)
(a>2)
(a[0] >22)
fail();
else
.
.
.
•
•
•
•
](https://image.slidesharecdn.com/thesis-presentation-131128061605-phpapp02/85/Master-Thesis-presentation-4-320.jpg)





















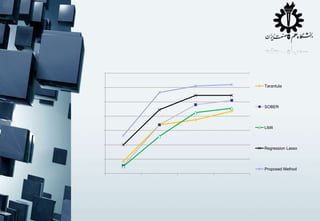



The document contains fragmented code snippets and mathematical expressions related to programming logic, algorithm implementation, and statistical measures. It discusses the behavior of functions, likelihood computations, and performance metrics for text-based modeling techniques such as unigrams, bigrams, and trigrams. Additionally, there are references to error testing methodologies and regression analysis in the context of algorithm evaluation.












































































