Download to read offline




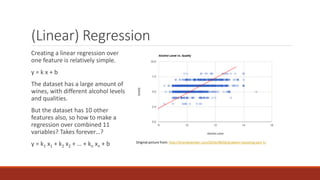
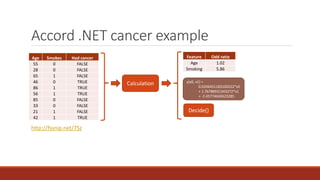



The document discusses applying machine learning techniques using Accord.NET with the wine quality dataset to estimate wine quality based on various features. It explains the process of dividing the dataset into training and evaluation sets, as well as the use of linear regression and decision trees for modeling. Additionally, it addresses potential challenges such as parameter mismatches when applying models to wines from different regions.


























































