Download as PDF, PPTX

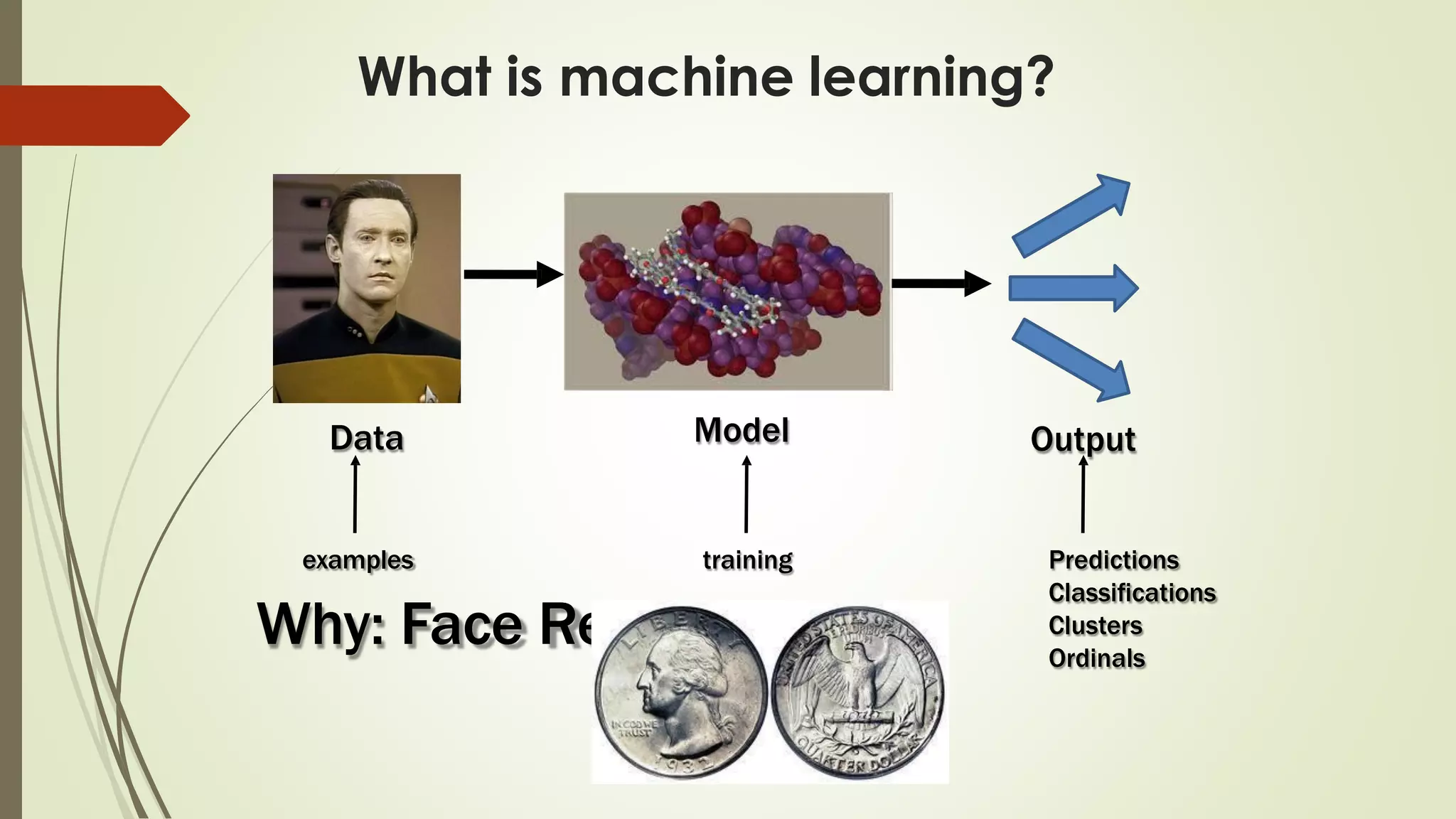
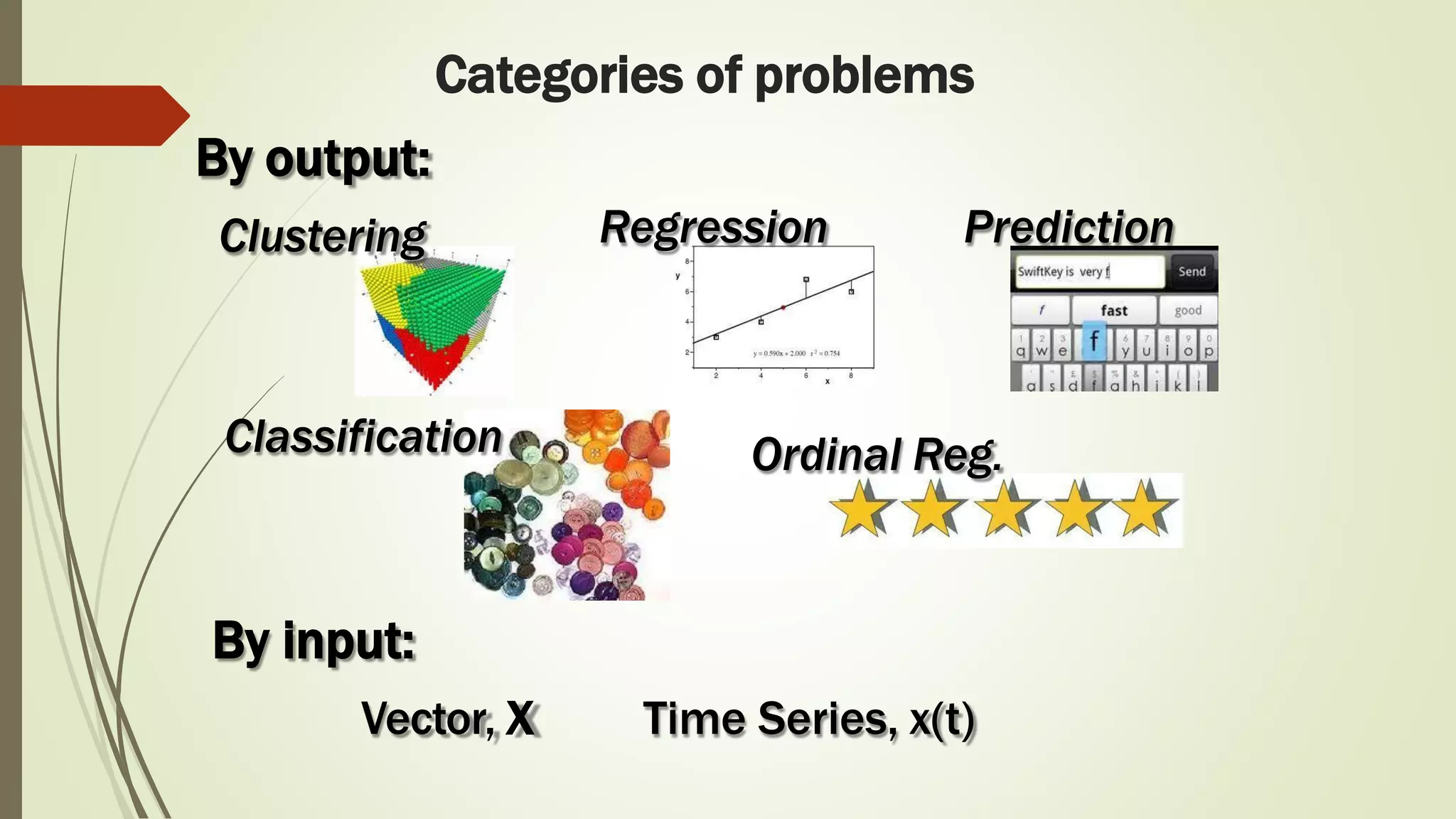

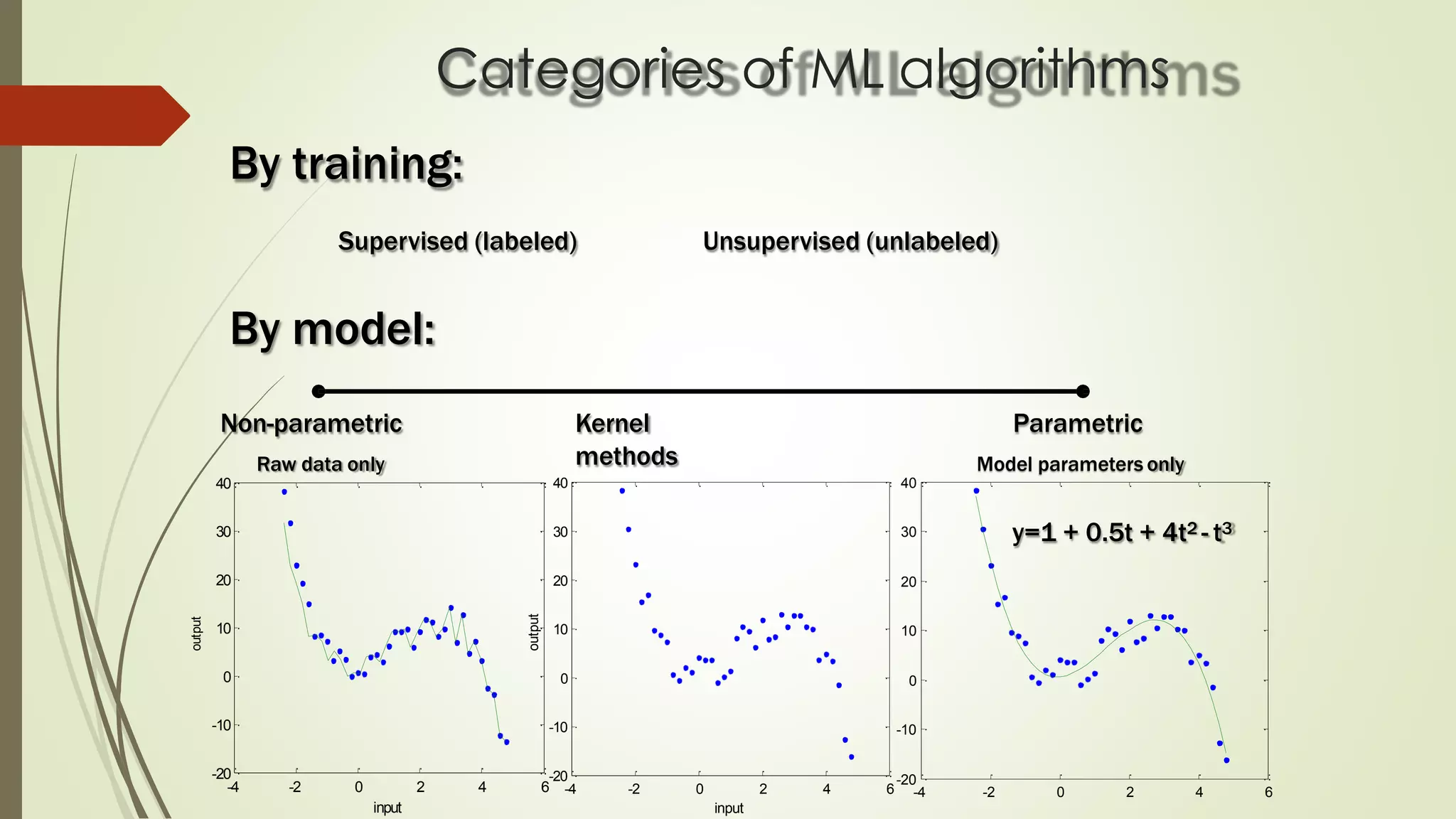
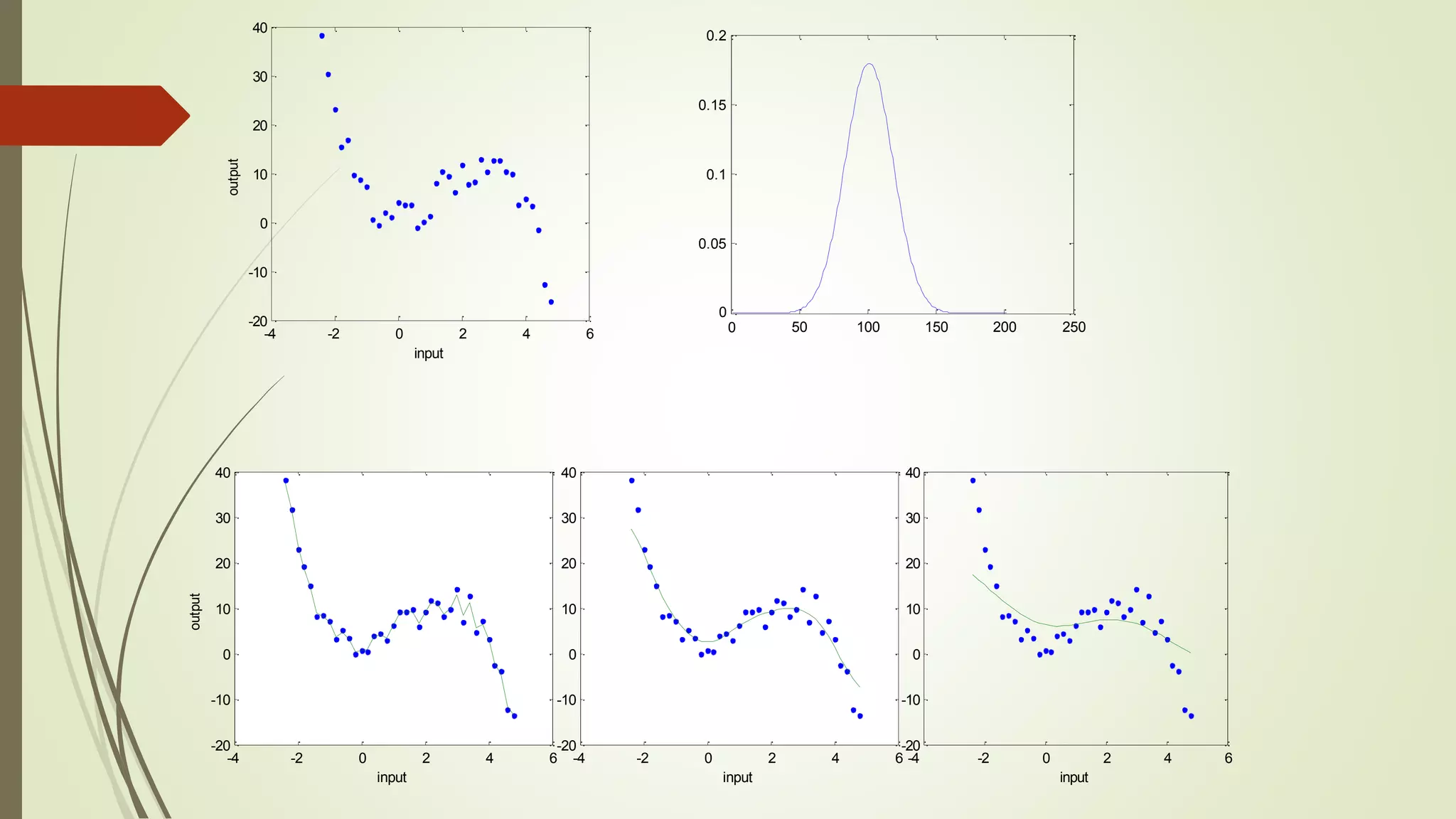
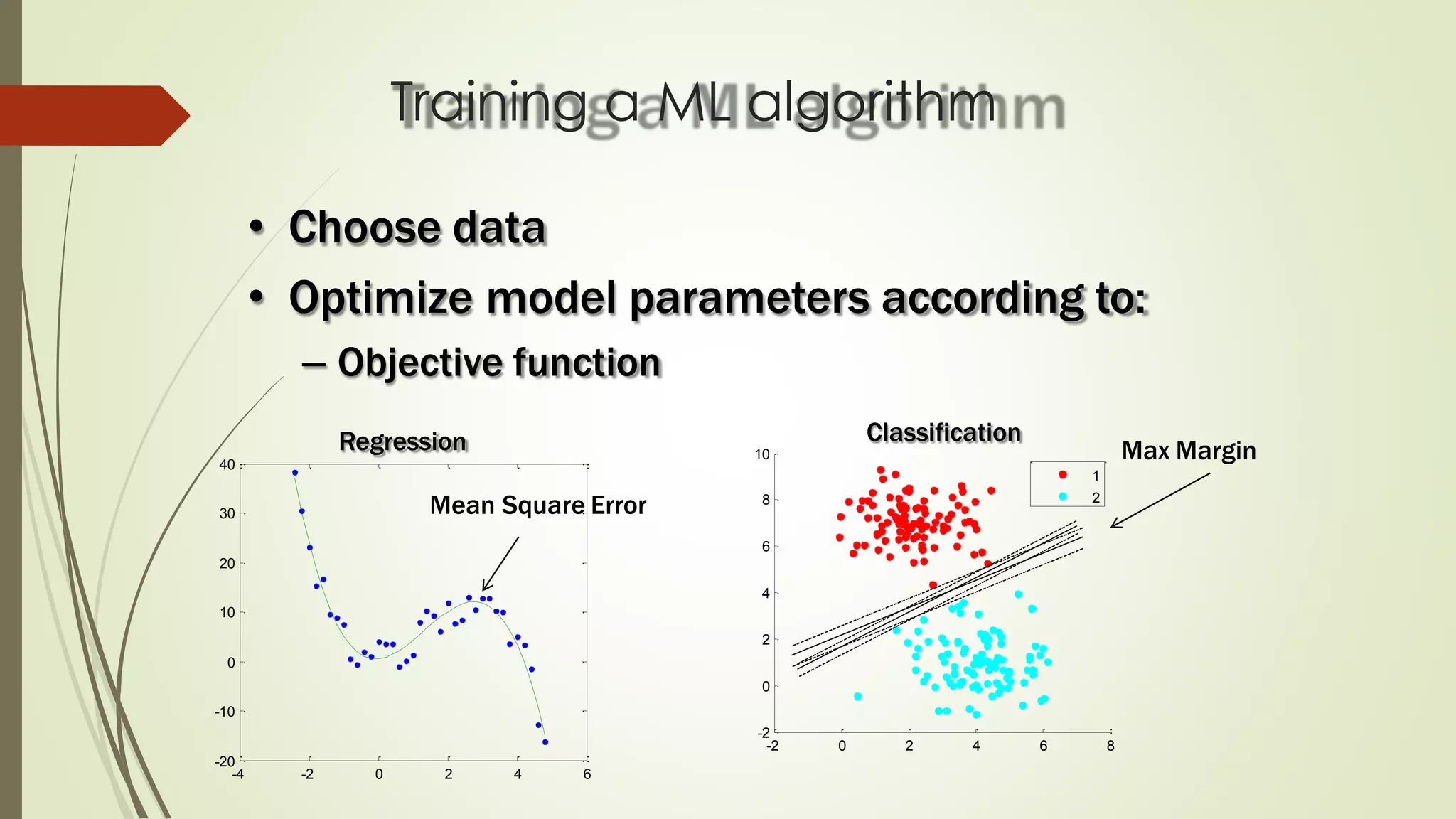

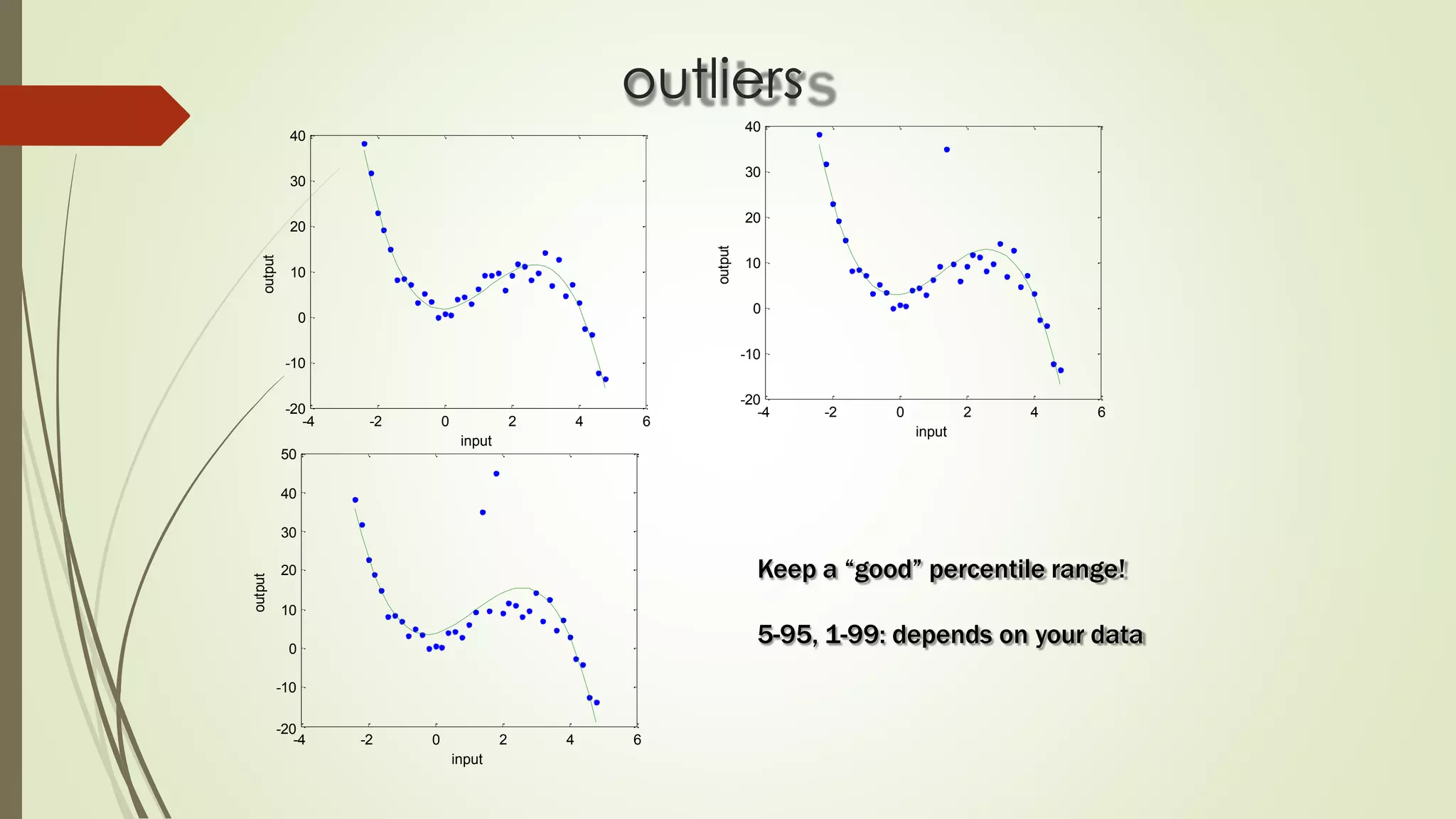
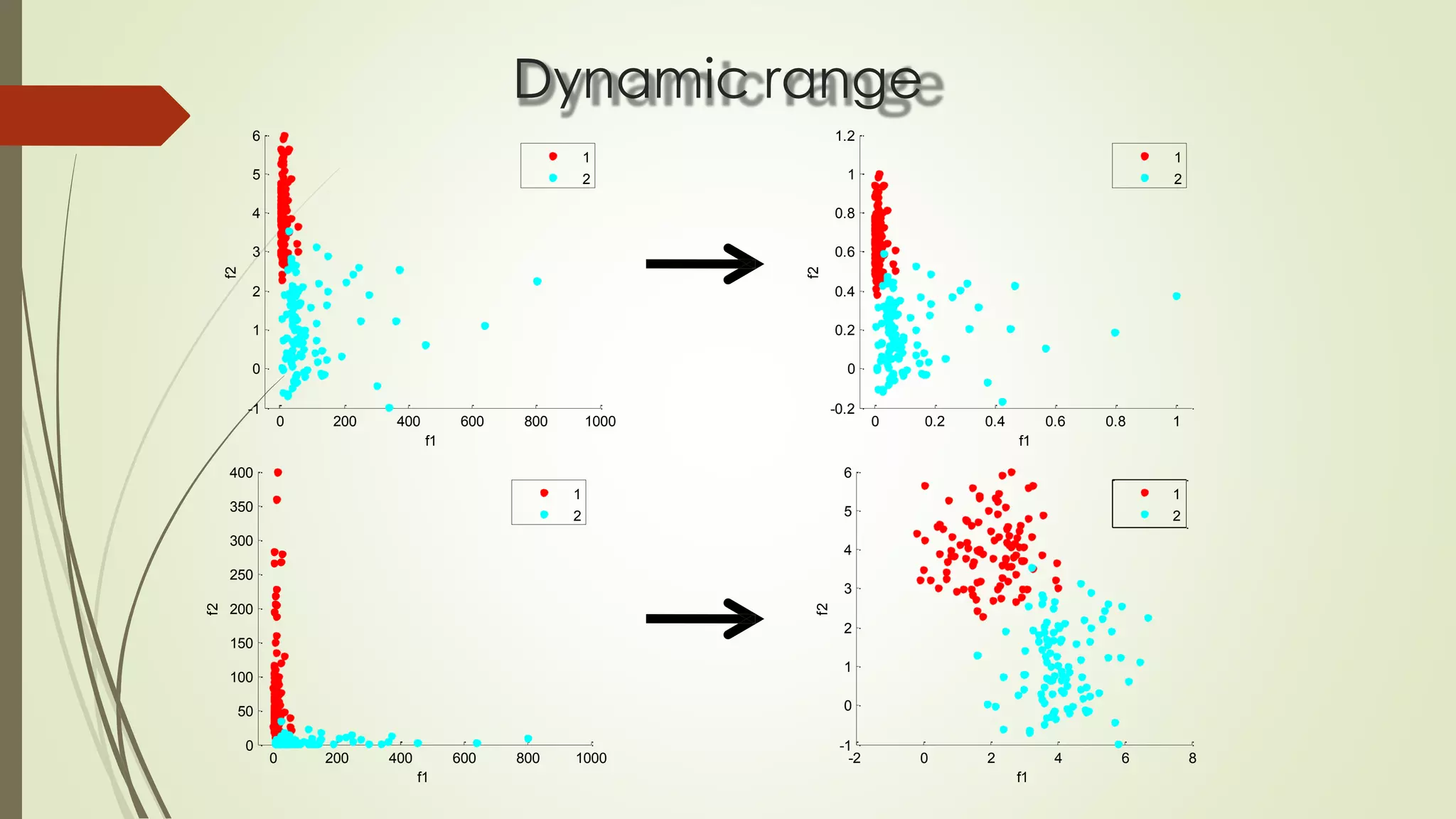
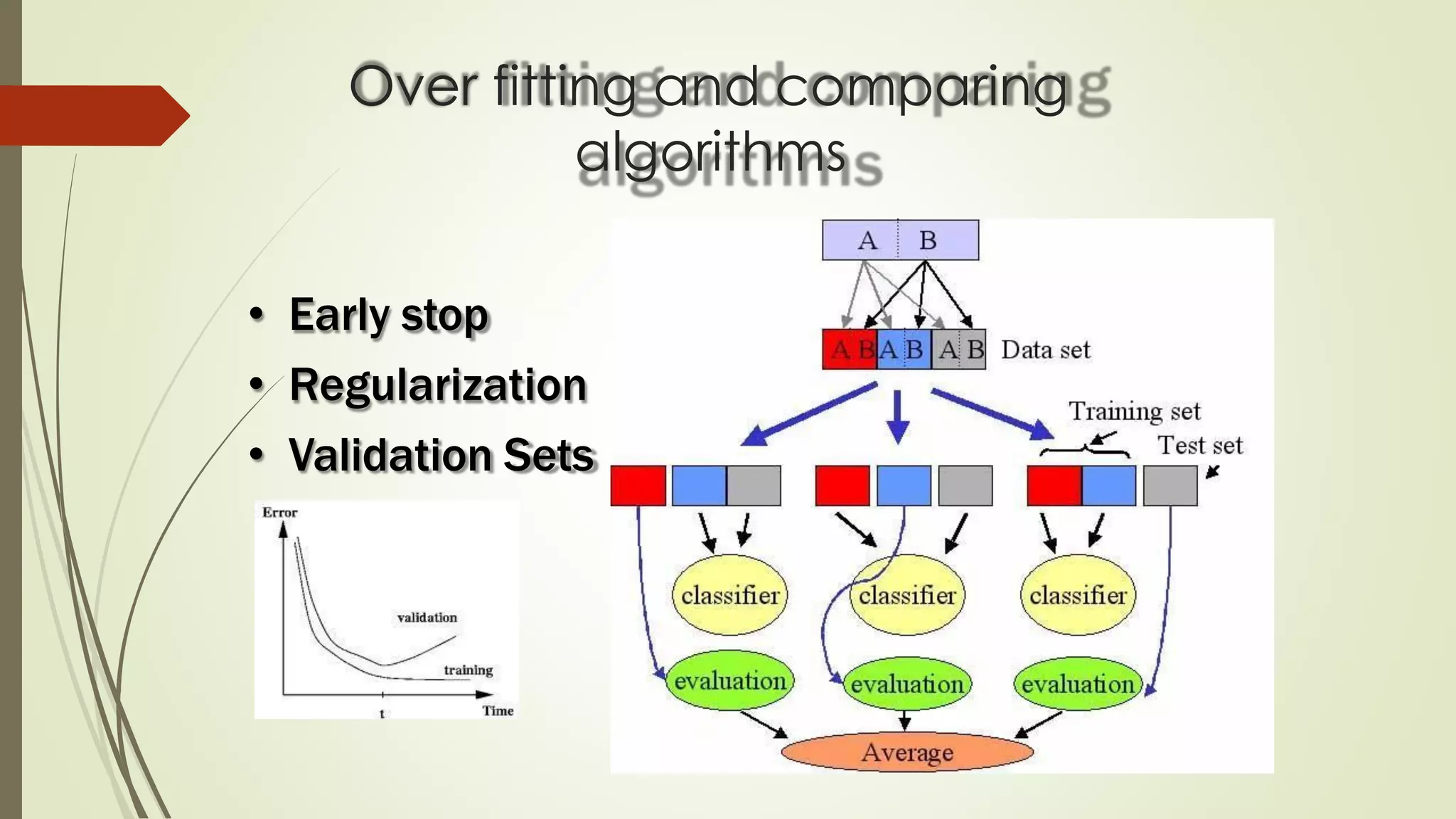

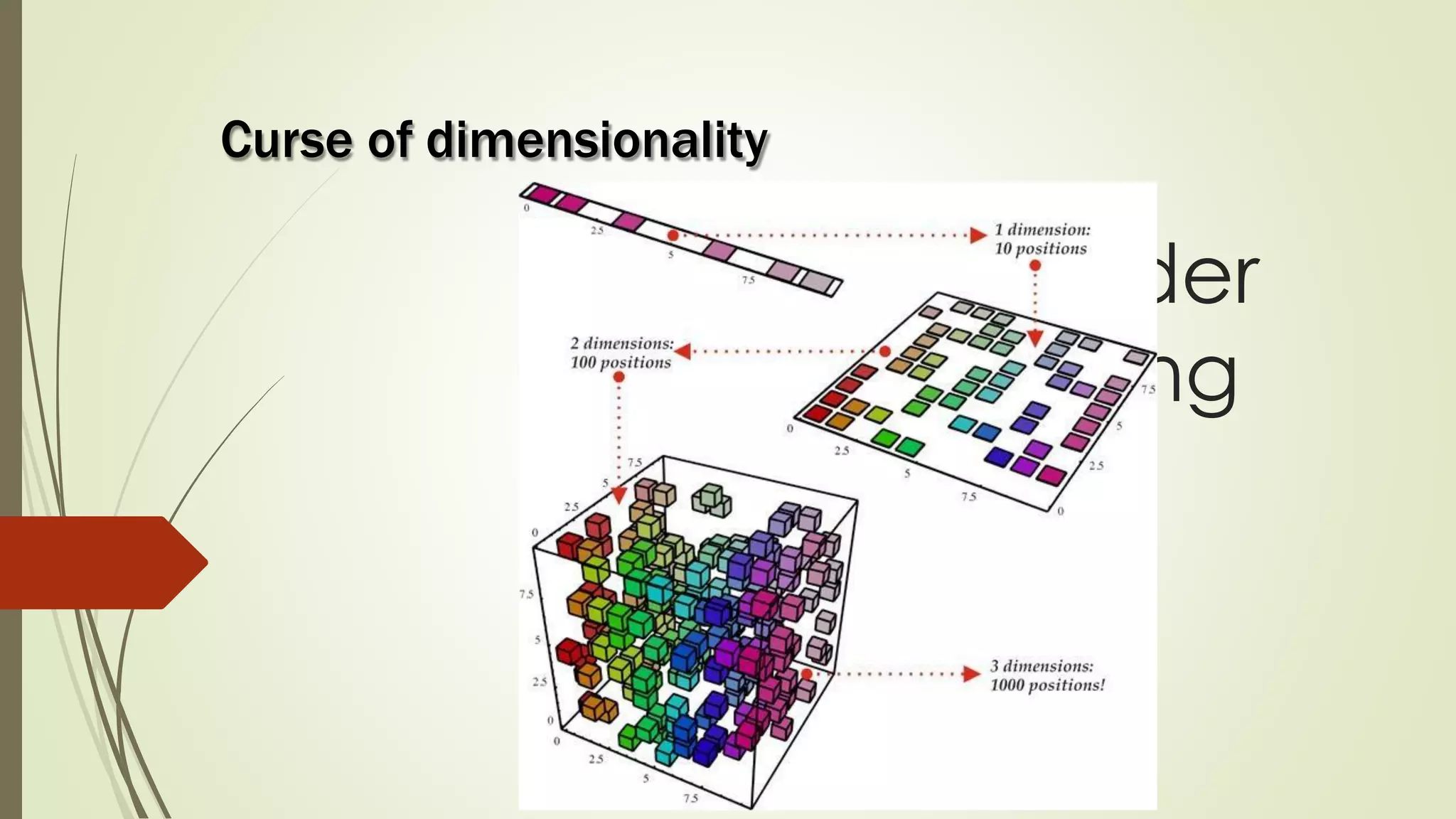
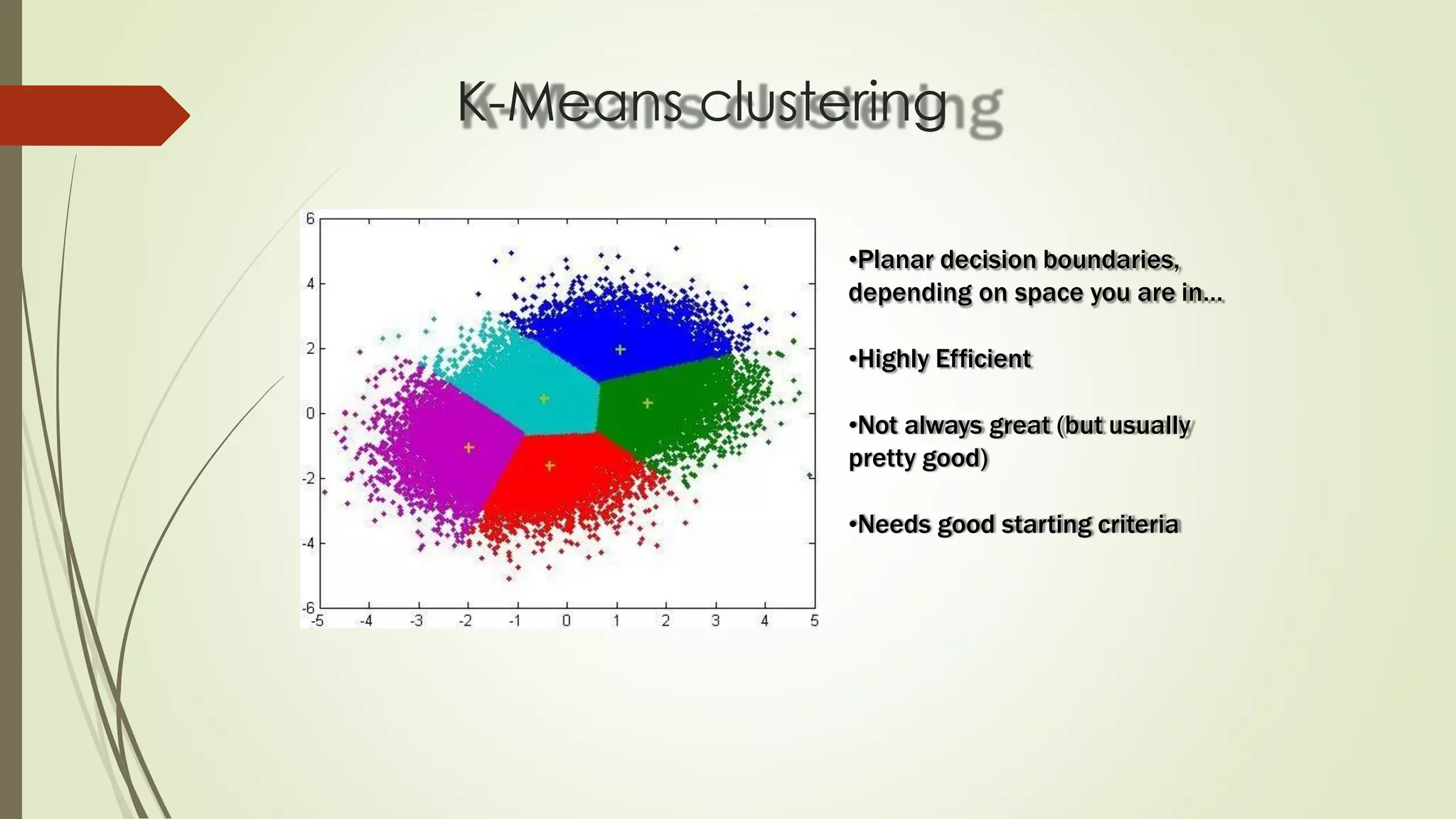

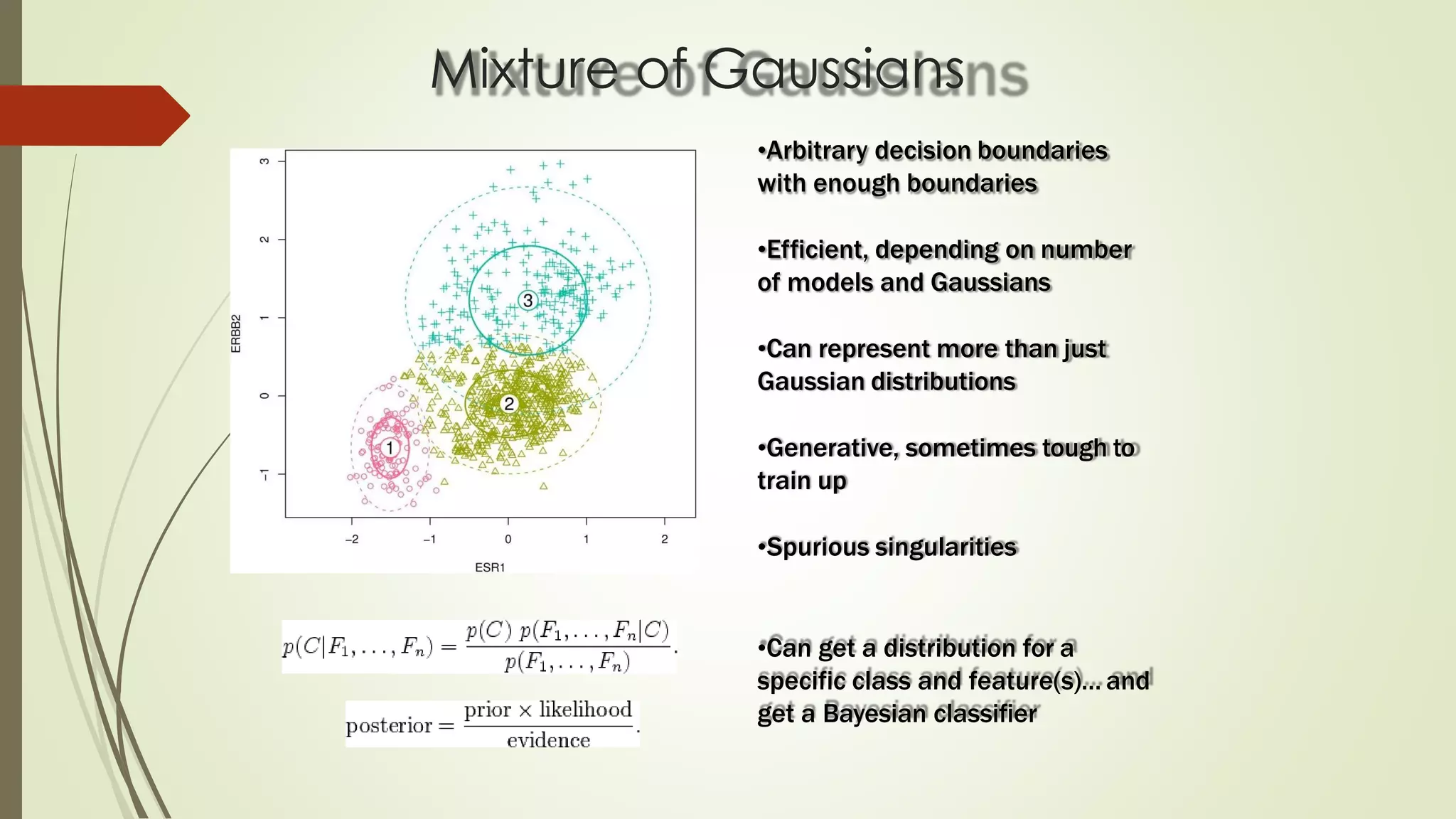

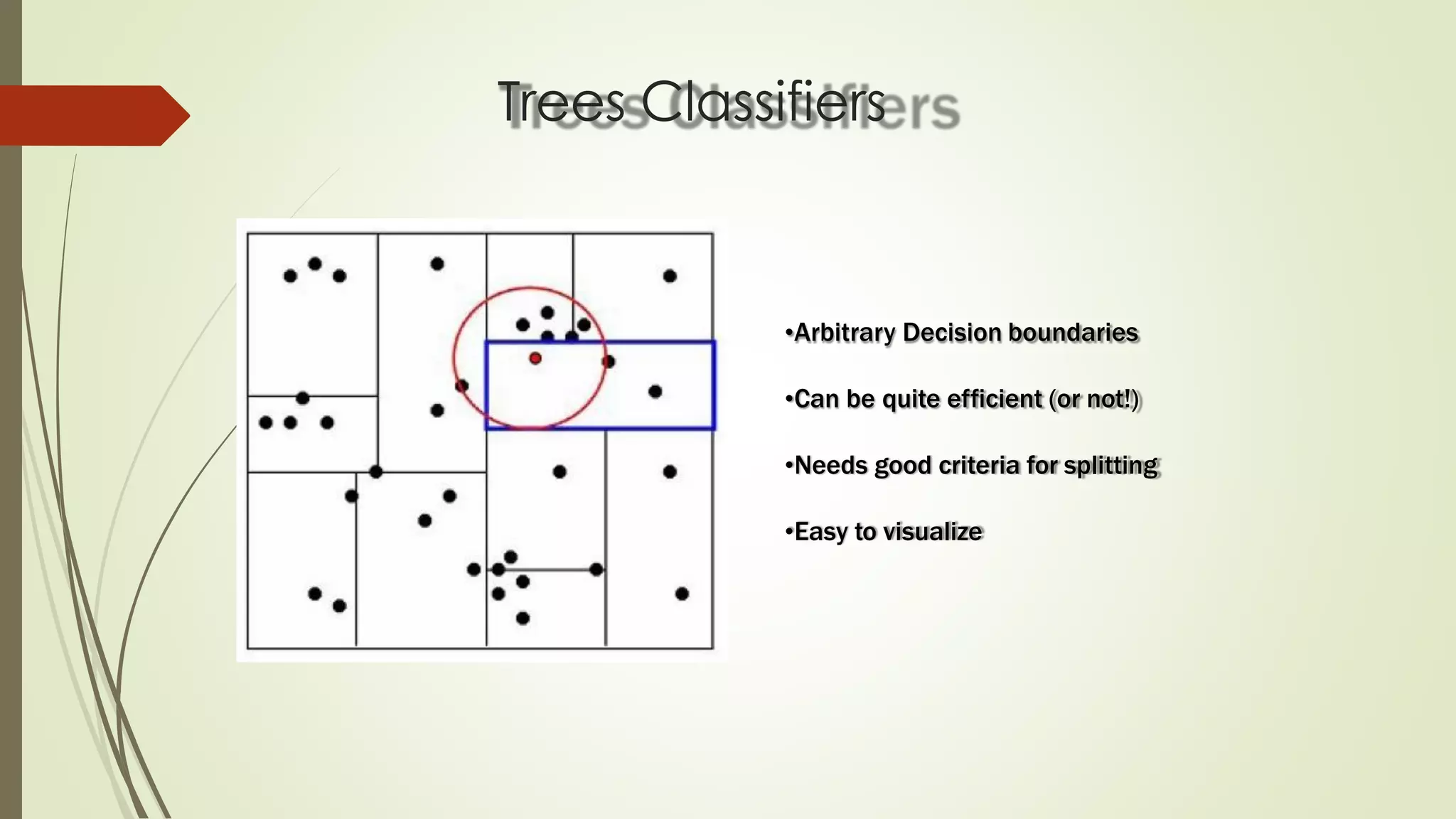
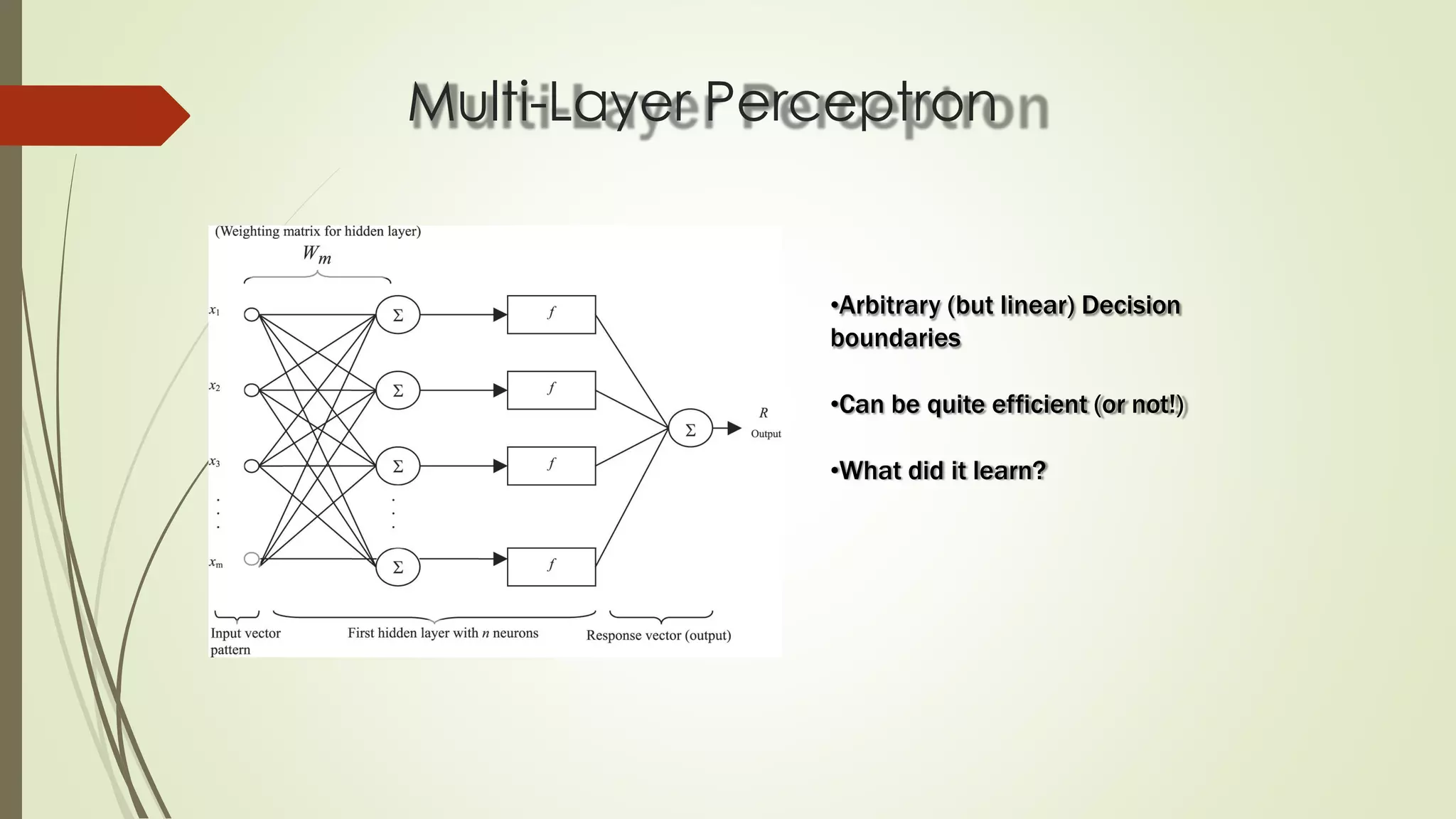

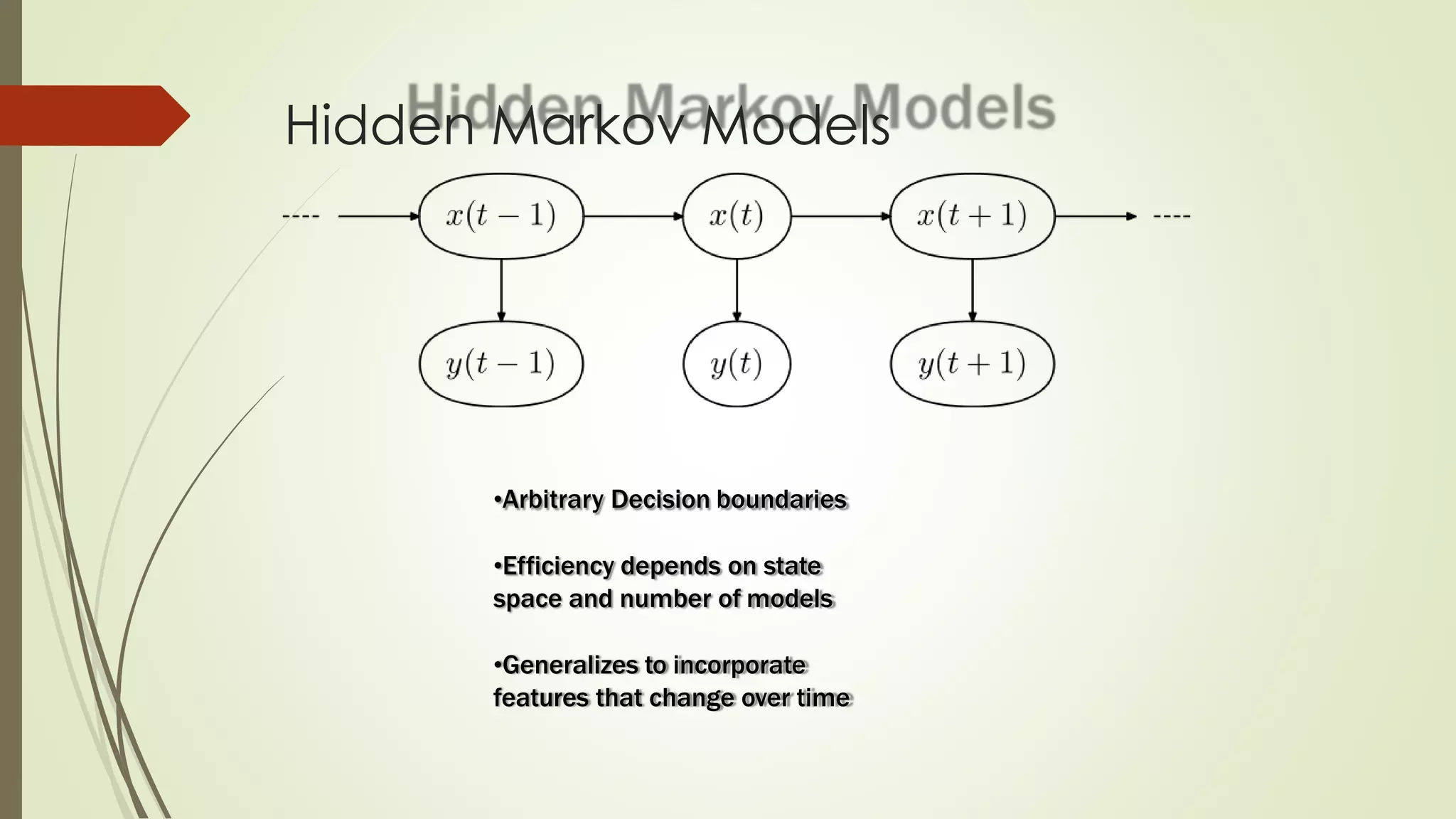


The document discusses various aspects of machine learning, including types of algorithms, training methods, and important considerations for optimizing models. It highlights supervised and unsupervised learning, the significance of feature selection, and common pitfalls such as overfitting and underfitting. Additionally, the text outlines various machine learning techniques like k-means clustering, decision trees, and support vector machines, providing insights on their efficiency and use cases.



































































