Downloaded 21 times






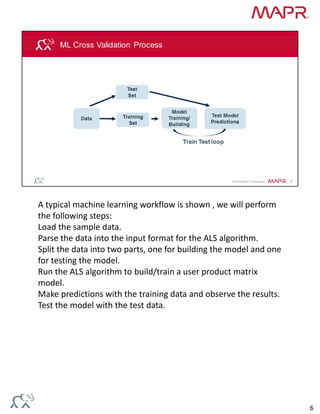

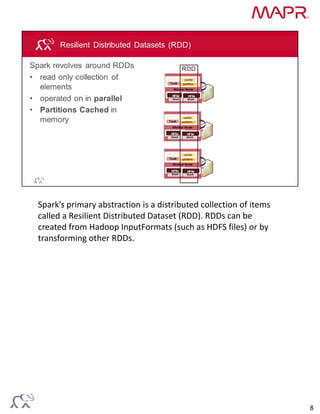

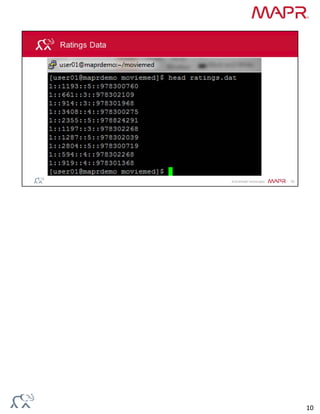

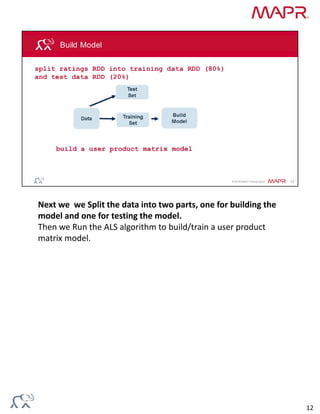



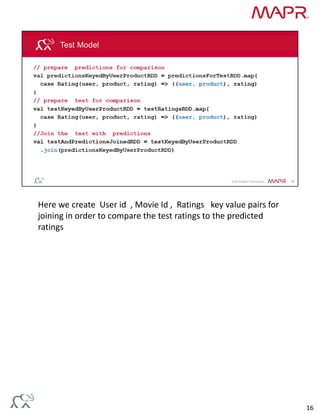









Collaborative filtering algorithms recommend items to users based on the preferences of similar users. They work by building a model from user preference data on many items. The model can then be used to predict item preferences for new users based on similarities to other users with similar preferences. Alternating least squares (ALS) is an iterative collaborative filtering algorithm that approximates the user-item rating matrix as the product of two dense matrices to discover latent features of users and items.






























![[Final]collaborative filtering and recommender systems](https://cdn.slidesharecdn.com/ss_thumbnails/finalcollaborativefilteringandrecommendersystems-141103044224-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)


















































