Maximum Likelihood
• Maximumlikelihood is a method for parameter estimation.
• The parameter values are found such that they maximize the
likelihood that the process described by the model, produced the
data that were actually observed.
• Our goal is to estimate the unknown parameters using a set of
known feature vectors in each class.
3
Zahra Sadeghi
3.
Maximum likelihood
• Considerthe problem of estimating a set of parameters θ of a probabilistic
model, given a set of observations x 1 , x 2 ,. . ., x n .
• Maximum likelihood techniques assume that
(1) the examples have no dependence on one another, in that the
occurrence of one has no effect on the others, and
(2) they can each be modeled in exactly the same way.
• These assumptions are often summarized by saying that events are
independent and identically distributed (i.i.d.).
• The i.i.d. assumption implies that a model for the joint probability density
function for all observations consists of the product of the same probability
model p(x_i ; θ) applied to each observation independently.
• For n observations:
4
Zahra Sadeghi
4.
Maximum likelihood
• Ifwe assume that data from one class do not affect
the parameter estimation of the others, we can formulate the
problem independent of classes and simplify our notation.
• Assumption: each data point is generated independently of
the others.
• If the events (i.e. the process that generates the data) are independent,
then the total probability of observing all of data is the product of
observing each data point individually (i.e. the product of the marginal
probabilities).
5
Zahra Sadeghi
5.
Likelihood
• Each functionp(x_i ; θ) has the same parameter values θ, and the aim
of parameter estimation is to maximize a joint probability model of
this form.
• Since the observations do not change, this value can only be changed
by altering the choice of the parameters θ.
• We can think about this value as the likelihood of the data, and write
it as
6
Zahra Sadeghi
6.
Log likelihood
• Sincethe data is fixed, it is arguably more useful to think of this as a
likelihood function for the parameters
• Multiplying many probabilities can lead to very small numbers, and so
people often work with the logarithm of the likelihood, or log-
likelihood which converts the product into a sum.
• Since logarithms are strictly monotonically increasing functions,
maximizing the log-likelihood is the same as maximizing the
likelihood.
7
Zahra Sadeghi
7.
Maximum likelihood estimation
•“Maximum likelihood” learning refers to techniques that search for
parameters that do this:
8
Zahra Sadeghi
8.
• The maximumlikelihood (ML) method estimates θ so that the
likelihood function takes its maximum value,
• A necessary condition in order to maximize it is the gradient of the
likelihood function with respect to θ to be zero, that is
9
Zahra Sadeghi
9.
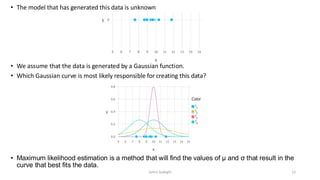
• Suppose thatmodel that has generated this data is unknown
11
Zahra Sadeghi
10.
• The modelthat has generated this data is unknown
• We assume that the data is generated by a Gaussian function.
• Which Gaussian curve is most likely responsible for creating this data?
• Maximum likelihood estimation is a method that will find the values of μ and σ that result in the
curve that best fits the data.
12
Zahra Sadeghi
Likelihood
• Likelihood functionmeasures the goodness of fit of a statistical model
to a sample of data for given values of the parameters θ
• The ground truth of observations is one-hot encoding
• The likelihood of observations is
15
Zahra Sadeghi
Negative log likelihood
•because the logarithmic function is monotonic, maximizing the
likelihood is the same as maximizing the log of the likelihood (i.e., log-
likelihood).
• since “minimizing loss” makes more sense, we can instead take the
negative of the log-likelihood and minimize that, resulting in the
Negative Log-Likelihood Loss
17
Zahra Sadeghi
15.
Maximum a PosterioriProbability Estimation
• For the derivation of the maximum likelihood estimate, we
considered θ as an unknown parameter.
• Now we will consider it as a random vector, and we will
estimate its value on the condition that samples x 1 , . . . , x N
have occurred.
• Using bayes theorem:
• p(X) is not involved since it is independent of θ.
20
Zahra Sadeghi
16.
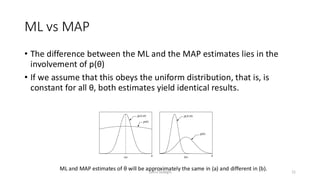
ML vs MAP
•The difference between the ML and the MAP estimates lies in the
involvement of p(θ)
• If we assume that this obeys the uniform distribution, that is, is
constant for all θ, both estimates yield identical results.
21
ML and MAP estimates of θ will be approximately the same in (a) and different in (b).
Zahra Sadeghi






































































![谷歌留痕技术 [ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130174328-3833018c-thumbnail.jpg?width=640&height=640&fit=bounds)












