Human learning
Continuouslearning in lifespan
Intelligence vs memory
Learning from experience
Types of learning
1. learning under Expert Guidance
2. Learning guided by knowledge gained from experts
3. self learning
2.
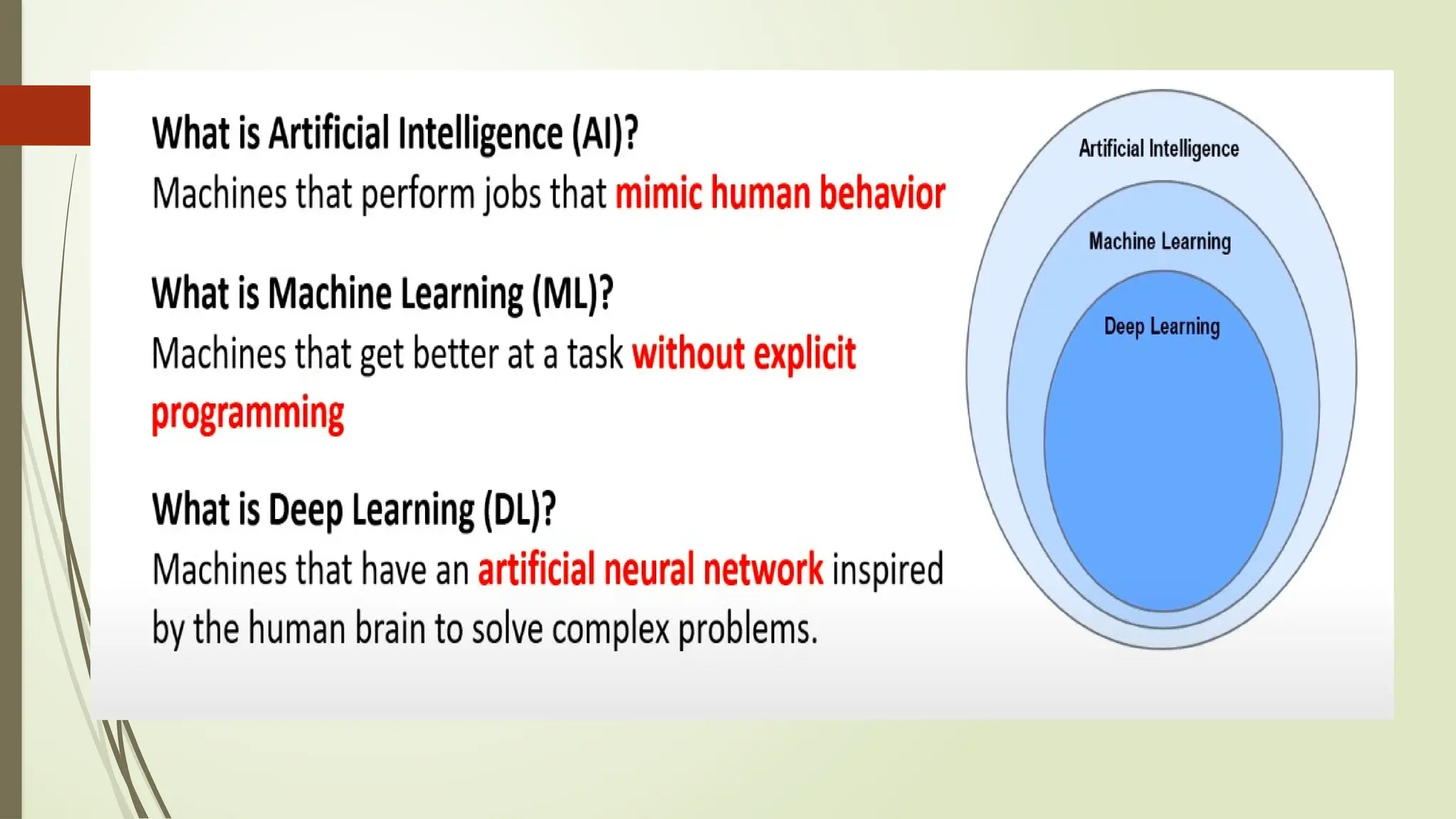
Machine learning
Machine learningis a branch of artificial intelligence (AI) and computer science which focuses
on the use of data and algorithms to imitate the way that humans learn, gradually improving
its accuracy.(IBM)
Arthur Samuel first used the term "machine learning" in 1959. It could be summarized as
follows:
Dfn: Without being explicitly programmed, machine learning enables a machine to
automatically learn from data, improve performance from experiences, and predict
things.
Machine learning algorithms create a mathematical model that, without being explicitly
programmed, aids in making predictions or decisions with the assistance of sample historical
data, or training data. For the purpose of developing predictive models, machine learning
brings together statistics and computer science.
5.
Need for MachineLearning(Why used ML )
Many of today's leading companies, such as Facebook, Google, and Uber, make machine learning a central
part of their operations. Machine learning has become a significant competitive differentiator for many
companies.
Following are some key points which show the importance of Machine Learning:
• Rapid increment in the production of data
• Solving complex problems, which are difficult for a human
• Decision making in various sector including finance
• Finding hidden patterns and extracting useful information from data.
6.
Use cases ofMachine Learning Technology
Some important applications in which machine learning is widely used are
given below:
Healthcare: Machine Learning is widely used in the healthcare industry. It helps
healthcare researchers to analyze data points and suggest outcomes
Automation: This is one of the significant applications of machine learning that
helps to make the system automated. It helps machines to perform repetitive tasks without human
intervention.
Banking and Finance: Machine Learning is a subset of AI that uses
statistical models to make accurate predictions. In the banking and finance sector, machine
learning helped in many ways, such as fraud detection, portfolio management, risk management,
chatbots, document analysis, high-frequency
7.
Transportation and TrafficPrediction: This is one of the most common applications of Machine Learning that
is widely used by all individuals in their daily routine. It helps to ensure highly secured routes, generate accurate ETAs, predict
vehicle breakdown, Driving Prescriptive Analytics, etc. Although machine learning has solved transportation problems, it still
requires more improvement. Statistical machine learning algorithms helps to build a smart transportation system. Further, deep
Learning explored the complex interactions of roads, highways, traffic, environmental elements, crashes, etc. Hence, machine
learning technology has improved daily traffic management as well as a collection of traffic data to predict insights of routes and
traffic.
Image Recognition: It is one of the most common applications of machine learning which is used to detect the image
over the internet. Further, various social media sites such as Facebook uses image recognition for tagging the images to your
Facebook friends with its feature named auto friend tagging suggestion.
Further, now a day's, almost all mobile devices come with exciting face detection features. Using this feature, you can secure your
mobile data with face unlocking, so if anyone tries to access your mobile device, they cannot open without face recognition.
Speech Recognition: Speech recognition is one of the biggest achievements of machine learning applications. It
enables users to search content without writing text or, in other words, 'search by voice'. It can search content/products on
YouTube, Google, Amazon, etc. platforms by your voice. This technology is referred to as speech recognition.
It is a process of converting voice instructions into the text; hence it is also known as 'Speech to text' or 'Computer speech
recognition. Some important examples of speech recognitions are Google assistant, Siri, Cortana, Alexa, etc.
8.
Product Recommendation: Itis one of the biggest
achievements made by machine learning which helps various e-commerce and entertainment
companies like Flipkart, Amazon, Netflix, etc., to digitally advertise their products over the
internet. When anyone searches for any product, they start getting an advertisement for the
same product while internet surfing
Virtual Personal Assistance: This feature helps us in many
ways, such as searching content using voice instruction, calling a number using voice, searching
for contacts on your mobile, playing music, opening an email, Scheduling an appointment, etc.
Email Spam and Malware Detection & Filtering: Machine learning
also helps us filter emails in different categories such as spam, important, general, etc.
9.
Self-driving cars: Thisis one of the most exciting applications of machine learning.
Machine learning plays a vital role in the manufacturing of self-driving cars. It uses an
unsupervised learning method to train car models to detect people and objects while driving.
Tata and Tesla are the most popular car manufacturing companies working on self-driving cars.
Credit card fraud detection: Credit card frauds have become very easy
targets for online hackers. As the culture of online/digital payments is increasing, the risk of
credit/debit cards is parallel increasing.
Stock Marketing and Trading: Machine learning also helps in the stock
marketing and trading sector, where it uses historical trends or experience for predicting market
risk.
Language Translation: The use of Machine learning can be seen in language
translation. It uses sequence-to-sequence learning algorithms for translating one language into
another.
Machine learningis a subset of AI, which enables the machine to automatically learn from data,
improve performance from past experiences, and make predictions.
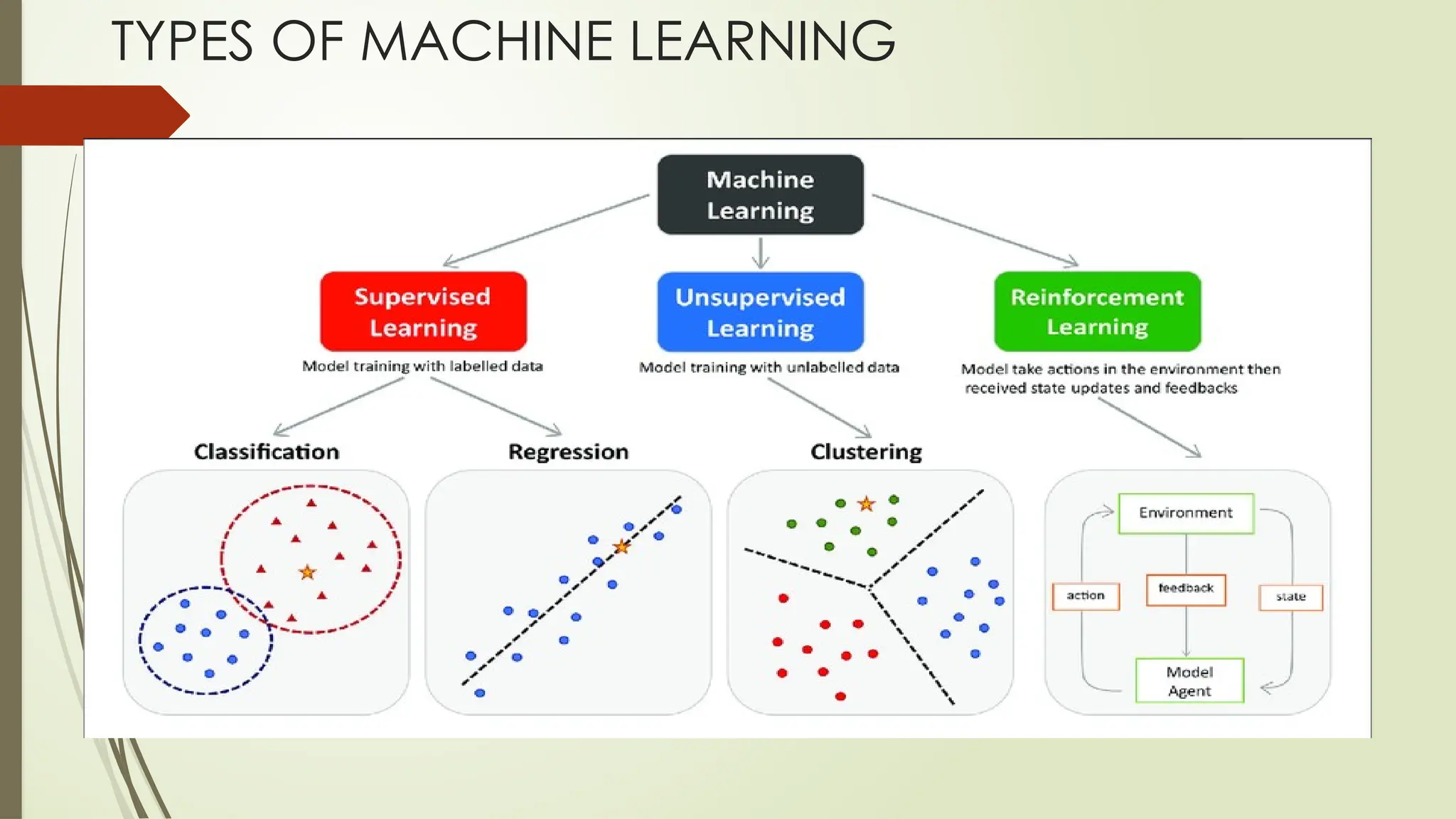
Based on the methods and way of learning, machine learning is divided into mainly four types, which are:
1. Supervised Machine Learning
2. Unsupervised Machine Learning
3. Semi-Supervised Machine Learning
4. Reinforcement Learning
1. Supervised Machine Learning
Supervised Machine learning is based on supervision. It means in the supervised learning
technique, we train the machines using the "labeled" dataset, and based on the training, the
machine predicts the output. Here, the labeled data specifies that some of the inputs are
already mapped to the output. More preciously, we can say; that first, we train the machine with
the input and corresponding output, and then we ask the machine to predict the output using
the test dataset.
Risk Assessment, Fraud Detection, Spam filtering, etc.
14.
Categories of SupervisedMachine Learning
• Classification
• Regression
a) Classification
Classification algorithms are used to solve the classification problems in
which the output variable is categorical, such as "Yes" or No, Male or
Female, Red or Blue, etc. The classification algorithms predict the categories
present in the dataset. Some real-world examples of classification algorithms
are Spam Detection, Email filtering, etc.
Some popular classification algorithms are given below:
15.
• Random ForestAlgorithm
• Decision Tree Algorithm
• Logistic Regression Algorithm
• Support Vector Machine Algorithm
b) Regression
Regression algorithms are used to solve regression problems in which there is a linear
relationship between input and output variables. These are used to predict continuous
output variables, such as market trends, weather prediction, etc.
Some popular Regression algorithms are given below:
• Simple Linear Regression Algorithm
• Multivariate Regression Algorithm
• Decision Tree Algorithm
• Lasso Regression
16.
Advantages and Disadvantagesof Supervised Learning
Advantages:
• Well-suited for tasks with labeled data.
• Can make accurate predictions once trained.
• Can handle both regression and classification problems.
Disadvantages:
• These algorithms are not able to solve complex tasks.
• It may predict the wrong output if the test data is different from the training
data.
• It requires lots of computational time to train the algorithm.
17.
Applications ofSupervised Learning
Some common applications of Supervised Learning are given below:
• Image Segmentation:
Supervised Learning algorithms are used in image segmentation. In this process,
image classification is performed on different image data with pre-defined labels.
• Medical Diagnosis:
Supervised algorithms are also used in the medical field for diagnosis purposes. It
is done by using medical images and past labelled data with labels for disease
conditions. With such a process, the machine can identify a disease for the new
patients.
• Fraud Detection - Supervised Learning classification algorithms are used for
identifying fraud transactions, fraud customers, etc. It is done by using historic data
to identify the patterns that can lead to possible fraud.
• Spam detection - In spam detection & filtering, classification algorithms are used.
These algorithms classify an email as spam or not spam. The spam emails are sent
to the spam folder.
• Speech Recognition - Supervised learning algorithms are also used in speech
recognition. The algorithm is trained with voice data, and various identifications can
be done using the same, such as voice-activated passwords, voice commands, etc.
18.
2. UnsupervisedMachine Learning
Unsupervised ML is different from the Supervised learning technique; as its name suggests,
there is no need for supervision. It means, in unsupervised machine learning, the machine is
trained using the unlabeled dataset, and the machine predicts the output without any
supervision.
The main aim of the unsupervised learning algorithm is to group or categories the
unsorted dataset according to the similarities, patterns, and differences. Machines are
instructed to find the hidden patterns from the input dataset.
19.
Categories ofUnsupervised Machine Learning
Unsupervised Learning can be further classified into two types, which are given below:
• Clustering
• Association
1) Clustering
The clustering technique is used when we want to find the inherent groups from the data. It is a
way to group the objects into a cluster such that the objects with the most similarities remain
in one group and have fewer or no similarities with the objects of other groups. An example of
the clustering algorithm is grouping the customers by their purchasing behavior.
Some of the popular clustering algorithms are given below:
• K-Means Clustering algorithm
• Mean-shift algorithm
• DBSCAN Algorithm
20.
2) Association
Association rule learning is an unsupervised learning technique, which finds interesting
relations among variables within a large dataset. The main aim of this learning algorithm is
to find the dependency of one data item on another data item and map those variables
accordingly so that it can generate maximum profit. This algorithm is mainly applied
in Market Basket analysis
Advantages:
• Can discover hidden patterns and structures in data without labeled examples.
• Useful for tasks like clustering, anomaly detection, and dimensionality reduction.
• Can potentially uncover valuable insights from large datasets.
Disadvantages:
• Results may be less interpretable compared to supervised learning.
• May require more computational resources and time to process large datasets.
21.
Applications ofUnsupervised Learning
• Network Analysis: Unsupervised learning is used for identifying plagiarism and copyright
in document network analysis of text data for scholarly articles.
• Recommendation Systems: Recommendation systems widely use unsupervised learning
techniques for building recommendation applications for different web applications and e-
commerce websites.
• Anomaly Detection: Anomaly detection is a popular application of unsupervised learning,
which can identify unusual data points within the dataset. It is used to discover fraudulent
transactions.
22.
Reinforcement Learning
Reinforcement learning works on a feedback-based process, in which an AI agent (A
software component) automatically explore s its surroundings by hitting & trail, taking
action, learning from experiences, and improving its performance. Agent gets rewarded
for each good action and get punished for each bad action; hence the goal of reinforcement
learning agent is to maximize the rewards.
The reinforcement learning process is similar to a human being; for example, a child learns
various things by experiences in his day-to-day life. An example of reinforcement learning is
to play a game, where the Game is the environment, the moves of an agent at each step
define states, and the goal of the agent is to get a high score. Agent receives feedback in
terms of punishment and rewards.
Due to its way of working, reinforcement learning is employed in different fields such
as Game theory, Operation Research,
23.
Reinforcement learningis categorized mainly into two types of methods/algorithms:
• Positive Reinforcement Learning: Positive reinforcement learning specifies increasing the
tendency that the required behavior would occur again by adding something. It enhances
the strength of the behavior of the agent and positively impacts it.
• Negative Reinforcement Learning: Negative reinforcement learning works exactly
opposite to the positive RL. It increases the tendency that the specific behaviour would occur
again by avoiding the negative condition.
24.
Real-world Usecases of Reinforcement Learning
• Video Games:
RL algorithms are much popular in gaming applications. It is used to gain super-human performance.
Some popular games that use RL algorithms are AlphaGO and AlphaGO Zero.
• Resource Management:
The "Resource Management with Deep Reinforcement Learning" paper showed that how to use RL in
computer to a
• utomatically learn and schedule resources to wait for different jobs in order to minimize average job
slowdown.
• Robotics:
RL is widely being used in Robotics applications. Robots are used in the industrial and manufacturing
area, and these robots are made more powerful with reinforcement learning. There are different
industries that have their vision of building intelligent robots using AI and Machine learning technology.
• Text Mining
Text-mining, one of the great applications of NLP, is now being implemented with the help of
Reinforcement Learning by Salesforce company.
25.
Advantages andDisadvantages of Reinforcement Learning
Advantages
• It helps in solving complex real-world problems which are difficult to be solved by general
techniques.
• The learning model of RL is similar to the learning of human beings; hence most accurate
results can be found.
• Helps in achieving long - term results.
Disadvantage
RL algorithms are not preferred for simple problems.
• RL algorithms require huge data and computations.
26.
Common Issues in Machine Learning
1. Inadequate Training Data
The major issue that comes while using machine learning algorithms is the lack of quality as well as quantity of data.
Although data plays a vital role in the processing of machine learning algorithms, many data scientists claim that
inadequate data, noisy data, and unclean data are extremely exhausting the machine learning algorithms.
Noisy Data- It is responsible for an inaccurate prediction that affects the decision as well as accuracy in classification tasks.
Incorrect data- It is also responsible for faulty programming and results obtained in machine learning models. Hence,
incorrect data may affect the accuracy of the results also.
Generalizing of output data- Sometimes, it is also found that generalizing output data becomes complex, which results in
comparatively poor future actions.
2. Poor quality of data
As we have discussed above, data plays a significant role in machine learning, and it must be of good quality as well. Noisy
data, incomplete data, inaccurate data, and unclean data lead to less accuracy in classification and low-quality results.
Hence, data quality can also be considered as a major common problem while processing machine learning algorithms.
3. Non-representative training data
To make sure our training model is generalized well or not, we have to ensure that sample training data must be
representative of new cases that we need to generalize. The training data must cover all cases that are already occurred
as well as occurring.
27.
4. Overfitting andUnderfitting
overfit models experience high variance—they give accurate results for the training set but not for
the test set. Methods to reduce overfitting:
• Increase training data in a dataset.
• Reduce model complexity by simplifying the model by selecting one with fewer parameters
• Ridge Regularization and Lasso Regularization
• Reduce the noise
• Reduce the number of attributes in training data.
Underfitting:
Underfitting is just the opposite of overfitting. Whenever a machine learning model is trained with
fewer amounts of data, and as a result, it provides incomplete and inaccurate data and destroys the
accuracy of the machine learning model.
Underfit models experience high bias—they give inaccurate results for both the training data and test
set.
28.
Methods toreduce Underfitting:
• Increase model complexity
• Remove noise from the data
• Trained on increased and better features
• Reduce the constraints
• Increase the number of epochs to get better results.
5. Monitoring and maintenance
As we know that generalized output data is mandatory for any machine learning model;
hence, regular monitoring and maintenance become compulsory for the same. Different
results for different actions require data change; hence editing of codes as well as resources
for monitoring them also become necessary.
29.
6. Lack ofskilled resources
Although Machine Learning and Artificial Intelligence are continuously growing in the market, still
these industries are fresher in comparison to others. The absence of skilled resources in the form of
manpower is also an issue. Hence, we need manpower having in-depth knowledge of mathematics,
science, and technologies for developing and managing scientific substances for machine learning.
7. Process Complexity of Machine Learning
The machine learning process is very complex, which is also another major issue faced by machine
learning engineers and data scientists. However, Machine Learning and Artificial Intelligence are
very new technologies but are still in an experimental phase and continuously being changing
over time. There is the majority of hits and trial experiments; hence the probability of error is
higher than expected. Further, it also includes analyzing the data, removing data bias, training
data, applying complex mathematical calculations, etc., making the procedure more complicated
and quite tedious.
30.
8. DataBias
Data Biasing is also found a big challenge in Machine Learning. These errors exist when certain
elements of the dataset are heavily weighted or need more importance than others. Biased data leads
to inaccurate results, skewed outcomes, and other analytical errors. However, we can resolve this error
by determining where data is actually biased in the dataset. Further, take necessary steps to reduce it.
• Use multi-pass annotation such as sentiment analysis, content moderation, and intent recognition.
9. Lack of Explainability
This basically means the outputs cannot be easily comprehended as it is programmed in specific ways
to deliver for certain conditions. Hence, a lack of explainability is also found in machine learning
algorithms which reduce the credibility of the algorithms.
10. Slow implementations and results
This issue is also very commonly seen in machine learning models. However, machine learning models
are highly efficient in producing accurate results but are time-consuming. Slow programming,
excessive requirements' and overloaded data take more time to provide accurate results than
expected. This needs continuous maintenance and monitoring of the model for delivering accurate
results.
11. Irrelevant features
Although machine learning models are intended to give the best possible outcome, if we feed garbage
data as input, then the result will also be garbage. Hence, we should use relevant features in our
training sample. A machine learning model is said to be good if training data has a good set of features
or less irrelevant features.
31.
Advantages OfPython Over Other Languages
1. Simple and Readable Syntax: Python has a straightforward and easy-to-read syntax,
which makes it suitable for beginners and experienced developers alike. Its syntax
emphasizes readability and reduces the cost of program maintenance and development.
2. Extensive Libraries and Frameworks: Python boasts a rich ecosystem of libraries and
frameworks for various tasks such as data analysis, machine learning, web development,
scientific computing, and more. Popular libraries like NumPy, pandas, TensorFlow, and
Django enable developers to build complex applications with minimal effort.
3. Platform Independence: Python is a platform-independent language, meaning that
Python code can run on any platform with the appropriate interpreter installed. This
portability allows developers to write code once and deploy it across multiple platforms
without modification.
4. Community Support: Python has a vibrant and active community of developers,
researchers, and enthusiasts who contribute to its growth and development. The
community provides extensive documentation, tutorials, forums, and third-party packages,
making it easier for developers to learn and troubleshoot problems.
32.
5. Ease ofLearning and Adoption: Python's simplicity and readability make it an ideal language for
beginners to learn programming. Its gentle learning curve and extensive resources make it
accessible to individuals from various backgrounds, including students, professionals, and
hobbyists.
6. Versatility: Python is a versatile language that can be used for a wide range of applications,
including web development, desktop applications, automation, scripting, data analysis, machine
learning, artificial intelligence, and more. Its flexibility allows developers to work on diverse projects
without switching to different languages.
7. Integration Capabilities: Python seamlessly integrates with other programming languages and
technologies, making it easy to incorporate existing code and systems into Python-based projects. It
supports interoperability with languages like C/C++, Java, and .NET, enabling developers to leverage
the strengths of different languages within a single application.
8. Scalability: Python is scalable, allowing developers to build small scripts or large-scale
applications efficiently. Its modular and object-oriented design facilitates code organization and
maintenance, making it easier to scale projects as they grow in complexity.
33.
SCIKIT_LEARN
Scikit-learn isa free, open-source machine-learning library for the Python programming language
Installation
1. Install Python: Ensure you have Python installed on your system. You can download and install Python
from the official website: https://www.python.org/
2. Install scikit-learn: You can install scikit-learn using pip, which is Python's package manager. Open your
terminal or command prompt and run the following command:
pip install scikit-learn
3. NumPy and SciPy: scikit-learn depends on NumPy and SciPy for numerical computations and scientific
algorithms. You can install them using pip:
pip install numpy scipy
4. Pandas: Pandas is a powerful data manipulation library often used in conjunction with scikit-learn for data
preprocessing and analysis:
pip install pandas
34.
Matplotlib: Matplotlibis a plotting library for creating static, interactive, and animated visualizations in
Python. It provides a MATLAB-like interface and supports a wide range of plots, including line plots,
scatter plots, bar plots, histograms, and more. Scikit-learn often uses Matplotlib for visualizing data and
model evaluation.
pip install matplotlib