アルゴリズム - Notations
samplesize:
#labels:
labels:
instance (features):
sample:
unknown distribution over ×
model:
misclassification error:
surrogate loss (such as the softmax cross-entropy):
:
ℓ(y, f(x)) = log[ e ] −
y ∈[L]
′
∑ f
(x)
y′
f
(x) =
y log[1 + e ] (1)
y =y
′
∑ f
(x)−f
(x)
y′ y
N
L
Y = [L] = 1, 2, ..., L
X
S = (x
, y
) ∼
n n n=1
N
PN
P X Y
f : X → RL
P
(y ∈
x,y / argmax
f
(x))
y ∈Y
′ y′
ℓ Y × R →
L
R
7.
アルゴリズム - BalancedError
これを最小化する
BER = P
(y ∈
L
1
y∈[L]
∑ x∣y / argmax f
(x))
y ∈Y
′ y′
8.
アルゴリズム - 従来手法
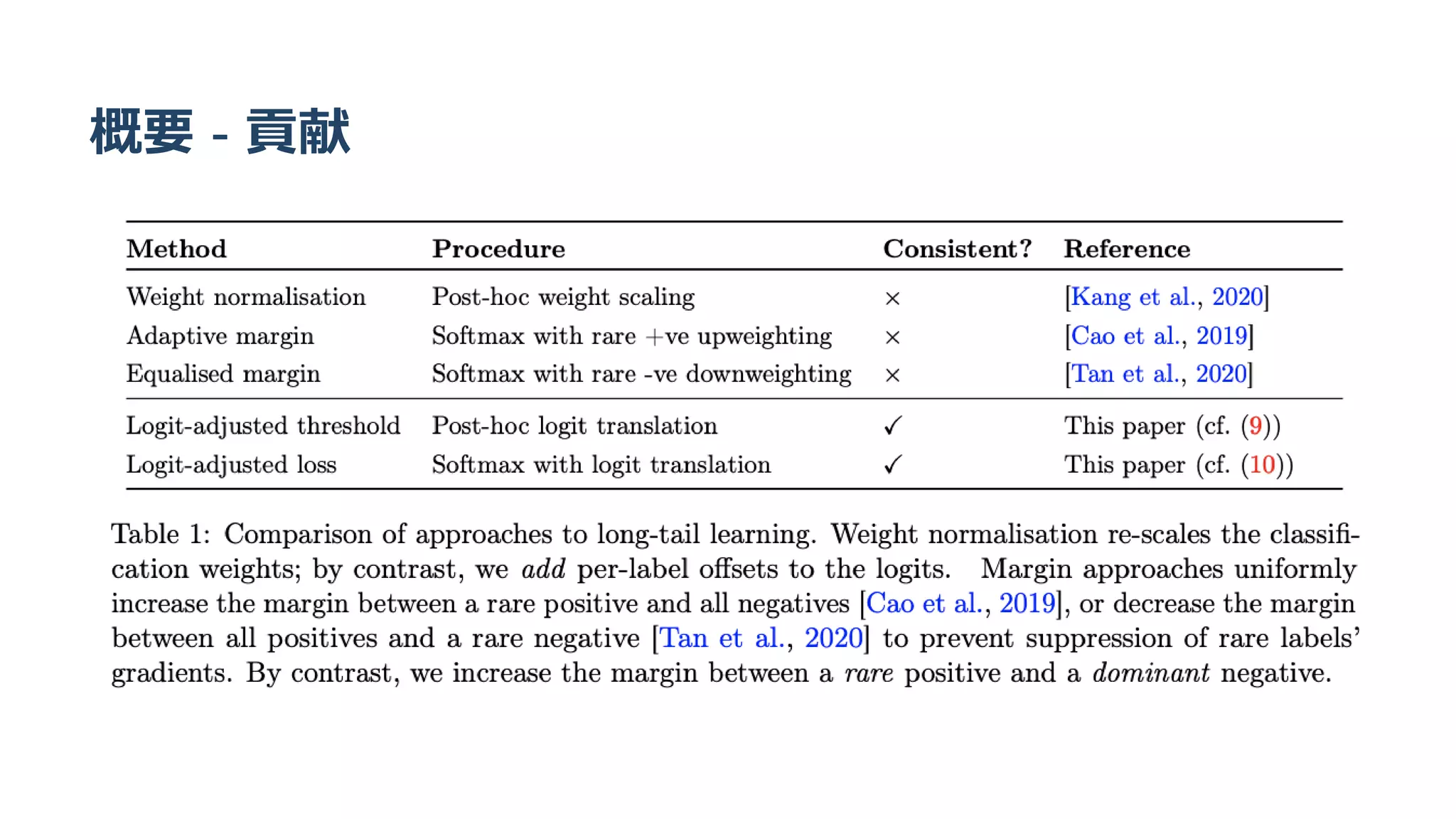
現行の対処方法は以下の3つに分類できる
1. モデルへの入力に対してなんやかんやするやつ(e.g.over- or under-sampling)
Kubat and Matwin, 1997, Chawla et al., 2002, Wallace et al., 2011, Mikolov et
al., 2013, Mahajan et al., 2018, Yin et al., 2018
2. モデルの出力をなんやかんやするやつ (e.g. post-hoc correction of the decision
threshold)
Fawcett and Provost, 1996, Collell et al., 2016] or weights [Kim and Kim, 2019,
Kang et al., 2020
3. モデルの中でなんやかんやするやつ (e.g. modifying the loss function)
Xie and Manski, 1989, Morik et al., 1999, Cui et al., 2019, Zhang et al., 2017,
Cao et al., 2019, Tan et al., 2020
今回扱うのは2.と3.
9.
アルゴリズム - 出力で調整する手法達
Post-hocweight normalization
argmax
w
Φ(x)/ν =
y∈[L] y
T
y
τ
argmax
f
(x)/ν (3)
y∈[L] y y
τ
クラスを計算する際(argmaxする際)に で除算して補正
重みの正規化によって少数ラベルの貢献度を上げる
in Kim and Kim, 2019、 Ye et al., 2020
in Kang et al., 2020
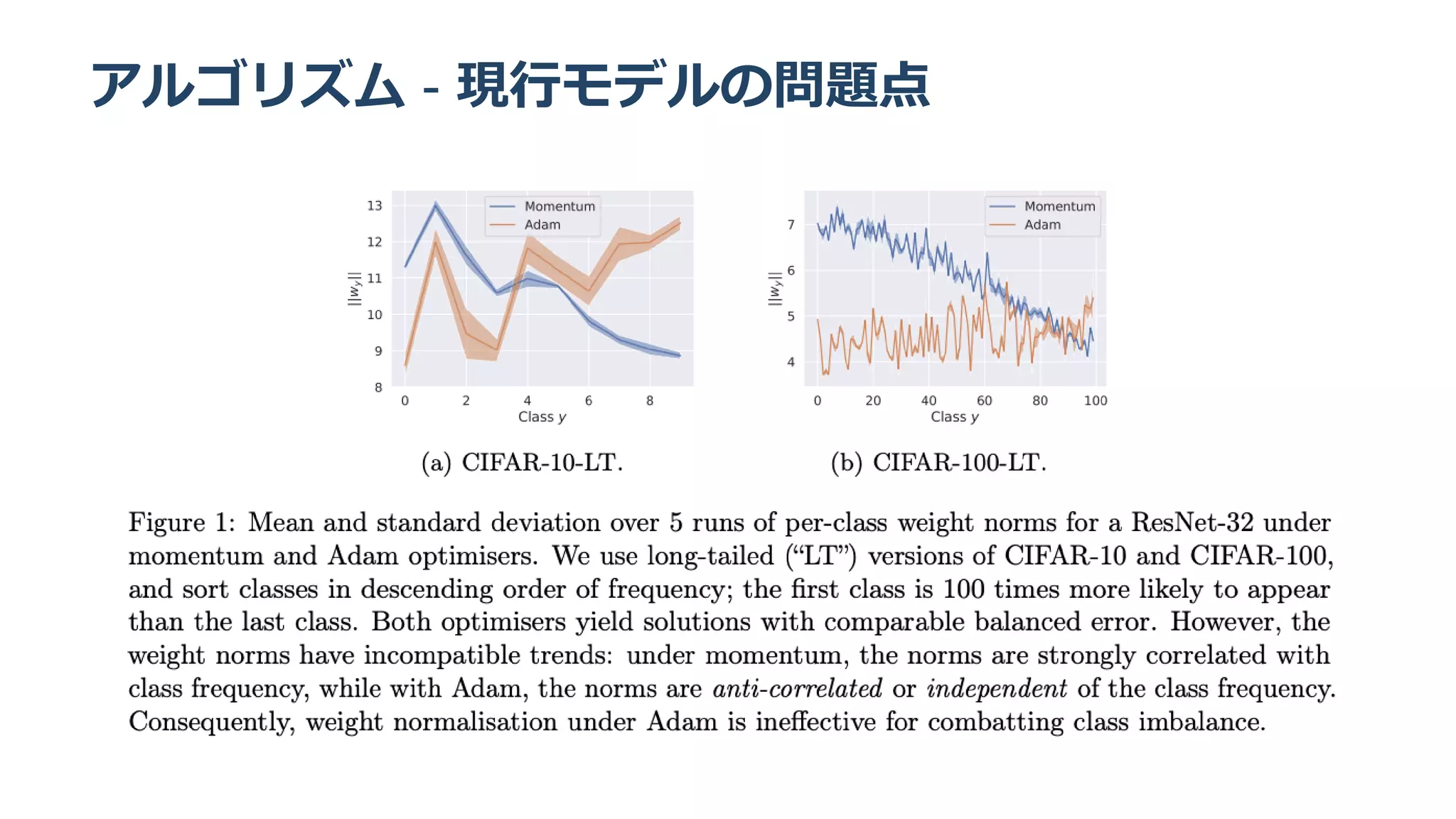
と が相関する傾向にあることを利用している
τ 0
νy
ν =
y P(y)
ν =
y ∣∣w
∣∣
y 2
∣∣w
∣∣
y 2 P(y)
10.
アルゴリズム - モデルの中で調整する手法達
Lossmodification (Xie and Manski, 1989、 Morik et al., 1999の提案手法)
ℓ(y, f(x)) = log[1 +
P(y)
1
e ] (4)
y =y
′
∑ f
(x)−f
(x)
y′ y
損失計算の際に調整(式(4)では で調整)
バランシングは分離可能な設定では最小限の効果しかない
訓練損失をゼロにする手法は重み付けをしても必然的に最適な状態が保たれる
(Byrd and Lipton, 2019)(らしい)
直感的に分離境界を支配的なクラスに近づけることが望ましい
P(y)
11.
アルゴリズム - モデルの中で調整する手法達
式(4)以外の例2選
hingelossにクラスごとのマージンを加える(Cao et al., 2019)
少数の正例 と任意の負例 との間にマージンが作れる
ℓ(y, f(x)) = [1 + e e ] (5)
y =y
′
∑ δ
y f
(x)−f
(x)
y′ y
クラスごとのマージンをソフトマックスクロスエントロピーに追加 (Tan et al.,
2020)
勾配を調整するのが目的
は を単調増加変換したもの
ℓ(y, f(x)) = [1 + e e ] (6)
y =y
′
∑ δ
y′ f
(x)−f (x)
y′ y
y y =
′
y
δ ∝
y P(y)−1/4
δ ≤
y 0 P(y)
アルゴリズム - 提案手法
平衡誤差を最小化することでベイズ最適解を得たい
になるようにしたい
バランス調整された推定量を推定するモデルを訓練すればよい(式(7))
平衡誤差を最小化することにおいてFisher Consistentがある
ロジット調整(logit adjustment)は明確な統計的根拠を持っている(Appendix参
照)
argmax
f
(x) =
y∈[L] y
∗
argmax
P (y∣x) =
y∈[L]
bal
argmax
P(x∣y) (7)
y∈[L]
そして推定量の対数を式(8)のように修正
式(8)は以下を仮定
class-probabilitiesを
where
bal ∗ ∗
f ∈
∗ argmin
BER(f)
f:X→RL
P (y∣x)
bal
P (y∣x) ∝
bal
P(y∣x)/P(y)
P(y∣x) ∝ exp(s
(x))
y
∗
s :
∗
X → RL
17.
アルゴリズム - Post-hoclogit adjustment
出力で調整する手法のロジット調整版
ほぼ式(8)そのまま
argmax
exp(w
Φ(x))/π =
y∈[L] y
T
y
τ
argmax
f
(x) −
y∈[L] y τ ⋅ logπ
(9)
y
ここで であり はclass prior の推定量(訓練データの出現割合でよい
っぽい)
はスケール係数(定数)
π ∈ Δ
Y π P(y)
τ 0
18.
アルゴリズム - logitadjusted softmax cross-entropy
softmax cross-entropyにロジット調整適用したやつ
pairwise margin lossを提案
ℓ(y, f(x)) = α ⋅
y log[1 + e ⋅
y =y
′
∑ Δ
yy′
e ] (11)
(f
(x)−f
(x))
y′ y
ここでlabel weights であり
α 0 Δ
=
yy′ log
π
y
π
y′





![アルゴリズム - Notations
sample size:
#labels:
labels:
instance (features):
sample:
unknown distribution over ×
model:
misclassification error:
surrogate loss (such as the softmax cross-entropy):
:
ℓ(y, f(x)) = log[ e ] −
y ∈[L]
′
∑ f
(x)
y′
f
(x) =
y log[1 + e ] (1)
y =y
′
∑ f
(x)−f
(x)
y′ y
N
L
Y = [L] = 1, 2, ..., L
X
S = (x
, y
) ∼
n n n=1
N
PN
P X Y
f : X → RL
P
(y ∈
x,y / argmax
f
(x))
y ∈Y
′ y′
ℓ Y × R →
L
R](https://image.slidesharecdn.com/long-taillearningvialogitadjustment-211229095016/75/Long-tail-learning-via-logit-adjustment-6-2048.jpg)
![アルゴリズム - Balanced Error
これを最小化する
BER = P
(y ∈
L
1
y∈[L]
∑ x∣y / argmax f
(x))
y ∈Y
′ y′](https://image.slidesharecdn.com/long-taillearningvialogitadjustment-211229095016/75/Long-tail-learning-via-logit-adjustment-7-2048.jpg)
![アルゴリズム - 従来手法
現行の対処方法は以下の3つに分類できる
1. モデルへの入力に対してなんやかんやするやつ(e.g. over- or under-sampling)
Kubat and Matwin, 1997, Chawla et al., 2002, Wallace et al., 2011, Mikolov et
al., 2013, Mahajan et al., 2018, Yin et al., 2018
2. モデルの出力をなんやかんやするやつ (e.g. post-hoc correction of the decision
threshold)
Fawcett and Provost, 1996, Collell et al., 2016] or weights [Kim and Kim, 2019,
Kang et al., 2020
3. モデルの中でなんやかんやするやつ (e.g. modifying the loss function)
Xie and Manski, 1989, Morik et al., 1999, Cui et al., 2019, Zhang et al., 2017,
Cao et al., 2019, Tan et al., 2020
今回扱うのは2.と3.](https://image.slidesharecdn.com/long-taillearningvialogitadjustment-211229095016/75/Long-tail-learning-via-logit-adjustment-8-2048.jpg)
![アルゴリズム - 出力で調整する手法達
Post-hoc weight normalization
argmax
w
Φ(x)/ν =
y∈[L] y
T
y
τ
argmax
f
(x)/ν (3)
y∈[L] y y
τ
クラスを計算する際(argmaxする際)に で除算して補正
重みの正規化によって少数ラベルの貢献度を上げる
in Kim and Kim, 2019、 Ye et al., 2020
in Kang et al., 2020
と が相関する傾向にあることを利用している
τ 0
νy
ν =
y P(y)
ν =
y ∣∣w
∣∣
y 2
∣∣w
∣∣
y 2 P(y)](https://image.slidesharecdn.com/long-taillearningvialogitadjustment-211229095016/75/Long-tail-learning-via-logit-adjustment-9-2048.jpg)
![アルゴリズム - モデルの中で調整する手法達
Loss modification (Xie and Manski, 1989、 Morik et al., 1999の提案手法)
ℓ(y, f(x)) = log[1 +
P(y)
1
e ] (4)
y =y
′
∑ f
(x)−f
(x)
y′ y
損失計算の際に調整(式(4)では で調整)
バランシングは分離可能な設定では最小限の効果しかない
訓練損失をゼロにする手法は重み付けをしても必然的に最適な状態が保たれる
(Byrd and Lipton, 2019)(らしい)
直感的に分離境界を支配的なクラスに近づけることが望ましい
P(y)](https://image.slidesharecdn.com/long-taillearningvialogitadjustment-211229095016/75/Long-tail-learning-via-logit-adjustment-10-2048.jpg)
![アルゴリズム - モデルの中で調整する手法達
式(4)以外の例2選
hinge lossにクラスごとのマージンを加える(Cao et al., 2019)
少数の正例 と任意の負例 との間にマージンが作れる
ℓ(y, f(x)) = [1 + e e ] (5)
y =y
′
∑ δ
y f
(x)−f
(x)
y′ y
クラスごとのマージンをソフトマックスクロスエントロピーに追加 (Tan et al.,
2020)
勾配を調整するのが目的
は を単調増加変換したもの
ℓ(y, f(x)) = [1 + e e ] (6)
y =y
′
∑ δ
y′ f
(x)−f (x)
y′ y
y y =
′
y
δ ∝
y P(y)−1/4
δ ≤
y 0 P(y)](https://image.slidesharecdn.com/long-taillearningvialogitadjustment-211229095016/75/Long-tail-learning-via-logit-adjustment-11-2048.jpg)



![アルゴリズム - 提案手法
平衡誤差を最小化することでベイズ最適解を得たい
になるようにしたい
バランス調整された推定量 を推定するモデルを訓練すればよい(式(7))
平衡誤差を最小化することにおいてFisher Consistentがある
ロジット調整(logit adjustment)は明確な統計的根拠を持っている(Appendix参
照)
argmax
f
(x) =
y∈[L] y
∗
argmax
P (y∣x) =
y∈[L]
bal
argmax
P(x∣y) (7)
y∈[L]
そして推定量の対数を式(8)のように修正
式(8)は以下を仮定
class-probabilitiesを
where
bal ∗ ∗
f ∈
∗ argmin
BER(f)
f:X→RL
P (y∣x)
bal
P (y∣x) ∝
bal
P(y∣x)/P(y)
P(y∣x) ∝ exp(s
(x))
y
∗
s :
∗
X → RL](https://image.slidesharecdn.com/long-taillearningvialogitadjustment-211229095016/75/Long-tail-learning-via-logit-adjustment-16-2048.jpg)
![アルゴリズム - Post-hoc logit adjustment
出力で調整する手法のロジット調整版
ほぼ式(8)そのまま
argmax
exp(w
Φ(x))/π =
y∈[L] y
T
y
τ
argmax
f
(x) −
y∈[L] y τ ⋅ logπ
(9)
y
ここで であり はclass prior の推定量(訓練データの出現割合でよい
っぽい)
はスケール係数(定数)
π ∈ Δ
Y π P(y)
τ 0](https://image.slidesharecdn.com/long-taillearningvialogitadjustment-211229095016/75/Long-tail-learning-via-logit-adjustment-17-2048.jpg)
![アルゴリズム - logit adjusted softmax cross-entropy
softmax cross-entropyにロジット調整適用したやつ
pairwise margin lossを提案
ℓ(y, f(x)) = α ⋅
y log[1 + e ⋅
y =y
′
∑ Δ
yy′
e ] (11)
(f
(x)−f
(x))
y′ y
ここでlabel weights であり
α 0 Δ
=
yy′ log
π
y
π
y′](https://image.slidesharecdn.com/long-taillearningvialogitadjustment-211229095016/75/Long-tail-learning-via-logit-adjustment-18-2048.jpg)










![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)




![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Flow-based Deep Generative Models](https://cdn.slidesharecdn.com/ss_thumbnails/20190307-190328024744-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontransformer20210709zhangxin-210709021501-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会] Spectral Norm Regularization for Improving the Generalizability of De...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhackspectralnorm1-170907072536-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]"CyCADA: Cycle-Consistent Adversarial Domain Adaptation"&"Learning Se...](https://cdn.slidesharecdn.com/ss_thumbnails/20180803dlakuzawa-180803003349-thumbnail.jpg?width=640&height=640&fit=bounds)














![[DSO] Machine Learning Seminar Vol.2 Chapter 3](https://cdn.slidesharecdn.com/ss_thumbnails/chapter3slides-200226170409-thumbnail.jpg?width=640&height=640&fit=bounds)








![[読会]A critical review of lasso and its derivatives for variable selection und...](https://cdn.slidesharecdn.com/ss_thumbnails/acriticalreviewoflassoanditsderivativesforvariableselectionunderdependenceamongcovariates-211229094859-thumbnail.jpg?width=640&height=640&fit=bounds)
![[読会]Logistic regression models for aggregated data](https://cdn.slidesharecdn.com/ss_thumbnails/logisticregressionmodelsforaggregateddata-211229094148-thumbnail.jpg?width=640&height=640&fit=bounds)


![[読会]Causal transfer random forest combining logged data and randomized expe...](https://cdn.slidesharecdn.com/ss_thumbnails/causaltransferrandomforest-combiningloggeddataandrandomizedexperimentsforrobustprediction-211229095227-thumbnail.jpg?width=640&height=640&fit=bounds)







![[読会]P qk means-_ billion-scale clustering for product-quantized codes](https://cdn.slidesharecdn.com/ss_thumbnails/pqk-meansbillion-scaleclusteringforproduct-quantizedcodes-211229095124-thumbnail.jpg?width=640&height=640&fit=bounds)



![[読会]Themis decentralized and trustless ad platform with reporting integrity](https://cdn.slidesharecdn.com/ss_thumbnails/themisdecentralizedandtrustlessadplatformwithreportingintegrity-211229094342-thumbnail.jpg?width=640&height=640&fit=bounds)

