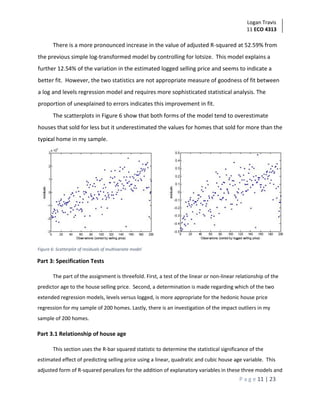
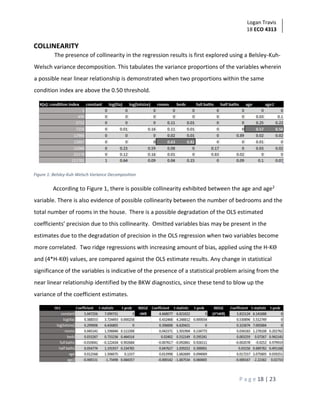
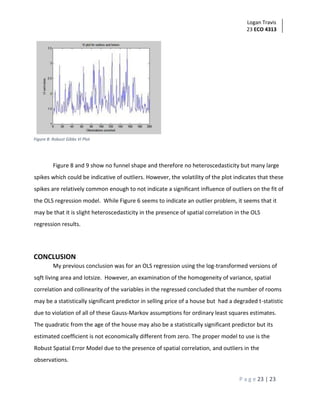
This document summarizes an analysis of home sale prices in Lucas County, Ohio using a sample of 200 homes. It describes fitting univariate regression models with selling price as the dependent variable and square footage as the independent variable, both in linear and log-transformed forms. Summary statistics are provided showing distributions of home characteristics. Regression results are presented, showing square footage is a statistically significant predictor of sale price, explaining around 40% of variation. Diagnotic plots reveal some outliers and tendency to over/underestimate for certain home sizes.