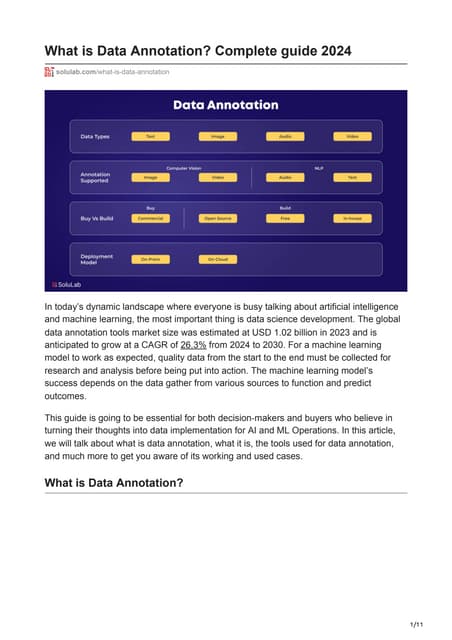
The document outlines seven innovative techniques for efficient data annotation in AI projects, including active learning, semi-supervised learning, and transfer learning, which enhance model training by optimizing data labeling. It also discusses collaborative annotation, gamification, AI-assisted annotation, and the importance of continuous feedback for improving accuracy and adaptability in the annotation process. These techniques aim to combine human and machine capabilities to streamline the data annotation workflow.