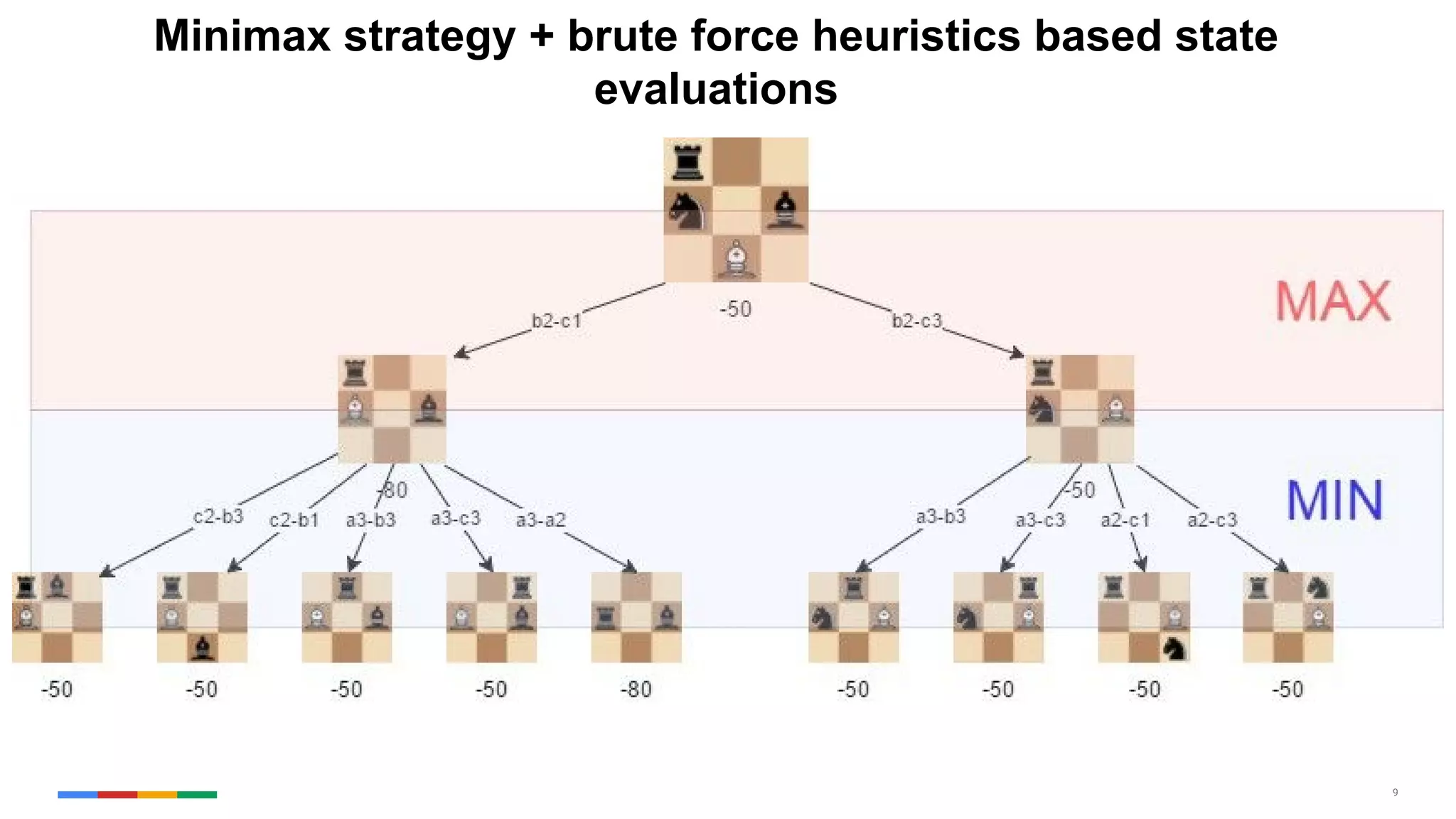
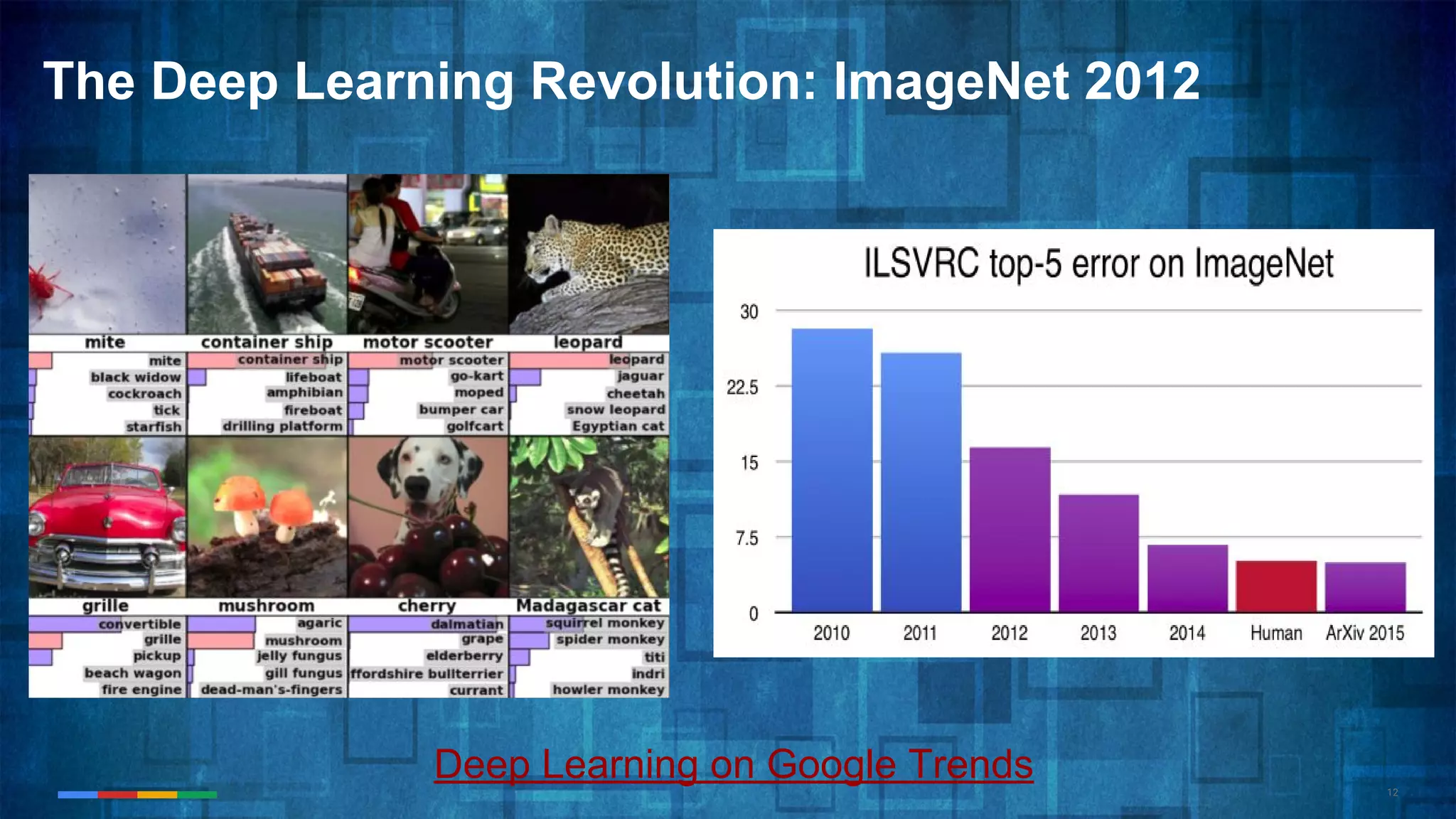
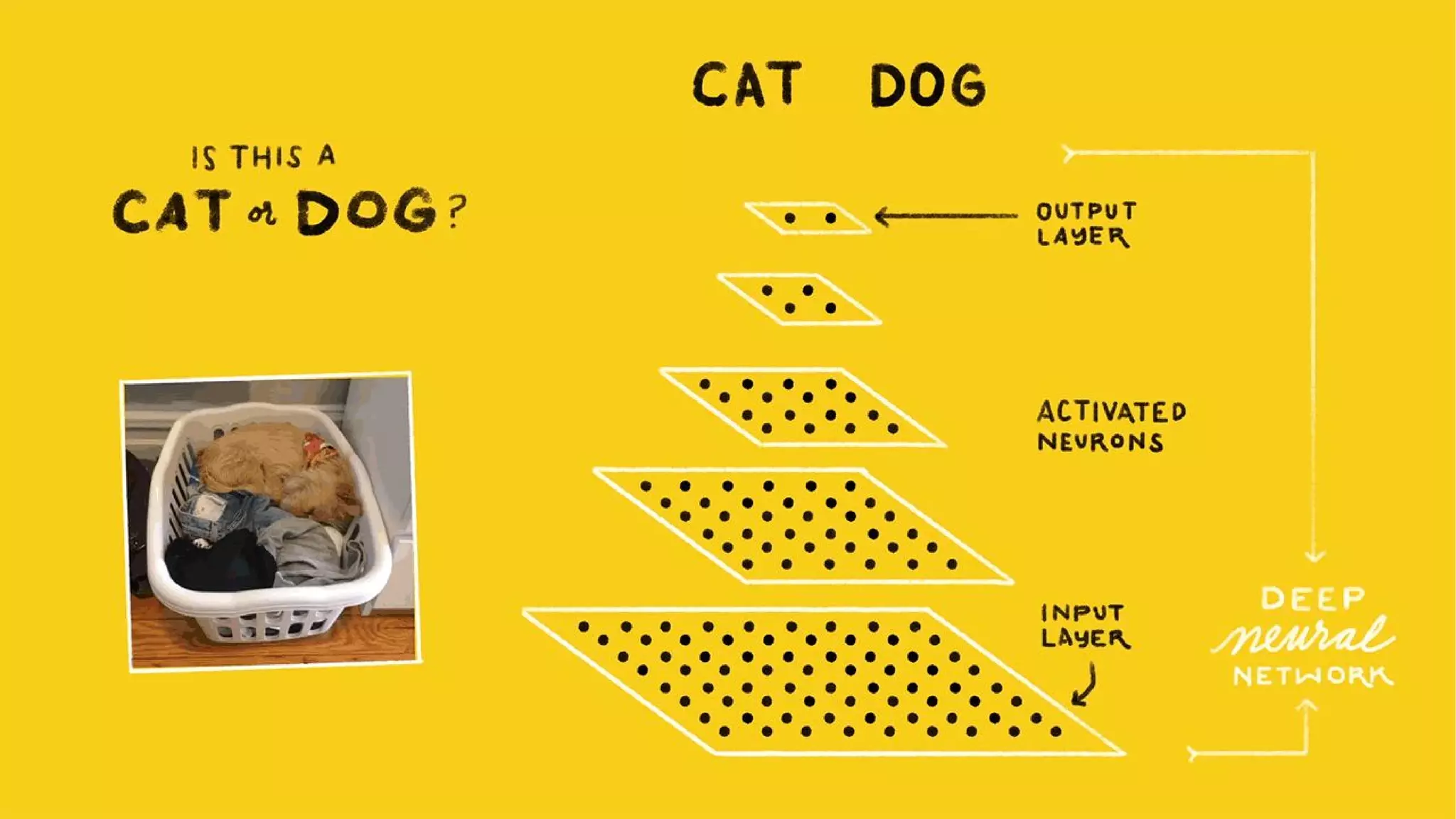
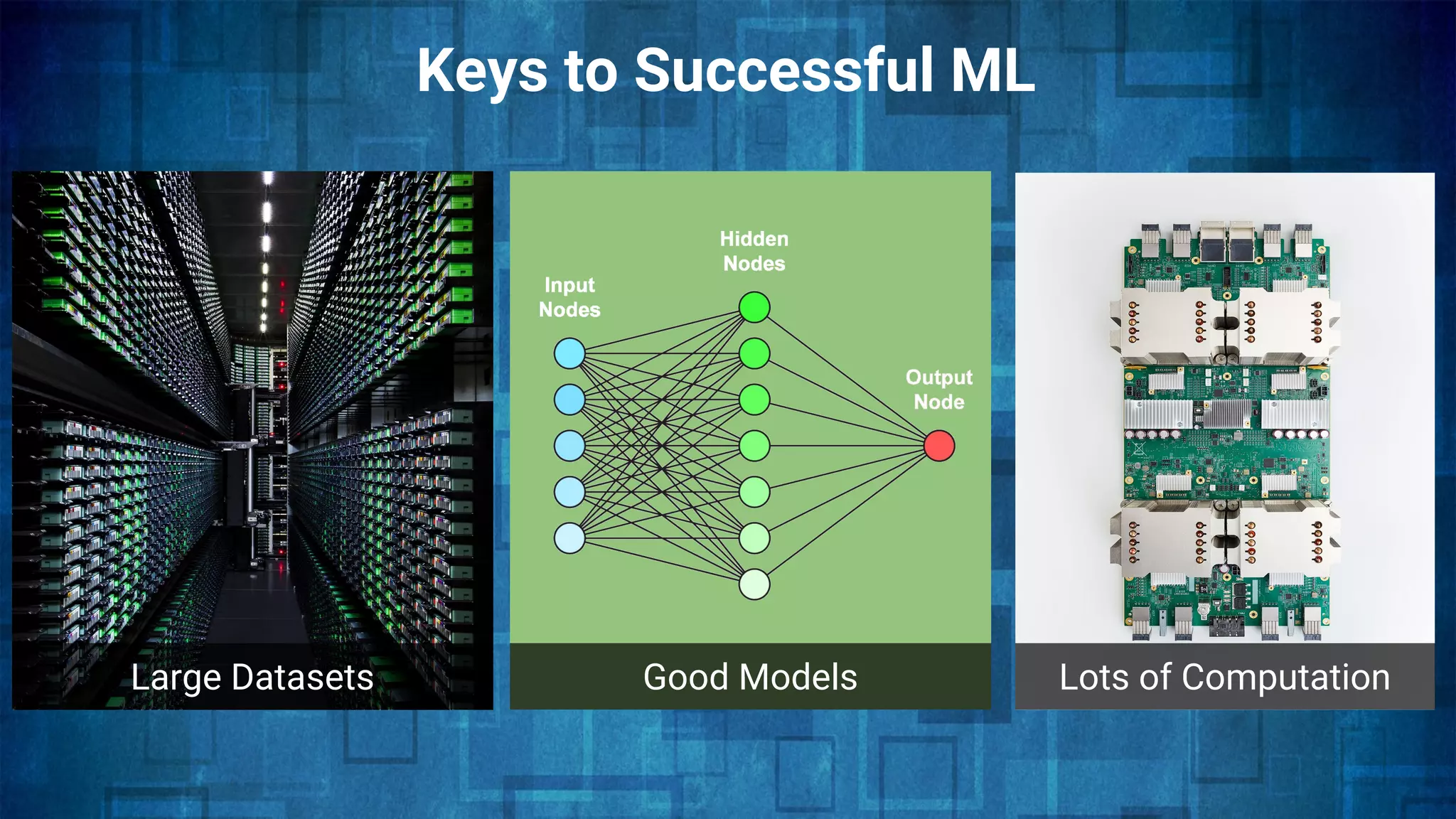
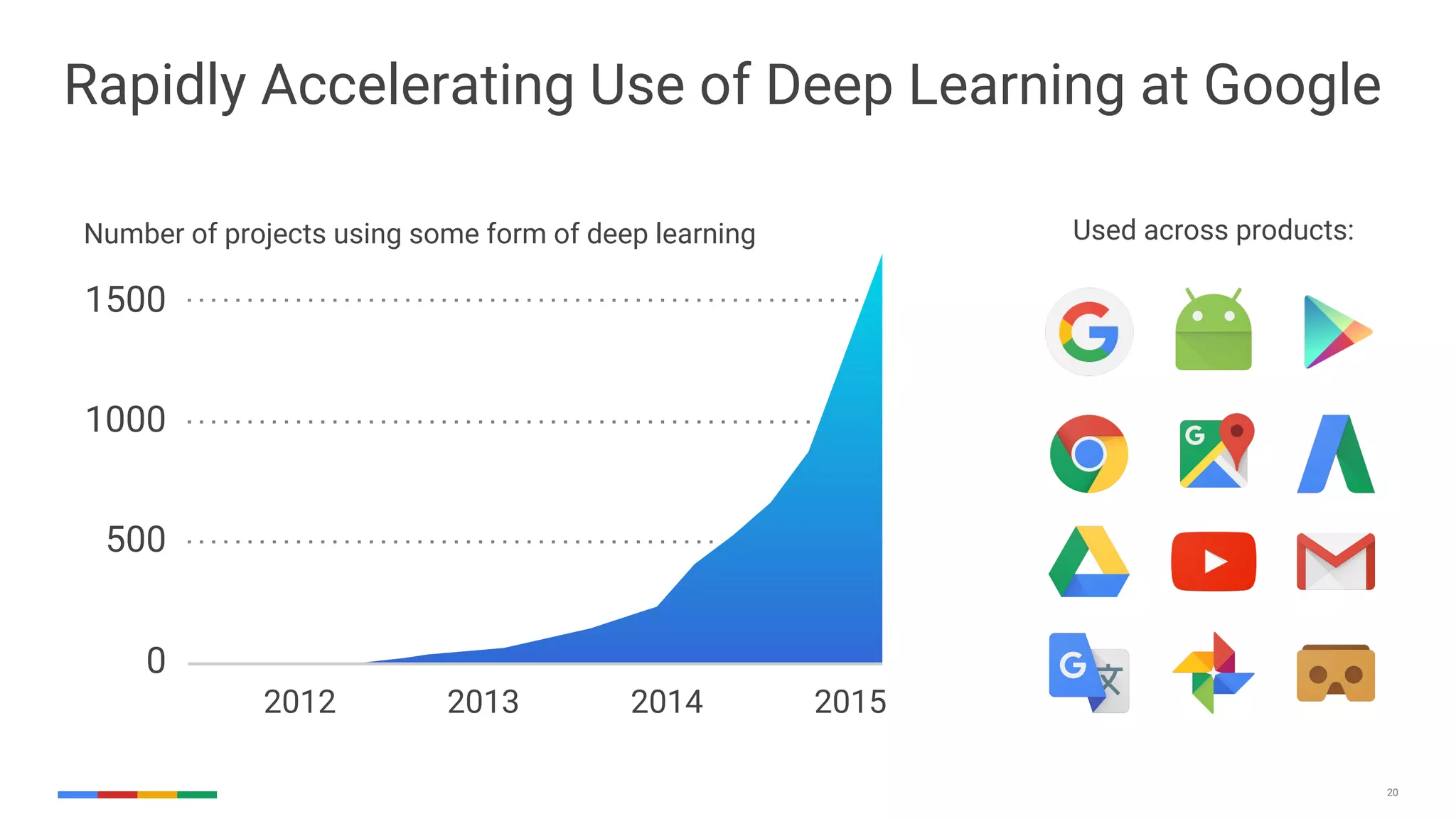
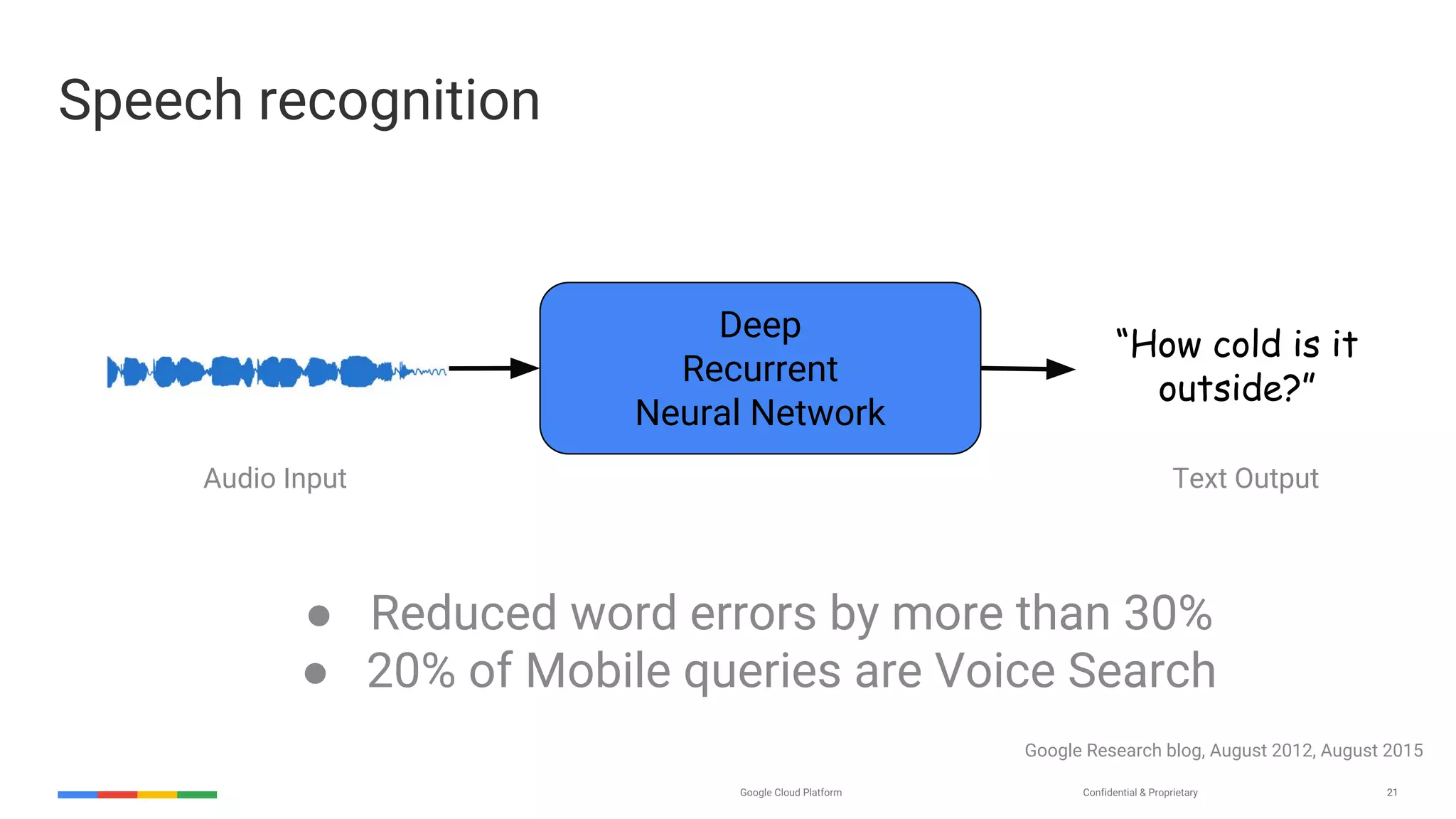
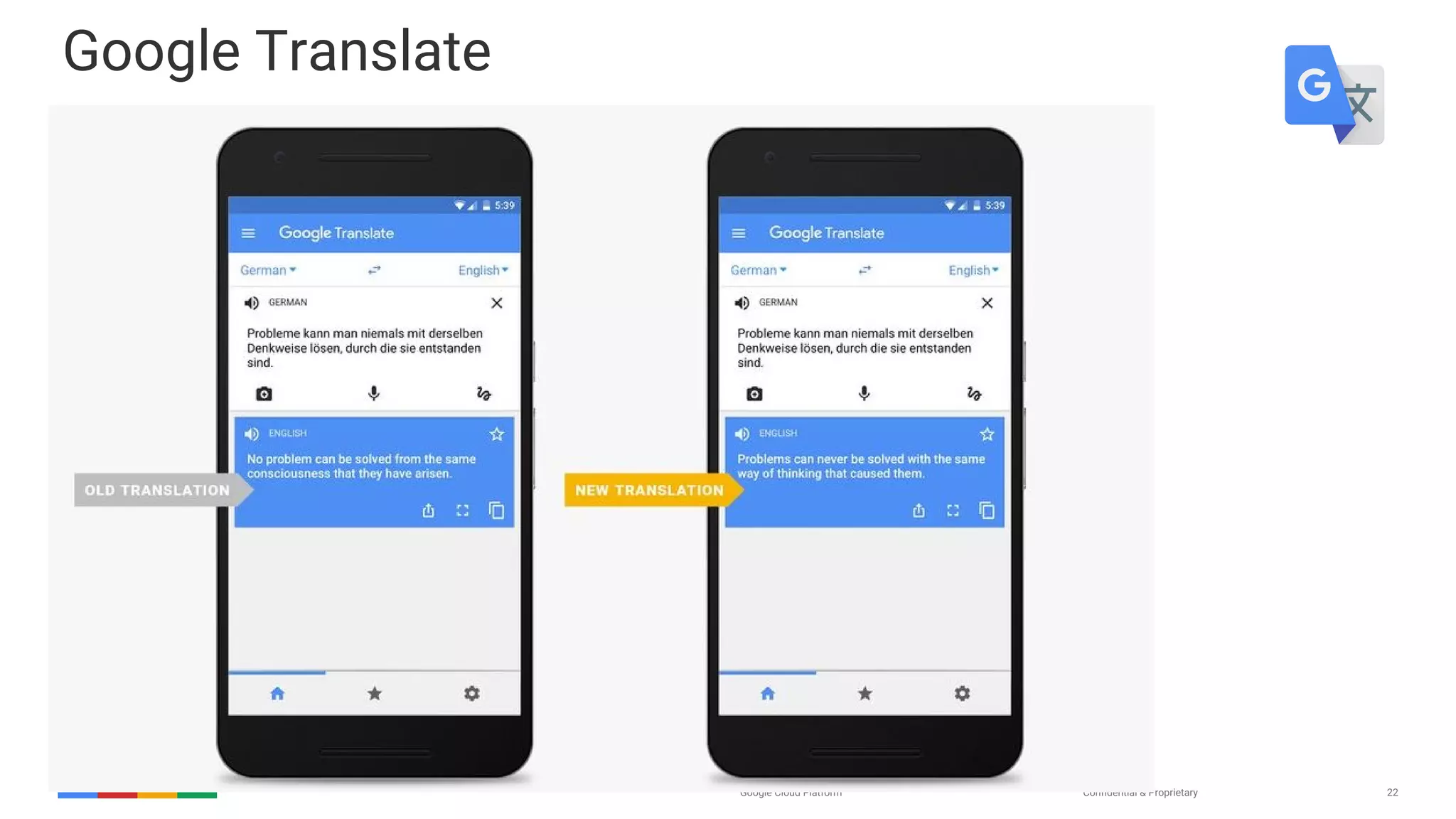
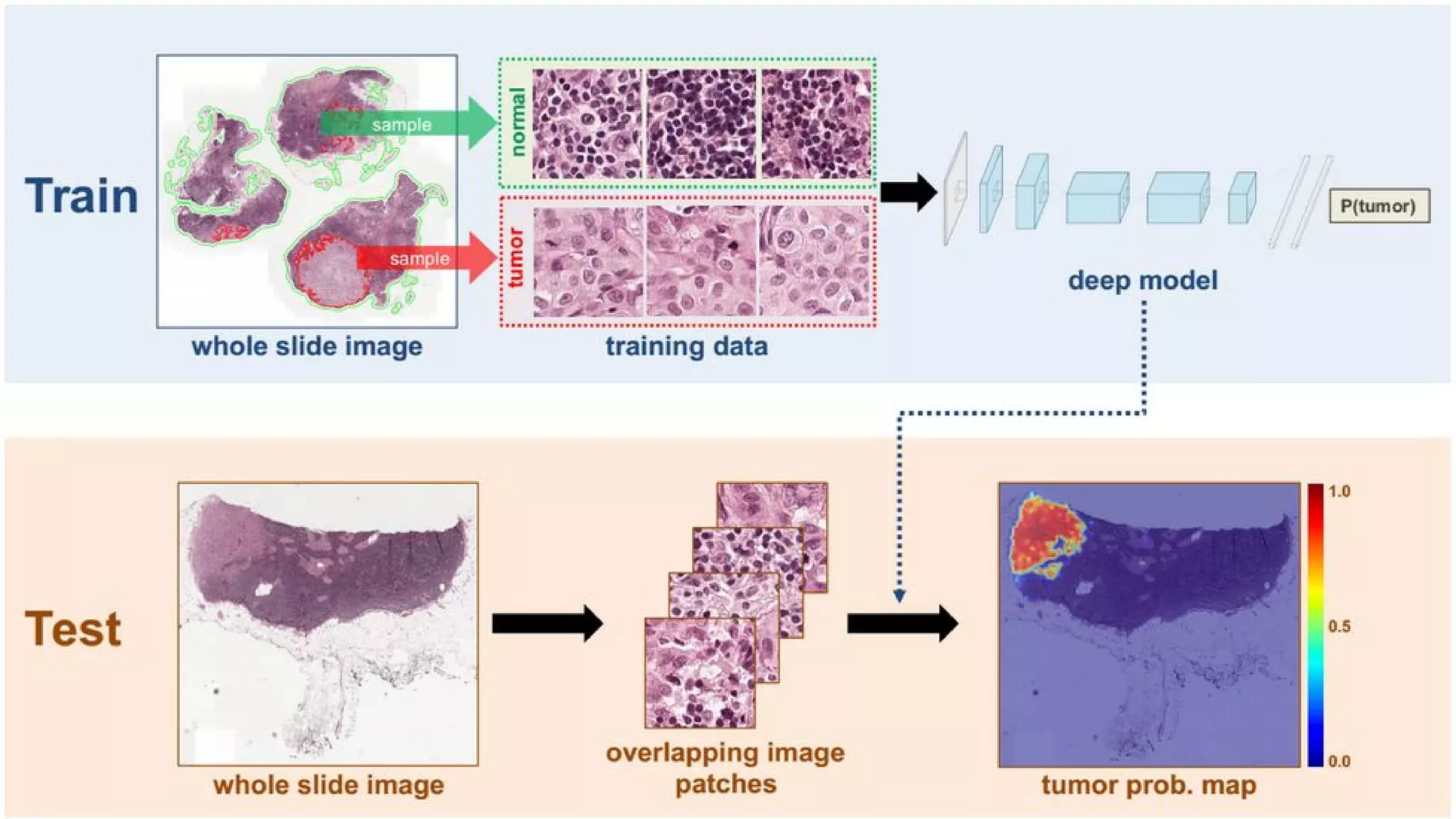
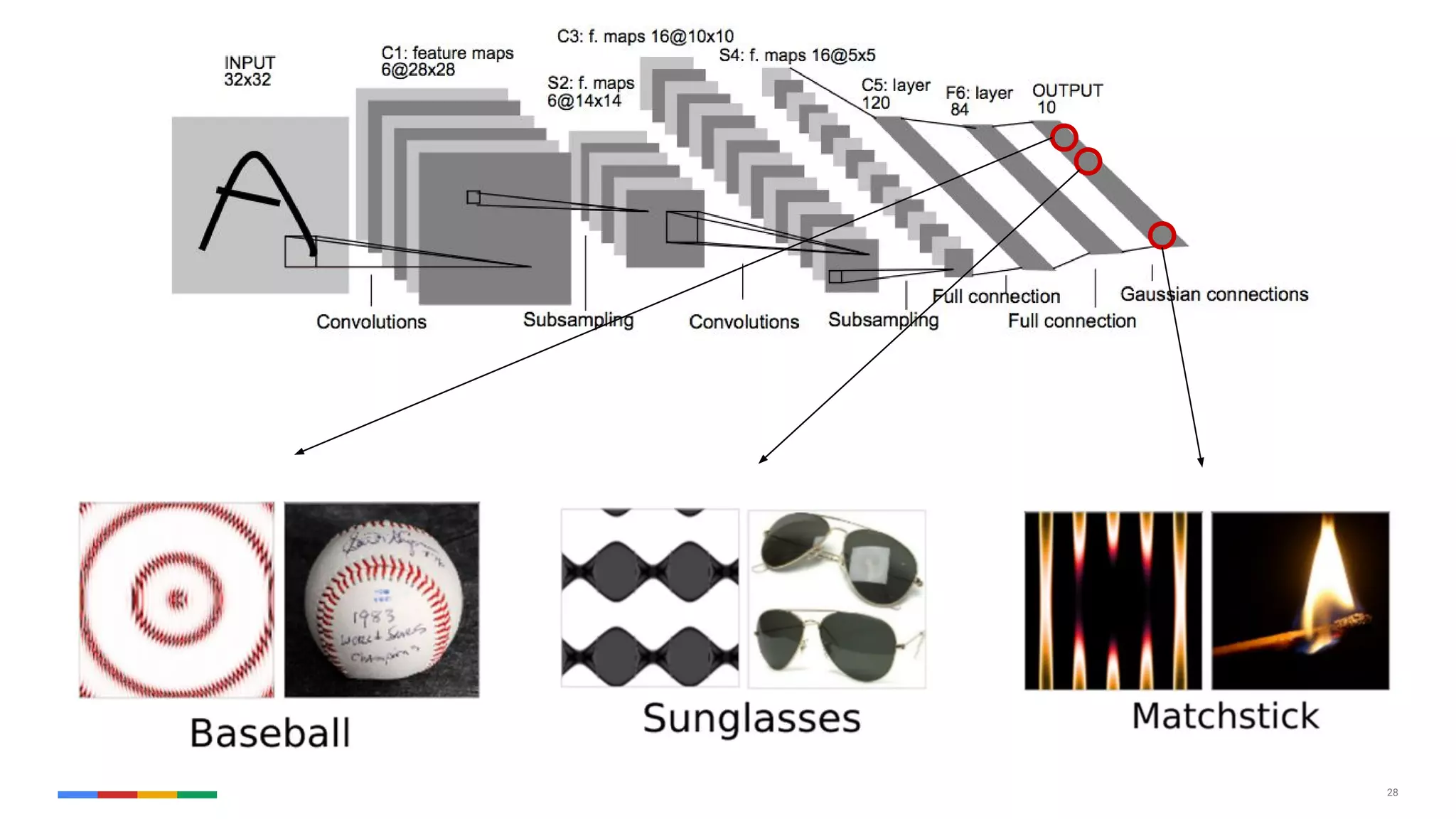
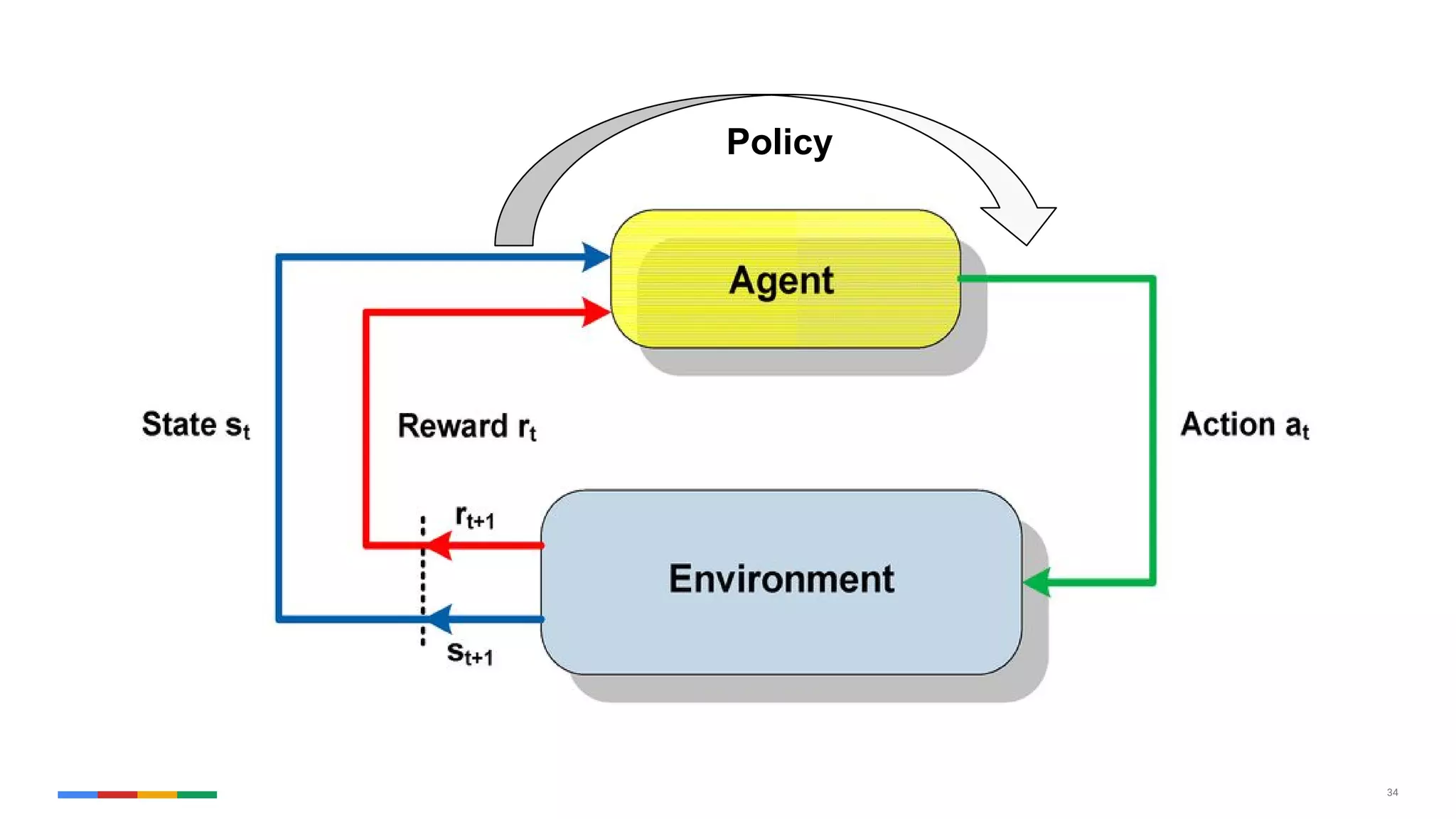
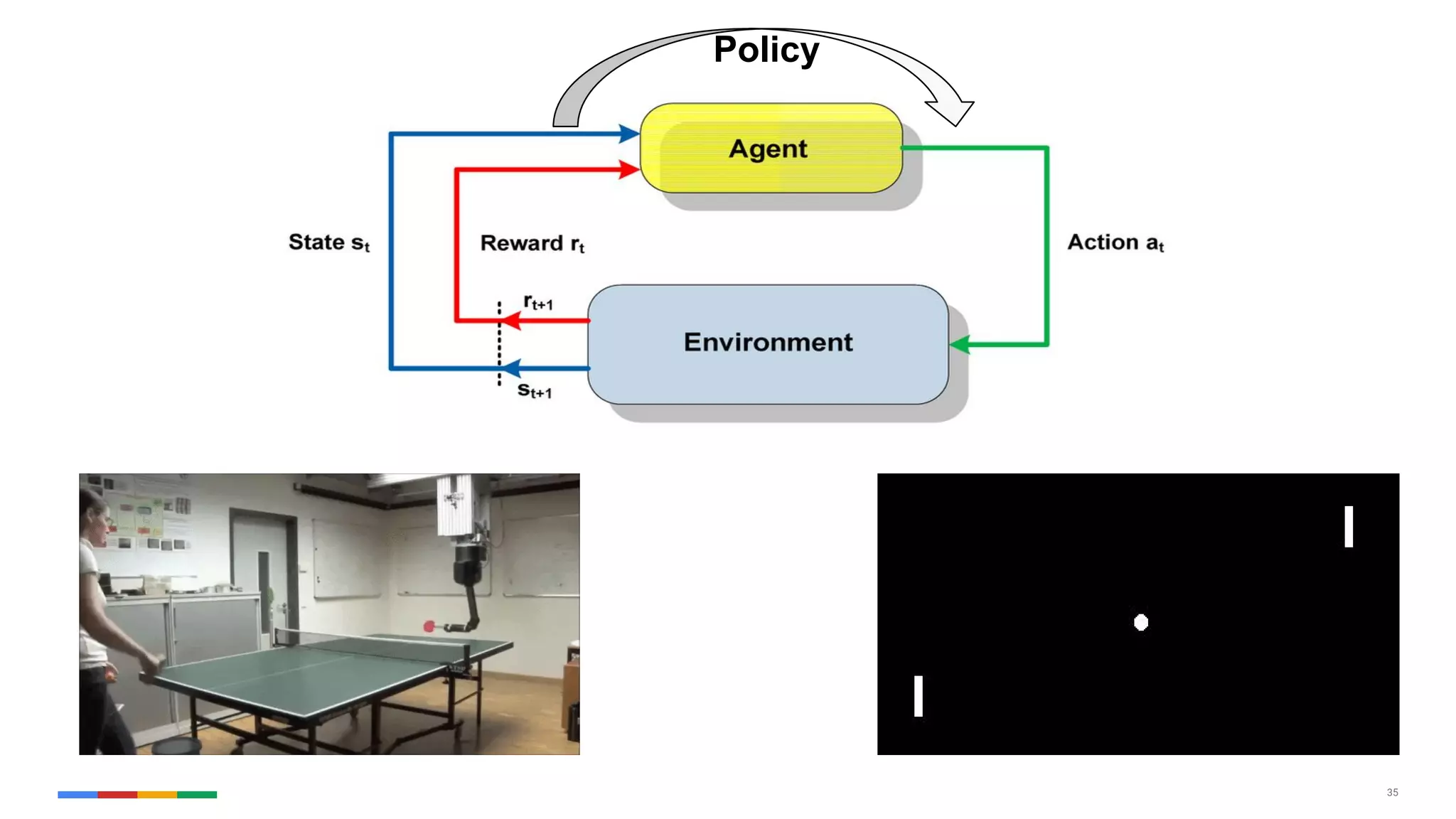
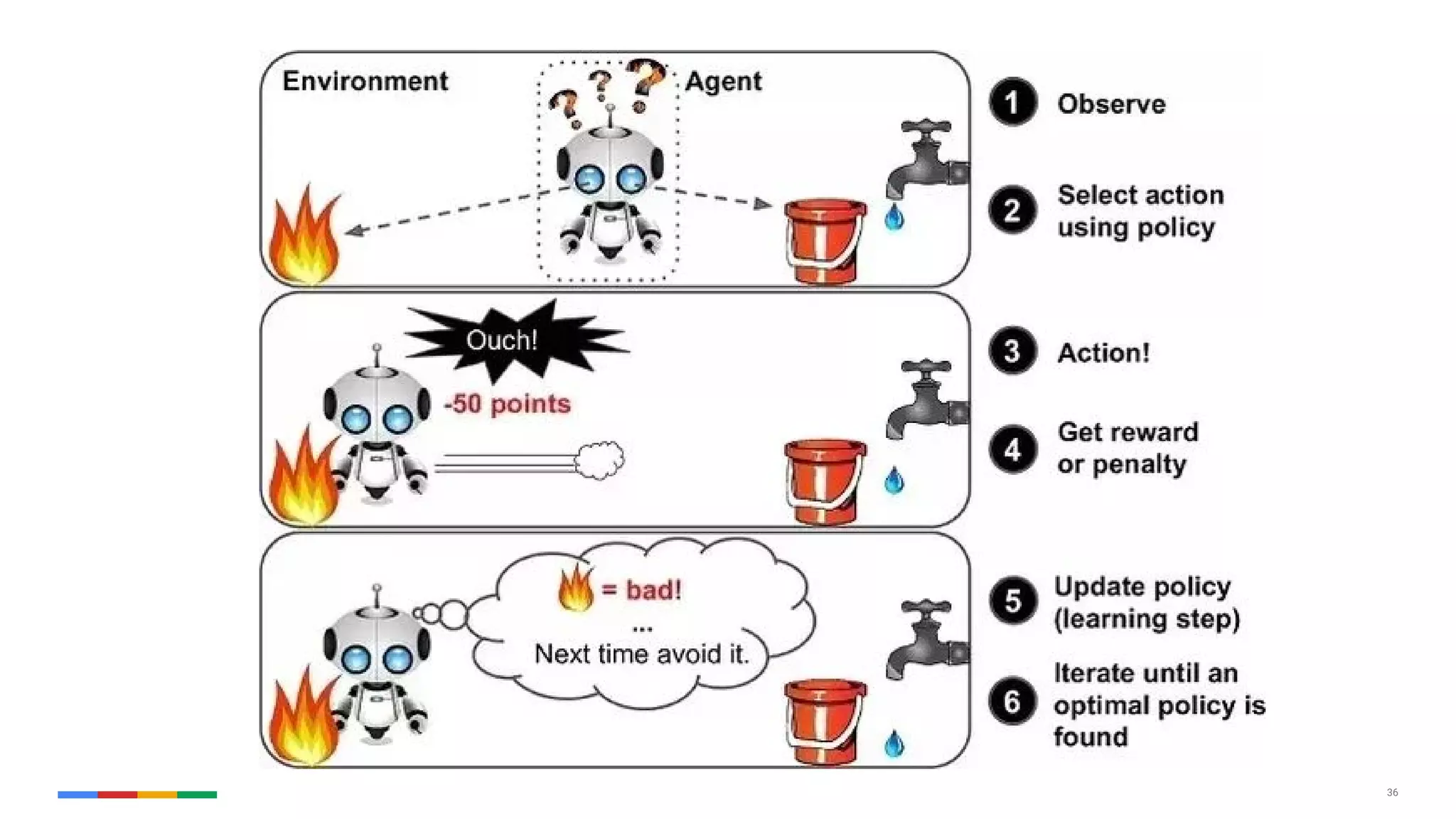
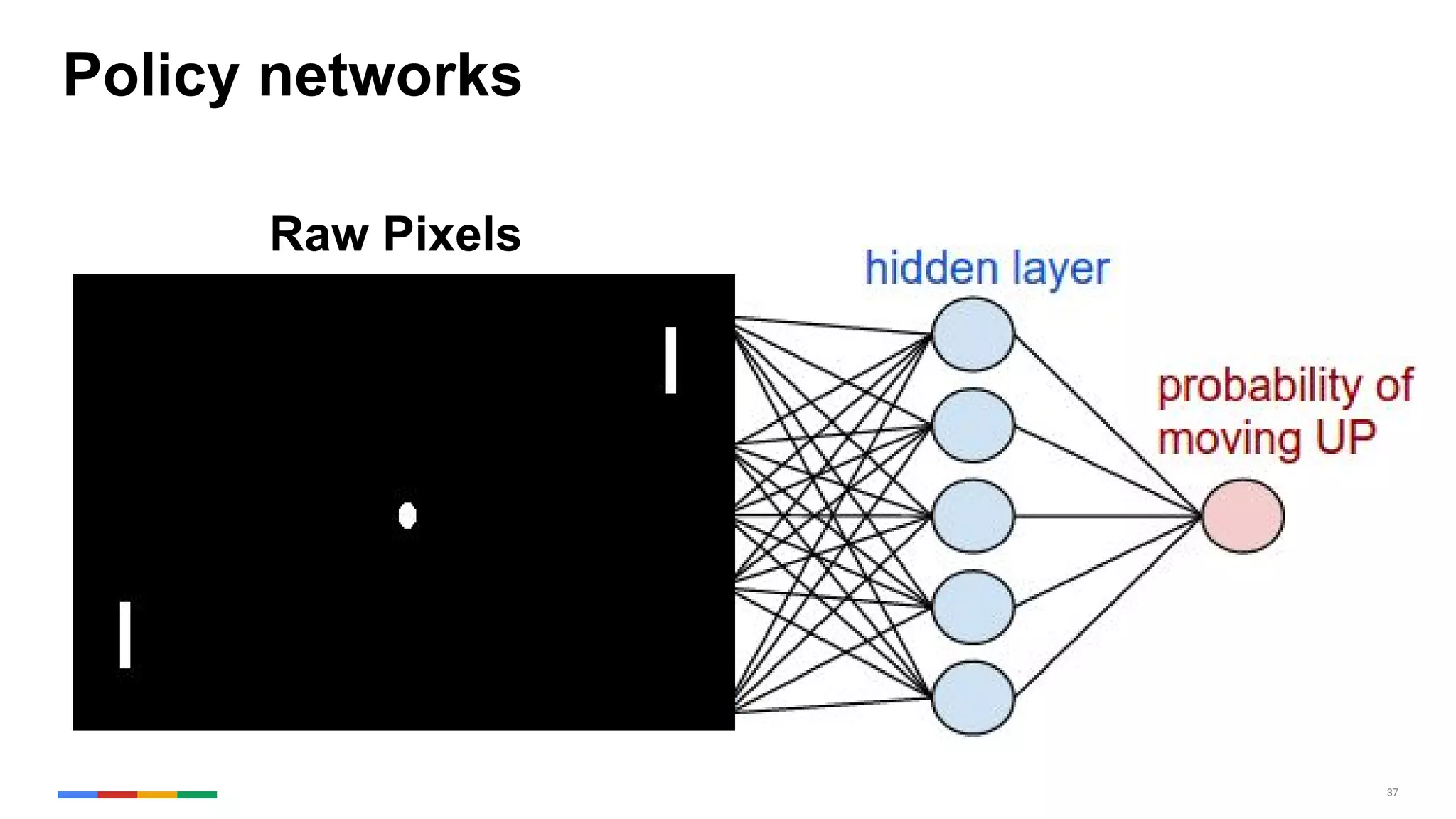
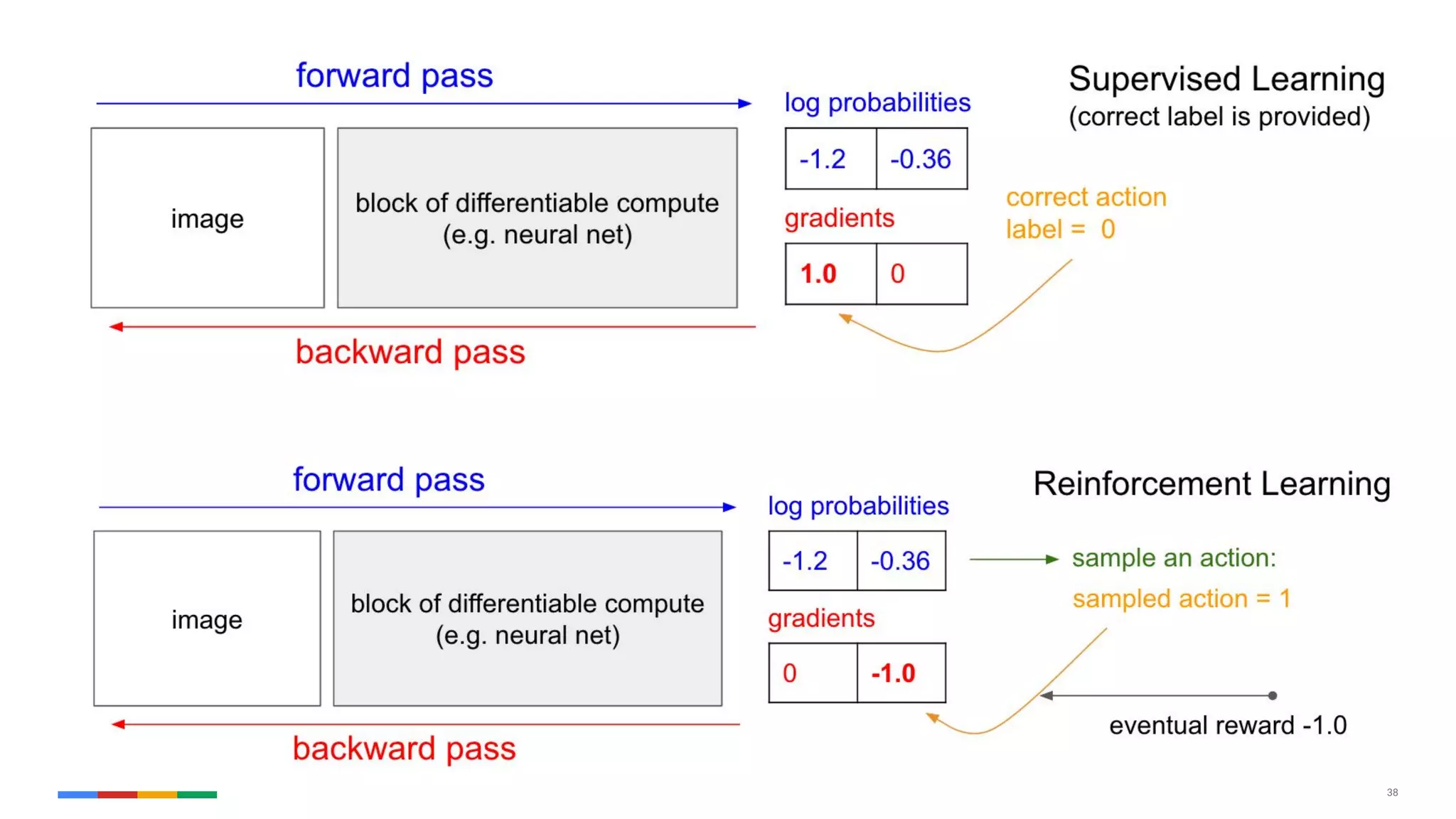
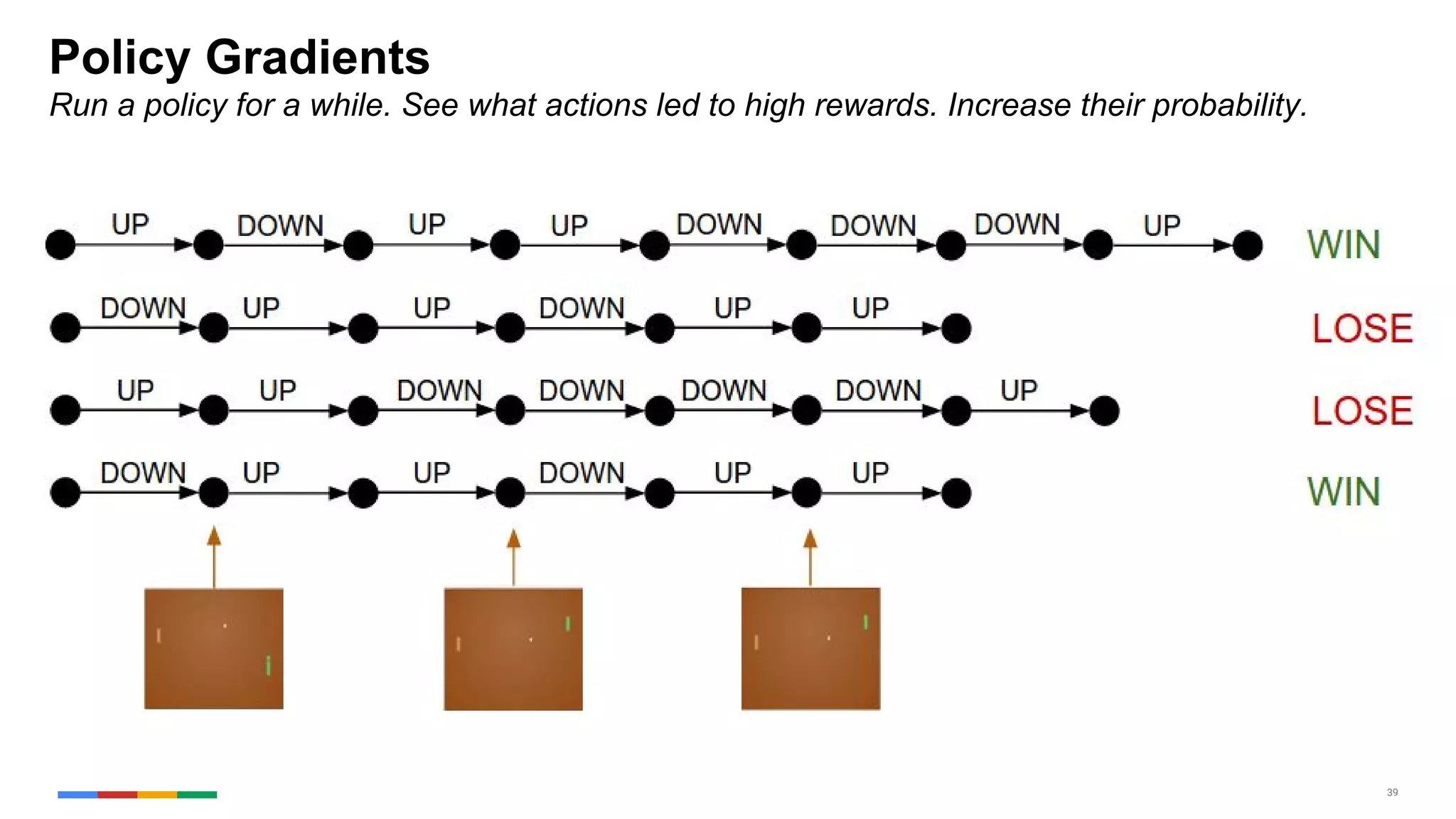
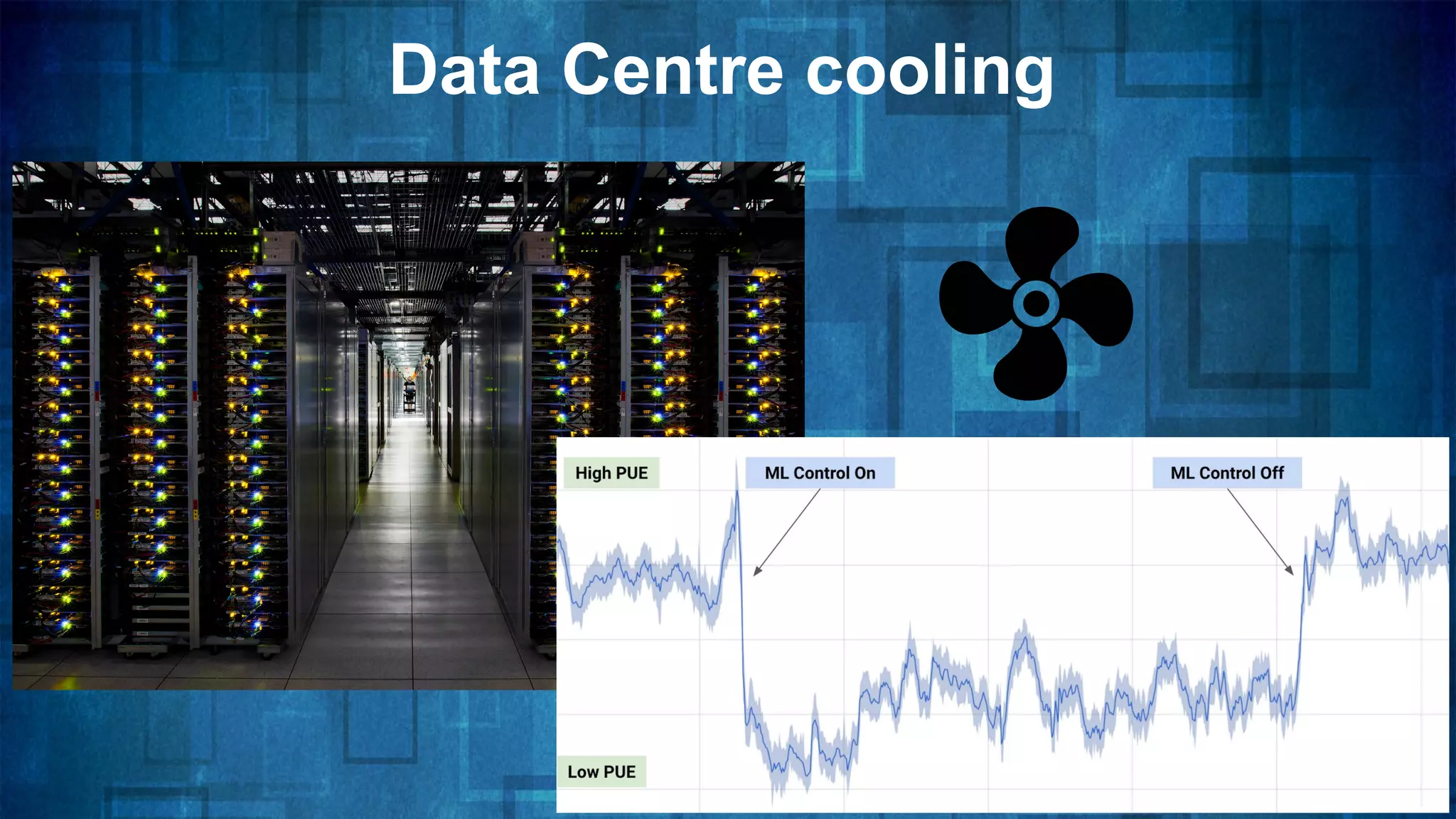
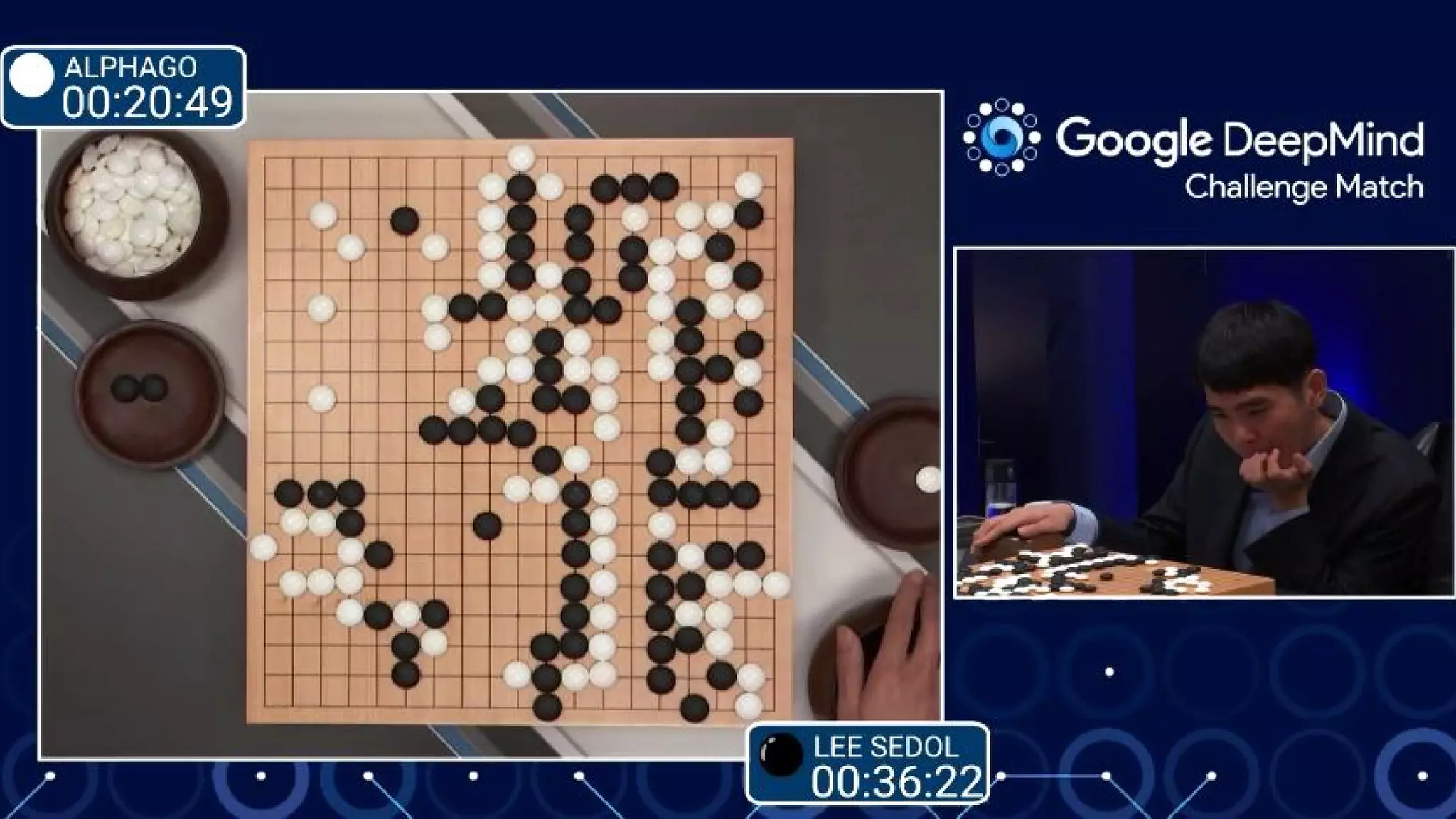
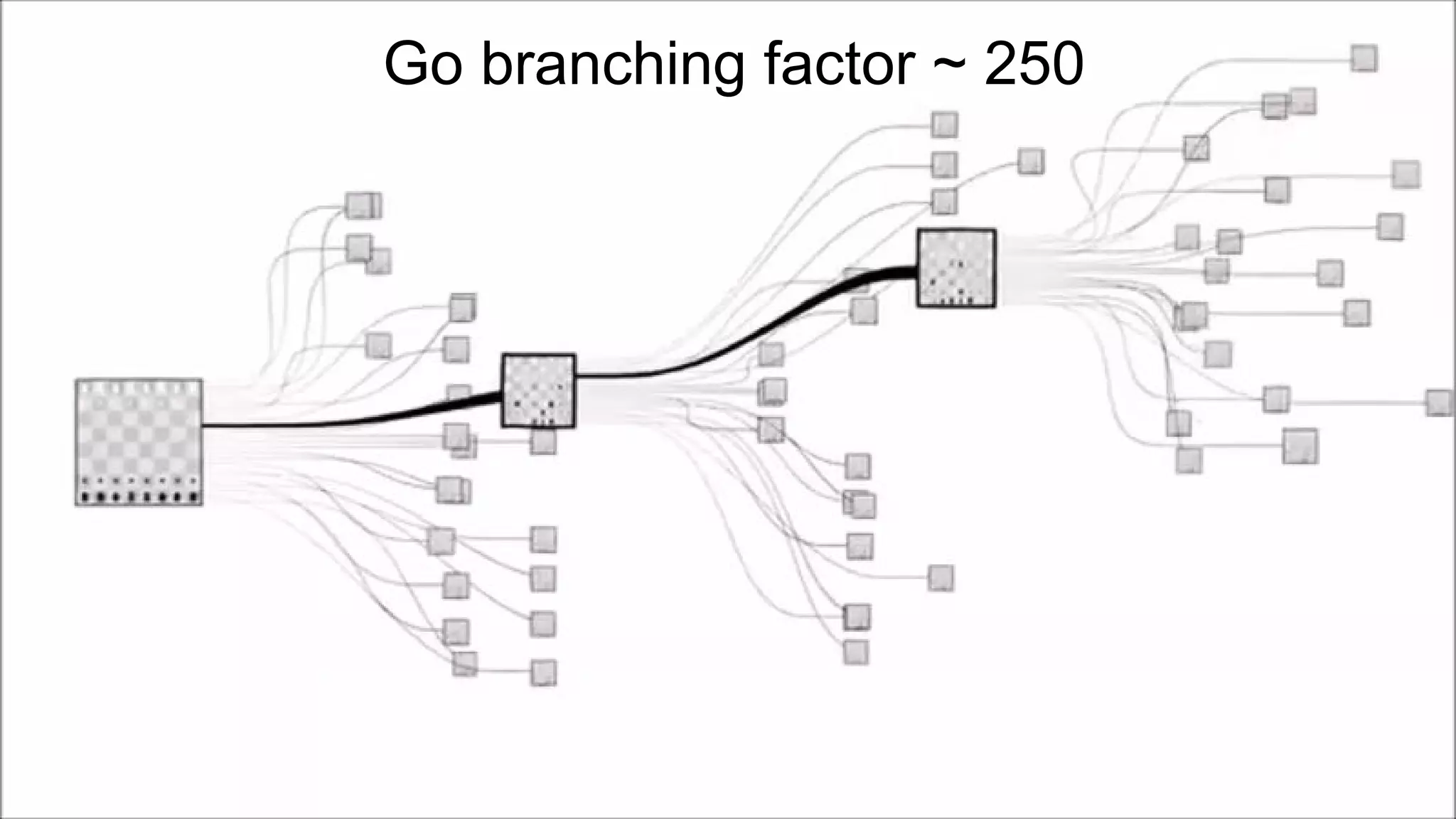
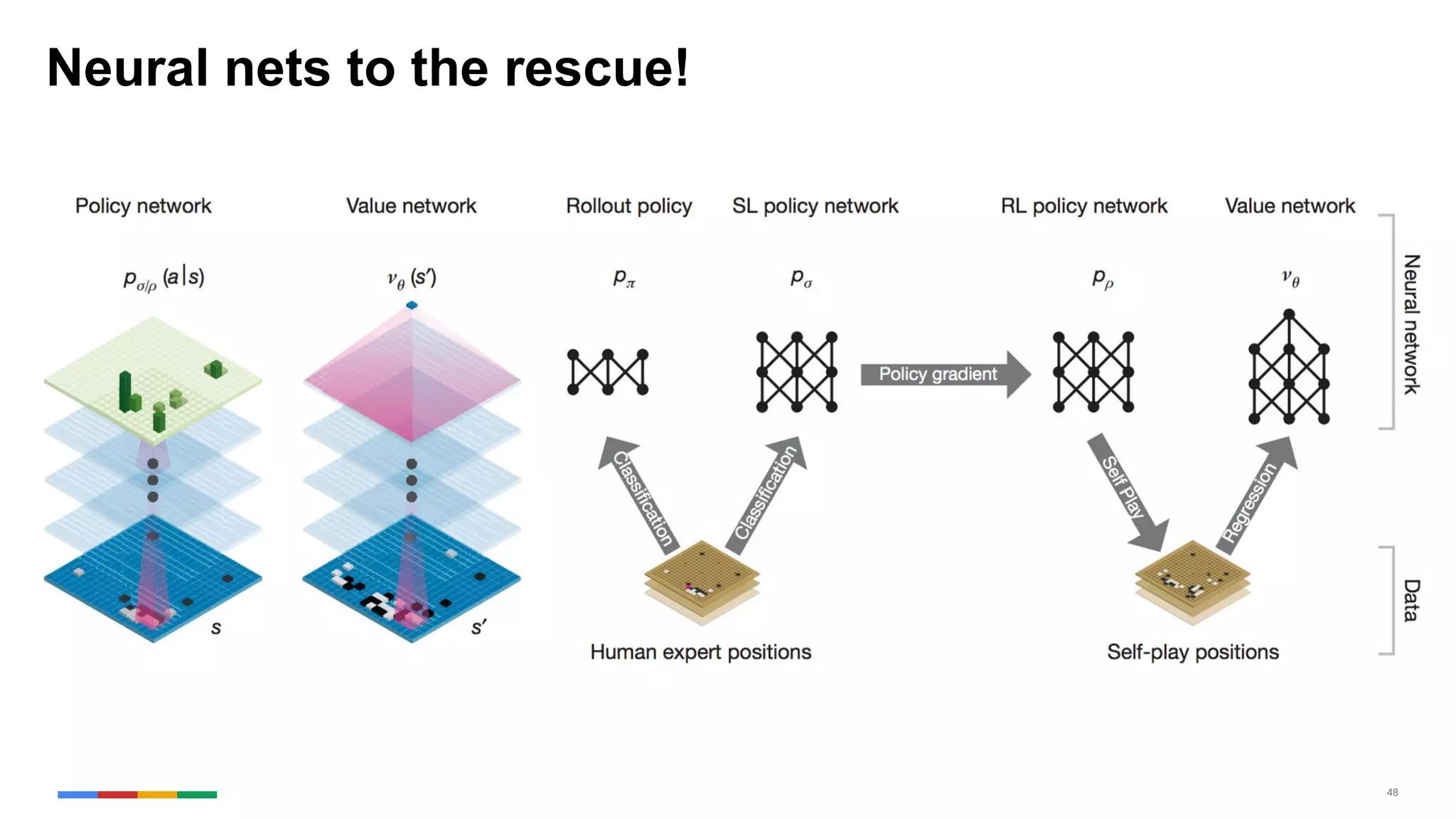
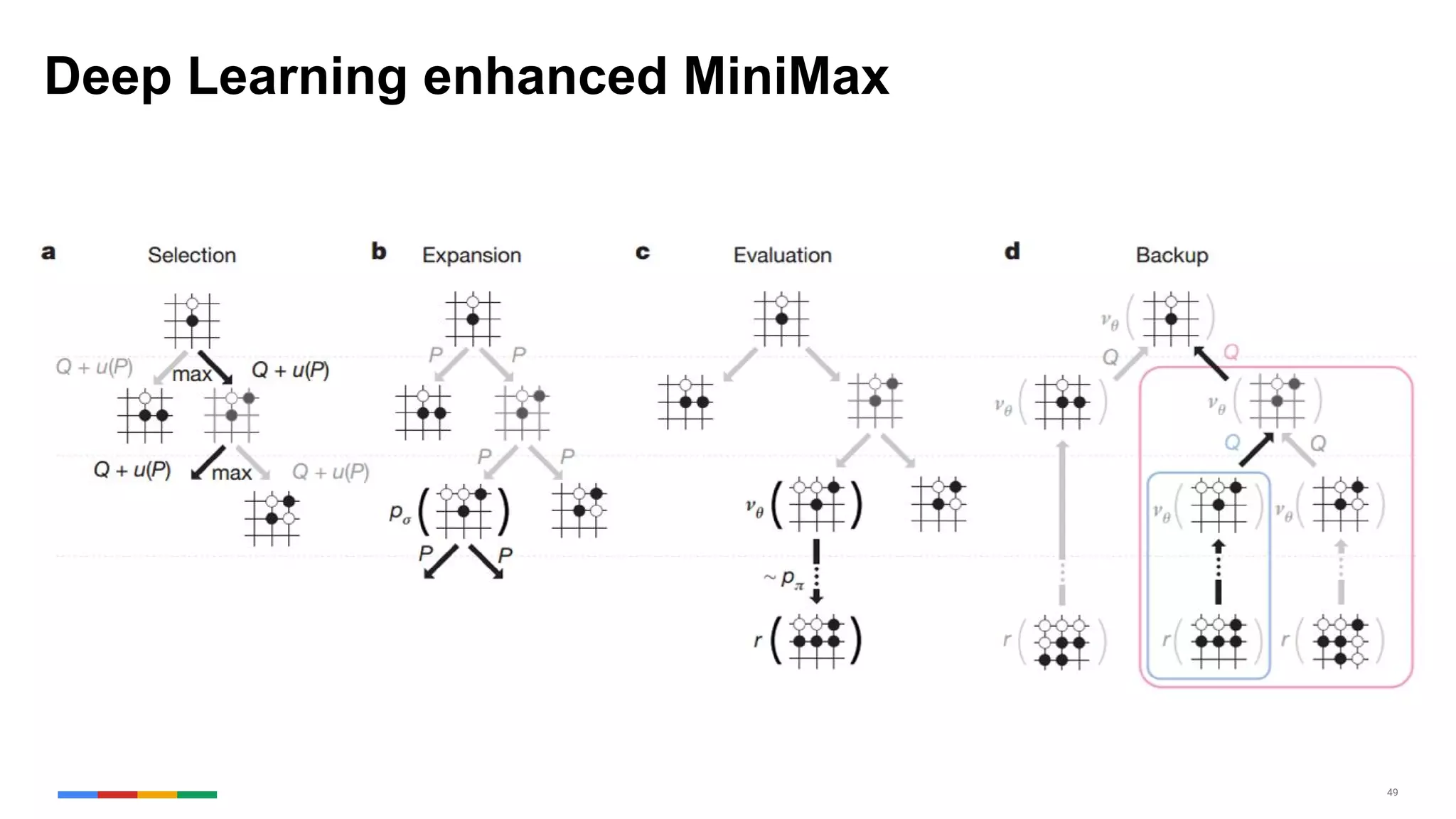
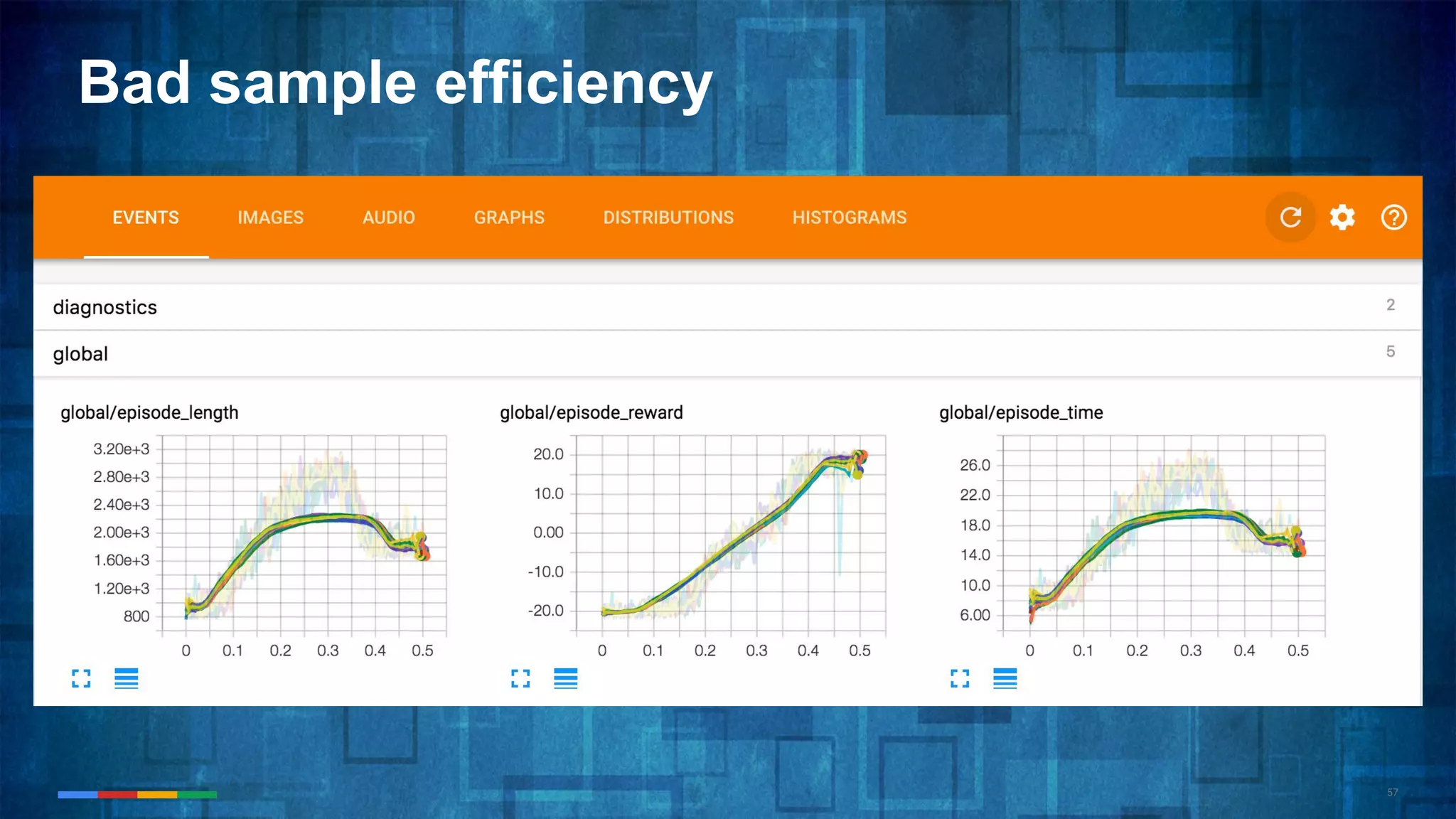
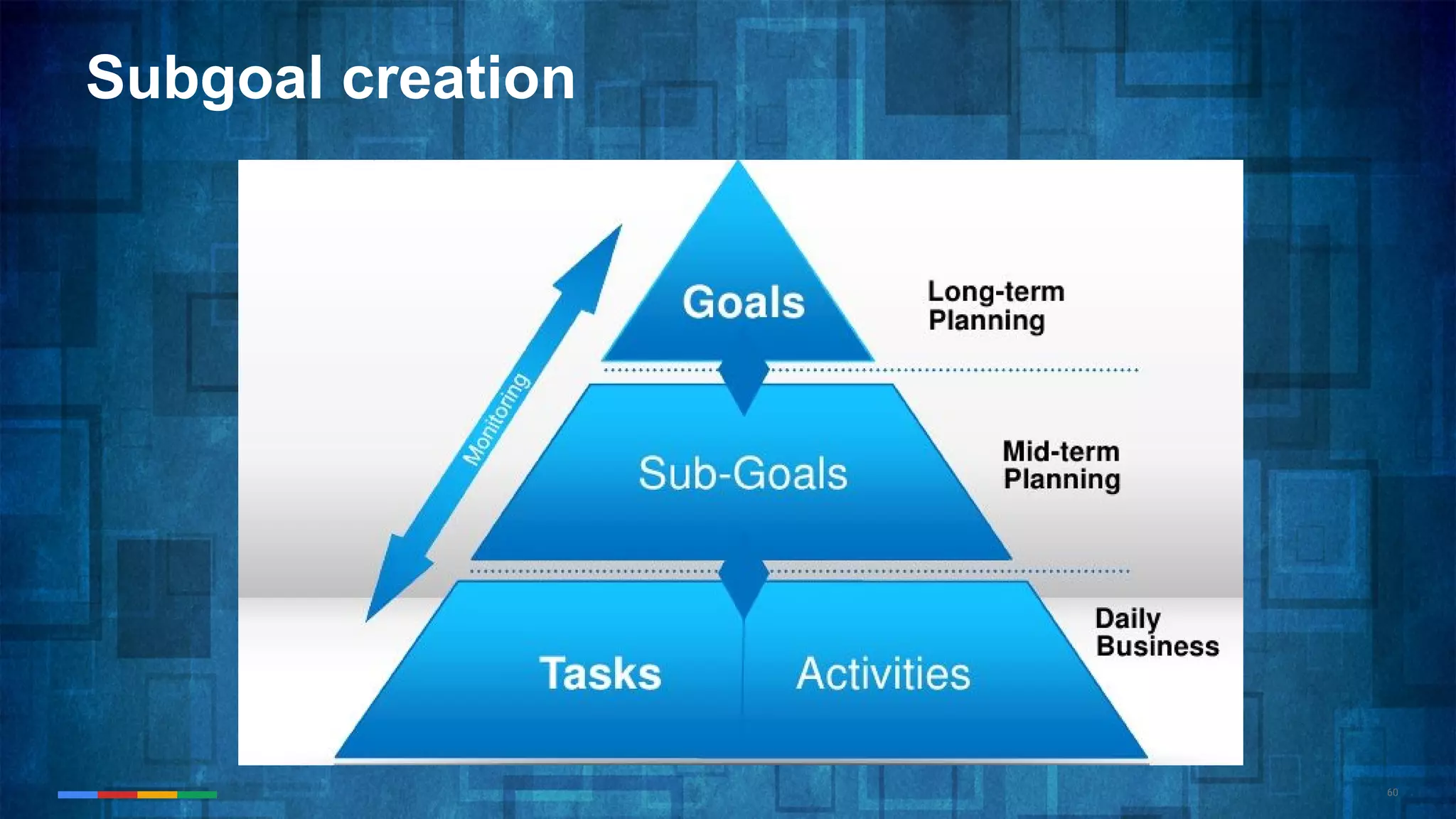
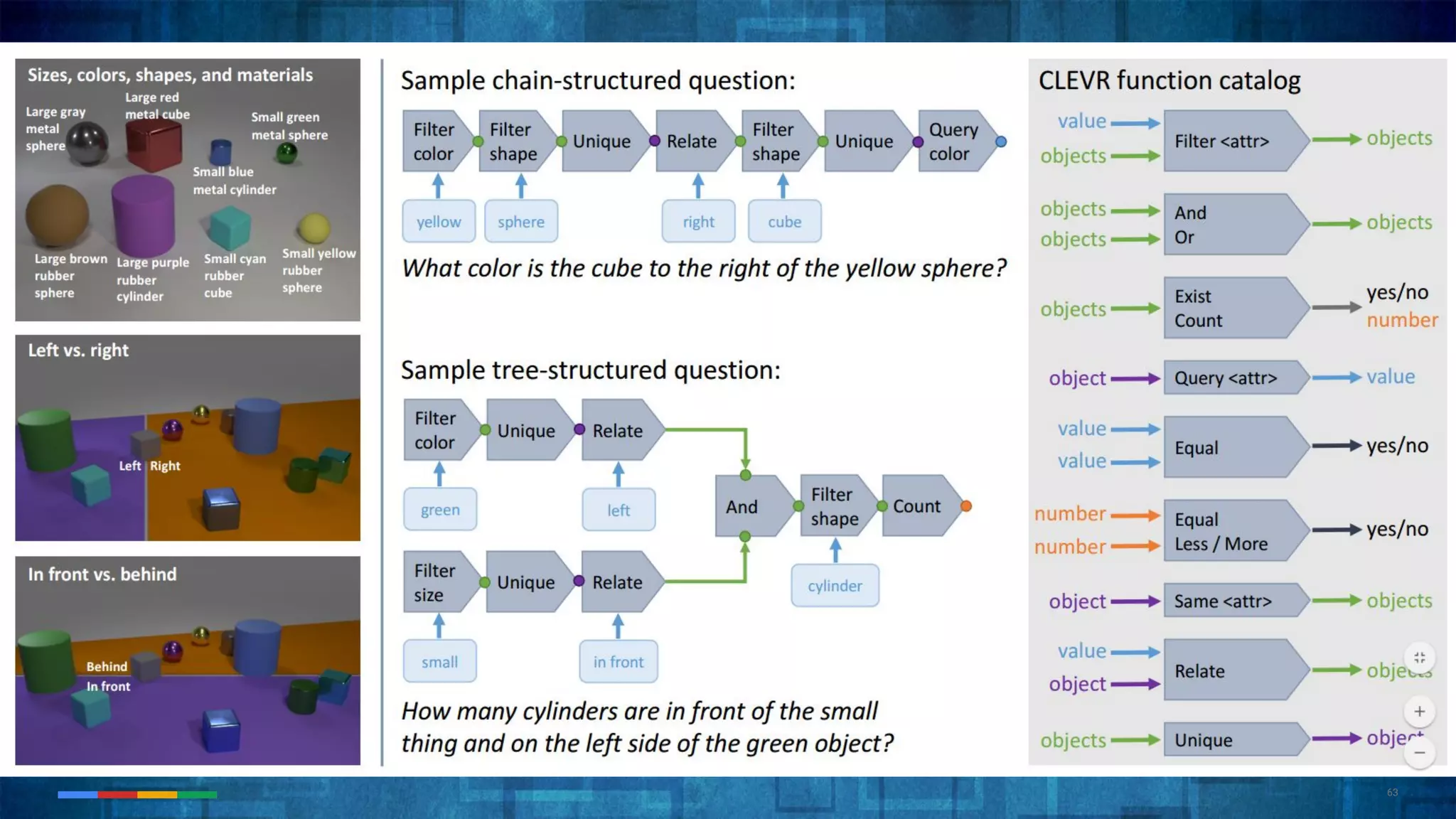
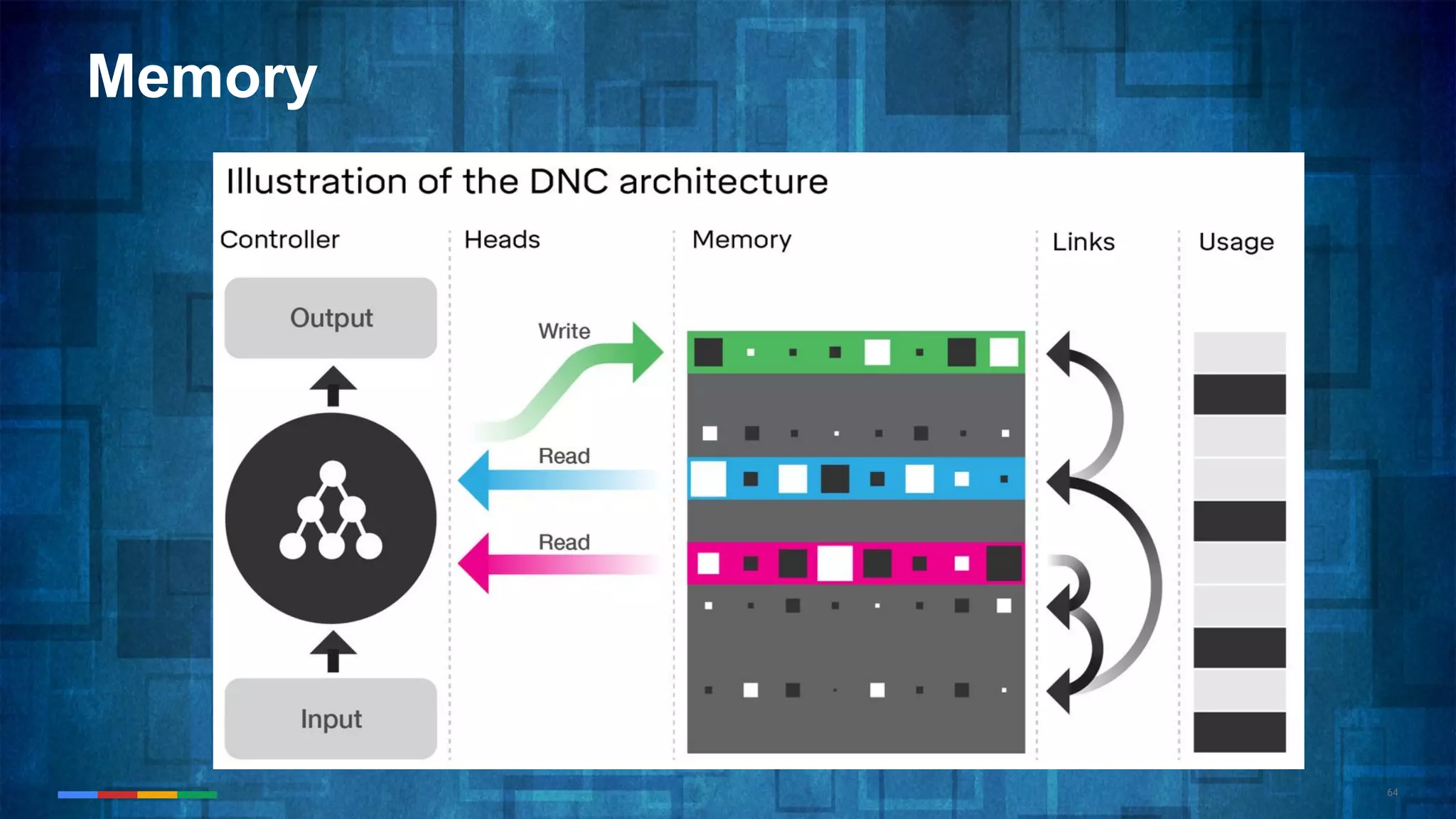
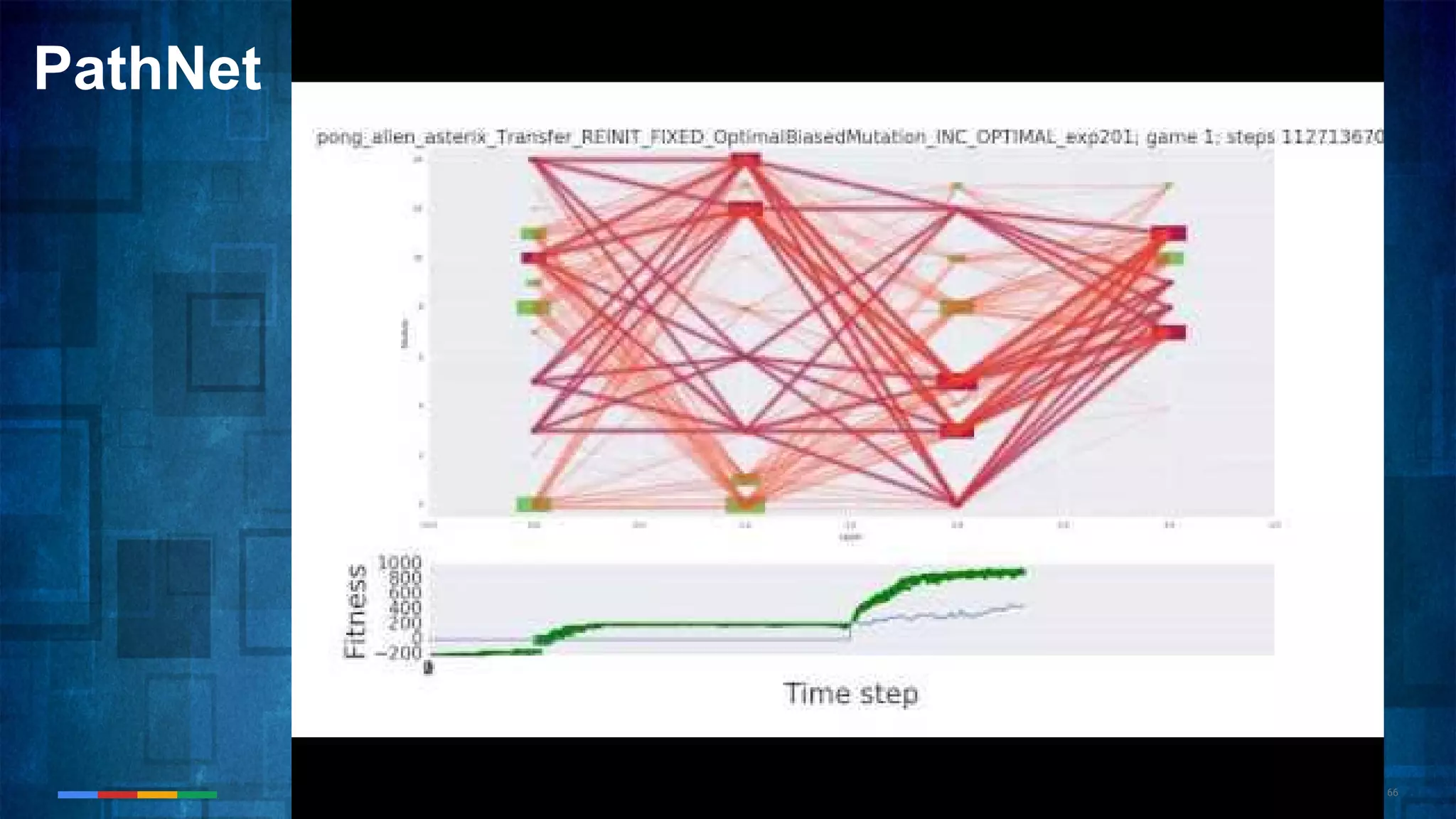
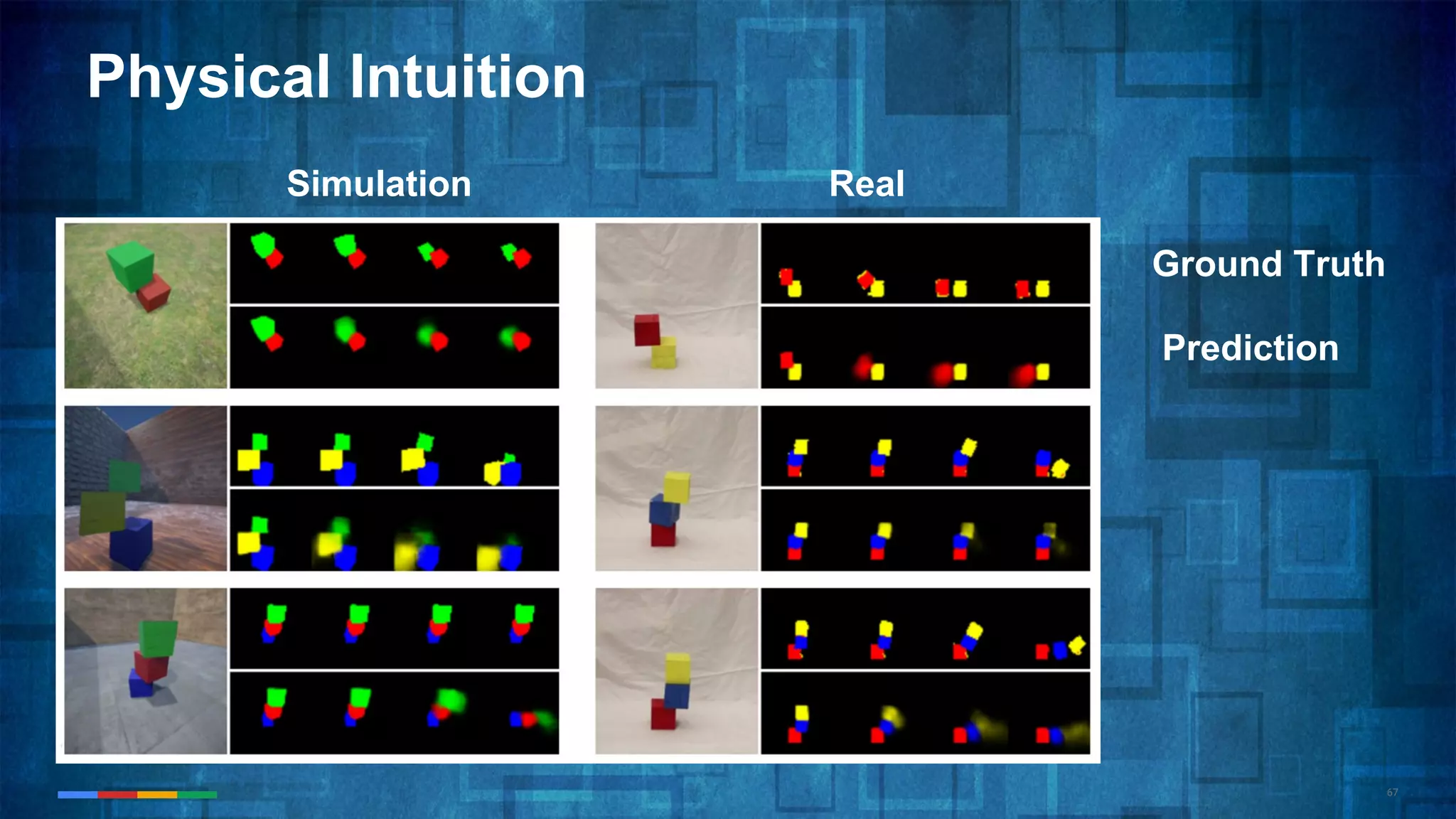
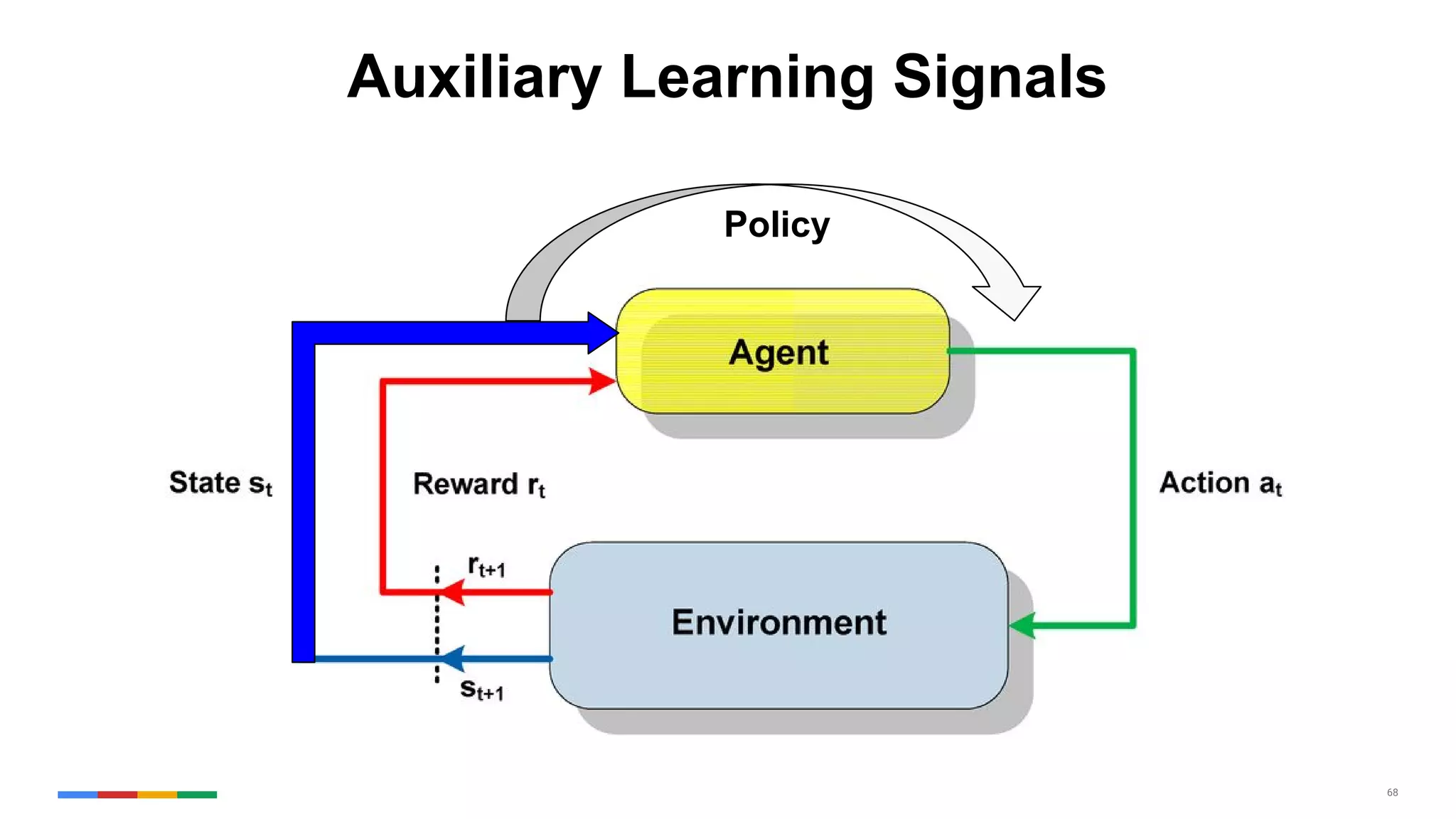
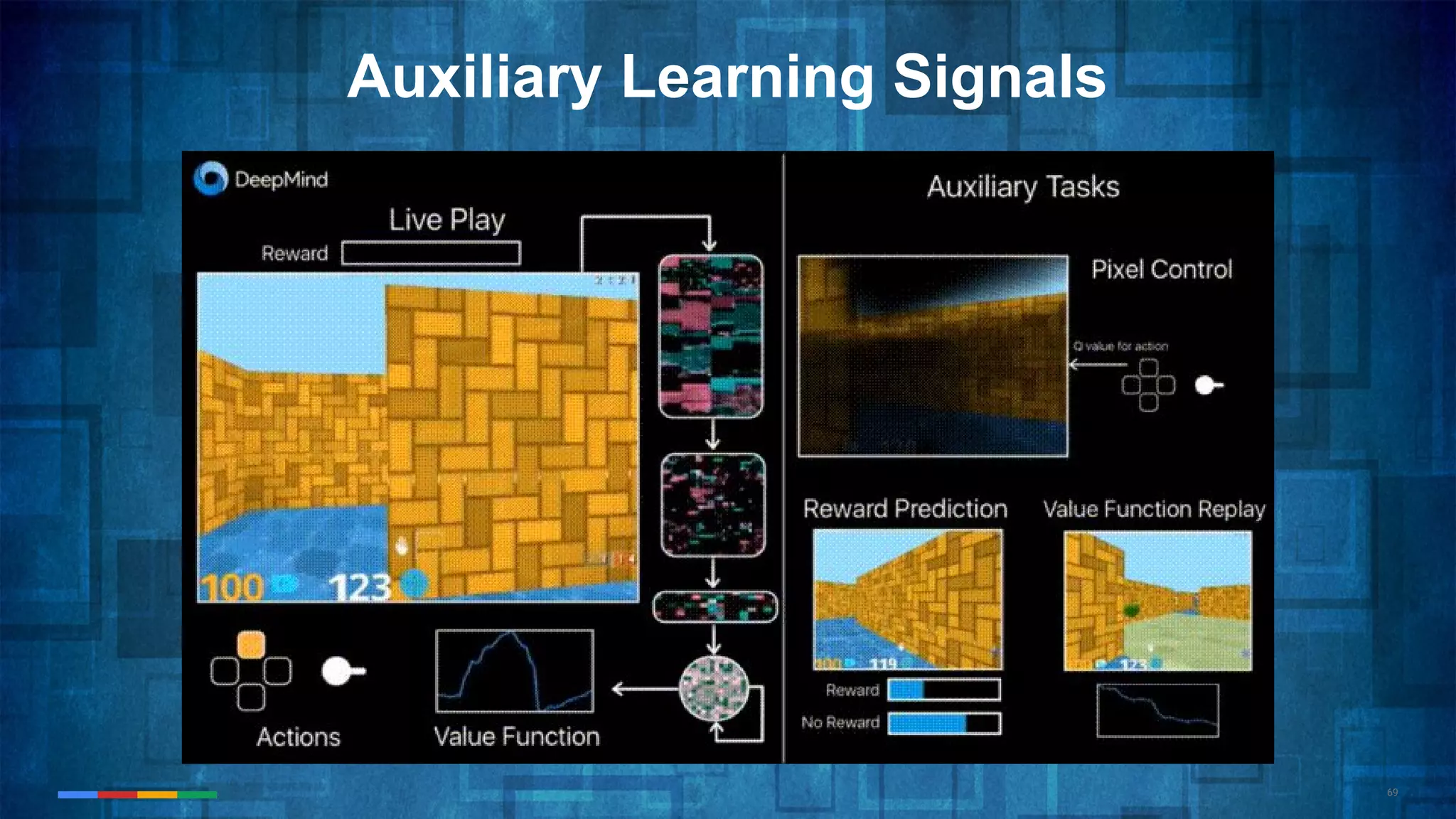
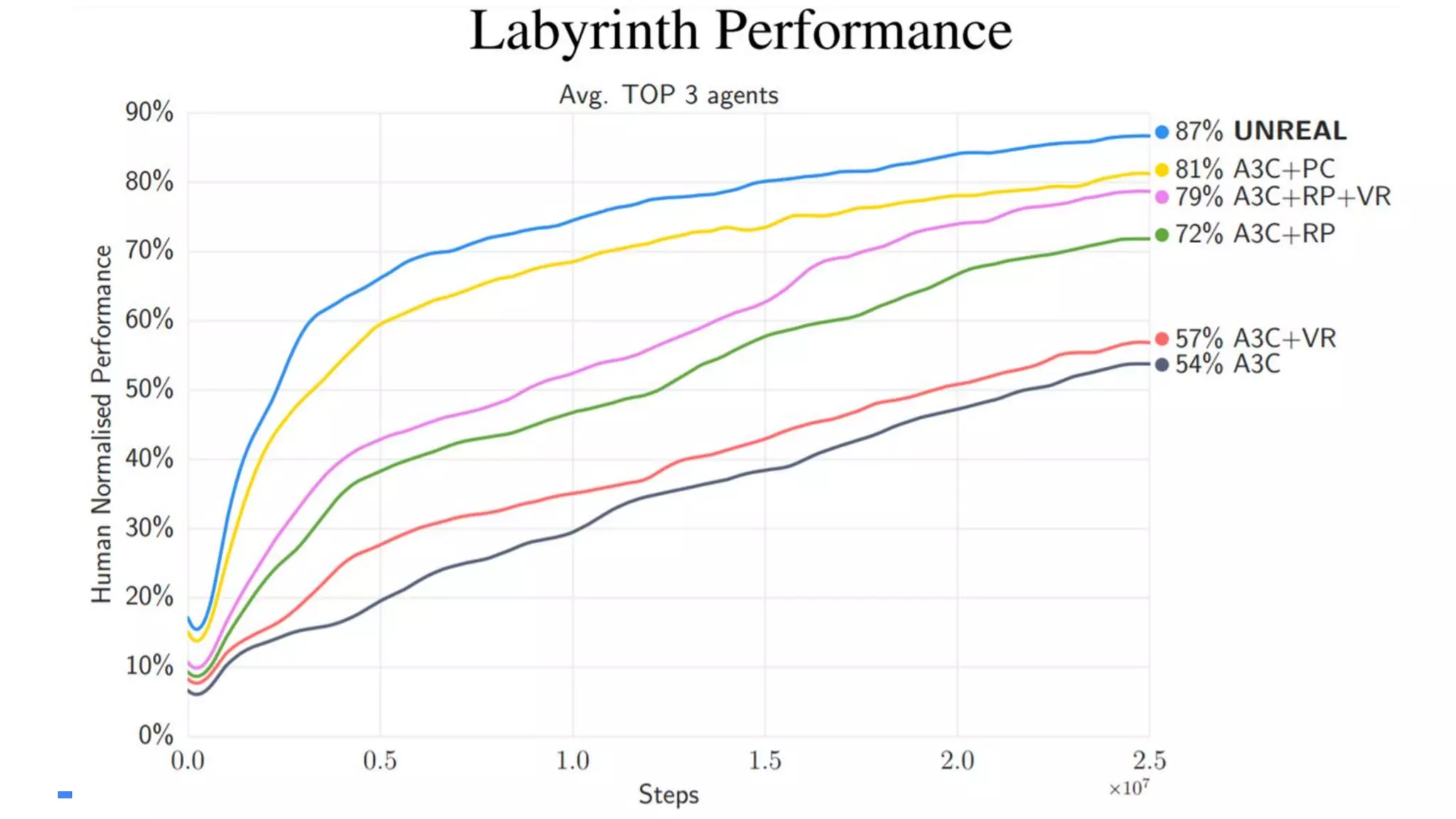
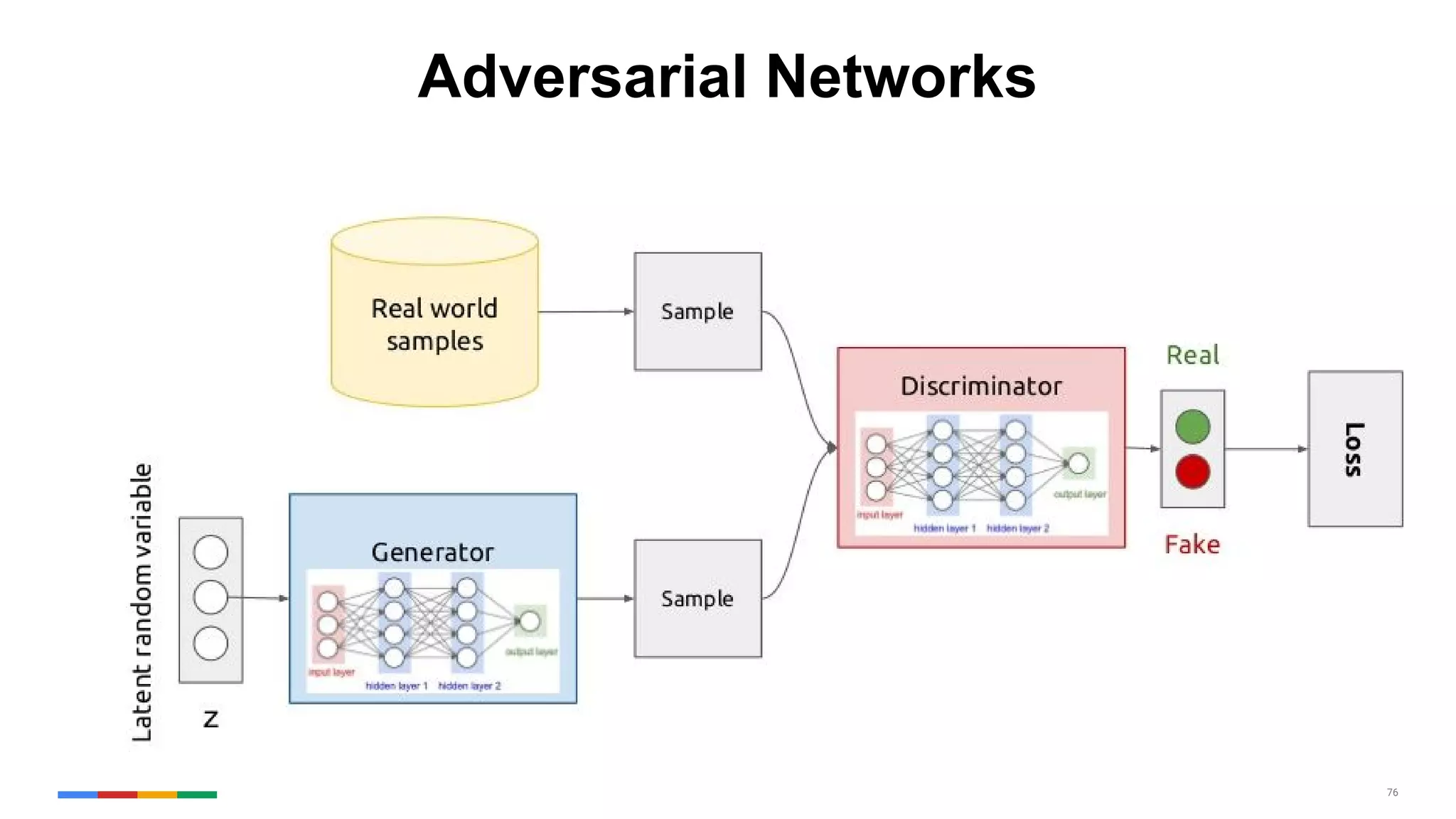
The document provides an overview of the history and evolution of artificial intelligence (AI) and reinforcement learning, highlighting key milestones such as Alan Turing's Turing test and IBM's Deep Blue. It discusses the practical applications of machine learning, the limitations of current AI systems, and explores promising areas of research. The author predicts that intelligent software will drive significant technological advancements in the next decade, impacting areas such as self-driving cars and virtual reality.















































































![[Nov 26] introduction to AI / ML](https://cdn.slidesharecdn.com/ss_thumbnails/nov26introductiontoaiml-211127034520-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DSC Europe 25] Marko Djordjevic - AI can help Agriculture.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/c0huq0ztiubmgccem2hc-marko-djordjevic-ai-can-help-agriculture-251218125253-7606f036-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Ivan Petrovic - Is it really that expensive to build an AI sy...](https://cdn.slidesharecdn.com/ss_thumbnails/ybqhdwvusbg7jms3doxh-9-251216105605-7aab5a10-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Ivan Peric - Intelligence Swarm Logic and Techno-Functional M...](https://cdn.slidesharecdn.com/ss_thumbnails/7my7c97fsduiccadgavw-2-251212103249-5a03f7c6-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Kaja Kandare - LLM as a judge.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/arxyccaxsdsd1ba99wjw-7-251212104007-2b4e3f64-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Branko Urosevic -Rethinking Financial Talent: Integrating Cod...](https://cdn.slidesharecdn.com/ss_thumbnails/8jjrus8ttko6qj64f58f-3-251212103250-642c6374-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Behzad Hosseini - AI Agents in the Wild: Deploying Models tha...](https://cdn.slidesharecdn.com/ss_thumbnails/3qtejajvsjqrzwfept2c-10-251212103250-7f2b1068-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Debmalya Biswas - Agentification: the art of transforming man...](https://cdn.slidesharecdn.com/ss_thumbnails/r5azlggvtqiaiiusrqdr-4-251212103249-5a12c89b-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Hans Kleinsman - The Compliance Gearbox: How Tax Tech Mediate...](https://cdn.slidesharecdn.com/ss_thumbnails/dxdytie1toel0hr90bjs-2-251212103250-174fdbe7-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Jean Del Rosario - How to Reduce GenAI Costs up to 73.45%.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/zjehcwqsiwjisav1znml-5-251217093201-eae4440a-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Miodrag Pesovic & Vladislav Radonjic - Federated Data Archite...](https://cdn.slidesharecdn.com/ss_thumbnails/gsbe3y5it5uhndi4e08e-1-251212103249-f1008e0c-thumbnail.jpg?width=640&height=640&fit=bounds)

