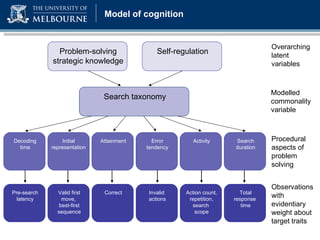
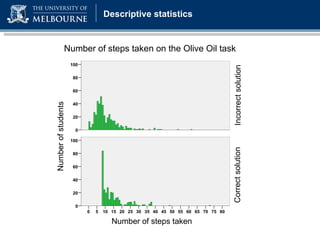
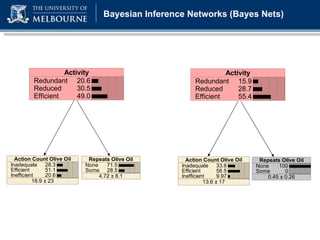
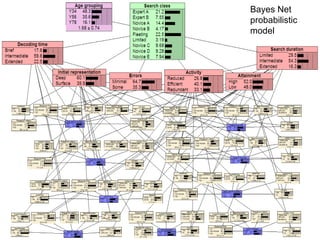
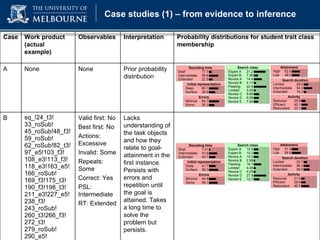
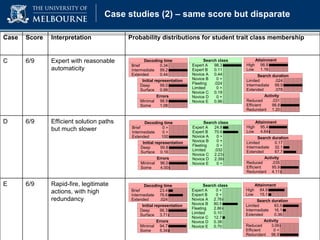
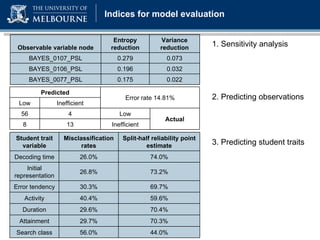
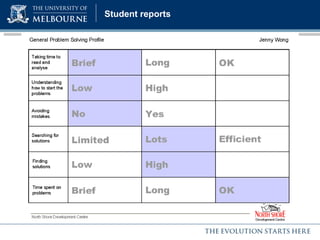
The document discusses a presentation on computer-based assessment of problem solving at the University of Heidelberg, focusing on the development of interactive tasks to evaluate student problem-solving skills for grades 3 to 8. It emphasizes the importance of understanding the cognitive processes involved in problem solving, using statistical modeling and process data to inform instructional methods. The research aims to enhance educational practices by identifying student strengths and weaknesses through innovative assessment methodologies.









































![Teaching Through Problem Solving[1]](https://cdn.slidesharecdn.com/ss_thumbnails/teachingthroughproblemsolving1-090330204217-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)











![Data driven ppt_presentation[1]](https://cdn.slidesharecdn.com/ss_thumbnails/datadrivenpptpresentation1-100710102551-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
































