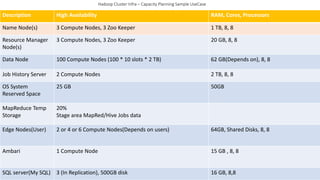
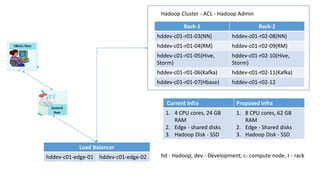
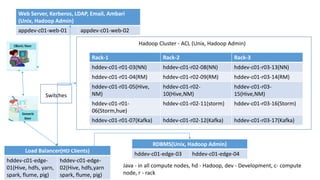
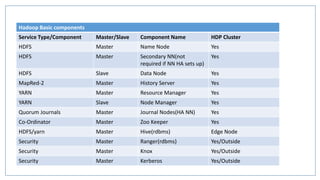
Download to read offline




![Install High level basic steps
• 1) Install Linux OS (CentOS 6.X), user accounts enabled/created: root/welcome1, hdpadmin/welcome1
Hadoop Admin GROUPID and USERID minimum should be 2000
• 2) Ensure SSH, python2.6 package installed running if not then install using root access
• 3) Setup hostname(FQDN) maps to IP using hosts file
• 4) Setup hostname or update the hostname entry network file
• 5) Tune kernel params, Disable IPv6 & transparent memory pages
• 6) Disable selinux
• 7) Ensure iptables or firewall off for demo setup[Later you can enable and allow required ports and access]
• 8) Ensure DNS name resolution to IP Address and vice versa
• 9) Install NTP service and assign to the region of NTP server
• 10) Hard and Soft limits for files, umask
• 11) Reboot
• 12) Hadoop Admin account must be part of sudoers list
• 13) Enable password less authentication using ssh](https://image.slidesharecdn.com/hadoopclustercapplan-201208170825/85/Hadoop-Architecture_Cluster_Cap_Plan-14-320.jpg)

Hadoop is an open-source framework that processes large datasets in a distributed manner across commodity hardware. It uses a distributed file system (HDFS) and MapReduce programming model to store and process data. Hadoop is highly scalable, fault-tolerant, and reliable. It can handle data volumes and variety including structured, semi-structured and unstructured data.



































































