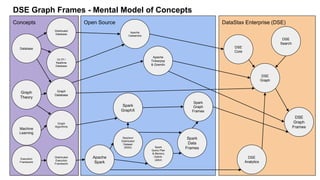
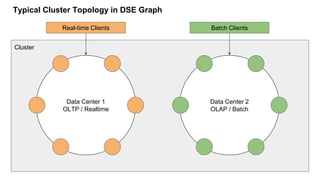
The document discusses Datastax's GraphFrames access methods, showcasing key concepts like OSS Spark GraphFrames, DSE GraphFrames, and various graph algorithms. It provides code examples for using Spark SQL and Tinkerpop/Gremlin for graph operations including shortest path calculations and motif finding. Additional resources and a demo dataset are also included to illustrate the practical applications of these graph technologies.

















![Motif finding
© 2016 DataStax, All Rights Reserved. 21
val g = spark.dseGraph("killrvideo")
//get a list of actors who have worked in comedy movies
var comedyActors = g.find("(movie)-[e1]->(person); (movie)-[e2]->(genre)")
.filter("""
person.`~label` = 'person'
and e1.`~label` = 'actor'
and movie.`~label` = 'movie'
and e2.`~label` = 'belongsTo'
and genre.`~label` = 'genre'
and genre.name = 'Comedy'
""")
.select("person.name", "movie.title", "genre.name")
comedyActors.show(false)
//comedyActors.explain](https://image.slidesharecdn.com/rseaqtc6qokvc9phqj4e-signature-2e34102920e0083f704761cb8431d8a3db5bfbdbec76cfae9cab985ed287f855-poli-180916172619/85/GraphFrames-Access-Methods-in-DSE-Graph-21-320.jpg)










![[DSC 2016] 系列活動:李泳泉 / 星火燎原 - Spark 機器學習初探](https://cdn.slidesharecdn.com/ss_thumbnails/sparkmllib-161026052038-thumbnail.jpg?width=640&height=640&fit=bounds)










































![[DSC Europe 25] Andrzej Kowalczyk - AI - how to start small and grow in the f...](https://cdn.slidesharecdn.com/ss_thumbnails/oy1zmo94qv6vpcqjvno2-andrzej-kowalczyk-ai-how-to-start-small-and-grow-in-the-future-1-260119121559-cf093b23-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DSC Europe 25] Borko Kozomora - Optimizing business workflows with advances ...](https://cdn.slidesharecdn.com/ss_thumbnails/hbgekyb0txw0xpo4yfml-borko-kozomora-leading-ai-transformation-260122103838-cc29ee38-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Tali Fulman - Guild Meetings, Then What? Building Data Commun...](https://cdn.slidesharecdn.com/ss_thumbnails/fgohhi33rwmhqdowdj5k-tali-fulman-guild-meetings-then-what-building-data-communities-that-actually-ch-260120105855-528492c3-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dubravko Culibrk - Deep Learning for Mammography.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/yiscimuktacgqoiu4dkp-deep-learning-for-mammography-260119121559-aad59182-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Bojan Djuricic - Predictive Design Process.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/5awdrbedqdek3gqu2ezy-4-the-predictive-design-bojan-djuricic-260120105856-6c399e9b-thumbnail.jpg?width=640&height=640&fit=bounds)



