Flamingo 1.2 릴리즈의 지원 기능 정리
•
12 likes•2,531 views

Open Cloud Engine의 Flamingo 프로젝트 1.2 버전에서 제공하는 기능 목록입니다.

Recommended
Recommended
More Related Content
What's hot
What's hot (20)
Viewers also liked
Viewers also liked (20)
Similar to Flamingo 1.2 릴리즈의 지원 기능 정리
Similar to Flamingo 1.2 릴리즈의 지원 기능 정리 (20)
Flamingo 1.2 릴리즈의 지원 기능 정리
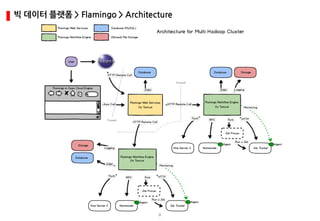
- 1. 0 빅 데이터 플랫폼 > Flamingo > Architecture
- 2. 1 빅 데이터 플랫폼 > Flamingo > Workbench Flamingo는 웹 브라우저에서 빅 데이터 인프라의 접근성 및 데이터 분석 업무의 생산성을 최대화 하기 위한 가상 데스크탑 환경을 제공하며 이를 통해 빅 데이터의 인프라 사용을 극대화합니다.
- 3. 2 빅 데이터 플랫폼 > Flamingo > 워크플로우 디자이너 Flamingo는 워크플로우 디자이너를 제공하여 하나 이상의 모듈을 연계하여 데이터 분석 및 처리 워크플로우를 구성할 수 있습니다. 전통적인 분석 도구의 UI와 Apache Hadoop을 결합하여 데이터 분석 및 처리 플로우를 구성 각 모듈별 설정 워크플로우 목록 데이터 분석/처리 모듈 (누구나 추가 가능)
- 4. 3 빅 데이터 플랫폼 > Flamingo > 워크플로우 디자이너 Flamingo는 워크플로우 디자이너를 제공하여 하나 이상의 모듈을 연계하여 데이터 분석 및 처리 워크플로우를 구성할 수 있습니다.
- 5. 4 빅 데이터 플랫폼 > Flamingo > 워크플로우 디자이너 > 기본 제공 알고리즘 Flamingo는 워크플로우 디자이너는 기본으로 사용가능한 다양한 MapReduce로 구현한 알고리즘을 제공합니다. 분류 내용 주요 출력 결과 MapReduce 처리 내용 수치/범주 데이터 기초 통계 분석 수치 데이터 기초 통계 합계, 평균(4종) 분산, 표준편차 최대/최소/중앙값 • 데이터의 분할 및 분할 데이터의 통계 산출 • 분할 산출된 통계의 합산 및 최종 통계 산출 범주 데이터 기초 통계 발생빈도, 발생비율 • 데이터의 속성값 별 빈도수 산출 • 빈도에 대한 전체 데이터 대비 비율 산출 수치 데이터 확신도 기반 합계 확신도(Certainty Factor) 기반 합계 • 데이터의 분할 및 분할 데이터의 확신도 산출 • 분할 산출된 통계의 합산 및 최종 확신도 산 출 전처리 수치 데이터 Min/Max 기반 정규화 Min/Max 정규화 값 • 데이터의 Min/Max 수치 산출 • Min/Max 값 기반 데이터 정규화 유사/상관 분석 이진 벡터 데이터 기반 Hamming, Jaccard/Tanimoto, Dice • 데이터의 속성별 분해 레코드 생성 • 분해된 속성별 데이터 레코드를 이용한 유사 /상관 수치 계산 수치 벡터 데이터 기반 Euclidean, Manhattan, Cosine, Pearson 문자열 데이터 기반 Hamming, Edit(Levenshtein) 마이닝 기계학습 Clustering K-Means, EM • 데이터 최근접 할당 (거리/확률 빌도) • 군집별 할당 데이터를 이용한 군집 중심 정보 갱신 (거리 평균/데이터 분포) Classification ID3 • 의사결정 트리의 분류 노드 선택을 위한 속성 별 정보량 계산 Recommendation Collaborative Filtering Item/Use based Recommendation • 사용자 및 아이템 간 상관계수 도출 • 아이템 속성별 이진 유사도 계산 • 사용자별 추천 아이템 생성 공통 Hadoop EcoSystem MapReduce, Hive, Pig, Program Java, Python, Bash
- 6. 5 빅 데이터 플랫폼 > Flamingo > 워크플로우 디자이너 > 향후 추가할 모듈 (계획) Flamingo는 워크플로우 디자이너는 기본으로 제공하는 데이터 분석 및 처리 모듈 이외에도 향후 다음의 분석 및 처리 모듈 그리고 통합을 추가할 계획을 하고 있습니다. 분류 내용 주요 출력 결과 예정 일정 전처리 MapReduce ETL Grep, Filter, Encrypt, Group By, Remove 등등 • Flamingo 1.3에서 지원 형태소 분석 한글 형태소 분석 • 완료 마이닝 기계학습 Clustering Canopy • Flamingo 1.4에서 지원 Classification Logistic Regression, Random Forest Naïve Bayes • Flamingo 1.4에서 지원 Graph Apache Giraph, GraphBuilder • Flamingo 1.4에서 지원 공통 Hadoop EcoSystem Sqoop • Flamingo 1.2에서 지원 Apache Spark & Shark • Flamingo 1.4에서 지원 Program PL/Java • Flamingo 1.4에서 지원 R Statistics • Flamingo 1.3에서 지원 Commercial SQL On Hadoop Pivotal HAWQ • Flamingo 1.5에서 지원 기타 Input Format Binary File Format • Flamingo 1.3에서 지원 File Format PDF Text Extractor • Flamingo 1.3에서 지원 Excel Text Processor • 현재 적용 완료 Framework 비정형 처리 Apache UIMA Framework • 현재 적용 완료 Log 처리 Apache Web Server Access Log To CSV • 현재 적용 완료
- 7. 6 빅 데이터 플랫폼 > Flamingo > Hadoop Job Tracker Monitoring Hadoop Job Tracker 모니터링은 Hadoop Cluster를 관리하는 관리자에게 매우 중요하므로 Flamingo에서는 가장 중요한 정보를 중점적으로 모니터링합니다. Job Tracker의 중요 정보 모니터링
- 8. 7 빅 데이터 플랫폼 > Flamingo > File System/Namenode Monitoring Apache Hadoop Cluster를 관리의 핵심중 하나가 바로 파일 시스템입니다. 전체 용량 및 데이터 노드의 동작 상태를 모니터링할 수 있도록 합니다. 파일 시스템 및 Namenode 모니터링
- 9. 8 빅 데이터 플랫폼 > Flamingo > Hadoop Job Monitoring Flamingo는 Apache Hadoop Job Tracker에서 제공하는 Hadoop Job 모니터링을 하둡 배포판의 수정 없이, 배포판 제한 없이, 어떠한 네트워크 환경 제약에서도, Amazon EMR에서도 완벽하게 제공합니다. Hadoop Job Tracker의 완벽한 모니터링
- 10. 9 빅 데이터 플랫폼 > Flamingo > Hadoop Job Monitoring 대용량 데이터 처리 및 분석 과정을 업무로 구현하기 위한 워크플로우 디자이너로서 클라우드 환경 및 웹 환경에 적합하도록 웹 브라우저에서 동작하며 완전하게 커스터마이징이 가능합니다. MapReduce의 처리 현황 그래프 데이터 검증을 위한 MapReduced의 Counter 정보 MapReduce Job Configuration 검색 및 다운로드 기능
- 11. 10 빅 데이터 플랫폼 > Flamingo > Hadoop Job Monitoring Hadoop Job 모니터링에서도 반대로 추적이 모두 가능해야 함.
- 12. 11 빅 데이터 플랫폼 > Flamingo > 워크플로우 모니터링 워크플로우 디자이너의 워크플로우를 실행하고 진행 상황을 모니터링하는 기능이며 Hadoop을 이용하는 개발자 및 분석가들이 보는 정보를 그대로 제공합니다. 워크플로우 디자이너에서 설계한 워크플로우의 동작 상태 모니터링 MapReduce, Pig, Hive Job의 완벽한 로그 보기
- 13. 12 빅 데이터 플랫폼 > Flamingo > 워크플로우 모니터링 합계 실행 로그 커맨드 라인 워크플로우의 노드는 다 수의 MAPREDUCE JOB으 로 동작할 수 있으므로 추적이 가능해야 함 사용자 관점의 MapReduce 실행 이력
- 14. 13 대용량 데이터 처리시 사용하는 다양한 로그 파일을 관리하는 관리 화면으로 웹 브라우저에서 대용량 분산 파일 시스템을 관리할 수 있으며 디렉토리를 즉시 DB로 전환하여 조회 및 통계를 산출할 수 있습니다. 빅 데이터 플랫폼 > Flamingo > File System Browser 파일 시스템에서 Hive DB, Table을 생성하고 바로 조회 및 통계 처리 가능
- 15. 14 빅 데이터 플랫폼 > Flamingo > File System Browser 디렉토리를 Hive DB와 Table로 전환 브라우저에서는 Hive DB와 Table 경로를 다른 아이콘으로 표시하여 확인 FLAMINGO에서는 사용자가 주로 하는 행위에 최적화하 여 기능을 제공
- 16. 15 HDFS에 저장되어 있는 각종 파일 및 디렉토리를 사용자가 처리하는 경우 관련한 모든 기록을 남기고 추적합니다. 빅 데이터 플랫폼 > Flamingo > File System Audit Log 파일 시스템 브라우저의 모든 활동을 모니터링
- 17. 16 워크플로우 구성시 Expression Language를 활용하여 변수 및 날짜 등을 동적으로 처리 빅 데이터 플랫폼 > Flamingo > Expression Language (EL) • 동적인 값들을 얻고자 할 때 Workflow Designer에서 활용 • 예) 오늘 날짜 : dateFormat(‘yyyyMMdd’) dateFormat(‘yyyy-MM-dd’) • 워크플로우가 실행할 때 특정한 값들은 해당 시간으로 대체되어야 하는 경우가 발생 • 예) 오늘 실행하는 워크플로우는 어제 날짜의 디렉토리에 기록 (일배치) • 제공하는 Expression Language • dateFormat(‘DATE FORMAT’) dateFormat(‘yyyyMMddHHmmss’) • hostname, escapeString, • yesterday, tommorow • month, day, hour, minute, … day(‘yyyyMMdd’, -1) :: 어제 날짜 (20131111) • trim, concat • urlEncode • firstNotNull • 등등
- 18. 17 워크플로우 구성시 Expression Language를 활용하여 변수 및 날짜 등을 동적으로 처리 빅 데이터 플랫폼 > Flamingo > Expression Language (EL) 입력 필드에 ${EL} 형식으로 입력하는 경우 동적으로 해석하여 값이 변경됨.
- 19. 18 HDFS에 저장되어 있는 각종 파일 및 디렉토리를 사용자가 처리하는 경우 관련한 모든 기록을 남기고 추적합니다. 빅 데이터 플랫폼 > Flamingo > Hive Editor & Metastore Browser
- 20. 19 HDFS에 저장되어 있는 각종 파일 및 디렉토리를 사용자가 처리하는 경우 관련한 모든 기록을 남기고 추적합니다. 빅 데이터 플랫폼 > Flamingo > Hive Editor & Metastore Browser 적용사례 시스템의 사용자 접근 이력 로그를 Hive로 조회하는 사례 – 대상 로그의 형식이 반정형이나 비정형인 경우 문제 발생 – 칼럼 안에 Array, Map 등의 이상한 구조를 가진 로그의 경우 문제 발생 대상 로그는 CSV 형식과 같은 잘 정리된 형식이 아닌 반정형 로그 형식
- 21. 20 HDFS에 저장되어 있는 각종 파일 및 디렉토리를 사용자가 처리하는 경우 관련한 모든 기록을 남기고 추적합니다. 빅 데이터 플랫폼 > Flamingo > Hive Editor & Metastore Browser 적용사례
- 22. 21 HDFS에 저장되어 있는 각종 파일 및 디렉토리를 사용자가 처리하는 경우 관련한 모든 기록을 남기고 추적합니다. 빅 데이터 플랫폼 > Flamingo > Hive Editor & Metastore Browser 적용사례
- 23. 22 Flamingo는 ETL 처리를 하는데 많이 사용하는 Apache Pig의 Latin Script를 자유롭게 사용할 수 있도록 Pig Editor를 제공합니다. 빅 데이터 플랫폼 > Flamingo > Pig Editor Pig Latin Script 편집기 Pig Script 실행 이력 및 로그 보기
- 24. 23 배치 작업으로 워크플로우를 실행하기 위한 Job Scheduler를 자체 내장하고 있어서 워크플로우 디자이너에서 설계한 워크플로우를 배치로 동작시킬 수 있습니다. 빅 데이터 플랫폼 > Flamingo > Job Management Cron Expression을 100% 지원
- 25. 24 배치 작업으로 워크플로우를 실행하기 위한 Job Scheduler를 자체 내장하고 있어서 워크플로우 디자이너에서 설계한 워크플로우를 배치로 동작시킬 수 있습니다. 빅 데이터 플랫폼 > Flamingo > Job Management 등록되어 있는 배치 작업 현황 작업 스케줄링 현황엔진의 메모리 상태
- 26. 25 Flamingo에서는 Hadoop 2 기반 하둡 클러스터를 구성하는 각각의 데이터 노드의 상태정보를 확인할 수 있습니다. 빅 데이터 플랫폼 > Flamingo > Hadoop 2 지원 데이터노드의 상태 정보
- 27. 26 Hadoop 2에서 새로 추가된 Resource Manager는 애플리케이션, 노드를 관리하며 이를 위한 정보를 Flamingo에서 다음과 같이 제공합니다. 빅 데이터 플랫폼 > Flamingo > Hadoop 2 지원 등록되어 있는 배치 작업 현황 Resource Manager 상태 정보
- 28. 27 Hadoop 2로 구성되어 있는 클러스터에서 YARN Application과 MapReduce Job을 실행하는 경우 다음과 같이 실행 이력을 목록으로 볼 수 있으며 상세정보도 볼 수 있습니다. 빅 데이터 플랫폼 > Flamingo > Hadoop 2 지원 YARN 애플리케이션 실행 목록 MapReduce Job 목록
- 29. 28 Flamingo의 Hadoop 2 지원 기능에는 MapReduce Job과 같은 Job에 대한 요약 정보를 테이블 형태로 볼 수 있도록 지원을 하여 개발자 및 운영자는 현황 정보를 쉽게 파악할 수 있습니다. 빅 데이터 플랫폼 > Flamingo > Hadoop 2 지원 MapReduce Job의 기본 요약 정보
- 30. 29 Flamingo는 MapReduce Job을 실행하는 다수의 작업(Task)의 실행 이력을 다음과 같이 볼 수 있습니다. 빅 데이터 플랫폼 > Flamingo > Hadoop 2 지원 Hadoop Job Counter MapReduce Job Tasks
- 31. 30 빅 데이터 플랫폼 > Flamingo의 기능 목록 구분 기능 모니터링 • Namenode 모니터링 (HDFS Usage, Datanode, Bad Block 등등) • Job Tracker 모니터링 (MapReduce Task, JVM Heap, Task Tracker, Job) • Hadoop Job 모니터링 (Job Info, MapReduce Progress, MapReduce Counter, MapReduce Configuration) • 워크플로우 모니터링 (실행 이력 및 상세 정보) • 배치 작업 모니터링 (작업 현황, 엔진의 메모리 상태) 워크플로우 관리 • 워크플로우 저장, 실행, 복사, 삭제 • 드래그 앤 드롭 • 워크플로우 변수 • 데이터 처리 모듈 제공 (MapReduce, Pig, Hive, Java, Bash, Python, Apache Log, Unstructure Analysis :: UIMA, Clustering, Classification, Normalization, Statistics, Similarity, Recommendation 등등) 배치 작업 관리 • 배치 작업 등록, 일시중지, 재시작, 종료 • 등록한 배치 작업 목록 및 상태 현황 보기(다음 실행 시간, 등록한 사용자 포함) Pig 편집기 • Pig Latin Script 편집 및 저장 • Pig Latin Script 실행 이력 보기 • Pig Latin Script 실행 및 로그 보기 Hive 편집기 • Hive 쿼리 편집 및 실행 • Hive 쿼리 실행 이력 • Hive 쿼리 실행 결과 브라우징(전/후) • Hive 쿼리 실행 결과 다운로드 파일 시스템 관리 • 디렉토리 관리 • 파일 관리 • 파일 업로드(멀티, 드래그 앤 드롭) 및 다운로드 • 파일 및 디렉토리 정보 보기 • Hive DB, Table 생성 • 파일 처리 이력 감시 기타 • 웹 브라우저로 모든 동작 가능(Chrome, Safari, IE) • Multi Hadoop Cluster 지원 • Amazon Elastic MapReduce 지원 Hadoop 2 지원 • 바닐라 Hadoop 2