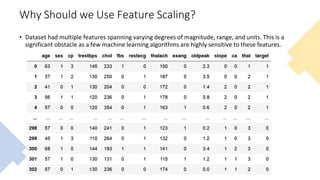
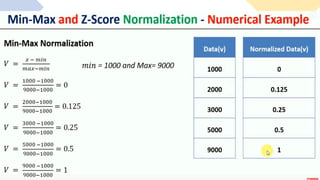
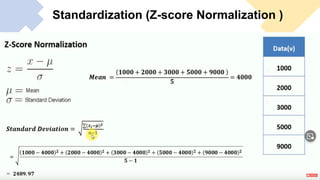
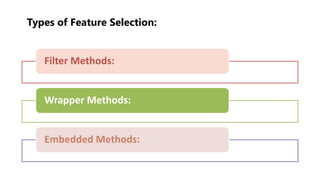
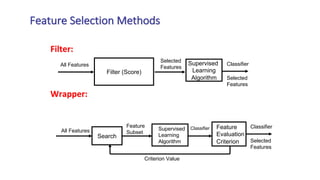
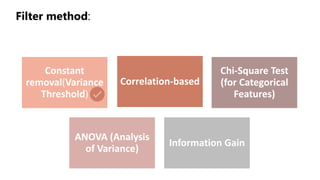
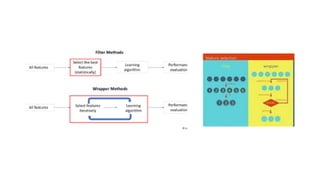
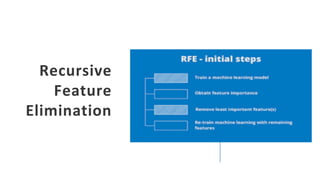
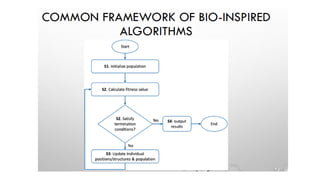
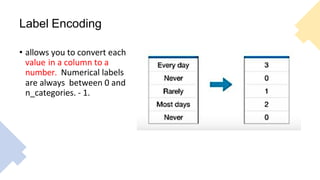
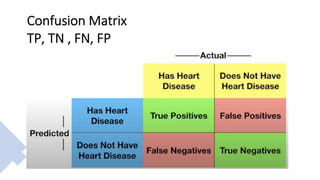
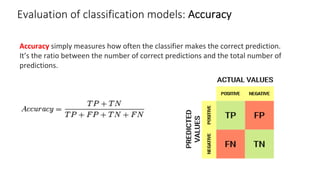
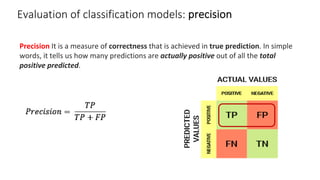
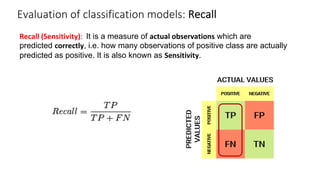
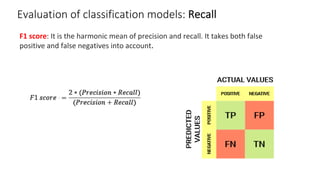
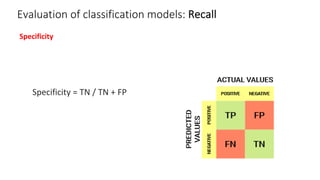
The document outlines key concepts in feature engineering, including feature scaling techniques such as normalization and standardization, and emphasizes the importance of feature selection for improving model performance. Various methods of feature selection are discussed, highlighting the need to remove irrelevant features for better accuracy and efficiency. Additionally, it covers techniques for encoding categorical data and evaluating classification and regression models using various metrics.