Downloaded 74 times
























The document discusses the roles and responsibilities of data engineers and data scientists, emphasizing the need for a solid data engineering foundation in AI and machine learning applications. It highlights key concepts such as the differences between data lakes and data warehouses, various processing technologies, and the significance of architecture in big data analytics. The conclusion notes the overlapping skills of data scientists and data engineers while advocating for clarity in their distinct roles based on organizational needs.
Introduction to data engineering and its relevance in AI production, along with an overview of the agenda.
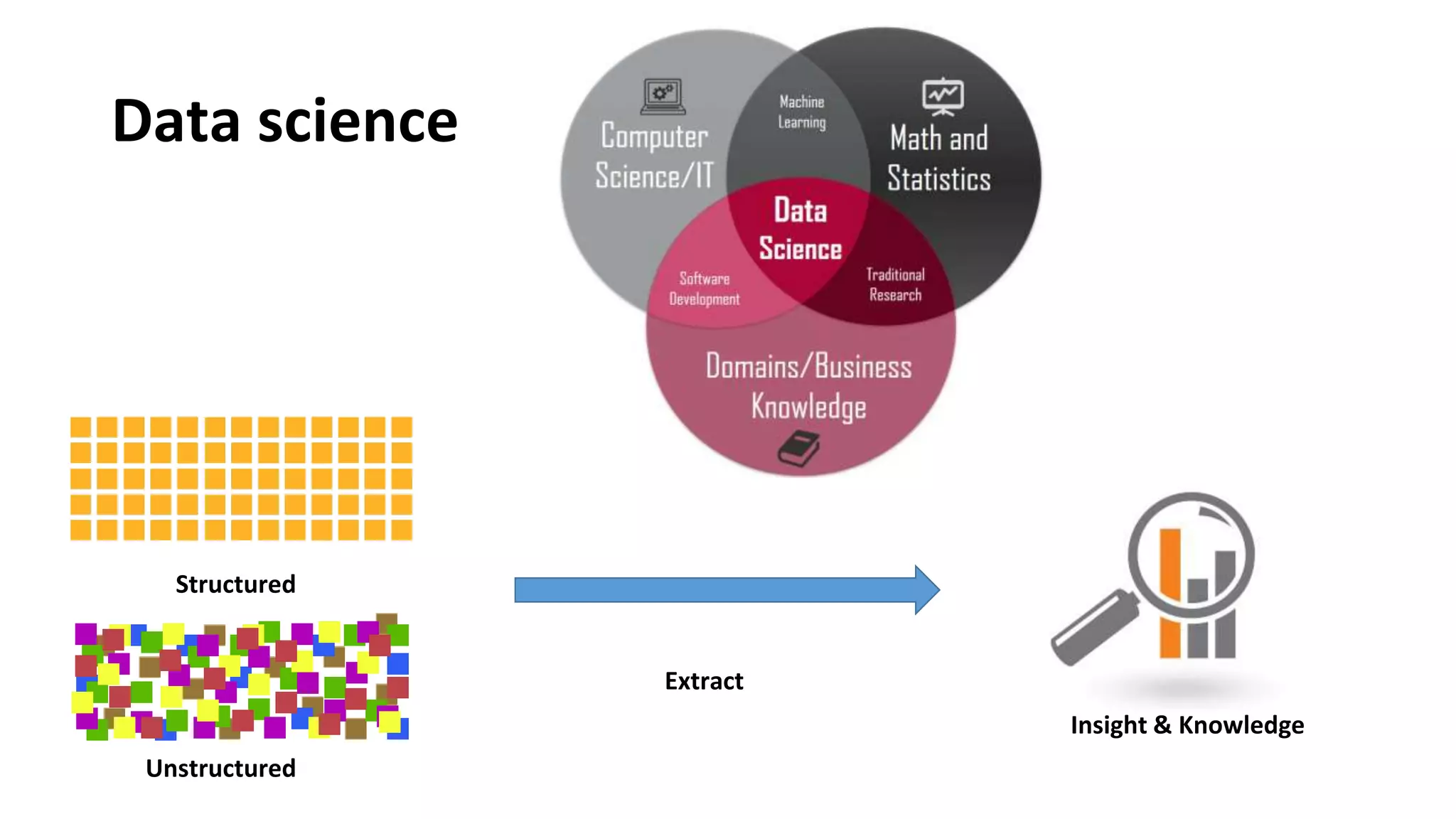
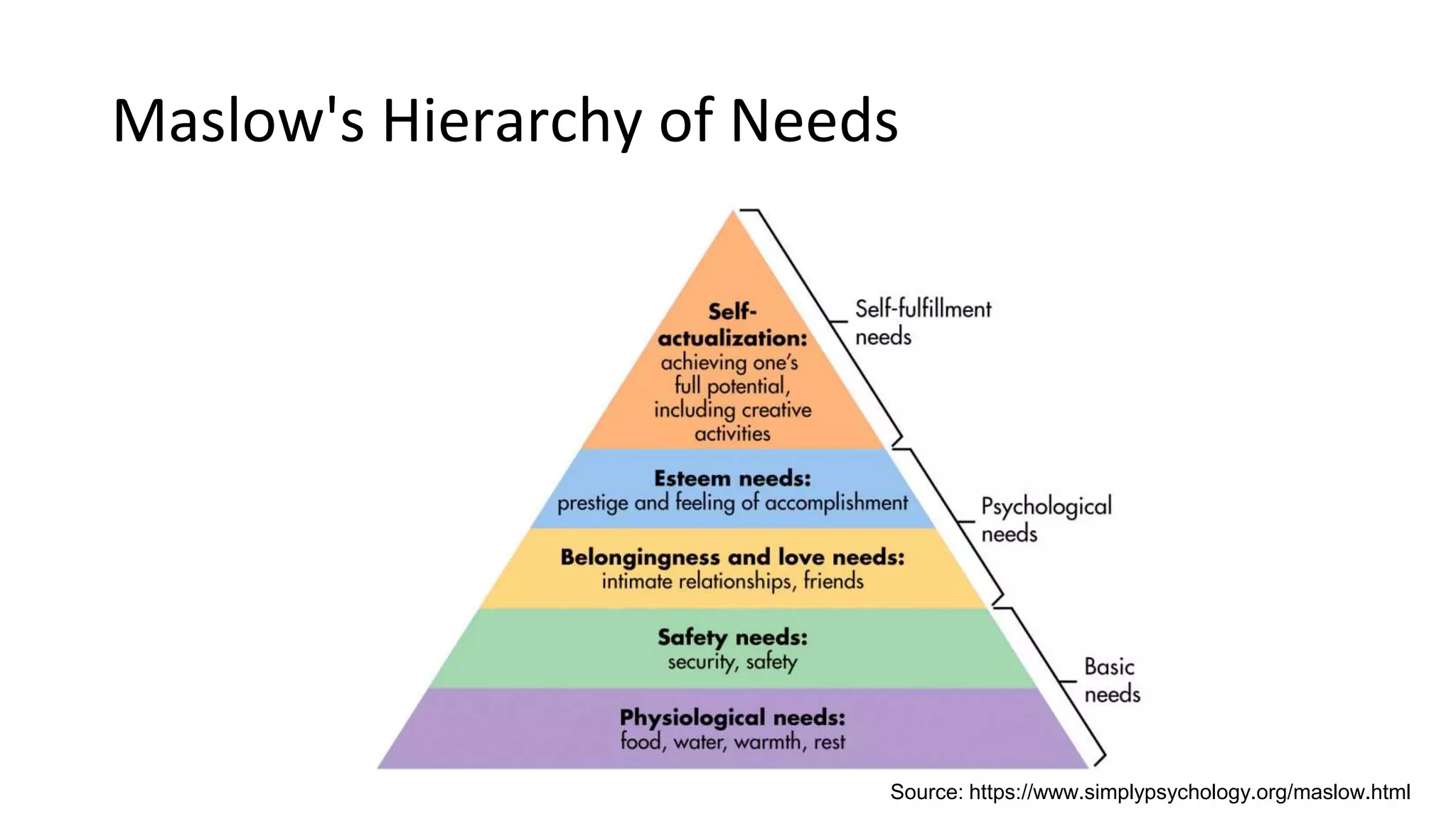
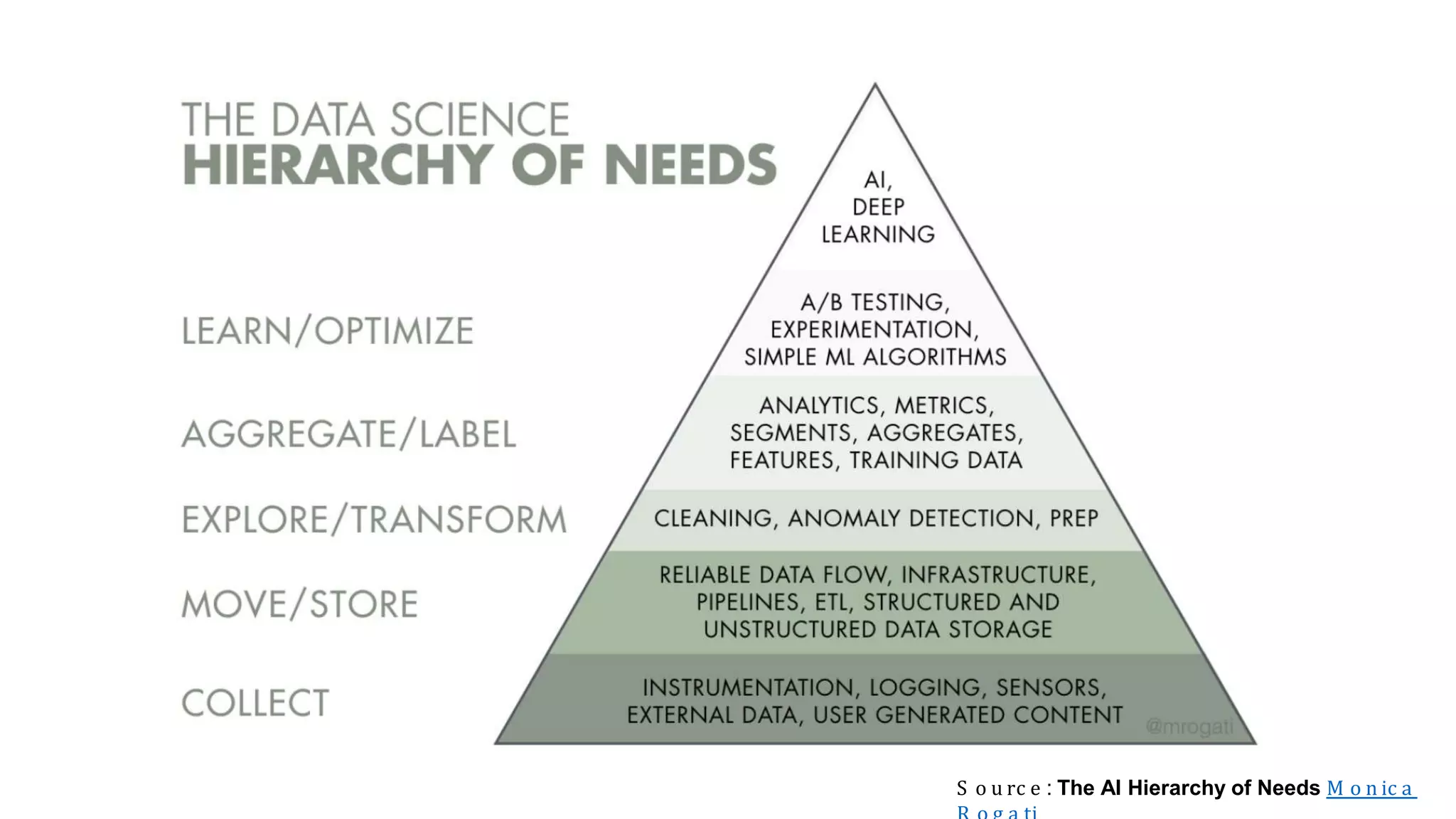
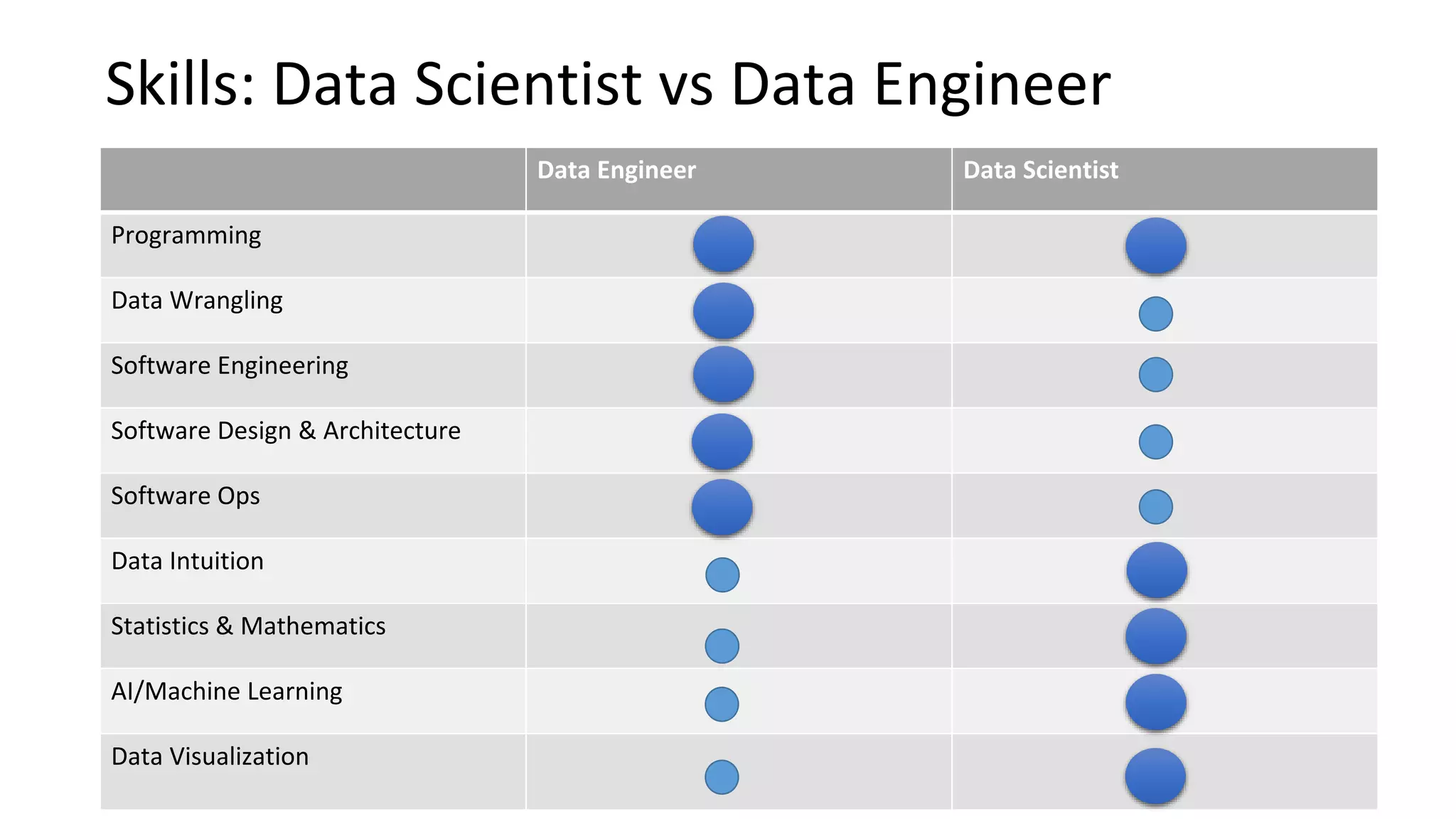
Overview of data science concepts such as data extraction and the roles of data engineers and data scientists.
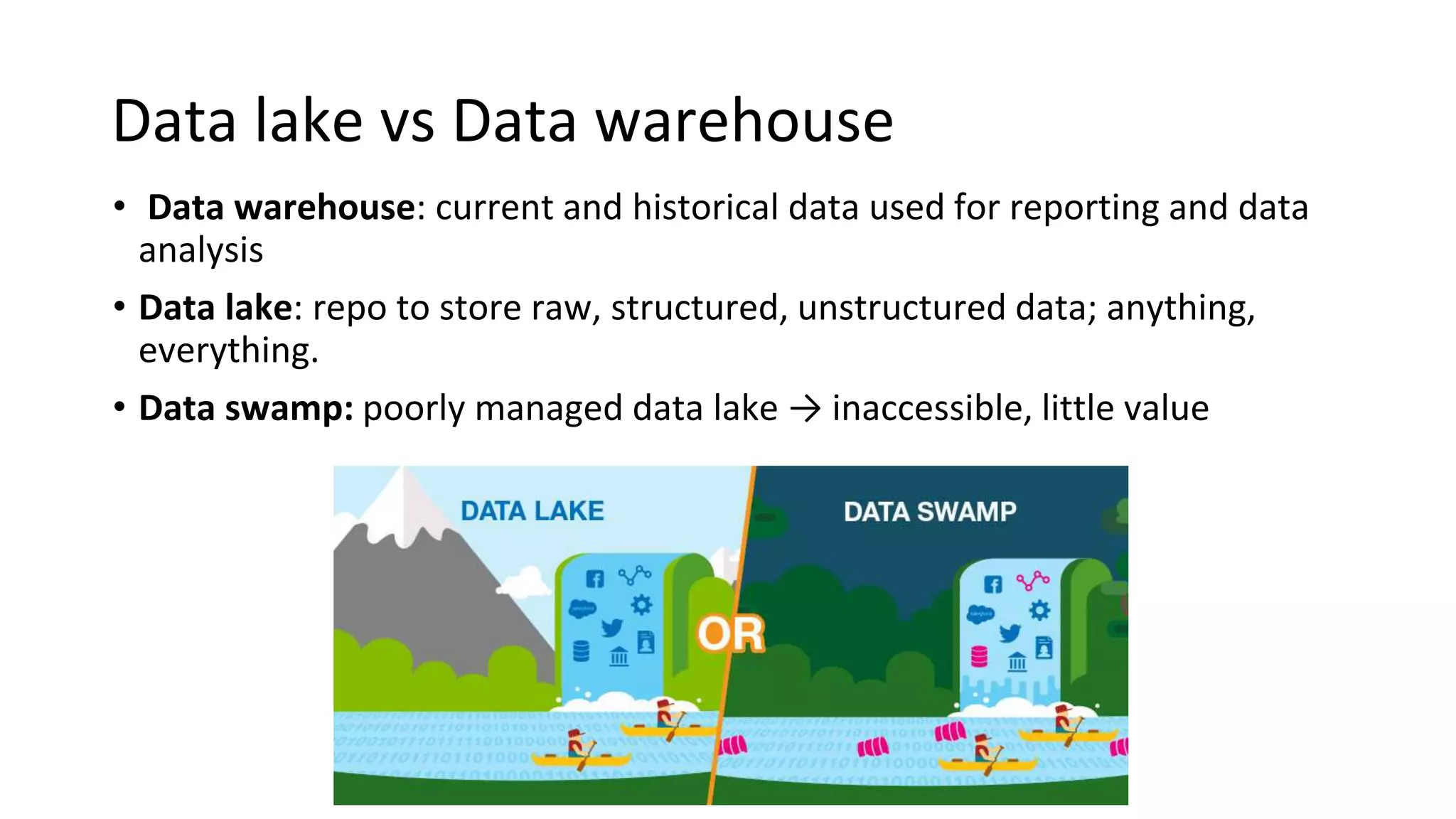
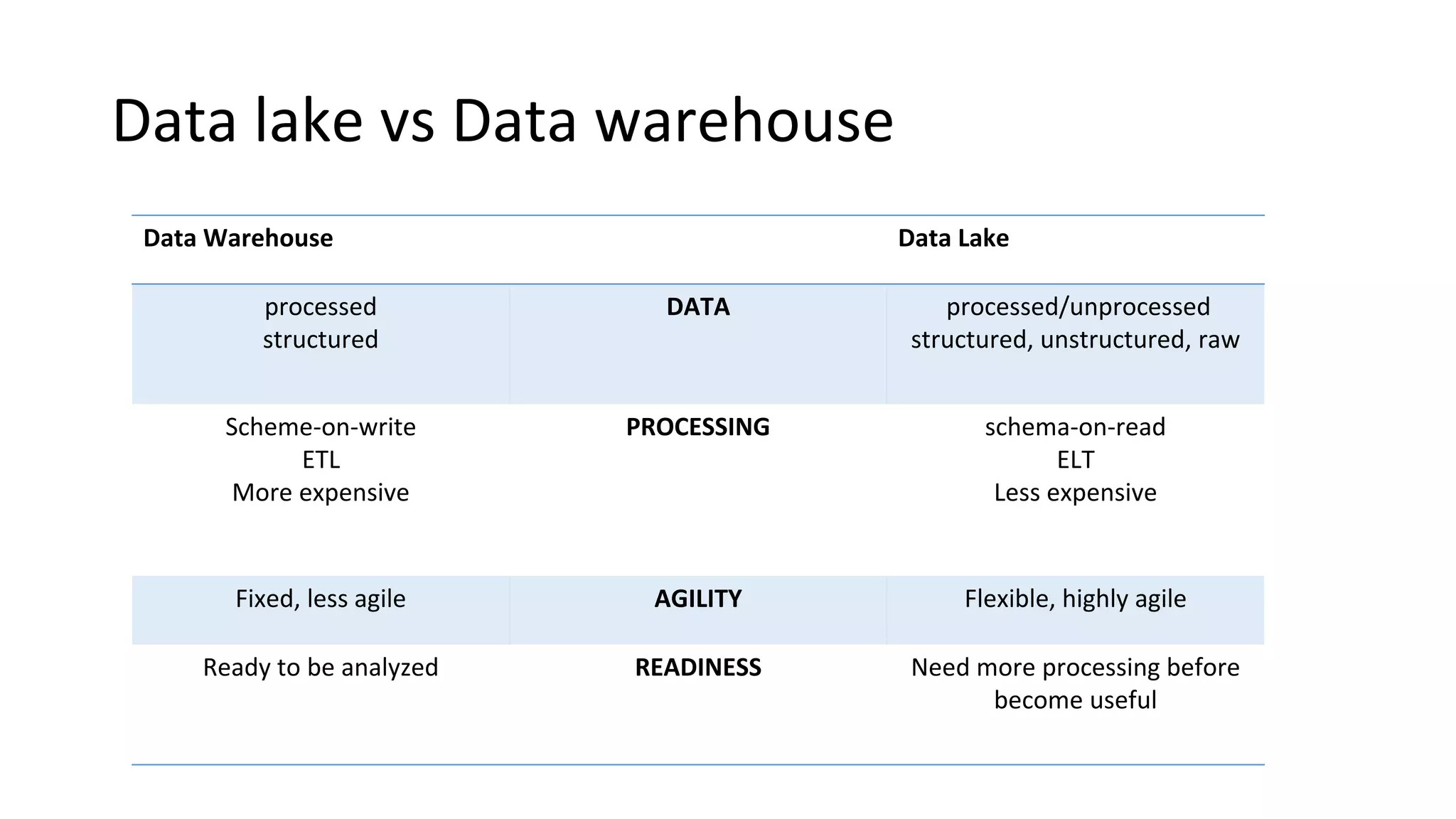
Explains the concepts of business analytics vs business intelligence, and the difference between data lakes and data warehouses.
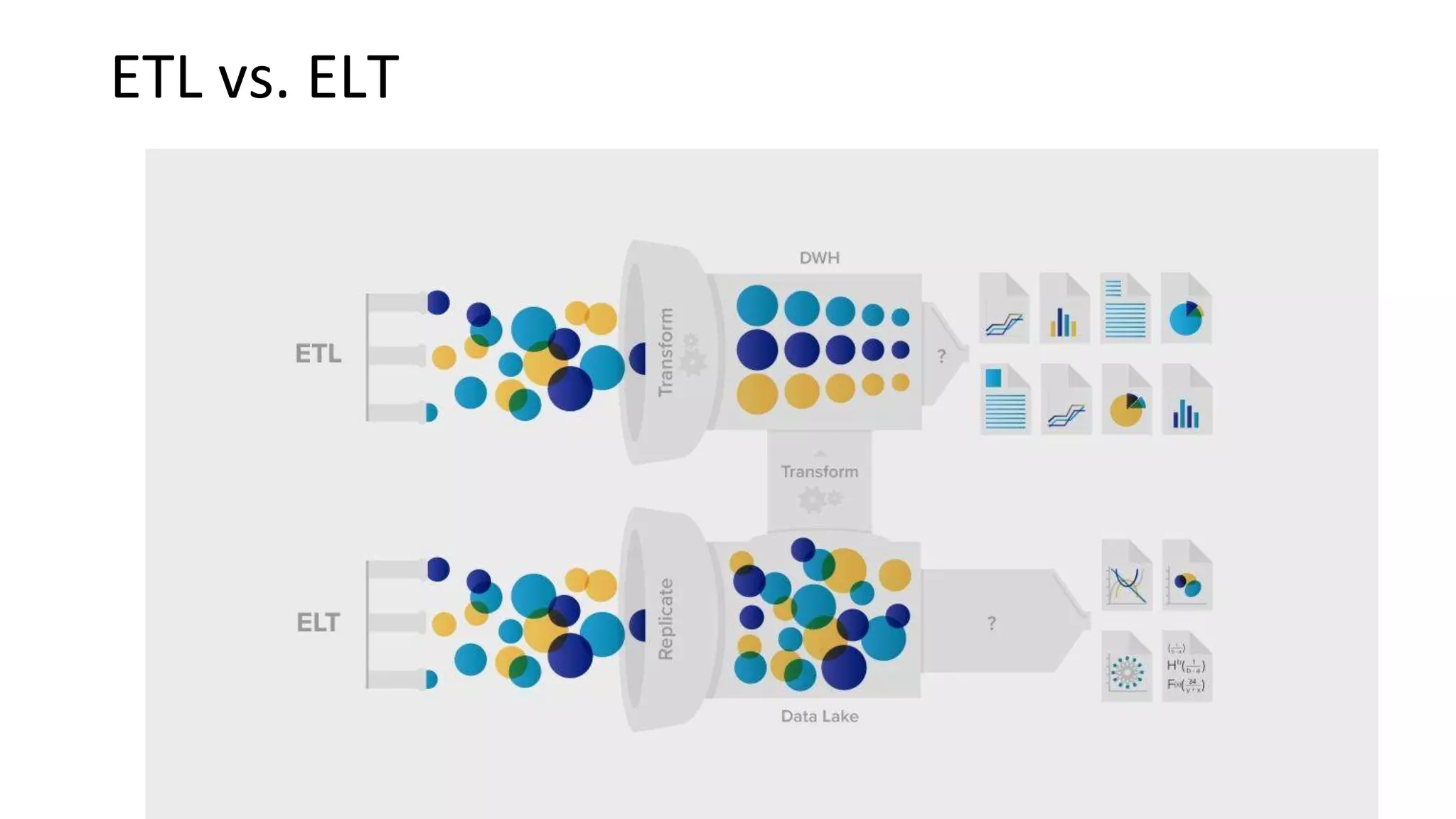
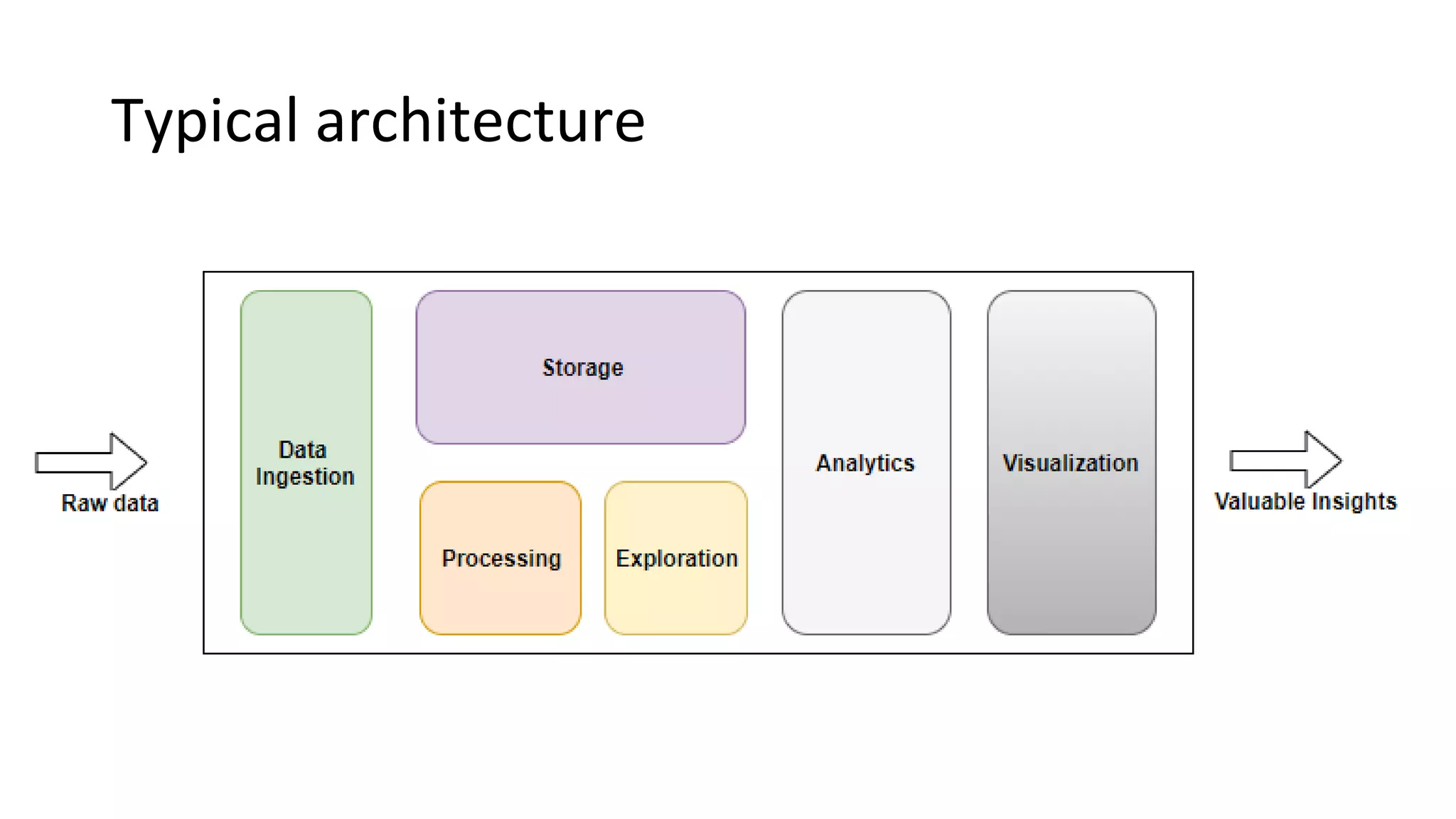
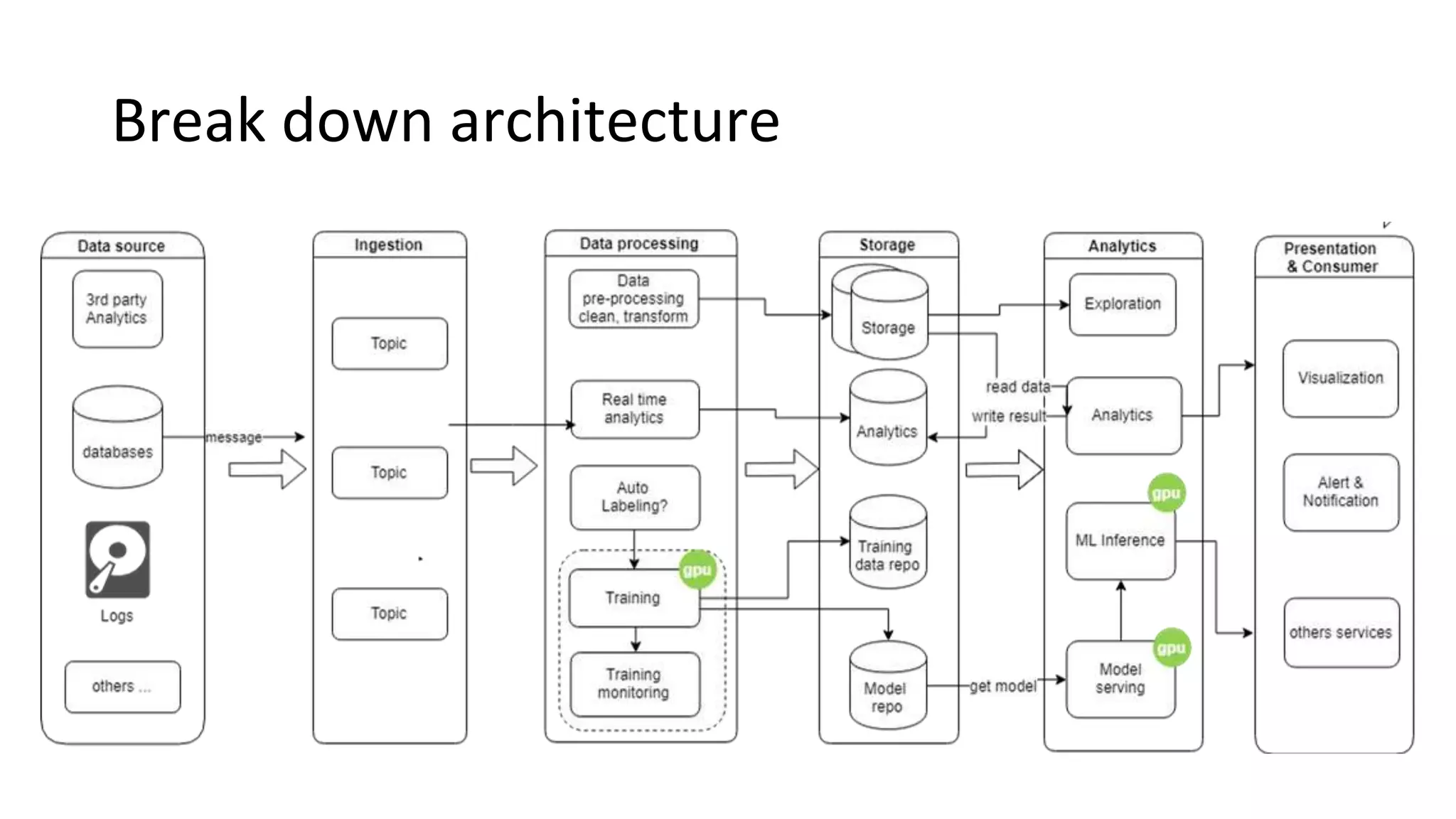
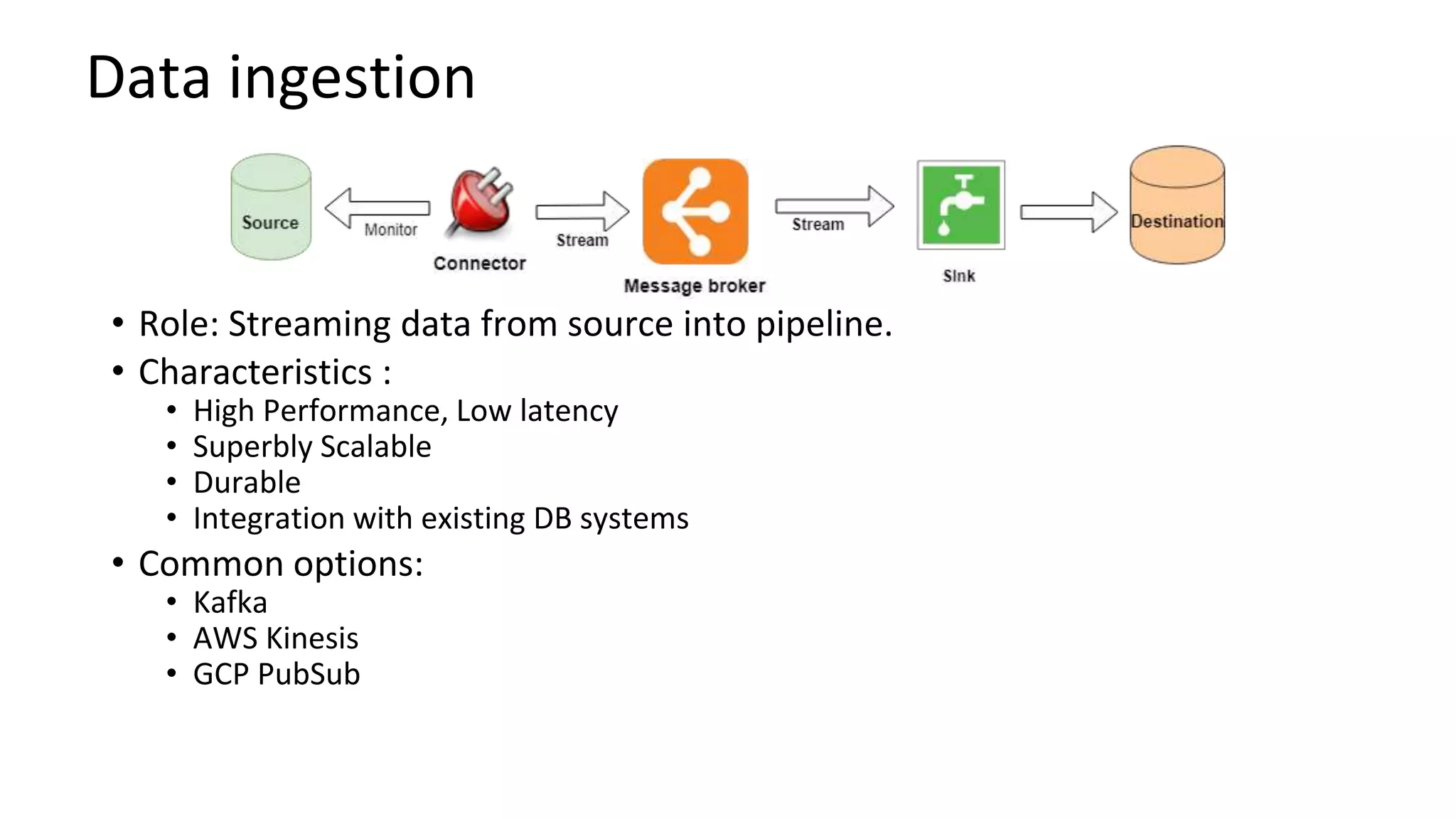
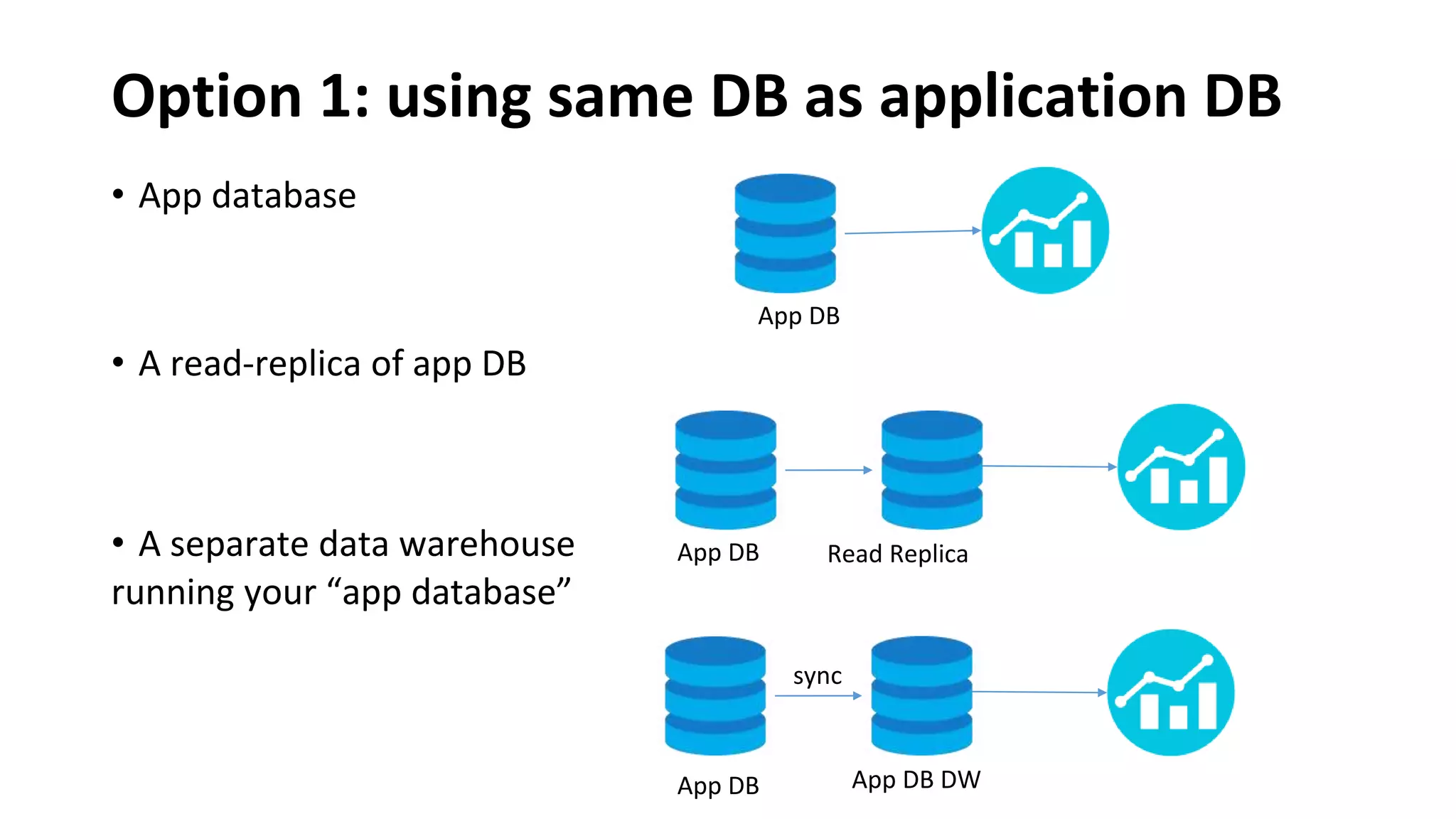
Introduces ETL vs ELT processes, typical architecture for big data analytics, and the role of data ingestion.
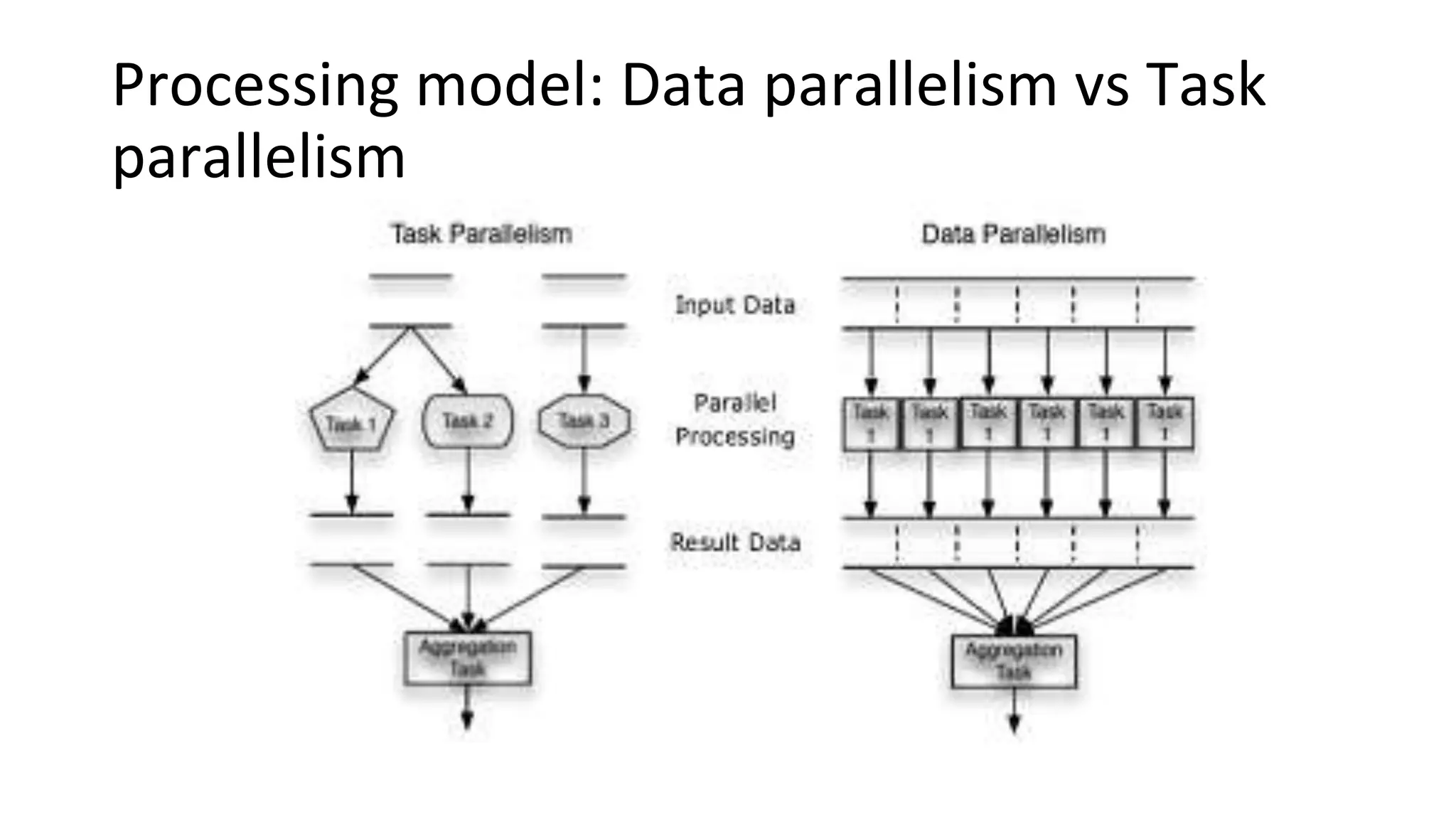
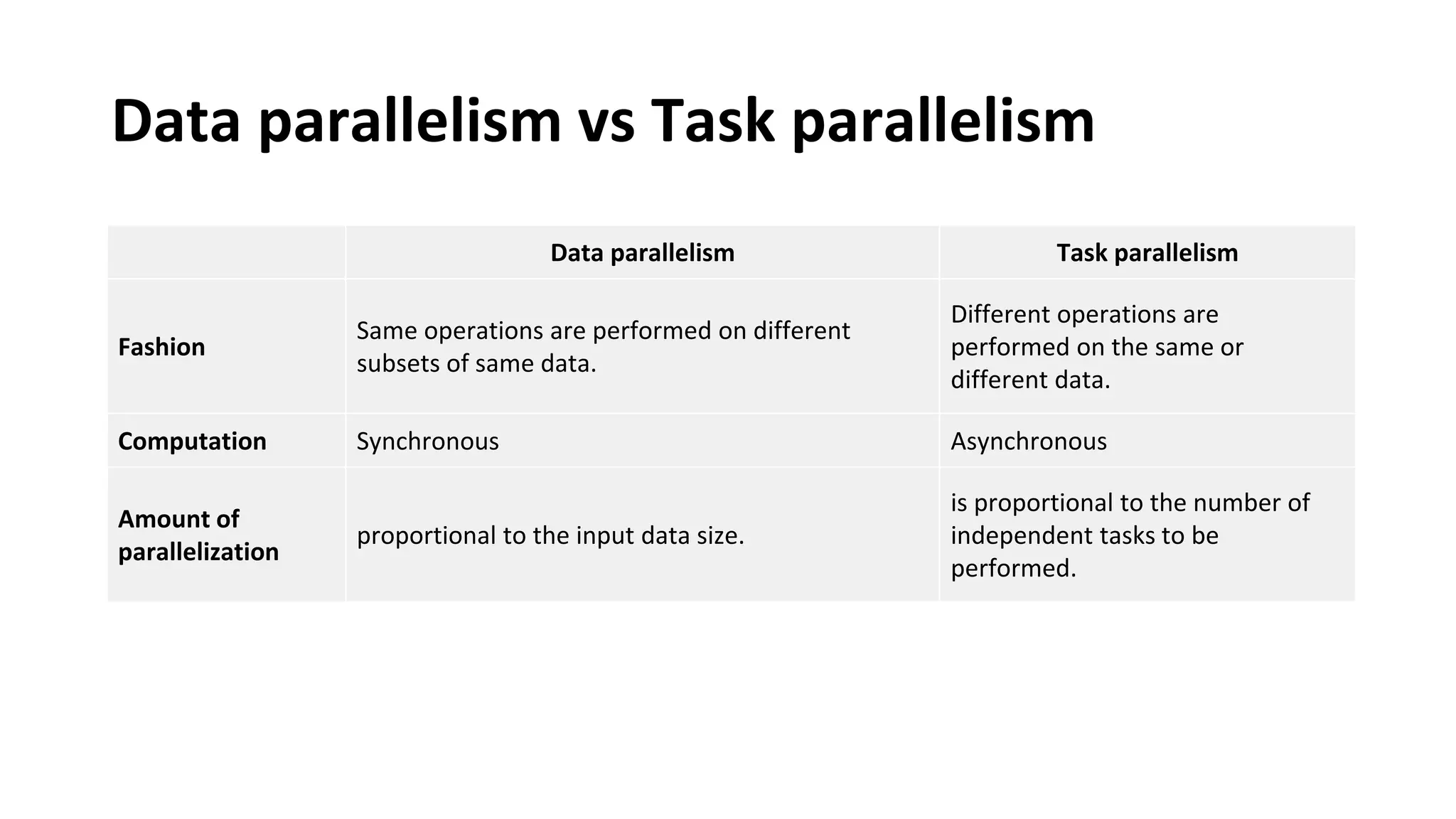
Discusses batch vs stream processing and parallelism in data processing, including unified processing models.
Explains various storage options for structured and unstructured data along with specific technologies for analytics.
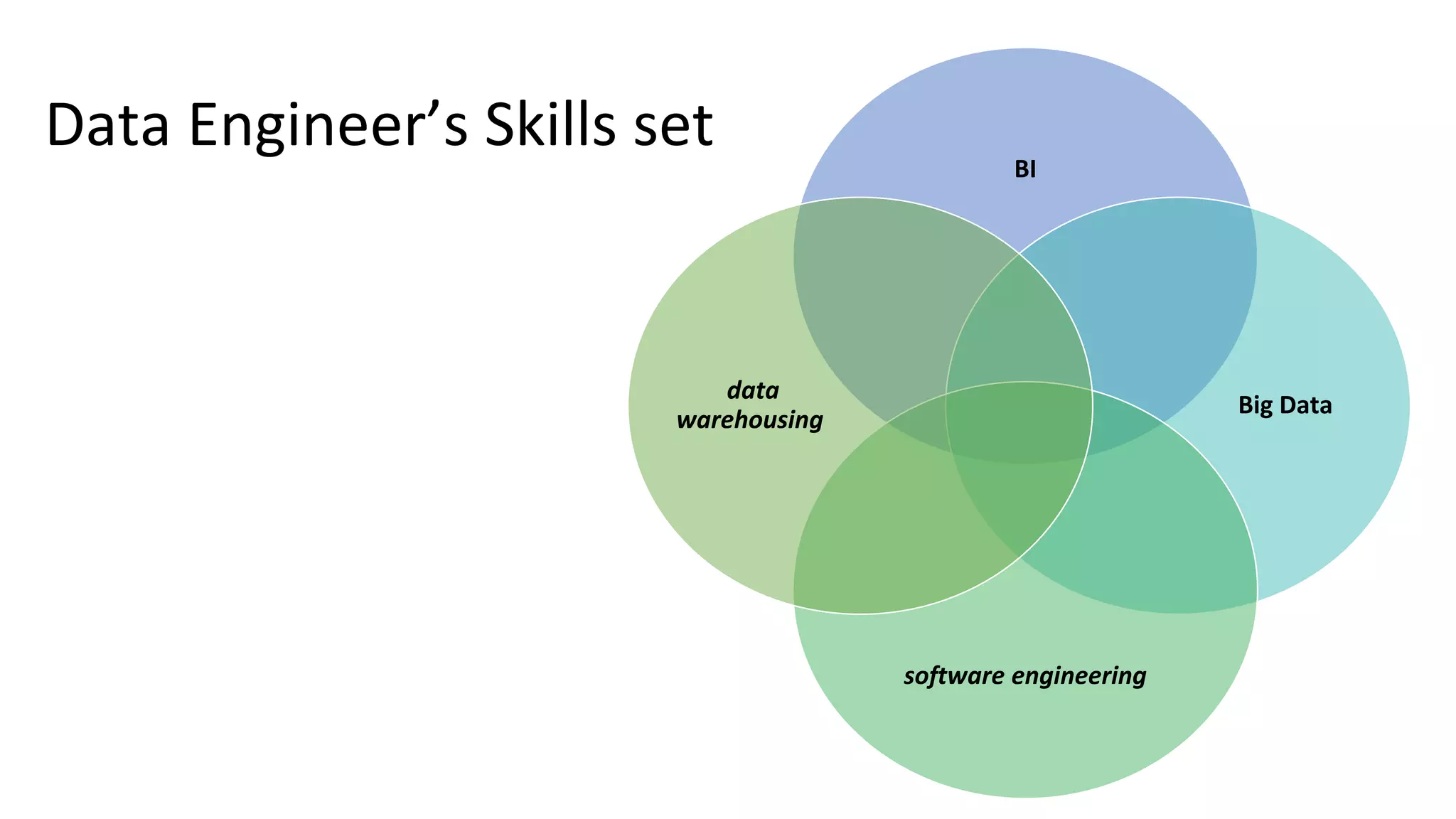
Summarizes the overlapping roles of data scientists and data engineers and highlights the importance of defining distinct roles.

















![[DSC Europe 22] Lakehouse architecture with Delta Lake and Databricks - Draga...](https://cdn.slidesharecdn.com/ss_thumbnails/draganberic-lakehousearchitecturewithdeltalakeanddatabricks-221130080712-6e817e95-thumbnail.jpg?width=640&height=640&fit=bounds)






























![[DSC Europe 25] Dusan Jovicic - AI Story: From on-prem to cloud and back agai...](https://cdn.slidesharecdn.com/ss_thumbnails/8kp49m6uq22ifnbwhfnk-2-251205085715-964d11a6-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DSC Europe 25] Vid Stimac - Policy Parsimony: Between Oversimplifying and Ov...](https://cdn.slidesharecdn.com/ss_thumbnails/eqlepagzqp2rhg3gbluh-dsc-stimac-251120-251205090438-059e7f54-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Goran Obradovic - The Rise of Sovereign AI: Building the Regi...](https://cdn.slidesharecdn.com/ss_thumbnails/7nw2xxixrxqdxvrb5wca-6-251205085714-ab09a2ac-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Marija Vlajkovic & Andrea Radonjanin - Integration of AI tool...](https://cdn.slidesharecdn.com/ss_thumbnails/qf1jrglttoc3bm8s3aop-final-integration-of-ai-tools-251208151905-394f3a6a-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Bogdan Daniel Maruneac - AI - It starts with you.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/odov3snhrcqs9hx5ny2n-4-251205085715-f1daacfe-thumbnail.jpg?width=640&height=640&fit=bounds)






