Download as PDF, PPTX










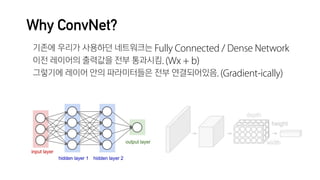
![ex) MNIST 이미지
image = tf.placeholder('int32', [28, 28])
x = tf.reshape(image, [-1]) # 크기 784짜리로 flatten
W = tf.Variable(tf.random_normal([784, 32]))
b = tf.Variable(tf.zeros([32]))
y = tf.nn.xw_plus_b(x, W, b) # xW + b](https://image.slidesharecdn.com/deepdark-161223083850/85/Deep-Learning-Into-Advance-1-Image-ConvNet-15-320.jpg)
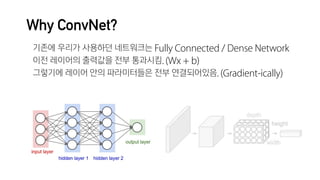
![ex) MNIST 이미지
image = tf.placeholder('int32', [28, 28])
x = tf.reshape(image, [-1]) # 크기 784짜리로 flatten
W = tf.Variable(tf.random_normal([784, 32]))
b = tf.Variable(tf.zeros([32]))
y = tf.nn.xw_plus_b(x, W, b) # xW + b](https://image.slidesharecdn.com/deepdark-161223083850/85/Deep-Learning-Into-Advance-1-Image-ConvNet-16-320.jpg)

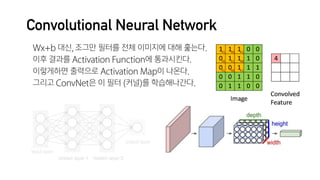


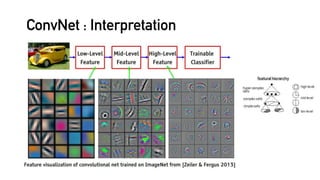
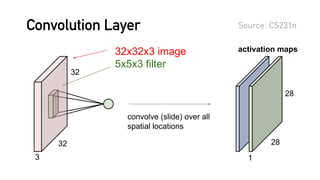
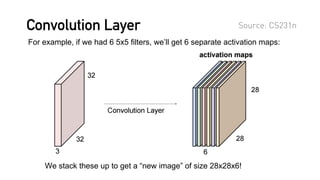
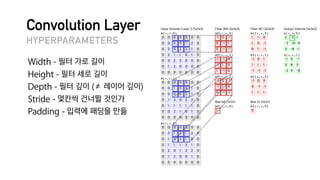
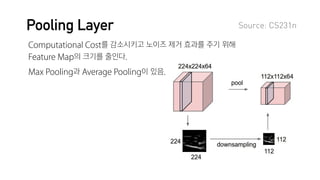




![R E F E R E N C E
Stanford University CS231n : Convolutional Neural Networks for Visual Recognition
Yu, Koltun,. Multi-Scale Context Aggregation by Dilated Convolutions.
arXiv preprint:1511.07122v3 [cs.cV]
Kernel (Image Processing) - Wikipedia
T H A N K Y O U](https://image.slidesharecdn.com/deepdark-161223083850/85/Deep-Learning-Into-Advance-1-Image-ConvNet-36-320.jpg)

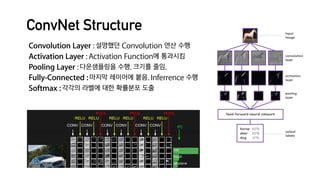
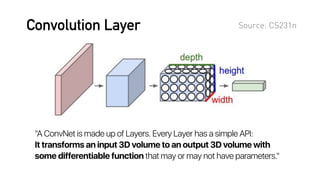
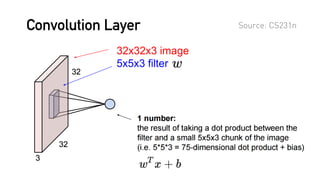
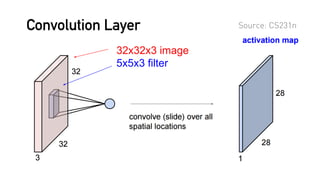
[본 자료는 AB180 사내 스터디의 일환으로 제작되었습니다.] 딥러닝에 대한 기초적인 이해 및 적용 예시를 알아보고, 인사이트를 공유하기 위해 만들었습니다. 첫번째로 딥러닝이 이미지 프로세싱에 적용된 방식 및, Convolutional Neural Network (ConvNet)의 기초에 대해 다루었습니다. * 본 스터디 자료는 Stanford 강좌인 CS231n (http://cs231n.stanford.edu)의 내용을 참고했습니다.



















































![[데이터 분석 소모임] Convolution Neural Network 김려린](https://cdn.slidesharecdn.com/ss_thumbnails/qjbtpgxtsksukja7q6eq-cnn-gimryeorin-240226120343-804ea096-thumbnail.jpg?width=640&height=640&fit=bounds)












![[Paper Review] Visualizing and understanding convolutional networks](https://cdn.slidesharecdn.com/ss_thumbnails/visualizingandunderstandingconvolutionalnetworks-171116075511-thumbnail.jpg?width=640&height=640&fit=bounds)

![[신경망기초] 심층신경망개요](https://cdn.slidesharecdn.com/ss_thumbnails/nn10-180318142325-thumbnail.jpg?width=640&height=640&fit=bounds)